Cabeça antifraude Andrey Popov Nox_andryfez uma apresentação sobre como conseguimos atender a todos esses requisitos conflitantes. O tópico central do relatório é um modelo para calcular fatores complexos em um fluxo de dados e garantir a tolerância a falhas do sistema. Andrey também descreveu brevemente a próxima iteração ainda mais rápida do antifraude, que estamos desenvolvendo atualmente.
A equipe antifraude resolve essencialmente o problema de classificação binária. Portanto, o relatório pode interessar não apenas aos especialistas em antifraude, mas também àqueles que fabricam vários sistemas que precisam de fatores rápidos, confiáveis e flexíveis em grandes quantidades de dados.
- Olá. Meu nome é Andrey. Eu trabalho na Yandex, sou responsável pelo desenvolvimento do antifraude. Foi-me dito que as pessoas preferem usar a palavra "recursos", então, ao longo do relatório, mencionarei isso, mas o título e a introdução permaneceram os mesmos, com a palavra "fatores".
O que é antifraude?
O que é antifraude, afinal? É um sistema que protege os usuários contra impactos negativos no serviço. Por influência negativa, quero dizer ações deliberadas que podem degradar a qualidade do serviço e, consequentemente, piorar a experiência do usuário. Podem ser analisadores e robôs bastante simples que pioram nossas estatísticas ou atividades fraudulentas deliberadamente complexas. O segundo, é claro, é mais difícil e mais interessante de definir.
Contra o que a antifraude luta? Alguns exemplos.
Por exemplo, imitação de ações do usuário. Isso é feito pelos caras que chamamos de "SEO preto" - aqueles que não querem melhorar a qualidade do site e o conteúdo do site. Em vez disso, eles escrevem robôs que vão para a pesquisa Yandex, clicam no site deles. Eles esperam que o site suba mais alto dessa maneira. Por precaução, lembro que essas ações contradizem o contrato do usuário e podem levar a sanções graves da Yandex.

Ou, por exemplo, trapacear comentários. Essa revisão pode ser vista na organização do Maps, que coloca janelas de plástico. Ela mesma pagou por esta revisão.
A arquitetura antifraude de nível superior é assim: um determinado conjunto de eventos brutos cai no próprio sistema antifraude como uma caixa preta. Na saída, eventos marcados são gerados.
Yandex tem muitos serviços. Todos eles, especialmente os grandes, de uma forma ou de outra, enfrentam diferentes tipos de fraude. Pesquisa, Mercado, Mapas e dezenas de outros.
Onde estávamos dois ou três anos atrás? Cada equipe sobreviveu sob o ataque de fraude da melhor maneira possível. Ela gerou suas equipes antifraude, seus sistemas, que nem sempre funcionavam bem, não eram muito convenientes para interagir com analistas. E o mais importante, eles estavam mal integrados entre si.
Quero contar como resolvemos isso criando uma única plataforma.

Por que precisamos de uma única plataforma? Reutilização de experiência e dados. A centralização da experiência e dos dados em um só lugar permite que você responda mais rápido e melhor a ataques grandes - eles geralmente são de serviço cruzado.
Kit de ferramentas unificado. As pessoas têm as ferramentas às quais estão acostumadas. E, obviamente, a velocidade da conexão. Se lançamos um novo serviço que está atualmente sob ataque ativo, devemos conectar rapidamente um antifraude de alta qualidade a ele.
Podemos dizer que não somos únicos a esse respeito. Todas as grandes empresas enfrentam problemas semelhantes. E todos com quem nos comunicamos vêm para a criação de sua plataforma única.
Vou lhe contar um pouco sobre como classificamos os antifraude.
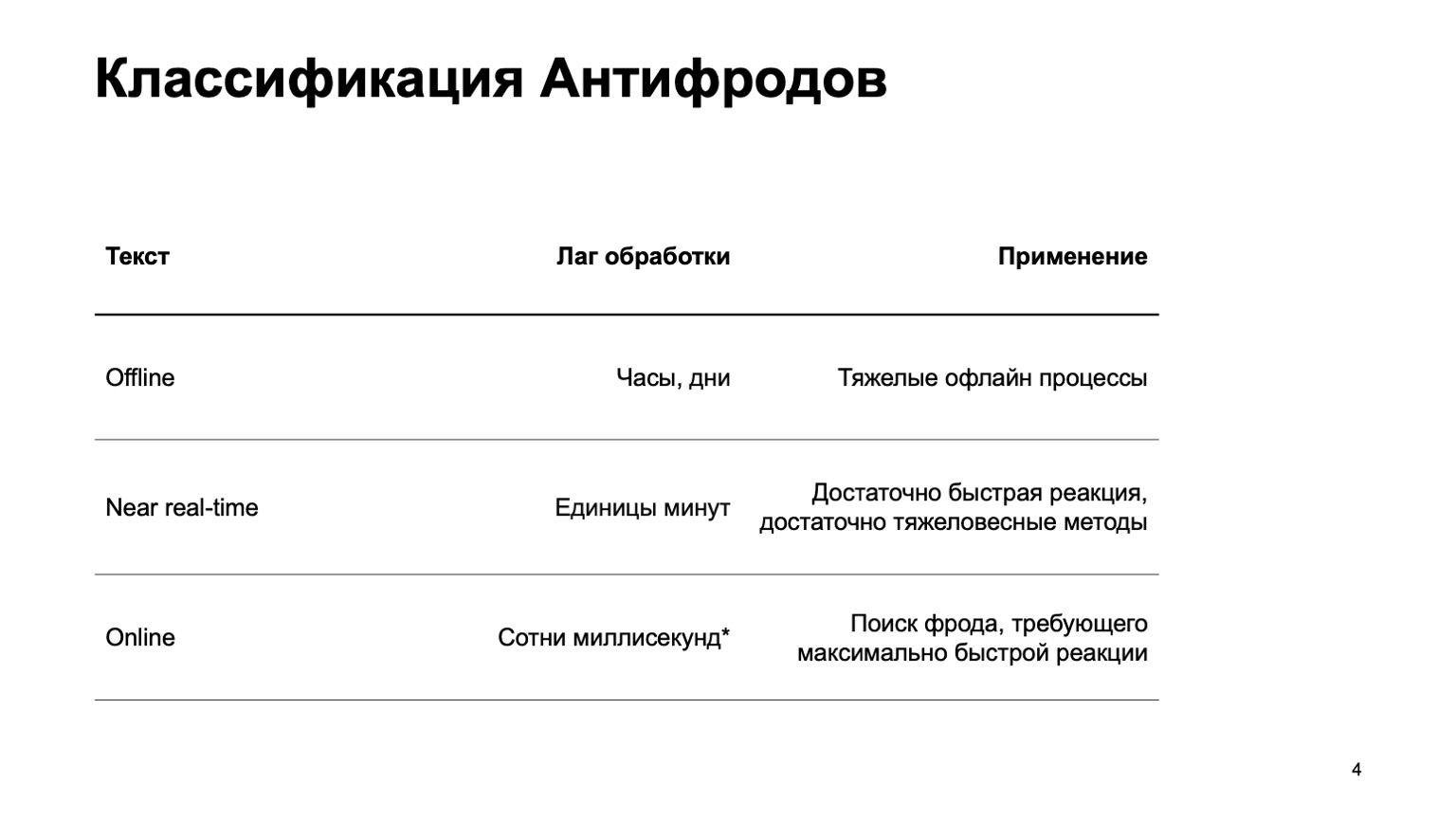
Pode ser um sistema off-line que conta horas, dias e processos off-line pesados: por exemplo, clustering complexo ou reciclagem complexa. Praticamente não tocarei nesta parte do relatório. Há uma parte quase em tempo real que funciona em alguns minutos. Este é um tipo de média de ouro, ela tem reações rápidas e métodos pesados. Primeiro de tudo, vou me concentrar nela. Mas é igualmente importante dizer que, neste estágio, estamos usando dados do estágio acima.
Também existem peças on-line necessárias em locais onde é necessária uma resposta rápida e é essencial eliminar a fraude antes mesmo de recebermos o evento e passá-lo ao usuário. Aqui, reutilizamos dados e algoritmos de aprendizado de máquina computados em níveis mais altos novamente.
Vou falar sobre como essa plataforma unificada é organizada, sobre a linguagem para descrever recursos e interagir com o sistema, sobre o nosso caminho para aumentar a velocidade, ou seja, sobre a transição do segundo estágio para o terceiro.
Mal tocarei nos próprios métodos de ML. Basicamente, falarei sobre plataformas que criam recursos, que depois usamos no treinamento.
Quem pode estar interessado nisso? Obviamente, para aqueles que escrevem antifraude ou combatem golpistas. Mas também para quem apenas inicia o fluxo de dados e lê os recursos, considera ML. Como criamos um sistema bastante geral, talvez você esteja interessado em algo disso.
Quais são os requisitos do sistema? Existem alguns deles, aqui estão alguns deles:
- Grande fluxo de dados. Processamos centenas de milhões de eventos em cinco minutos.
- Recursos totalmente configuráveis.
- .
- , - exactly-once- , . — , , , , .
- , , .
Além disso, vou falar sobre cada um desses pontos separadamente.
Como, por razões de segurança, não posso falar sobre serviços reais, vamos apresentar um novo serviço Yandex. Na verdade não, esqueça, este é um serviço fictício que eu criei para mostrar exemplos. Que seja um serviço no qual as pessoas tenham um banco de dados de todos os livros existentes. Eles entram, dão classificações de um a dez, e os atacantes querem influenciar a classificação final para que seus livros sejam comprados.
Todas as coincidências com serviços reais são, é claro, aleatórias. Vamos considerar, em primeiro lugar, a versão quase em tempo real, pois on-line não é especificamente necessário aqui na primeira aproximação.
Big data
O Yandex tem uma maneira clássica de resolver problemas de big data: use o MapReduce. Usamos nossa própria implementação do MapReduce chamada YT . A propósito, Maxim Akhmedov tem uma história sobre ela esta noite . Você pode usar sua implementação ou uma implementação de código aberto como o Hadoop.
Por que não usamos a versão online imediatamente? Nem sempre é necessário, pode complicar os recálculos no passado. Se adicionamos um novo algoritmo, novos recursos, geralmente queremos recalcular os dados no passado para alterar os veredictos. É mais difícil usar métodos pesados - acho claro o porquê. E a versão online, por várias razões, pode ser mais exigente em termos de recursos.
Se usarmos o MapReduce, obteremos algo assim. Utilizamos um tipo de mini-lote, ou seja, dividimos o lote nas menores peças possíveis. Nesse caso, é um minuto. Mas quem trabalha com o MapReduce sabe que menos desse tamanho, provavelmente, já existem despesas gerais muito grandes do próprio sistema - despesas gerais. Convencionalmente, não será capaz de lidar com o processamento em um minuto.
Em seguida, executamos o conjunto Reduzir nesse conjunto de lotes e obtemos um lote marcado.

Em nossas tarefas, geralmente é necessário calcular o valor exato dos recursos. Por exemplo, se quisermos calcular o número exato de livros que o usuário leu no último mês, calcularemos esse valor para cada lote e devemos armazenar todas as estatísticas coletadas em um único local. E então remova valores antigos e adicione novos.
Por que não usar métodos de contagem aproximada? Resposta curta: nós também as usamos, mas, às vezes, em problemas antifraude, é importante ter exatamente o valor exato para alguns intervalos. Por exemplo, a diferença entre dois e três livros lidos pode ser bastante significativa para certos métodos.
Como conseqüência, precisamos de um grande histórico de dados no qual armazenaremos essas estatísticas.
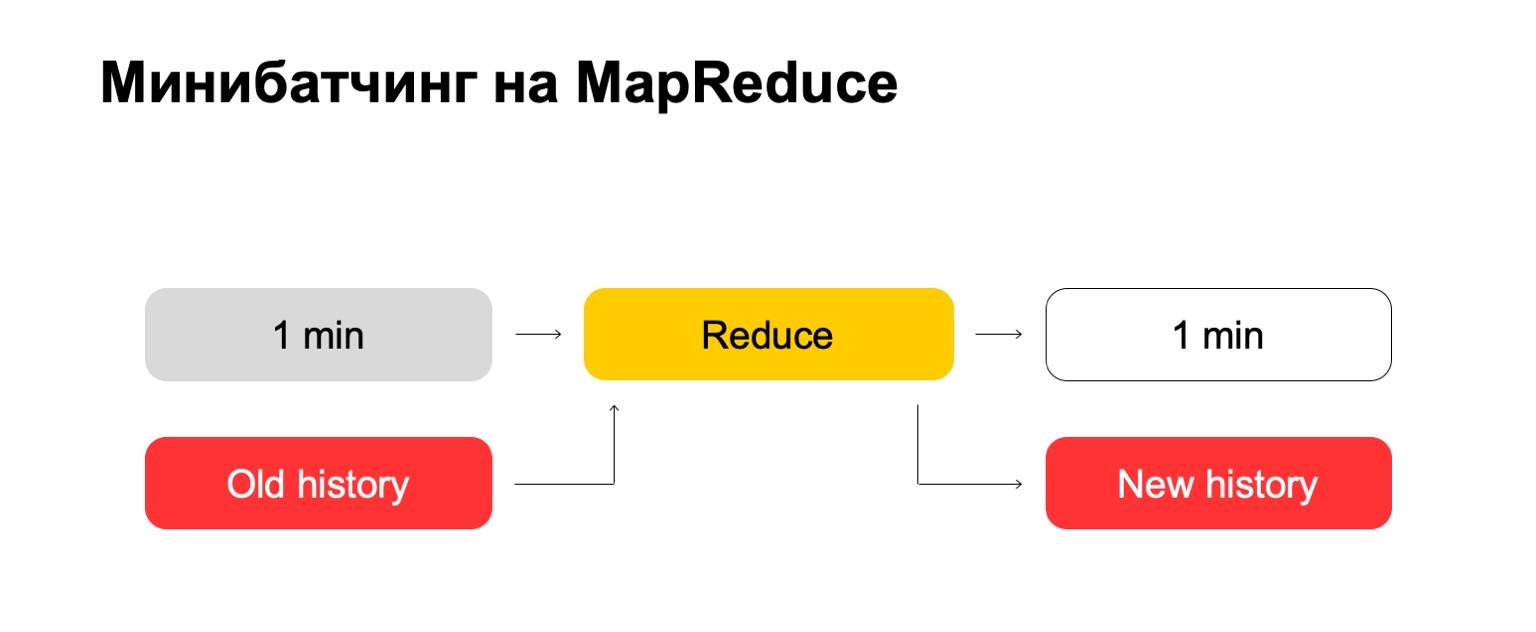
Vamos tentar "de frente". Temos um minuto e uma grande história antiga. Colocamos na entrada Reduzir e produzimos um histórico atualizado e um registro marcado, dados.
Para aqueles que trabalharam com o MapReduce, provavelmente sabem que isso pode funcionar muito mal. Se o histórico puder ser centenas ou mesmo milhares, dezenas de milhares de vezes maior que o próprio lote, esse processamento poderá funcionar proporcionalmente ao tamanho do histórico, e não ao tamanho do lote.
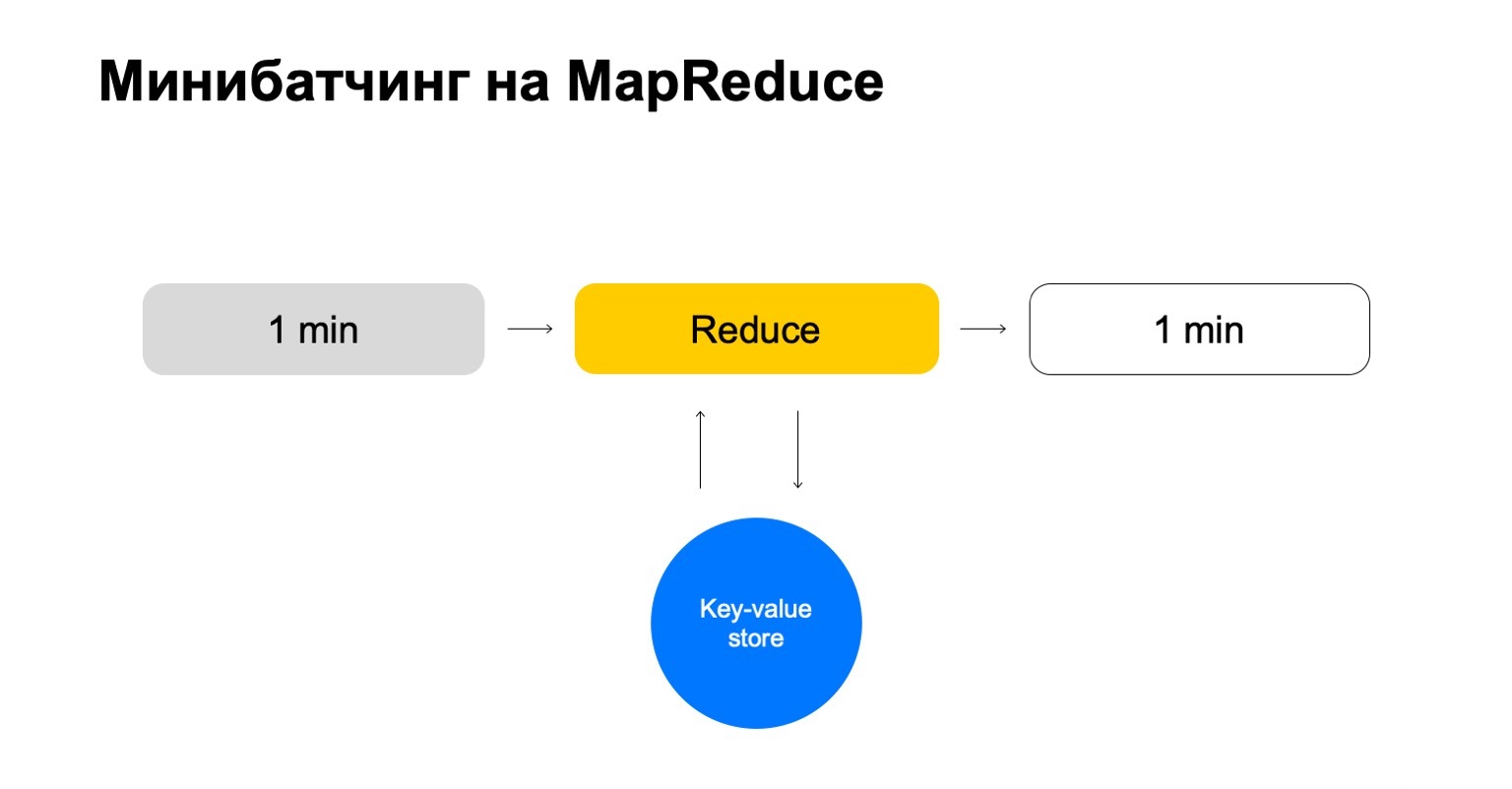
Vamos substituir isso por algum armazenamento de valor-chave. Esta é novamente a nossa própria implementação, armazenamento de valores-chave, mas armazena dados na memória. Provavelmente o analógico mais próximo é algum tipo de Redis. Mas temos uma pequena vantagem aqui: nossa implementação do armazenamento de valores-chave está muito bem integrada ao MapReduce e ao cluster MapReduce no qual é executado. Acontece uma transacionalidade conveniente, transferência de dados conveniente entre eles.
Mas o esquema geral é que, em cada tarefa deste Reduce, iremos para esse armazenamento de valor-chave, atualizaremos os dados e os escreveremos novamente depois de formar um veredicto.
Terminamos com uma história que apenas lida com as chaves de que precisamos e dimensiona facilmente.
Recursos configuráveis
Um pouco sobre como configuramos recursos. Contadores simples muitas vezes não são suficientes. Para pesquisar golpistas, você precisa de vários recursos, de um sistema inteligente e conveniente para configurá-los.
Vamos dividir em três etapas:
- Extrair, onde extraímos dados para a chave fornecida e do log.
- Mesclar, onde mesclamos esses dados com as estatísticas que estão no histórico.
- Build, onde formamos o valor final do recurso.
Por exemplo, vamos calcular a porcentagem de histórias de detetive lidas por um usuário.
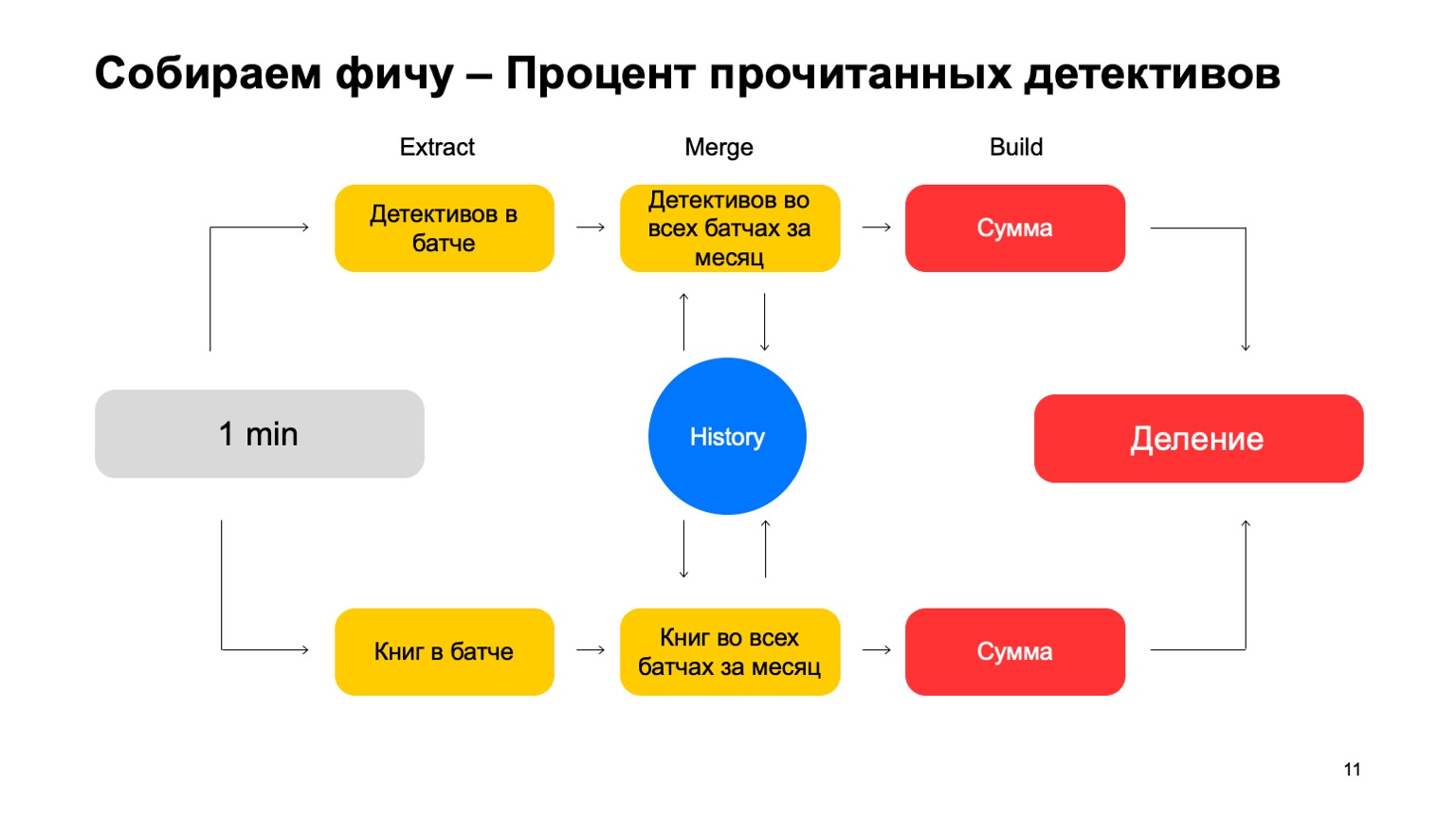
Se o usuário ler muitas histórias de detetive, ele é muito suspeito. Nunca fica claro o que esperar dele. Extrair é a remoção do número de detetives que o usuário leu neste lote. Mesclagem - captura todos os detetives, todos esses dados de lotes por um mês. E Build é alguma quantia.
Então fazemos o mesmo pelo valor de todos os livros que ele leu e terminamos com a divisão.
E se quisermos contar valores diferentes, por exemplo, o número de autores diferentes que um usuário lê?
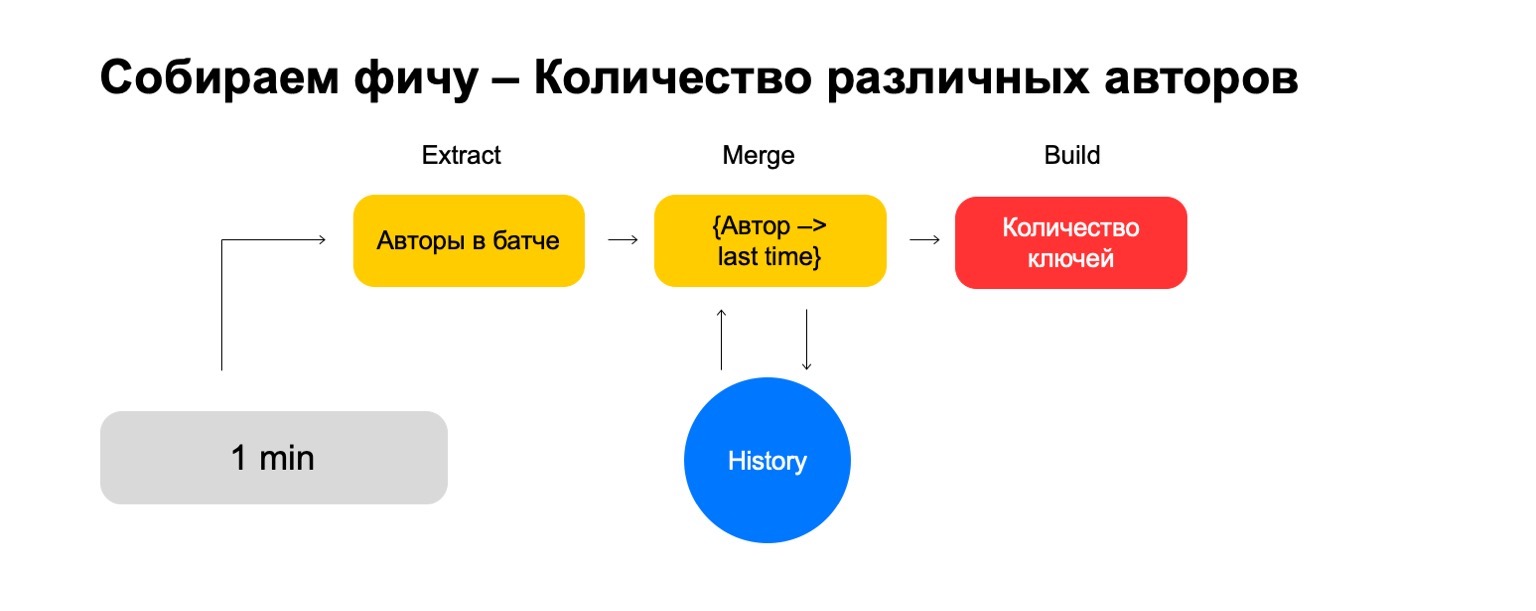
Em seguida, podemos pegar o número de autores diferentes que o usuário leu neste lote. Além disso, armazene alguma estrutura em que fazemos uma associação de autores recentemente, quando o usuário os lê. Portanto, se encontrarmos novamente esse autor no usuário, atualizaremos esse tempo. Se precisarmos excluir eventos antigos, sabemos o que excluir. Para calcular o recurso final, basta contar o número de chaves nele.

Mas, em um sinal barulhento, esses recursos não são suficientes para um corte, precisamos de um sistema para colar suas junções, colando esses recursos a partir de diferentes cortes.
Vamos, por exemplo, introduzir tais cortes - usuário, autor e gênero.

Vamos calcular algo difícil. Por exemplo, lealdade média ao autor. Por lealdade, quero dizer que os usuários que lêem o autor - quase o lêem. Além disso, esse valor médio é bastante baixo para o número médio de autores lidos pelos usuários que o leram.
Este poderia ser um sinal potencial. Ele, é claro, pode significar que o autor é assim: existem apenas fãs ao seu redor, todos que o lêem lêem apenas ele. Mas também pode significar que o próprio autor está tentando enganar o sistema e criar esses usuários falsos que supostamente o leram.
Vamos tentar calcular isso. Vamos contar um recurso que conta o número de autores diferentes por um longo intervalo. Por exemplo, aqui o segundo e o terceiro valores parecem suspeitos para nós, são poucos.
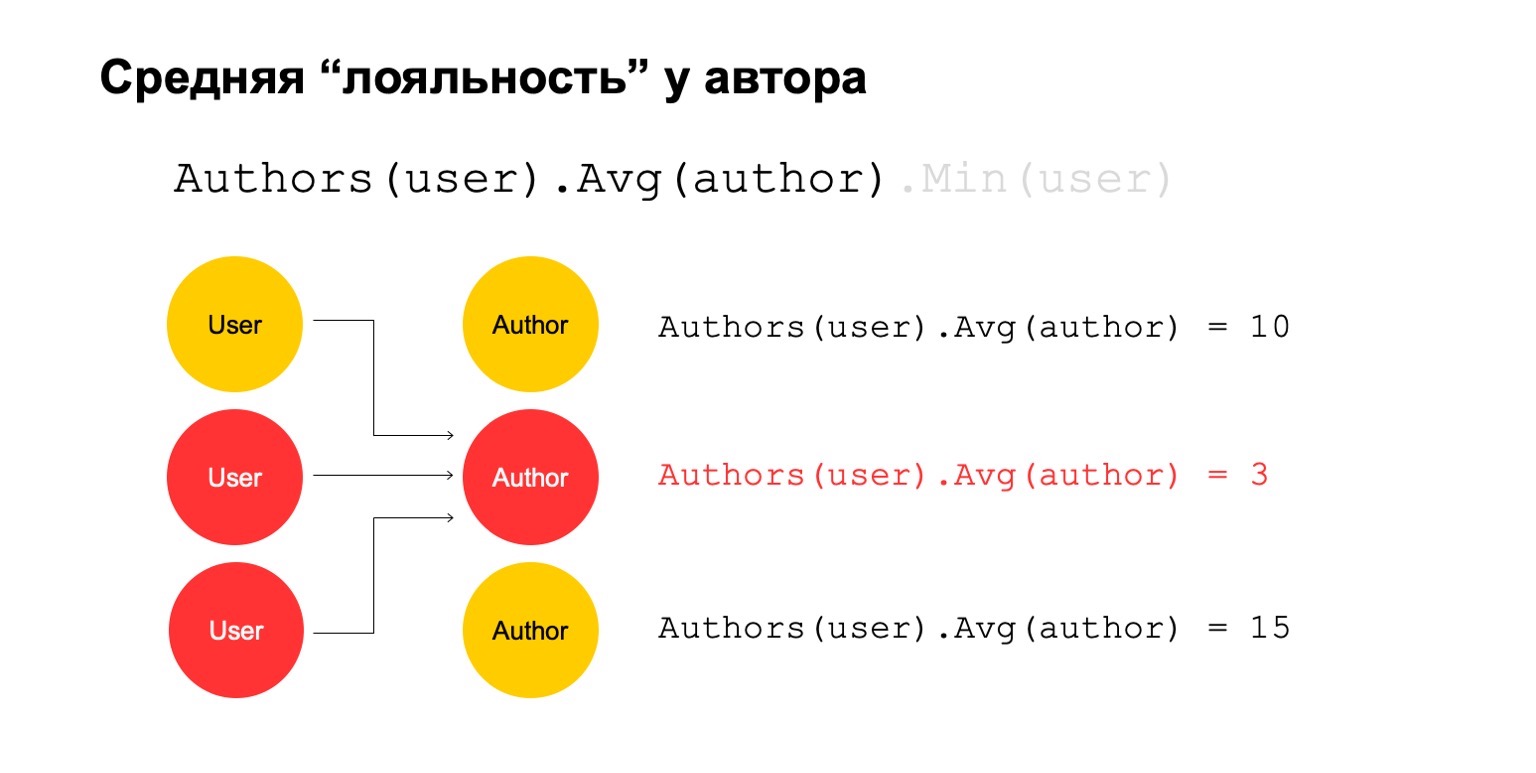
Então vamos calcular o valor médio para os autores que estão relacionados em um intervalo grande. E então aqui o valor médio é novamente bastante baixo: 3. Por alguma razão, este autor parece suspeito para nós.
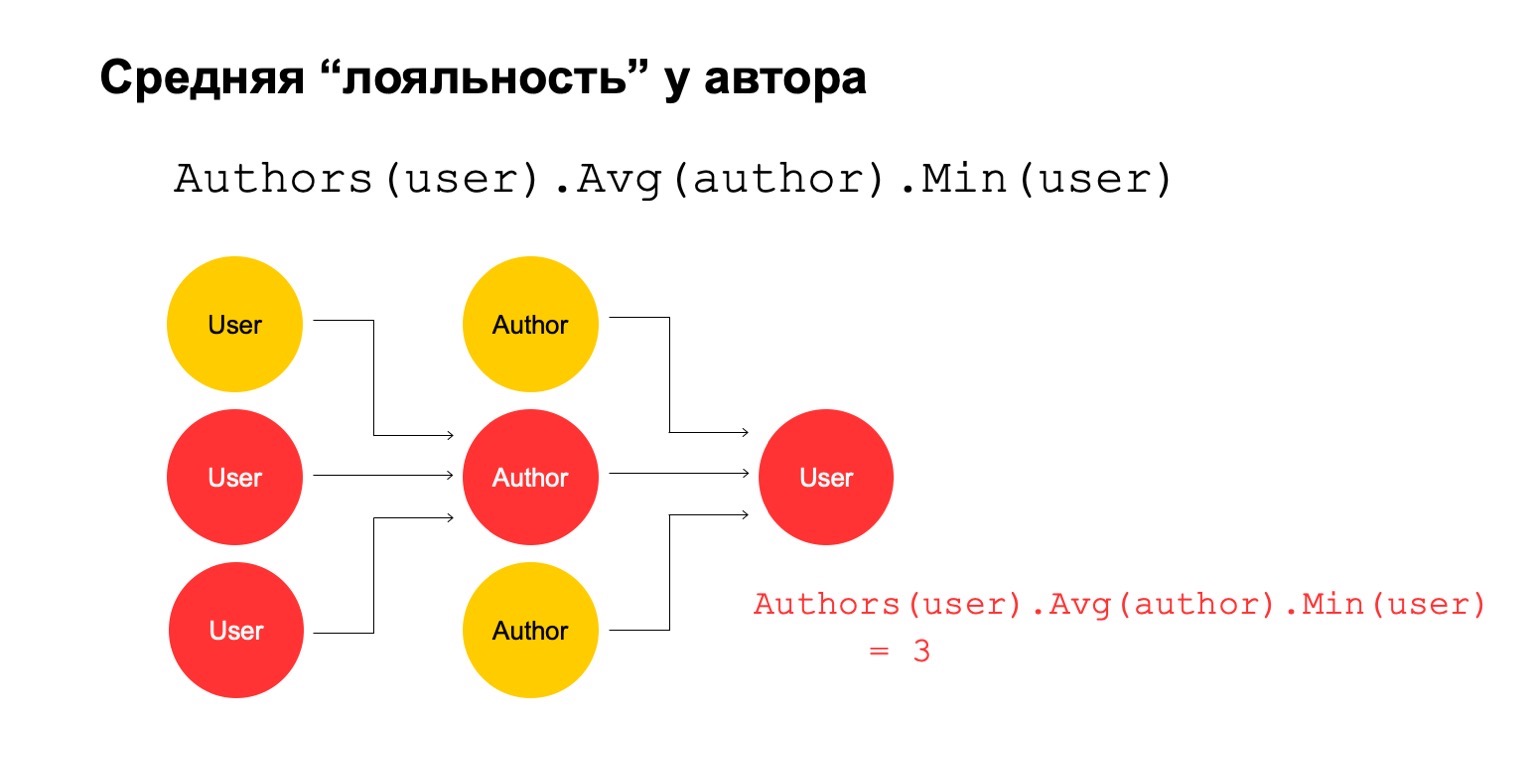
E podemos devolvê-lo ao usuário para entender que esse usuário específico tem uma conexão com o autor, o que parece suspeito para nós.
É claro que isso por si só não pode ser um critério explícito de que o usuário deve ser filtrado ou algo parecido. Mas este poderia ser um dos sinais que podemos usar.
Como fazer isso no paradigma MapReduce? Vamos fazer várias reduções consecutivas e as dependências entre elas.

Temos um gráfico de reduções. Ela influencia em quais fatias contamos os recursos, quais junções geralmente são permitidas, na quantidade de recursos consumidos: obviamente, quanto mais reduções, mais recursos. E latência, taxa de transferência.
Vamos construir, por exemplo, esse gráfico.
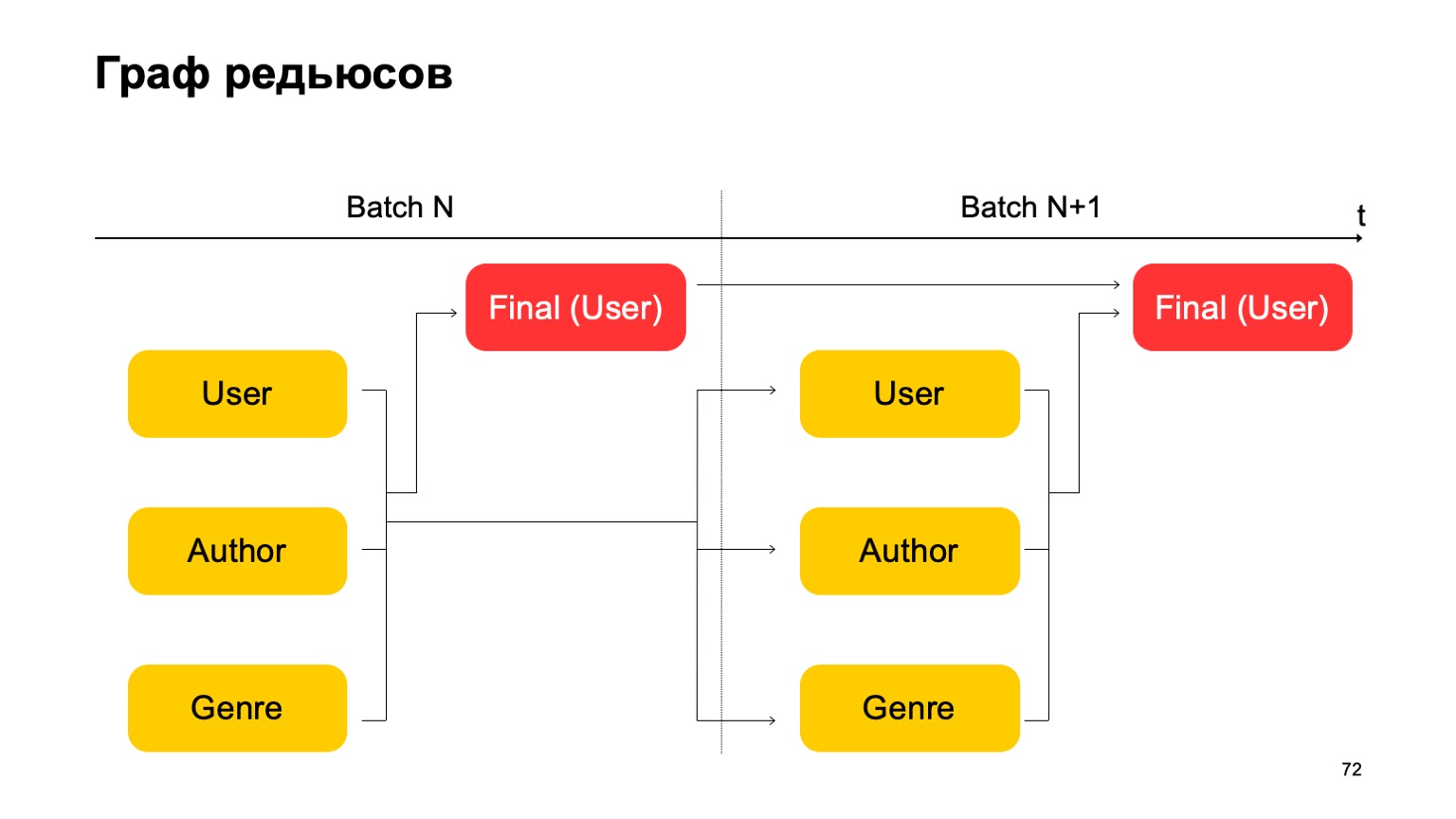
Ou seja, vamos dividir as reduções que temos em duas etapas. Na primeira etapa, calcularemos diferentes reduções em paralelo para diferentes seções - nossos usuários, autores e gênero. E precisamos de algum tipo de segundo estágio, onde coletaremos recursos dessas diferentes reduções e aceitaremos o veredicto final.
Para o próximo lote, fazemos o mesmo. Além disso, temos uma dependência do primeiro estágio de cada lote no primeiro estágio do passado e no segundo estágio no segundo estágio do passado.
É importante aqui que não tenhamos essa dependência:
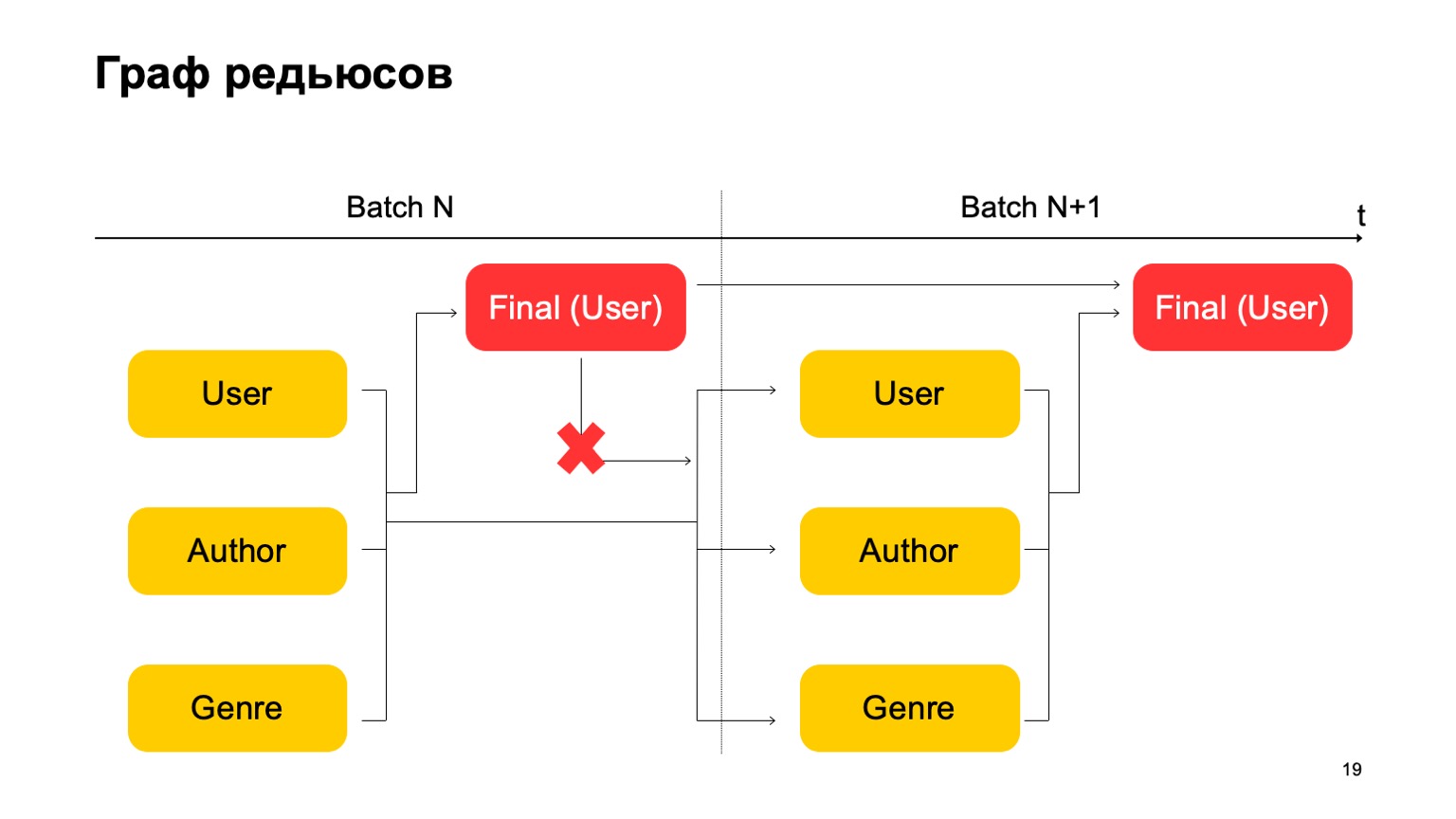
Ou seja, na verdade temos um transportador. Ou seja, o primeiro estágio do próximo lote pode funcionar em paralelo com o segundo estágio do primeiro lote.
Como podemos fazer as estatísticas de três estágios apresentadas acima, se temos apenas duas etapas? Muito simples. Podemos ler o primeiro valor no primeiro estágio do lote N.
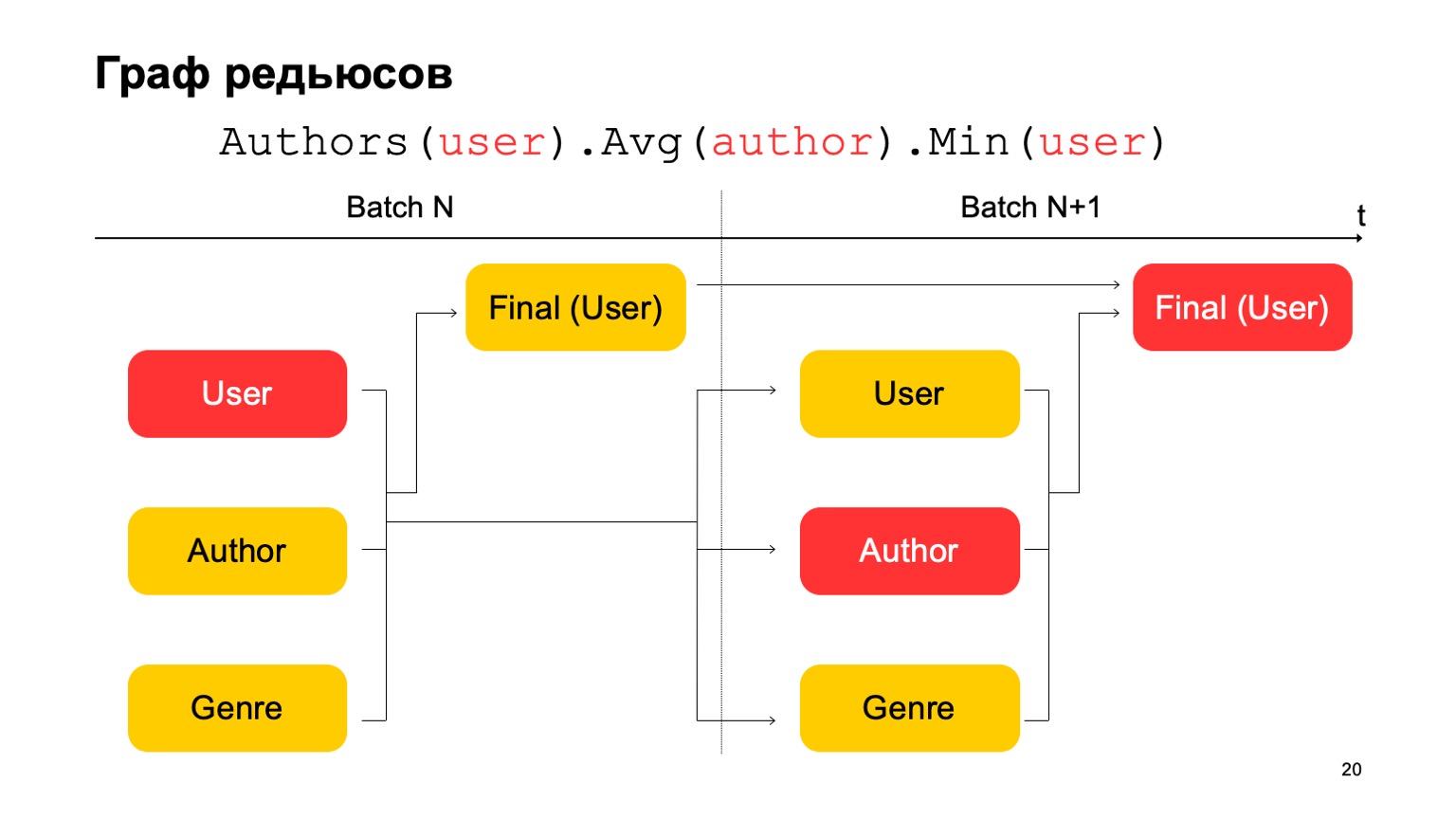
O segundo valor no primeiro estágio do lote é N + 1, e o valor final deve ser lido no segundo estágio do lote N + 1. Assim, durante a transição entre o primeiro estágio e o segundo, talvez haja estatísticas não muito precisas para o lote N + 1. Mas geralmente isso é suficiente para esses cálculos.

Com todas essas coisas, é possível criar recursos mais complexos a partir de cubos. Por exemplo, o desvio da classificação atual do livro em relação à classificação média do usuário. Ou a proporção de usuários que classificam um livro de maneira muito positiva ou negativa. Também suspeito. Ou a classificação média de livros de usuários com mais de N classificações para livros diferentes. Esta é talvez uma avaliação mais precisa e justa de algum ponto de vista.

Adicionado a isso é o que chamamos de relação entre eventos. Muitas vezes, duplicatas aparecem nos logs ou nos dados que são enviados para nós. Podem ser eventos técnicos ou comportamento robótico. Também encontramos essas duplicatas. Ou, por exemplo, alguns eventos relacionados. Digamos que seu sistema exibe recomendações de livros e os usuários clicam nessas recomendações. Para que as estatísticas finais que afetam a classificação não sejam estragadas, precisamos garantir que, se filtrarmos a impressão, também precisaremos filtrar o clique na recomendação atual.
Mas como nosso fluxo pode ocorrer de maneira desigual, primeiro um clique, devemos adiá-lo até vermos o programa e aceitarmos um veredicto com base nele.
Idioma da descrição do recurso
Vou falar um pouco sobre a linguagem usada para descrever tudo isso.

Você não precisa ler, isso é por exemplo. Começamos com três componentes principais. A primeira é uma descrição das unidades de dados na história, de um modo geral, de um tipo arbitrário.

Este é algum tipo de recurso, um número anulável.

E algum tipo de regra. O que chamamos de regra? Este é um conjunto de condições para esses recursos e outras coisas. Tínhamos três arquivos separados.
O problema é que aqui uma cadeia de ações se espalha por arquivos diferentes. Um grande número de analistas precisa trabalhar com nosso sistema. Eles estavam desconfortáveis.
A linguagem acaba sendo imperativa: descrevemos como calcular os dados, e não declarativo, quando descreveríamos o que precisamos calcular. Isso também não é muito conveniente, é fácil cometer um erro e um alto limite de entrada. Novas pessoas vêm, mas elas não entendem como trabalhar com isso.
Solução - vamos criar nossa própria DSL. Descreve nosso cenário de forma mais clara, é mais fácil para novas pessoas, é de mais alto nível. Nós nos inspiramos em SQLAlchemy, C # Linq e similares.
Vou dar alguns exemplos semelhantes aos que dei acima.

Porcentagem de histórias de detetive lidas. Contamos o número de livros lidos, ou seja, agrupamos por usuário. Adicionamos filtragem a essa condição e, se queremos calcular a porcentagem final, apenas calculamos a classificação. Tudo é simples, claro e intuitivo.

Se contarmos o número de autores diferentes, agruparemos por usuário, definir autores distintos. Para isso, podemos adicionar algumas condições, por exemplo, uma janela de cálculo ou um limite no número de valores que armazenamos devido a restrições de memória. Como resultado, contamos a contagem, o número de chaves nele.

Ou a lealdade média que eu estava falando. Ou seja, novamente, temos algum tipo de expressão calculada de cima. Agrupamos por autor e definimos algum valor médio entre essas expressões. Em seguida, reduzimos de volta para o usuário.

Para isso, podemos adicionar uma condição de filtro. Ou seja, nosso filtro pode ser, por exemplo, o seguinte: a lealdade não é muito alta e a porcentagem de detetives está entre 80 em 100.
O que usamos para isso sob o capô?
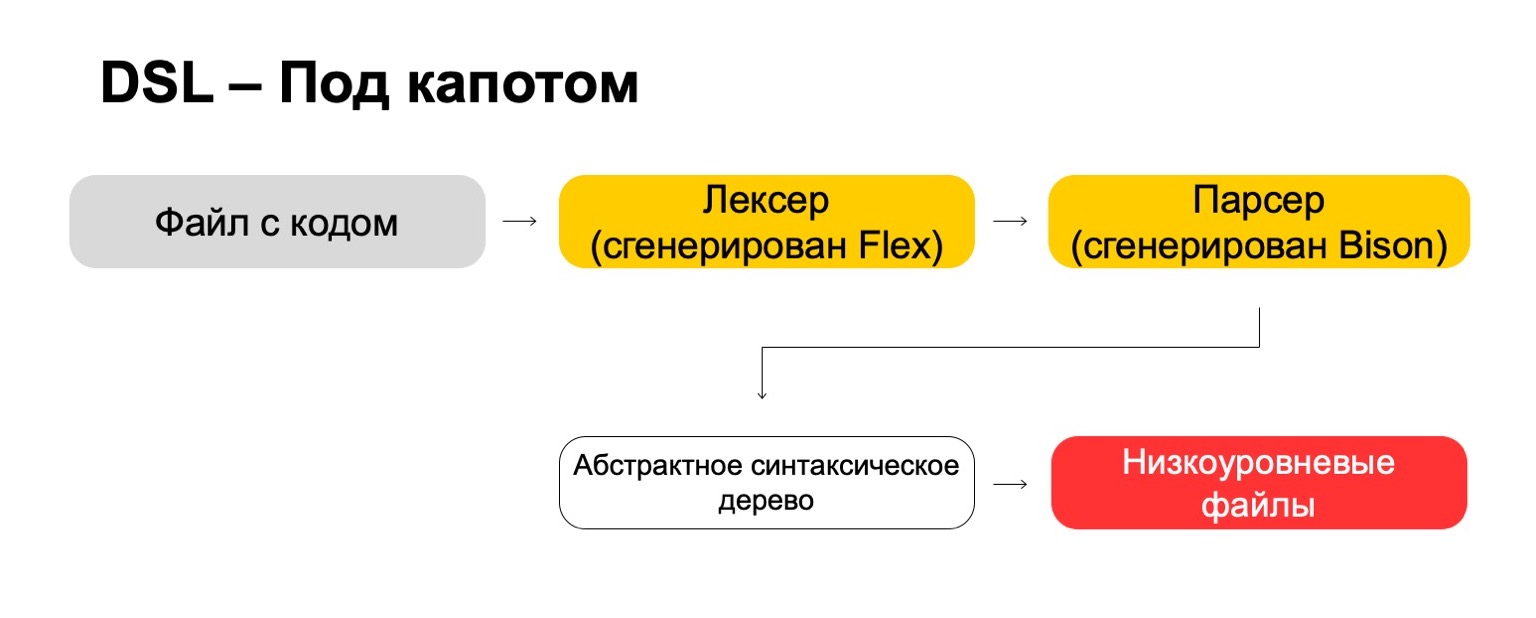
Sob o capô, usamos as mais modernas tecnologias diretamente dos anos 70, como Flex e Bison. Talvez você tenha ouvido. Eles geram código. Nosso arquivo de código passa pelo nosso lexer, que é gerado no Flex, e pelo analisador, que é gerado no Bison. O lexer gera símbolos ou palavras terminais no idioma, o analisador gera expressões de sintaxe.
A partir disso, obtemos uma árvore de sintaxe abstrata, com a qual já podemos fazer transformações. E, no final, transformamos em arquivos de baixo nível que o sistema entende.
Qual é o resultado? Isso é mais complicado do que parece à primeira vista. São necessários muitos recursos para refletir sobre as pequenas coisas, como prioridades de operações, casos extremos e coisas do gênero. Você precisa aprender tecnologias raras que dificilmente serão úteis para você na vida real, a menos que você escreva compiladores, é claro. Mas no final vale a pena. Ou seja, se você, como nós, tem um grande número de analistas que geralmente vêm de outras equipes, isso no final dá uma vantagem significativa, porque fica mais fácil para eles trabalharem.
Confiabilidade
Alguns serviços exigem tolerância a falhas: processamento cross-DC e exatamente uma vez. Uma violação pode causar discrepância nas estatísticas e perdas, incluindo perdas monetárias. Nossa solução para o MapReduce é tal que lemos os dados de cada vez em apenas um cluster e os sincronizamos no segundo.
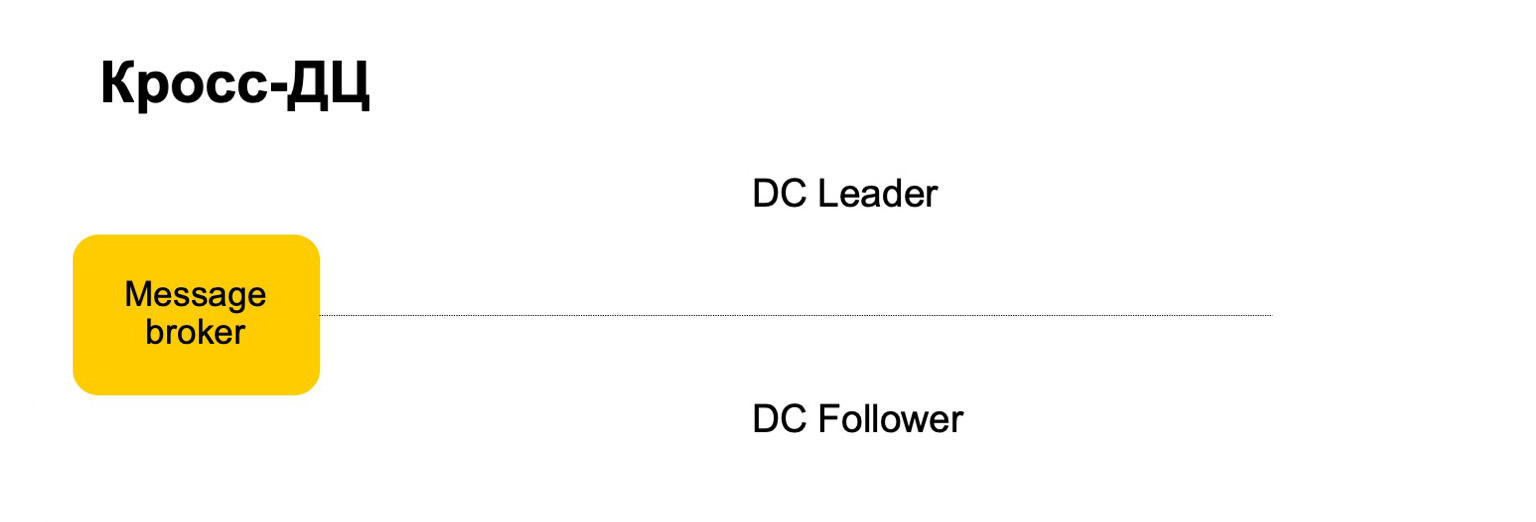
Por exemplo, como nos comportaríamos aqui? Existe um líder, seguidor e intermediário de mensagens. Pode-se considerar que este é um kafka condicional, embora aqui, é claro, sua própria implementação.
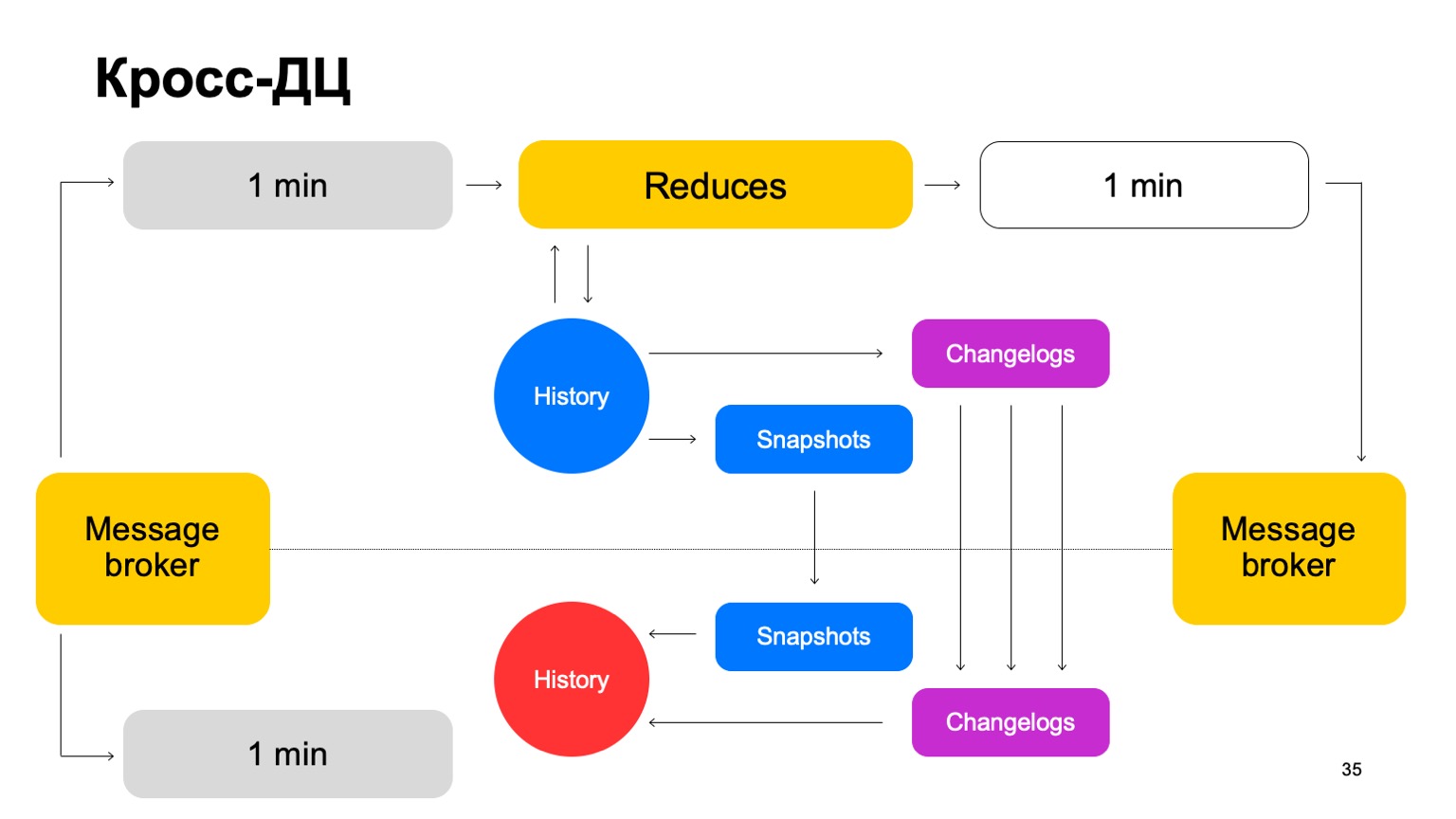
Entregamos nossos lotes para ambos os clusters, lançamos um conjunto de reduções no mesmo líder, aceitamos os veredictos finais, atualizamos o histórico e enviamos os resultados de volta ao serviço para o intermediário de mensagens.
De vez em quando, naturalmente temos que fazer a replicação. Ou seja, coletamos instantâneos, coletamos alterações - alterações para cada lote. Sincronizamos ambos com o segundo seguidor de cluster. E também trazendo uma história tão quente. Deixe-me lembrá-lo de que a história é mantida na memória aqui.
Portanto, se um controlador de domínio, por algum motivo, ficar indisponível, podemos rapidamente, com um atraso mínimo, mudar para o segundo cluster.
Por que não contar com dois grupos em paralelo? Os dados externos podem diferir em dois clusters, eles podem ser fornecidos por serviços externos. O que são dados externos, afinal? Isso é algo que sobe deste nível superior. Ou seja, clustering complexo e similares. Ou apenas dados auxiliares para cálculos.
Precisamos de uma solução acordada. Se contarmos os vereditos em paralelo usando dados diferentes e alternar periodicamente os resultados de dois grupos diferentes, a consistência entre eles cairá drasticamente. E, claro, economizando recursos. Como usamos os recursos da CPU em apenas um cluster por vez.
E o segundo cluster? Quando trabalhamos, ele está praticamente ocioso. Vamos usar os recursos dele para uma pré-produção completa. Por pré-produção completa, quero dizer aqui uma instalação completa que aceita o mesmo fluxo de dados, trabalha com os mesmos volumes de dados etc.

Se o cluster estiver indisponível, alteramos essas instalações de venda para pré-produção. Portanto, temos um pré-produto há algum tempo, mas tudo bem.
A vantagem é que podemos contar mais recursos no pré-processo. Por que isso é necessário? Como fica claro que, se queremos contar uma grande quantidade de recursos, geralmente não precisamos contar todos eles à venda. Lá, contamos apenas o necessário para obter vereditos finais.
(00:25:12)
Mas, ao mesmo tempo, temos um tipo de cache quente no pré-processo, grande, com uma ampla variedade de recursos. No caso de um ataque, podemos usá-lo para fechar o problema e transferir esses recursos para produção.
Além disso, estão os benefícios dos testes B2B. Ou seja, todos lançamos, é claro, primeiro a pré-venda. Comparamos completamente quaisquer diferenças e, portanto, não nos enganamos, minimizamos a probabilidade de cometer um erro ao lançar para venda.
Um pouco sobre o agendador. É claro que temos algum tipo de máquina que executa a tarefa no MapReduce. Estes são alguns tipos de trabalhadores. Eles sincronizam seus dados regularmente com o banco de dados Cross-DC. Este é apenas o estado do que eles conseguiram calcular no momento.
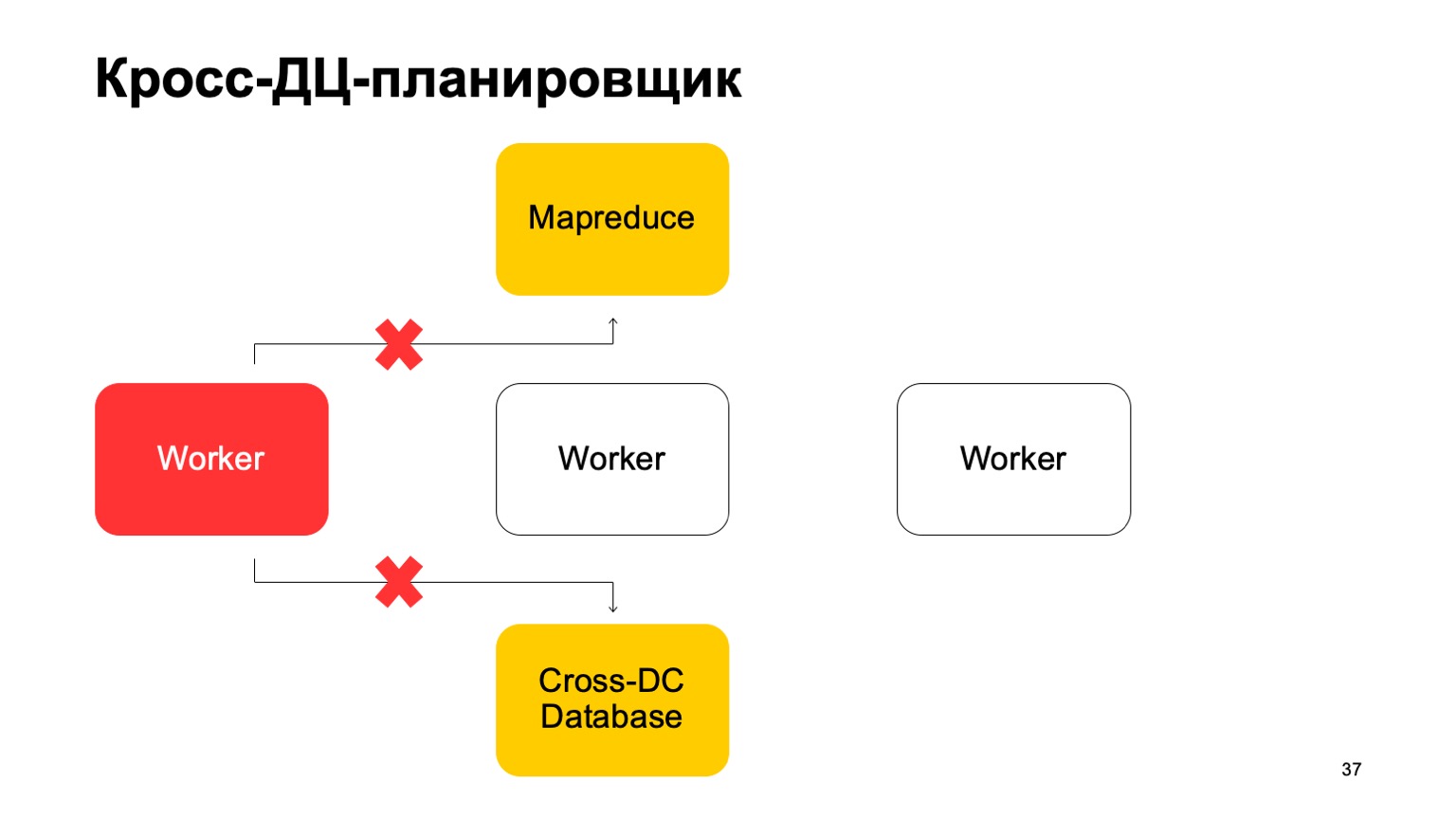
Se um trabalhador ficar indisponível, outro trabalhador tentará capturar o log, assumir o estado.
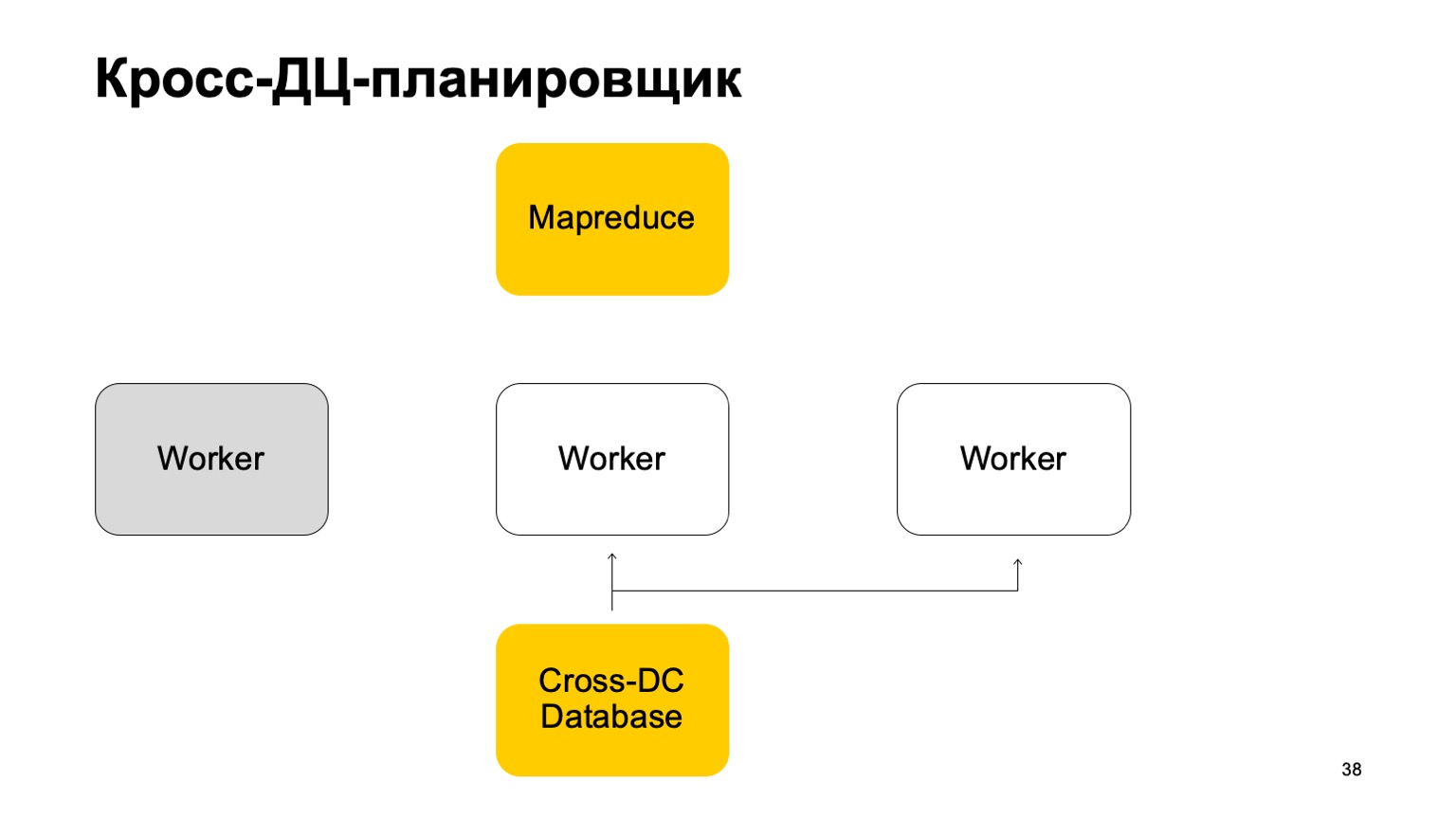
Levante-se e continue trabalhando. Continue configurando tarefas neste MapReduce.
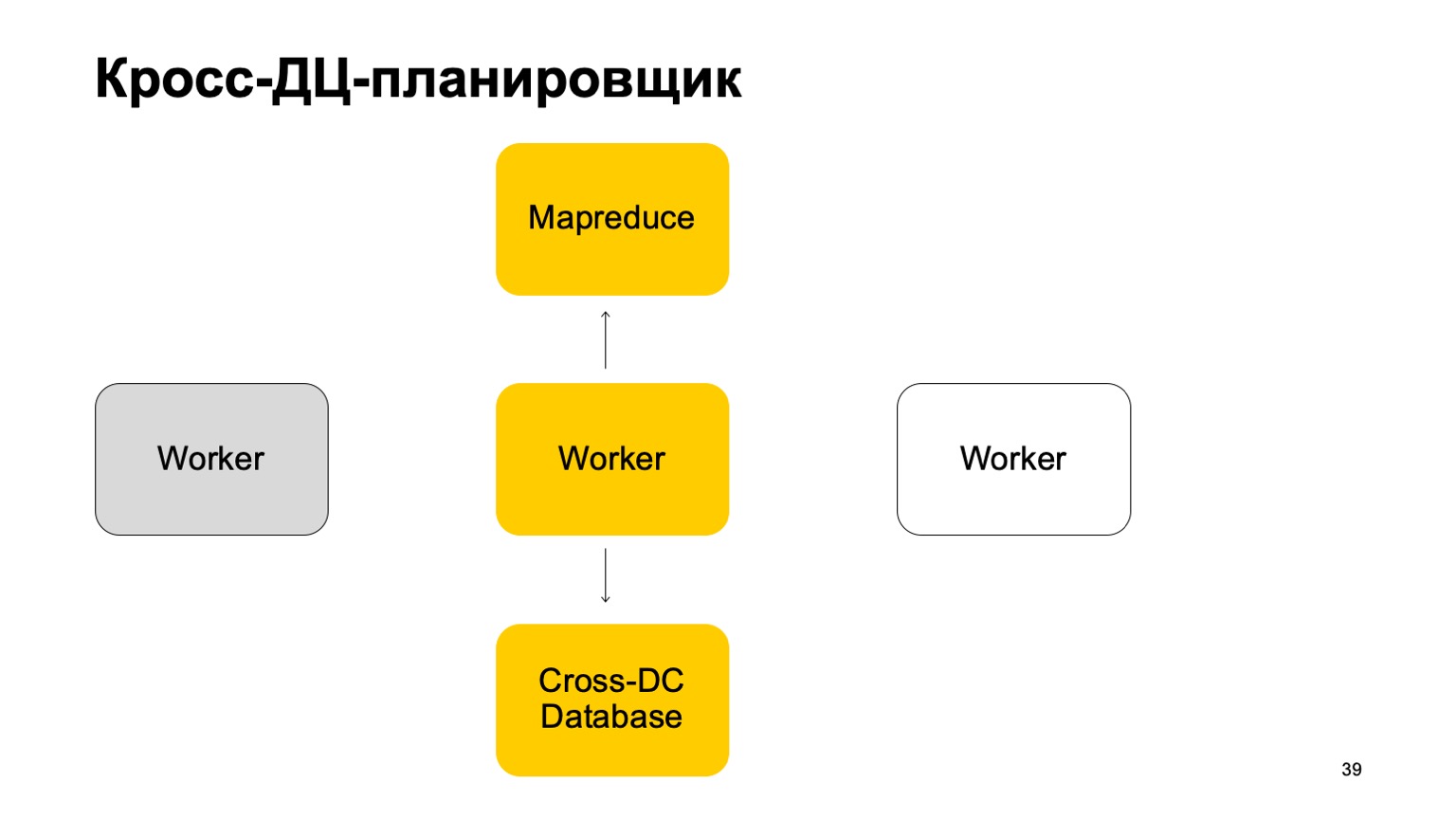
É claro que, no caso de substituir essas tarefas, algumas delas podem ser reiniciadas. Portanto, há uma propriedade muito importante para nós aqui: idempotência, a capacidade de reiniciar cada operação sem consequências.
Ou seja, todo o código deve ser escrito de tal maneira que funcione bem.

Vou lhe contar um pouco exatamente uma vez. Estamos chegando a um veredicto em conjunto, isso é muito importante. Utilizamos tecnologias que nos dão tais garantias e, naturalmente, monitoramos todas as discrepâncias, reduzimos a zero. Mesmo quando parece que isso já foi reduzido, de tempos em tempos surge um problema muito complicado que não levamos em consideração.
Instrumentos
Muito brevemente sobre as ferramentas que usamos. Manter vários antifraude para diferentes sistemas é uma tarefa difícil. Temos literalmente dezenas de serviços diferentes, precisamos de algum tipo de local único onde você possa ver o estado do trabalho deles no momento.
Aqui está nosso posto de comando, onde você pode ver o status dos clusters com os quais estamos trabalhando atualmente. Você pode alterná-los entre si, lançar uma versão etc.
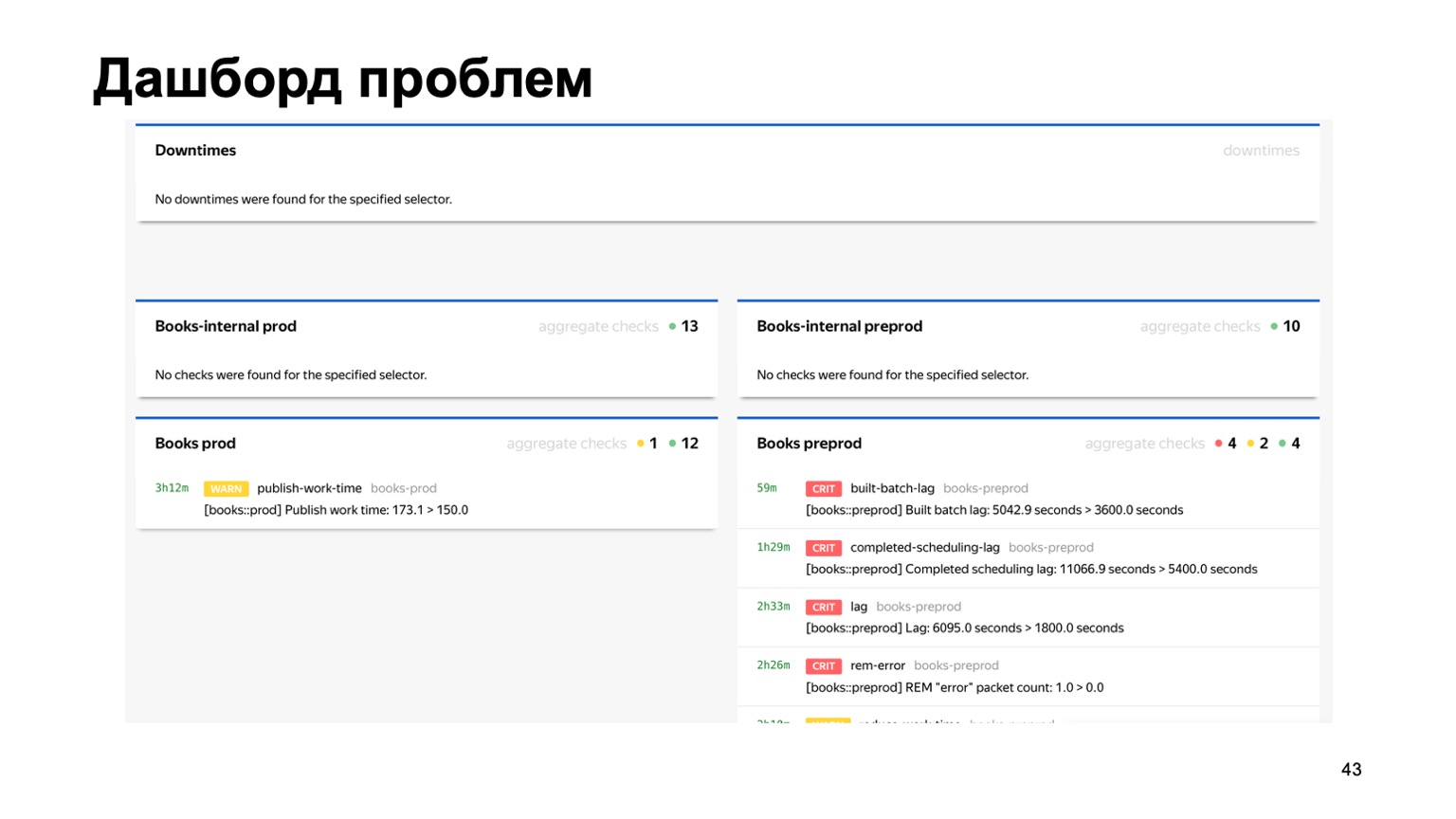
Ou, por exemplo, um painel de problemas, onde vemos imediatamente em uma página todos os problemas de todos os antifraude de diferentes serviços que estão conectados a nós. Aqui você pode ver que algo está claramente errado com nosso serviço de Livros no momento. Mas o monitoramento funcionará, e a pessoa de plantão olhará para ele.
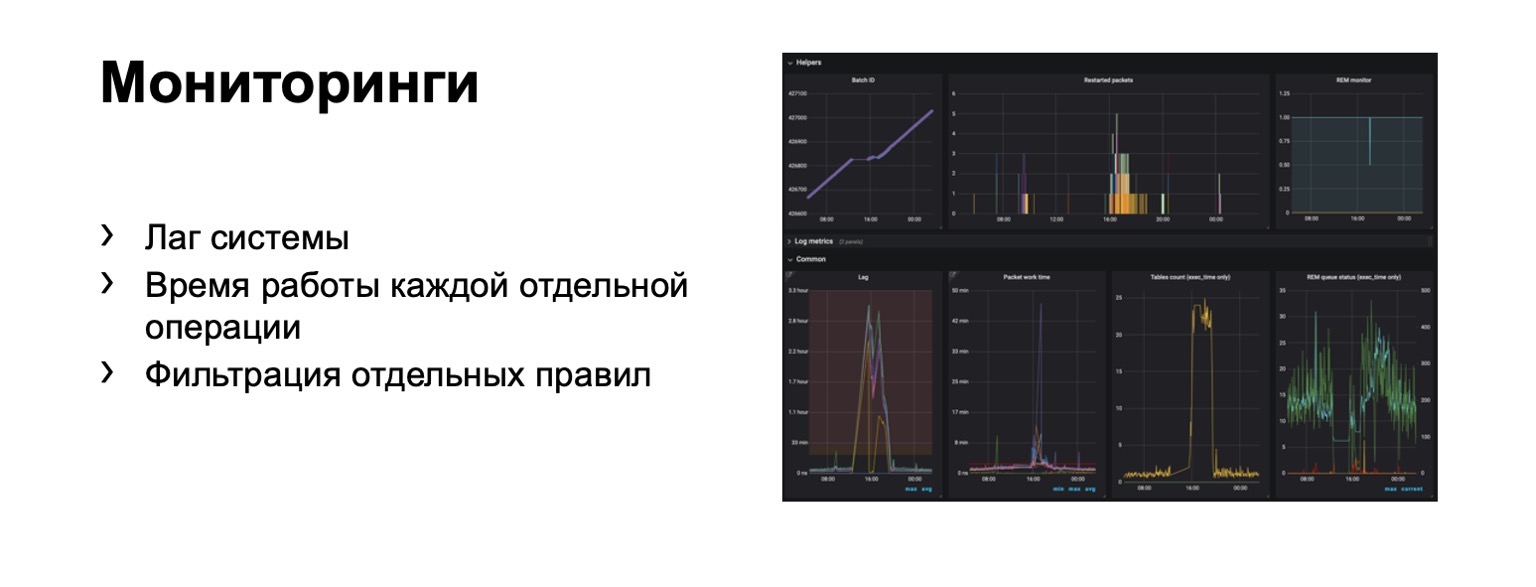
O que estamos monitorando? Obviamente, o atraso do sistema é extremamente importante. Obviamente, o tempo de execução de cada estágio individual e, claro, a filtragem de regras individuais. Este é um requisito comercial.
Centenas de gráficos e painéis aparecem. Por exemplo, neste painel, você pode ver que o contorno estava ruim o suficiente agora que tivemos um atraso significativo.
Rapidez
Vou falar sobre a transição para a parte online. O problema aqui é que o atraso em um circuito completo pode chegar a alguns minutos. Está no esboço do MapReduce. Em alguns casos, precisamos proibir, detectar fraudadores mais rapidamente.
O que poderia ser? Por exemplo, nosso serviço agora tem a capacidade de comprar livros. E, ao mesmo tempo, um novo tipo de fraude de pagamento apareceu. Você precisa reagir a isso mais rapidamente. Surge a questão - como transferir todo esse esquema, idealmente preservando ao máximo a linguagem de interação familiar aos analistas? Vamos tentar transferi-lo "para a testa".
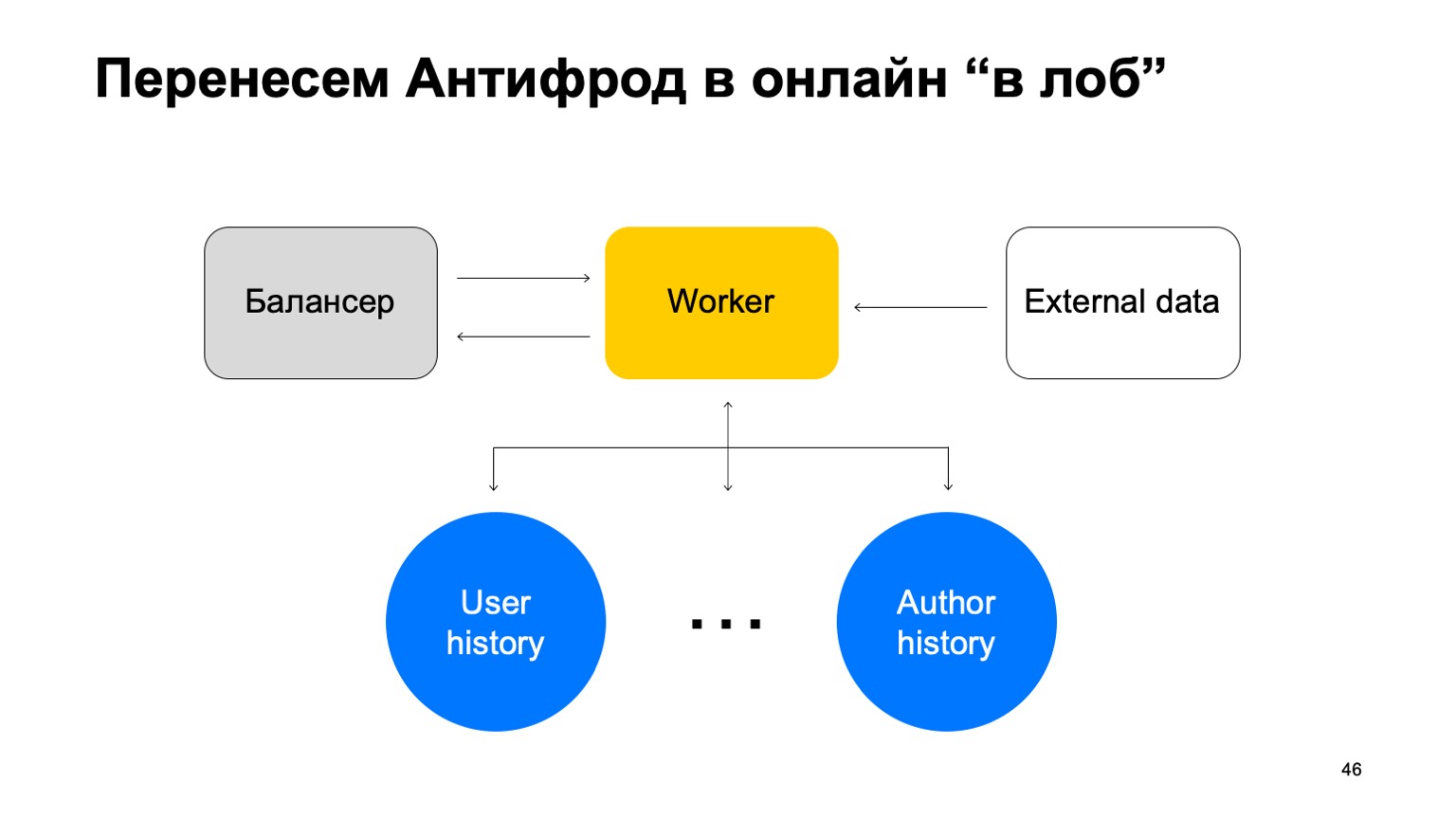
Digamos que temos um balanceador com dados do serviço e um certo número de trabalhadores para os quais compartilhamos dados do balanceador. Existem dados externos que usamos aqui, eles são muito importantes e um conjunto dessas histórias. Deixe-me lembrá-lo de que cada uma dessas histórias é diferente para diferentes reduções, porque possui chaves diferentes.
Nesse esquema, o seguinte problema pode surgir.
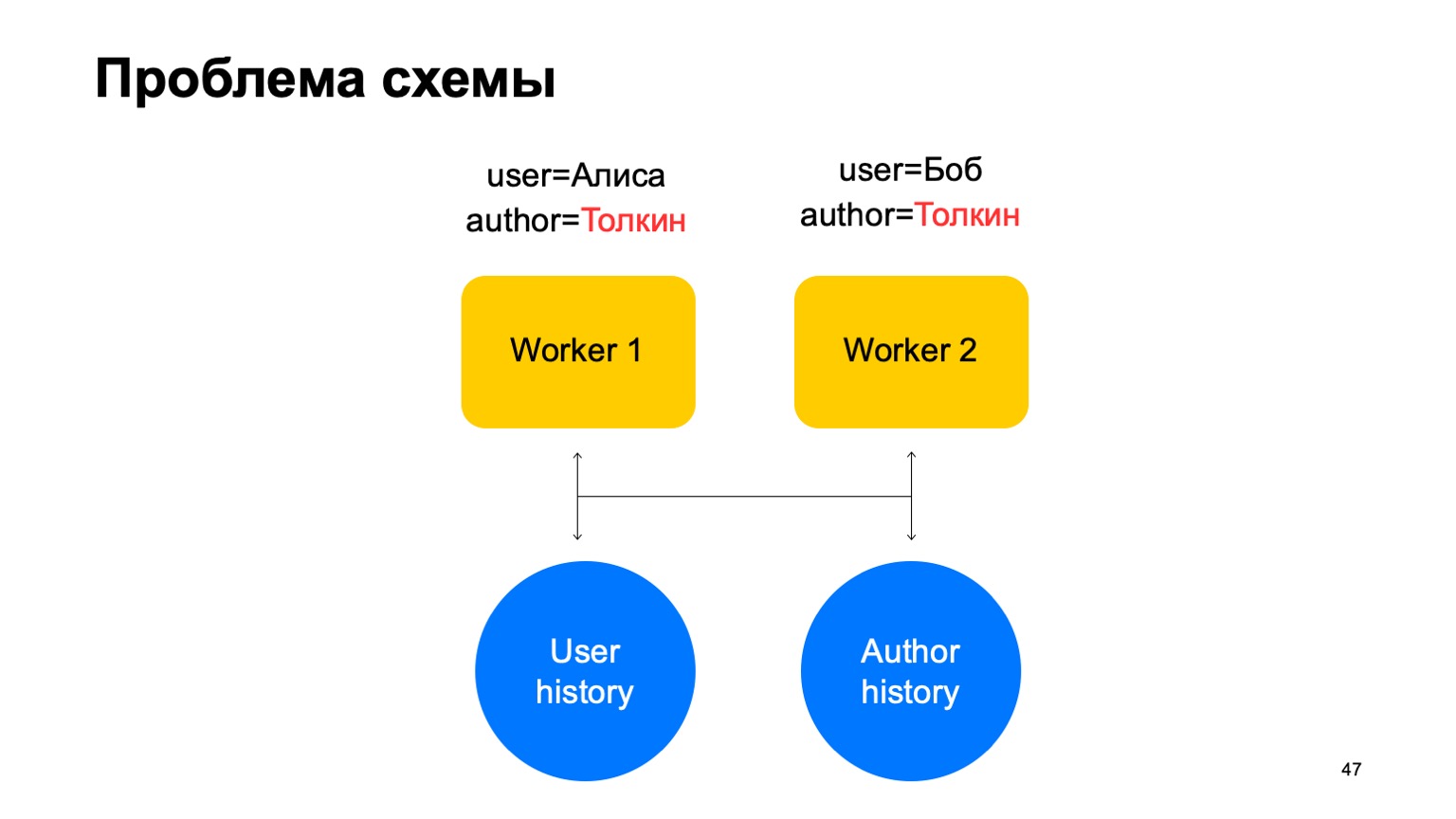
Digamos que temos dois eventos em nosso trabalhador. Nesse caso, com qualquer compartilhamento desses trabalhadores, uma situação pode surgir quando uma chave chega a trabalhadores diferentes. Neste caso, este é o autor Tolkien, ele entrou em dois trabalhadores.
Em seguida, lemos os dados desse armazenamento de valor-chave para os dois funcionários da história, vamos atualizá-los de maneiras diferentes e uma corrida surgirá quando tentarmos escrever de volta.
Solução: Vamos supor que a leitura e a gravação possam ser separadas, que a escrita possa ocorrer com um pequeno atraso. Isso geralmente não é muito importante. Por um pequeno atraso, quero dizer unidades de segundos aqui. Isso é importante, em particular, porque nossa implementação desse armazenamento de valores-chave leva mais tempo para gravar dados do que lê-los.
Atualizaremos as estatísticas com um atraso. Em média, isso funciona mais ou menos bem, pois manteremos o estado em cache nas máquinas.
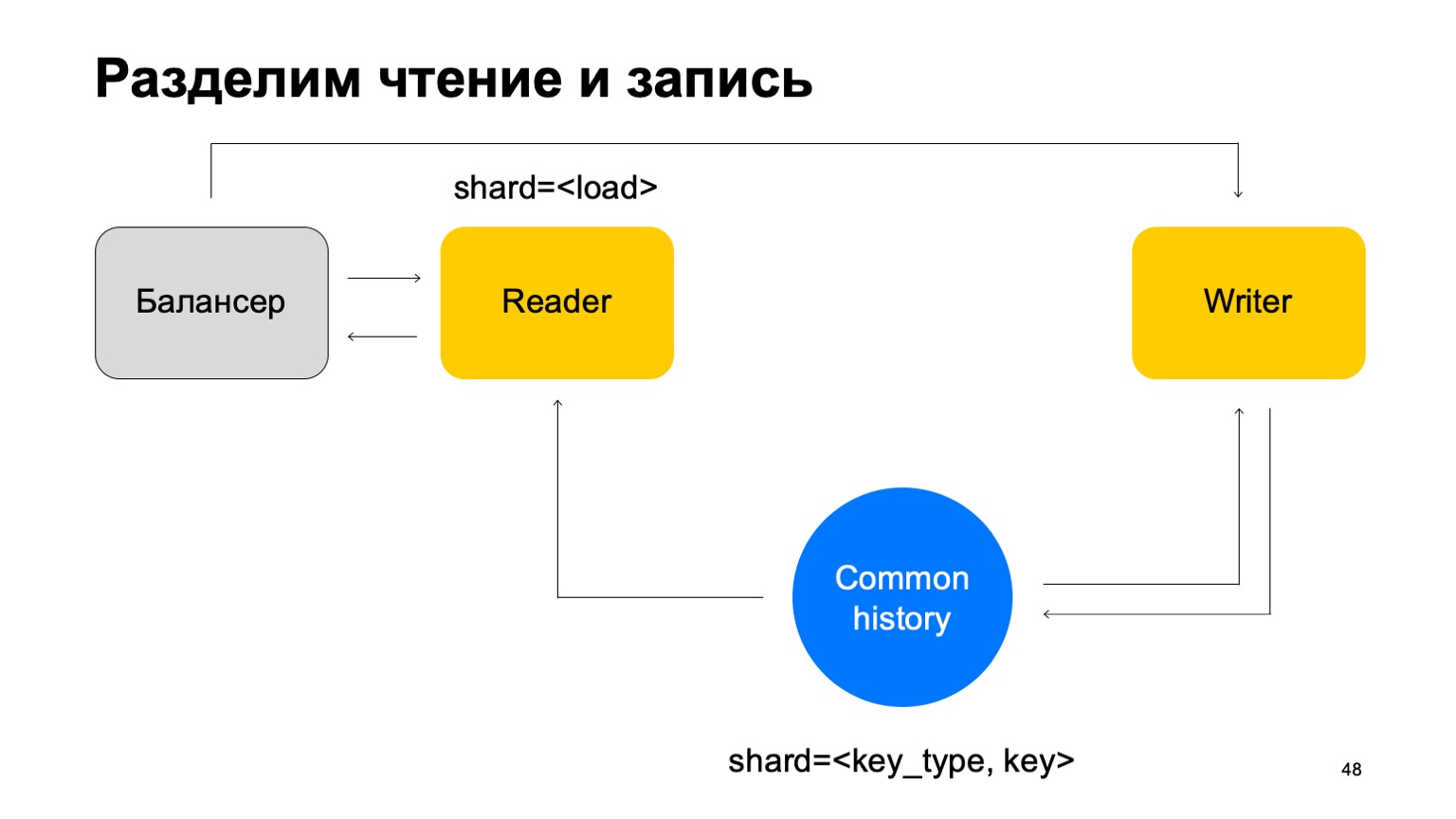
E outra coisa. Para simplificar, vamos mesclar essas histórias em uma e anotá-las de acordo com o tipo e a chave do corte. Temos algum tipo de história comum.
Em seguida, adicionaremos o balanceador novamente, adicionaremos as máquinas dos leitores, que podem ser fragmentadas de qualquer maneira - por exemplo, simplesmente por carga. Eles simplesmente lerão esses dados, aceitarão os veredictos finais e os devolverão ao balanceador.
Nesse caso, precisamos de um conjunto de máquinas de gravadores para as quais esses dados serão enviados diretamente. Os escritores atualizarão a história de acordo. Mas aqui ainda surge o problema, sobre o qual escrevi acima. Vamos mudar a estrutura do escritor um pouco então.
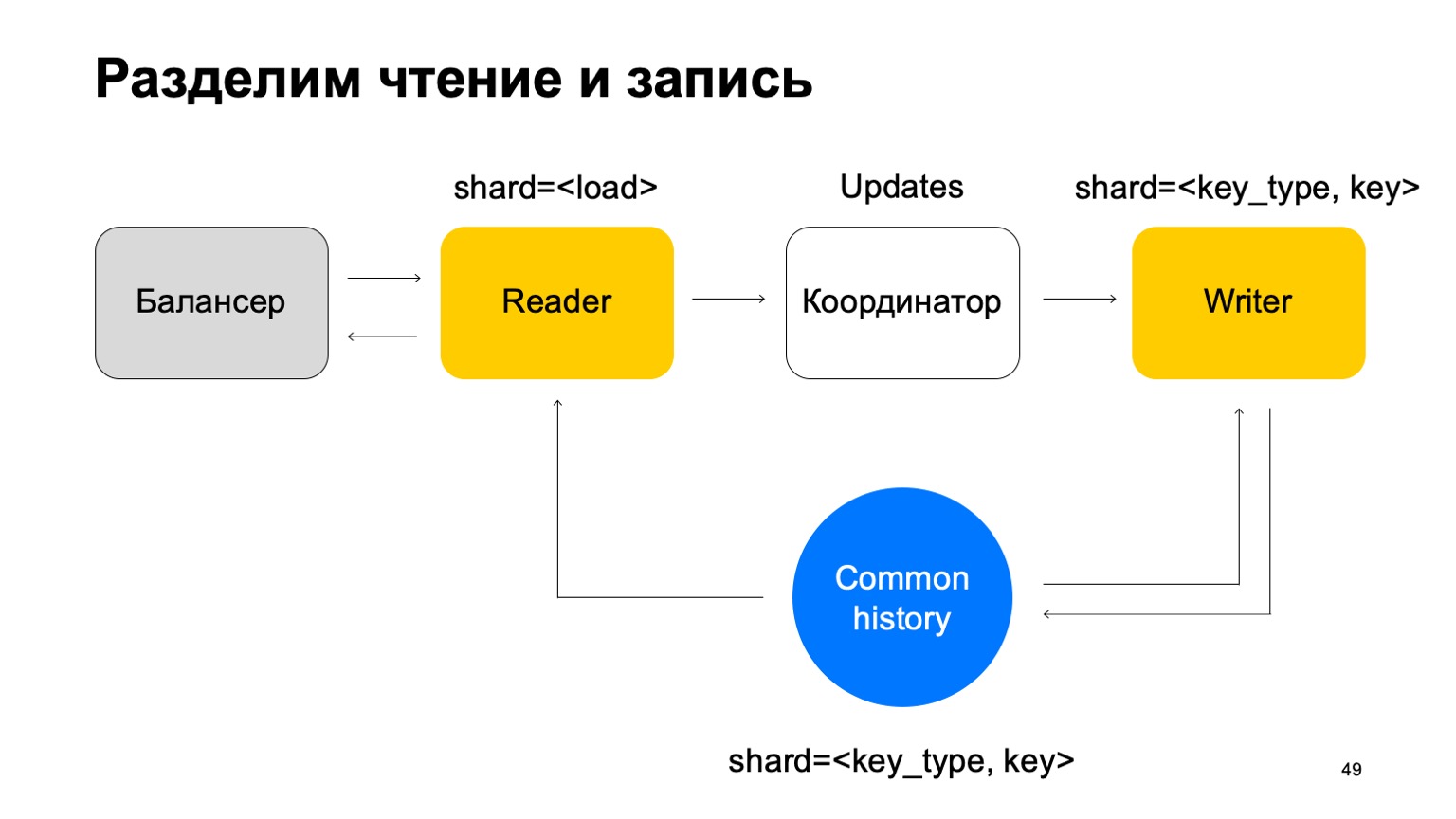
Vamos fazer com que ele seja compartilhado da mesma maneira que a história - pelo tipo e valor da chave. Nesse caso, quando seu sharding for igual ao histórico, não teremos o problema mencionado acima.
Aqui sua missão muda. Ele não aceita mais veredictos. Em vez disso, ele apenas aceita atualizações do Reader, as mistura e as aplica corretamente ao histórico.
É claro que aqui é necessário um componente, um coordenador que distribui essas atualizações entre leitores e escritores.
A isso, é claro, é adicionado o fato de que o trabalhador precisa manter um cache atualizado. Como resultado, acontece que somos responsáveis por centenas de milissegundos, às vezes menos, e atualizamos as estatísticas em um segundo. Em geral, funciona bem, para serviços é suficiente.

O que conseguimos? Os analistas começaram a fazer seus trabalhos mais rapidamente e da mesma maneira para todos os serviços. Isso melhorou a qualidade e a conectividade de todos os sistemas. Você pode reutilizar dados entre antifraude de diferentes serviços, e novos serviços obtêm antifraude de alta qualidade rapidamente.

Um par de pensamentos no final. Se você escrever algo assim, pense imediatamente na conveniência dos analistas em termos de suporte e extensibilidade desses sistemas. Torne tudo configurável, você precisa. Às vezes, as propriedades cross-DC e exatamente uma vez são difíceis de obter, mas podem. Se você acha que já conseguiu, verifique novamente. Agradecimentos para sua atenção.