No X5, o sistema que rastreia mercadorias rotuladas e troca dados com o governo e fornecedores é chamado de "Markus". Vamos dizer em ordem como e quem o desenvolveu, que tipo de pilha de tecnologia possui e por que temos algo para nos orgulhar.
Real HighLoad
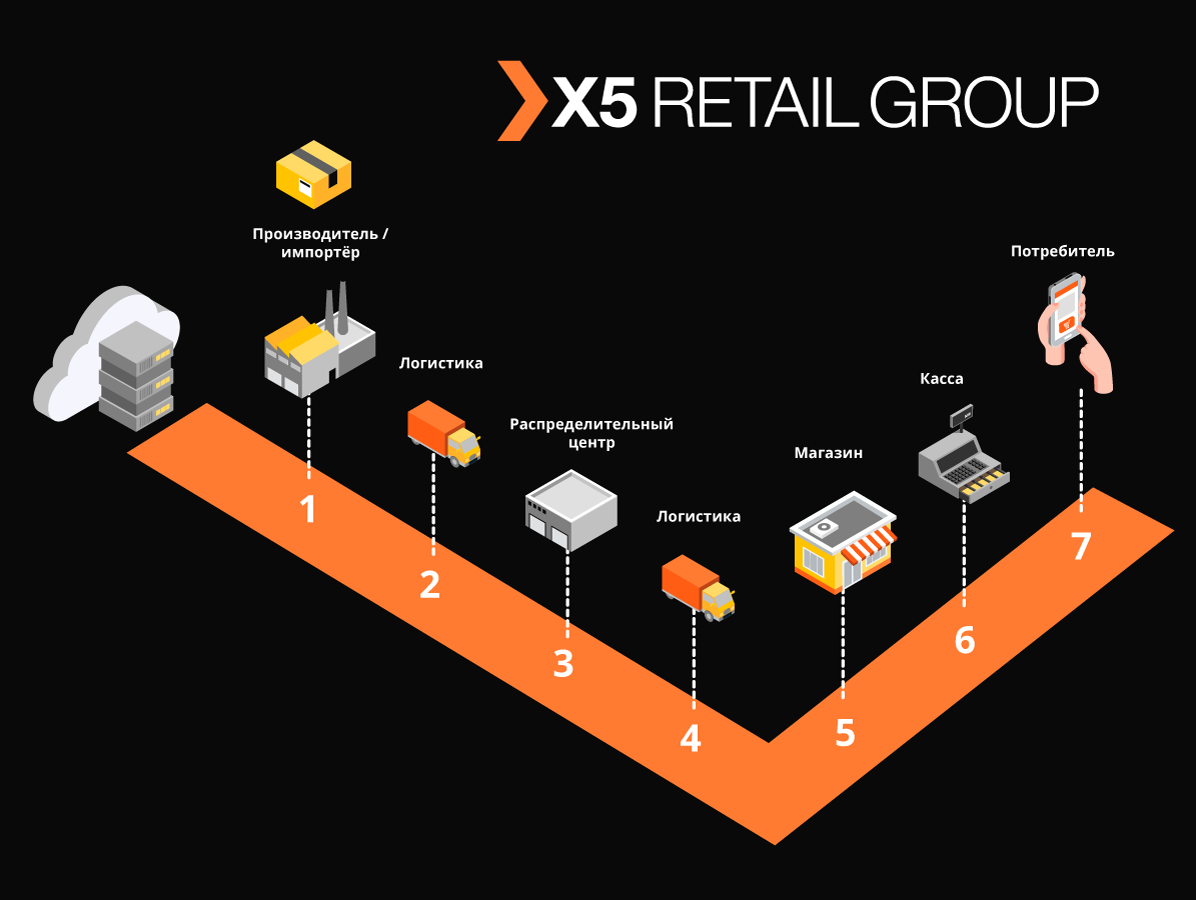
O “Markus” resolve muitos problemas, o principal deles é a interação de integração entre os sistemas de informação X5 e o sistema de informações de produtos rotulados (GIS MP) para rastrear o movimento dos produtos rotulados. A plataforma também armazena todos os códigos de marcação recebidos por nós e todo o histórico do movimento desses códigos entre objetos, ajuda a eliminar a re-classificação dos produtos marcados. No exemplo de produtos de tabaco, incluídos nos primeiros grupos de produtos rotulados, apenas um caminhão de cigarros contém cerca de 600.000 maços, cada um com seu próprio código único. E a tarefa do nosso sistema é rastrear e verificar a legalidade dos movimentos de cada pacote entre armazéns e lojas e, finalmente, verificar a admissibilidade de sua implementação para o cliente final. E registramos transações em dinheiro em torno de 125.000 por hora,e também é necessário registrar como cada pacote entrou na loja. Assim, considerando todos os movimentos entre objetos, esperamos dezenas de bilhões de registros por ano.
Team M
Apesar de o "Markus" ser considerado um projeto no X5, ele está sendo implementado de acordo com a abordagem do produto. A equipe trabalha no Scrum. O início do projeto foi no verão passado, mas os primeiros resultados vieram apenas em outubro - a equipe própria foi totalmente montada, a arquitetura do sistema foi desenvolvida e o equipamento adquirido. Agora, a equipe tem 16 pessoas, seis das quais estão envolvidas no desenvolvimento de back-end e front-end, três em análise de sistemas. Mais seis pessoas estão envolvidas em manual, carregamento, testes automatizados e suporte ao produto. Além disso, temos um especialista em SRE.
O código em nossa equipe é escrito não apenas pelos desenvolvedores, quase todos sabem como programar e escrever autotestes, carregar scripts e scripts de automação. Prestamos atenção especial a isso, pois mesmo o suporte ao produto requer um alto nível de automação. Nós sempre tentamos aconselhar e ajudar nossos colegas que não haviam programado antes, a dar algumas tarefas pequenas para o trabalho.
Em conexão com a pandemia de coronavírus, transferimos toda a equipe para o trabalho remoto, a disponibilidade de todas as ferramentas de gerenciamento de desenvolvimento, o fluxo de trabalho integrado no Jira e no GitLab facilitou a etapa. Os meses passados em um local remoto mostraram que a produtividade da equipe não sofreu com isso; para muitos o conforto no trabalho aumentou, a única coisa é que não há comunicação ao vivo suficiente.
Reunião da equipe antes da distância

Reuniões remotas
Pilha de tecnologia da solução
O repositório padrão e a ferramenta CI / CD para X5 é o GitLab. Nós o usamos para armazenamento de código, teste contínuo, implantação em servidores de teste e produção. Também usamos a prática de revisão de código, quando pelo menos 2 colegas precisam aprovar as alterações feitas pelo desenvolvedor no código. Os analisadores de código estático SonarQube e JaCoCo nos ajudam a manter o código limpo e a fornecer o nível exigido de cobertura de teste de unidade. Todas as alterações no código devem passar por essas verificações. Todos os scripts de teste executados manualmente são posteriormente automatizados.
Para a execução bem-sucedida dos processos de negócios por “Markus”, tivemos que resolver vários problemas tecnológicos, cada um em ordem.
Tarefa 1. A necessidade de escalabilidade horizontal do sistema
Para resolver esse problema, escolhemos uma abordagem de microsserviço à arquitetura. Era muito importante entender as áreas de responsabilidade dos serviços. Tentamos dividi-los em operações de negócios, levando em consideração as especificidades dos processos. Por exemplo, a aceitação em um armazém não é muito frequente, mas uma operação muito volumosa, durante a qual é necessário obter do regulador estadual o mais rapidamente possível informações sobre as unidades de mercadorias recebidas, cujo número em uma entrega chega a 600.000, verifique a admissibilidade de aceitar este produto no armazém e dê a todos informações necessárias para o sistema de automação de armazém. Porém, a remessa dos armazéns tem uma intensidade muito maior, mas ao mesmo tempo opera com pequenas quantidades de dados.
Implementamos todos os serviços com base no princípio apátrida e até tentamos dividir as operações internas em etapas, usando o que chamamos de auto-tópico Kafka. É quando um microsserviço envia uma mensagem para si mesmo, o que permite equilibrar a carga para operações com mais recursos e simplifica a manutenção do produto, mas mais sobre isso posteriormente.
Decidimos separar os módulos para interação com sistemas externos em serviços separados. Isso tornou possível resolver o problema de alterar frequentemente as APIs de sistemas externos, praticamente sem afetar os serviços com funcionalidade de negócios.
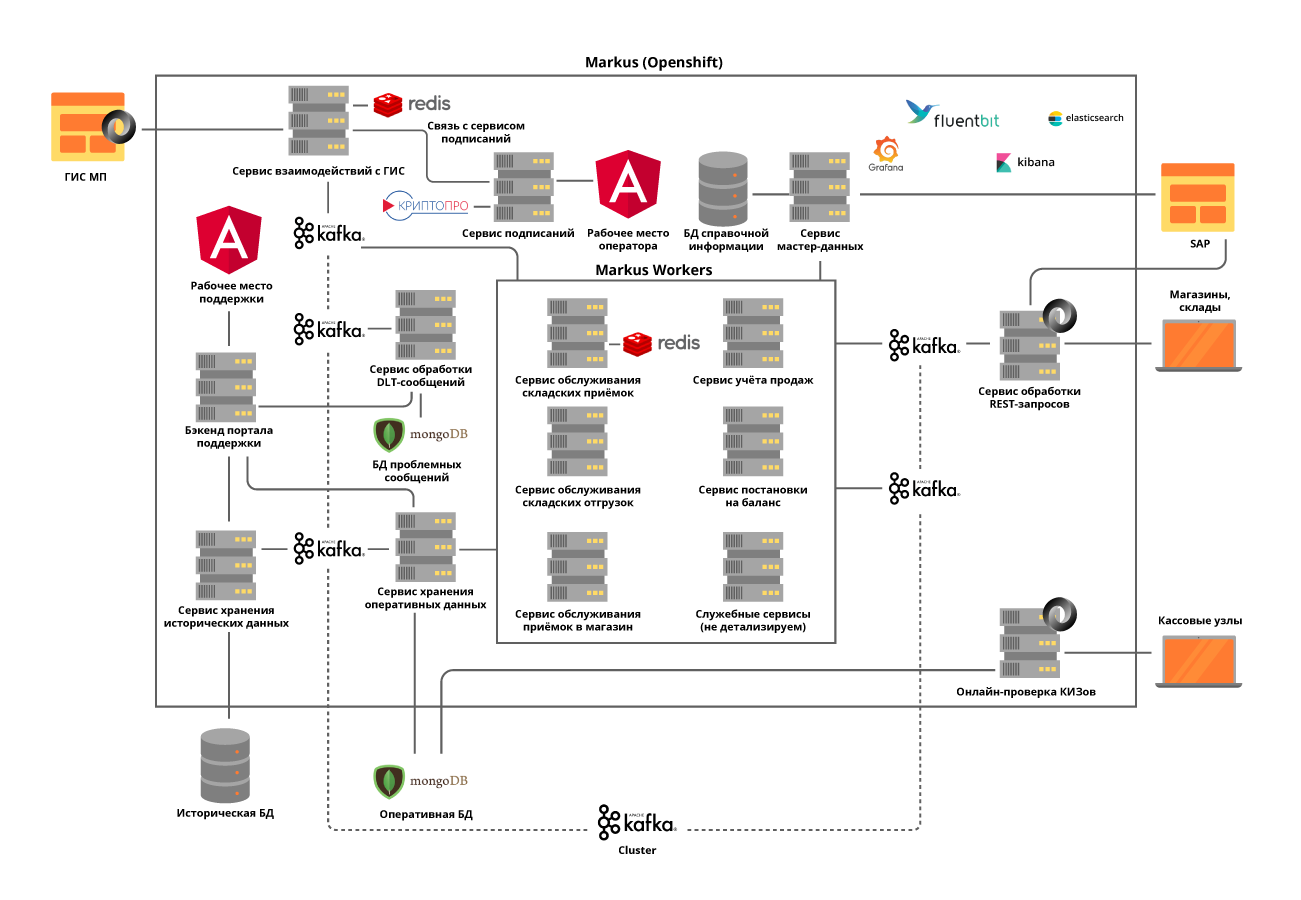
Todos os microsserviços são implantados no cluster OpenShift, que resolve o problema de dimensionar cada microsserviço e nos permite não usar ferramentas de descoberta de serviço de terceiros.
Tarefa 2. A necessidade de manter uma carga alta e uma troca de dados muito intensa entre os serviços da plataforma: somente na fase de lançamento do projeto, são executadas cerca de 600 operações por segundo. Esperamos que esse valor aumente até 5.000 op / s à medida que os objetos de negociação se conectam à nossa plataforma.
Essa tarefa foi resolvida implantando um cluster Kafka e abandonando quase completamente a comunicação síncrona entre os microsserviços da plataforma. Isso requer uma análise cuidadosa dos requisitos do sistema, pois nem todas as operações podem ser assíncronas. Ao mesmo tempo, não apenas transmitimos eventos através do broker, mas também transmitimos todas as informações comerciais necessárias na mensagem. Assim, o tamanho da mensagem pode ser de várias centenas de kilobytes. A limitação no volume de mensagens no Kafka exige que possamos prever com precisão o tamanho das mensagens e, se necessário, as dividimos, mas a divisão é lógica, associada às operações de negócios.
Por exemplo, as mercadorias chegaram no carro, dividimos em caixas. Para operações síncronas, microsserviços separados são alocados e testes de carga rigorosos são realizados. O uso do Kafka representou outro desafio para nós - testar nosso serviço com a integração do Kafka torna todos os nossos testes de unidade assíncronos. Resolvemos esse problema escrevendo nossos próprios métodos utilitários usando o Embedded Kafka Broker. Isso não evita a necessidade de escrever testes de unidade para métodos individuais, mas preferimos testar casos complexos usando o Kafka.
Dedicamos muita atenção ao rastreamento de logs para que seu TraceId não seja perdido quando exceções são lançadas durante a operação de serviços ou ao trabalhar com o lote Kafka. E se não houver perguntas especiais com a primeira, no segundo caso, somos forçados a gravar no log todo o TraceId com o qual o lote veio e selecionar uma para continuar o rastreamento. Em seguida, ao procurar o TraceId inicial, o usuário descobrirá facilmente com qual rastreamento o rastreamento continuou.
Objetivo 3. Necessidade de armazenar uma grande quantidade de dados: mais de 1 bilhão de rótulos por ano apenas para tabaco são enviados para o X5. Eles exigem acesso constante e rápido. No total, o sistema deve processar cerca de 10 bilhões de registros no histórico do movimento desses produtos marcados.
Para resolver o terceiro problema, o banco de dados MongoDB NoSQL foi escolhido. Criamos um fragmento de 5 nós e em cada nó um conjunto de réplicas de 3 servidores. Isso permite dimensionar o sistema horizontalmente, adicionando novos servidores ao cluster e garantir sua tolerância a falhas. Aqui enfrentamos outro problema - garantir a transacionalidade no cluster mongo, levando em consideração o uso de microsserviços escaláveis horizontalmente. Por exemplo, uma das tarefas do nosso sistema é detectar tentativas de revender mercadorias com os mesmos códigos de marcação. Aqui, as sobreposições aparecem com varreduras erradas ou com operações de caixa incorretas. Descobrimos que essas duplicatas podem ocorrer dentro de um lote sendo processado em Kafka e dentro de dois lotes processados em paralelo. Portanto, verificar duplicatas consultando o banco de dados não deu nada.Para cada um dos microsserviços, resolvemos o problema separadamente, com base na lógica de negócios desse serviço. Por exemplo, para recebimentos, adicionamos uma verificação dentro do lote e um processamento separado para a aparência de duplicatas quando inseridas.
Para que o trabalho dos usuários com o histórico de operações não afete o mais importante - o funcionamento de nossos processos de negócios, separamos todos os dados históricos em um serviço separado, com um banco de dados separado, que também recebe informações através do Kafka. Assim, os usuários trabalham com um serviço isolado sem afetar os serviços que processam dados nas operações atuais.
Tarefa 4. Reprocessando filas e monitorando:
Em sistemas distribuídos, surgem inevitavelmente problemas e erros na disponibilidade de bancos de dados, filas e fontes de dados externas. No caso de Markus, a fonte desses erros é a integração com sistemas externos. Era necessário encontrar uma solução que permitisse solicitações repetidas de respostas erradas com um tempo limite especificado, mas ao mesmo tempo não parasse de processar solicitações bem-sucedidas na fila principal. Para isso, foi escolhido o chamado conceito "nova tentativa com base em tópicos". Para cada tópico principal, um ou vários tópicos de nova tentativa são criados, para os quais são enviadas mensagens erradas e, ao mesmo tempo, o atraso no processamento de mensagens do tópico principal é eliminado. Esquema de interação -
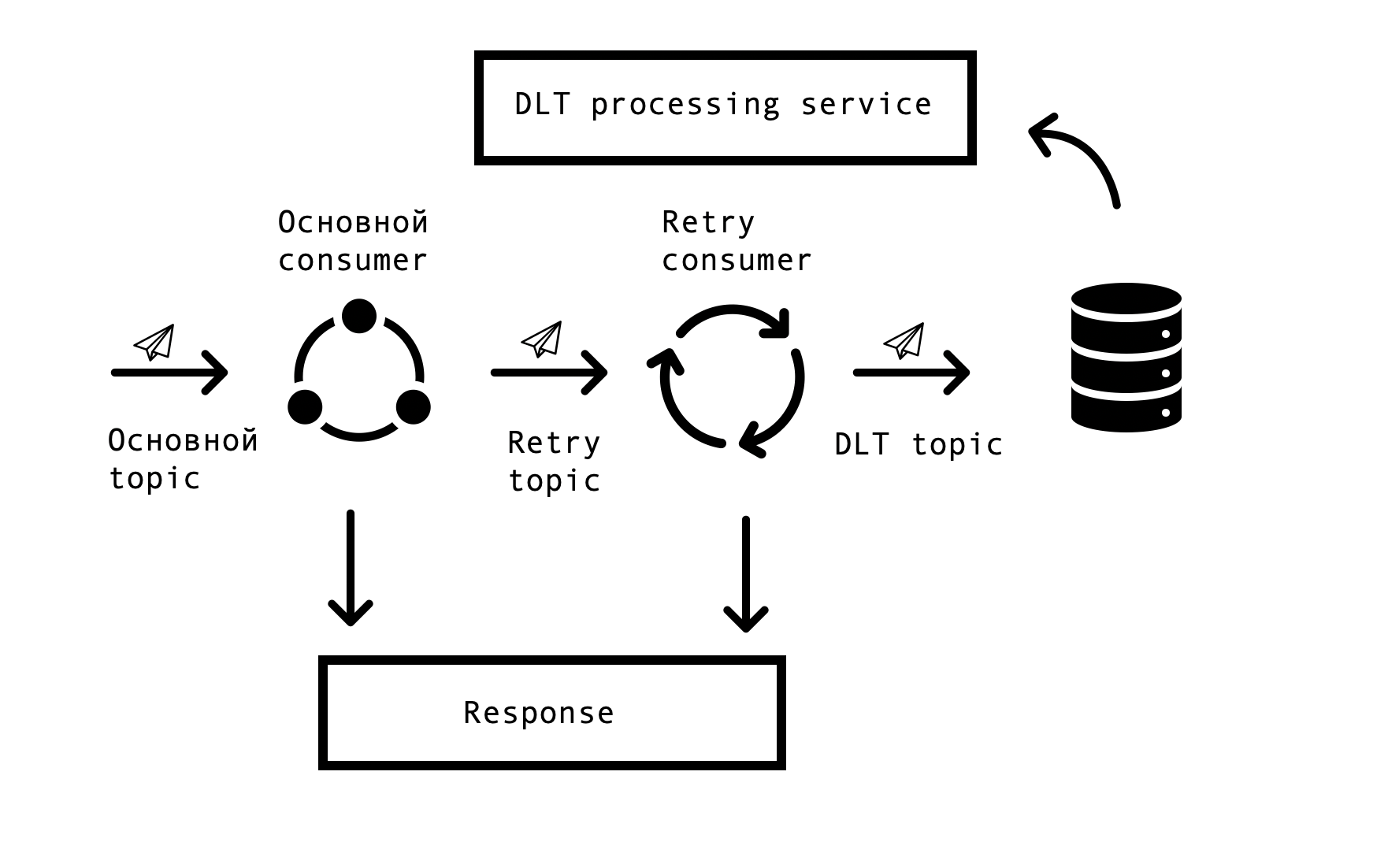
Para implementar esse esquema, precisávamos do seguinte - para integrar esta solução ao Spring e evitar a duplicação de código. Na vastidão da rede, encontramos uma solução semelhante baseada no Spring BeanPostProccessor, mas isso nos parecia desnecessariamente complicado. Nossa equipe criou uma solução mais simples que nos permite integrar o ciclo de criação de consumidores da Spring e adicionar adicionalmente novos consumidores. Oferecemos um protótipo de nossa solução para a equipe Spring, você pode vê-lo aqui . O número de Repetir Consumidores e o número de tentativas de cada consumidor são configurados através dos parâmetros, dependendo das necessidades do processo de negócios e, para que tudo funcione, resta apenas colocar a anotação org.springframework.kafka.annotation.KafkaListener, que é familiar a todos os desenvolvedores do Spring.
Se a mensagem não puder ser processada após todas as tentativas de repetição, ela entrará no DLT (tópico de devoluções) usando Spring DeadLetterPublishingRecoverer. A pedido do suporte, expandimos essa funcionalidade e criamos um serviço separado que permite exibir mensagens, stackTrace, traceId e outras informações úteis sobre elas que entraram no DLT. Além disso, monitoramento e alertas foram adicionados a todos os tópicos da DLT e agora, de fato, a aparência de uma mensagem em um tópico da DLT é um motivo para analisar e estabelecer um defeito. Isso é muito conveniente - pelo nome do tópico, entendemos imediatamente em qual etapa do processo o problema surgiu, o que acelera significativamente a busca por sua causa raiz.

Mais recentemente, implementamos uma interface que nos permite reenviar mensagens por nosso suporte, após eliminar suas causas (por exemplo, restaurar a operacionalidade do sistema externo) e, é claro, estabelecer o defeito correspondente para análise. É aqui que nossos tópicos próprios foram úteis, para não reiniciar uma longa cadeia de processamento, você pode reiniciá-lo a partir da etapa desejada.
Operação da plataforma
A plataforma já está em operação produtiva, todos os dias realizamos entregas e envios, conectamos novos centros de distribuição e lojas. Como parte do piloto, o sistema trabalha com os grupos de mercadorias "Tabaco" e "Sapatos".
Toda a nossa equipe está envolvida na condução de pilotos, analisando problemas emergentes e fazendo propostas para melhorar nosso produto, desde a melhoria de registros até a alteração de processos.
Para não repetir nossos erros, todos os casos encontrados durante o piloto são refletidos em testes automatizados. A presença de um grande número de autotestes e testes de unidade permite realizar testes de regressão e colocar um hotfix em apenas algumas horas.
Agora continuamos a desenvolver e melhorar nossa plataforma e enfrentamos constantemente novos desafios. Se você estiver interessado, falaremos sobre nossas soluções nos seguintes artigos.