
Chegou o momento da publicação da segunda parte, hoje continuaremos desenvolvendo nosso editor de código e adicionando a ele o preenchimento automático e o realce de erros, além de falarmos sobre o porquê de qualquer editor de código
EditTextnão ficar para trás.
Antes de ler mais, recomendo fortemente que você leia a primeira parte .
Introdução
 Primeiro, vamos lembrar de onde paramos na última parte . Escrevemos um destaque de sintaxe otimizado que analisa o texto em segundo plano e colore apenas sua parte visível, além de numeração de linha adicional (embora sem quebras de linha no Android, mas ainda assim).
Primeiro, vamos lembrar de onde paramos na última parte . Escrevemos um destaque de sintaxe otimizado que analisa o texto em segundo plano e colore apenas sua parte visível, além de numeração de linha adicional (embora sem quebras de linha no Android, mas ainda assim).
Nesta parte, adicionaremos a conclusão do código e o realce do erro.
Conclusão de código
Primeiro, vamos imaginar como deve funcionar:
- Usuário escreve uma palavra
- Depois de inserir os primeiros N caracteres, uma janela aparece com dicas
- Quando você clica na dica, a palavra é automaticamente "impressa"
- A janela com dicas é fechada e o cursor é movido para o final da palavra
- Se o usuário digitar a palavra exibida na dica de ferramenta, a janela com dicas deverá fechar automaticamente
Não parece nada? O Android já possui um componente com exatamente a mesma lógica -
MultiAutoCompleteTextViewportanto PopupWindow, não precisamos escrever muletas conosco (elas já foram escritas para nós).
O primeiro passo é mudar o pai da nossa classe:
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
Agora precisamos escrever o
ArrayAdapterque exibirá os resultados encontrados. O código completo do adaptador não estará disponível; exemplos de implementação podem ser encontrados na Internet. Mas vou parar no momento com a filtragem.
Para
ArrayAdapterentender quais dicas precisam ser exibidas, precisamos substituir o método getFilter:
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf<String>()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() //
addAll(suggestions)
notifyDataSetChanged()
}
}
}
E, no método,
performFilteringpreencha a lista suggestionsde palavras com base na palavra que o usuário começou a inserir (contida em uma variável constraint).
Onde obter os dados antes de filtrar?
Tudo depende de você - você pode usar algum tipo de intérprete para selecionar apenas opções válidas ou digitalizar o texto inteiro quando abrir o arquivo. Para simplificar o exemplo, usarei uma lista pronta de opções de preenchimento automático:
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() //
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
A lógica de filtragem aqui é bastante primitiva, percorremos a lista inteira e, ignorando o caso, comparamos o início da string.
Instalou o adaptador, escreva o texto - ele não funciona. O que há de errado? No primeiro link no Google, encontramos uma resposta que diz que esquecemos de instalar
Tokenizer.
Para que serve o Tokenizer?
Em termos simples,
Tokenizerajuda a MultiAutoCompleteTextViewentender após o caractere digitado que a palavra entrada pode ser considerada completa. Ele também possui uma implementação pronta na forma de CommaTokenizerseparar palavras em vírgulas, que neste caso não nos convém.
Bem, como
CommaTokenizernão estamos satisfeitos, escreveremos os nossos:
Tokenizer personalizado
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
Vamos descobrir:
TOKEN - uma string com caracteres que separam uma palavra da outra. Nos métodos findTokenStarte findTokenEndpercorremos o texto em busca desses símbolos muito separados. O método terminateTokenpermite que você retorne um resultado modificado, mas não precisamos dele; portanto, apenas devolvemos o texto inalterado.
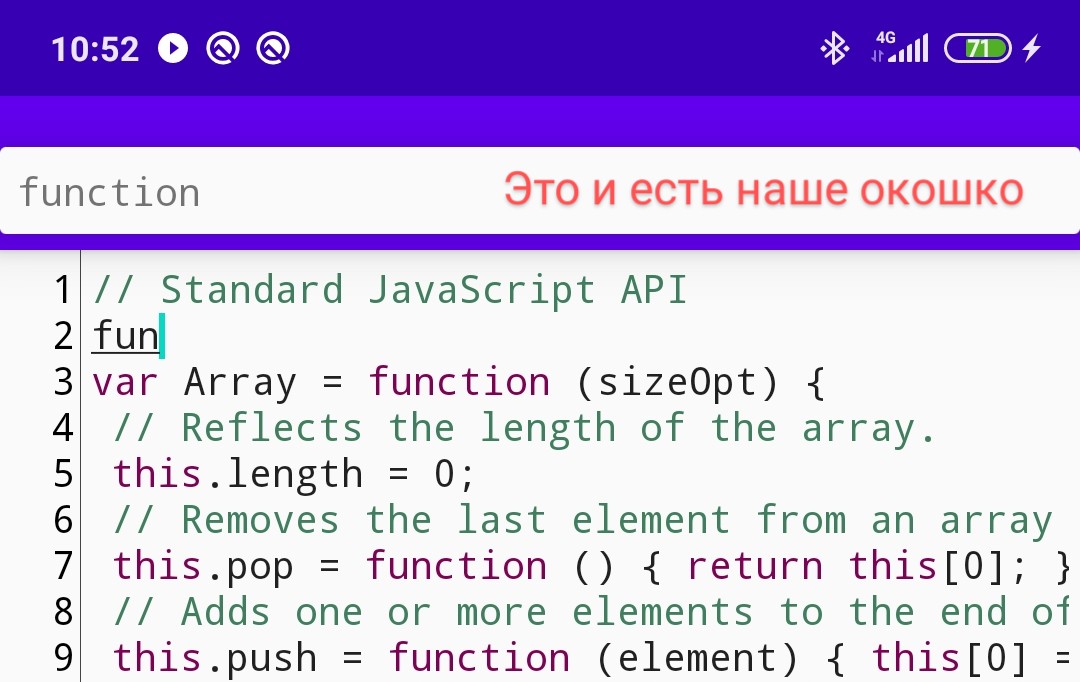
Também prefiro adicionar um atraso de entrada de 2 caracteres antes de exibir a lista:
textProcessor.threshold = 2Instale, execute, escreva texto - funciona! Mas, por alguma razão, a janela com avisos se comporta de maneira estranha - é exibida em largura total, sua altura é pequena e, em teoria, deve aparecer sob o cursor, como vamos corrigi-lo?
Corrigindo falhas visuais
É aqui que a diversão começa, porque a API nos permite alterar não apenas o tamanho da janela, mas também sua posição.
Primeiro, vamos decidir o tamanho. Na minha opinião, a opção mais conveniente seria uma janela com metade da altura e largura da tela, mas como nosso tamanho
Viewmuda dependendo do estado do teclado, selecionaremos os tamanhos no método onSizeChanged:
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
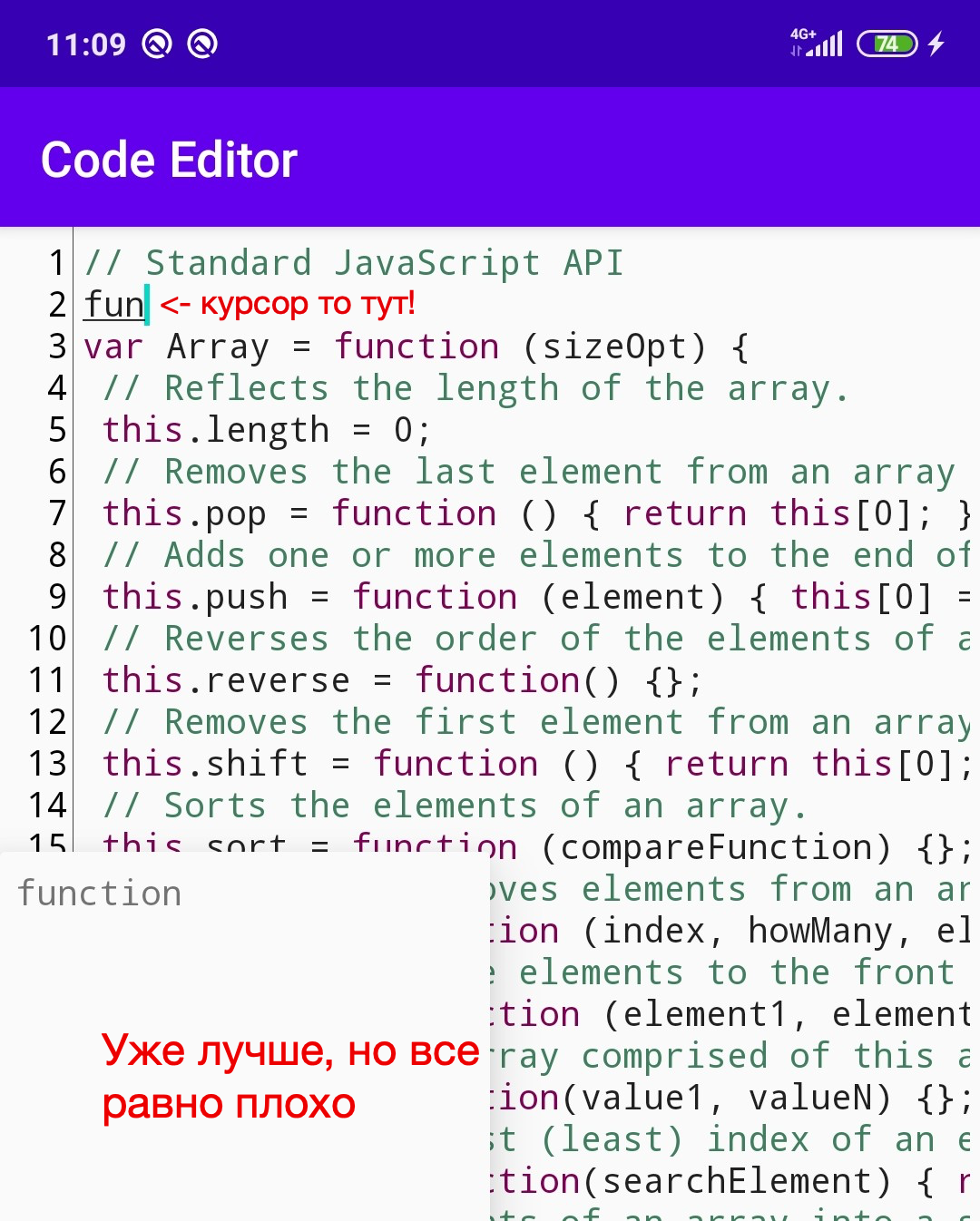 Parece melhor, mas não muito. Queremos que a janela apareça sob o cursor e se mova durante a edição.
Parece melhor, mas não muito. Queremos que a janela apareça sob o cursor e se mova durante a edição.
Se tudo for bem simples ao se mover ao longo de X - pegamos a coordenada do início da letra e configuramos esse valor para
dropDownHorizontalOffset, então escolher a altura será mais difícil.
Google sobre as propriedades das fontes, você pode encontrar este post . A figura que o autor anexou mostra claramente quais propriedades podemos usar para calcular a coordenada vertical.

Agora vamos escrever um método que chamaremos quando o texto mudar para
onTextChanged:
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) //
val x = layout.getPrimaryHorizontal(selectionStart) //
val y = layout.getLineBaseline(line) // baseline
val offsetHorizontal = x + gutterWidth //
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY ""
dropDownVerticalOffset = offsetVertical
}
Parece que eles não esqueceram nada - o deslocamento X funciona, mas o deslocamento Y é calculado incorretamente. Isso ocorre porque não especificamos
dropDownAnchorna marcação:
android:dropDownAnchor="@id/toolbar"Ao especificar
Toolbara qualidade, dropDownAnchorinformamos ao widget que a lista suspensa será exibida abaixo dele.
Agora, se começarmos a editar o texto, tudo funcionará, mas com o tempo perceberemos que, se a janela não couber no cursor, ela é arrastada para cima com um recuo enorme, que parece feio. É hora de escrever uma muleta:

val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
Não precisamos alterar o recuo se a soma for
offsetVertical + dropDownHeightmenor que a altura visível da tela, pois, neste caso, a janela é colocada sob o cursor. Porém, se ainda houver mais, subtraímos o recuo dropDownHeight- para que ele caia sobre o cursor sem um recuo enorme que o próprio widget adiciona.
PS Você pode ver o teclado piscando no gif e, para ser sincero, não sei como consertá-lo; portanto, se você tiver uma solução, escreva.
Erros de destaque
Com o realce do erro, tudo é muito mais simples do que parece, porque nós mesmos não podemos detectar diretamente erros de sintaxe no código - usaremos uma biblioteca de analisadores de terceiros. Como estou escrevendo um editor para JavaScript, minha escolha foi no Rhino , um popular mecanismo JavaScript testado pelo tempo e ainda com suporte.
Como vamos analisar?
Iniciar o Rhino é uma operação bastante complicada, portanto, executar o analisador após cada caractere inserido (como fizemos com o destaque) não é uma opção. Para resolver esse problema, usarei a biblioteca RxBinding e, para aqueles que não desejam arrastar o RxJava para o projeto, tente opções semelhantes .
O operador
debouncenos ajudará a alcançar o que queremos e, se você não estiver familiarizado com ele, aconselho a ler este artigo .
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
//
}
.disposeOnFragmentDestroyView()
Agora vamos escrever um modelo que o analisador retornará para nós:
data class ParseResult(val exception: RhinoException?)Sugiro usar a seguinte lógica: se nenhum erro for encontrado,
exceptionhaverá null. Caso contrário, obteremos um objeto RhinoExceptionque contém todas as informações necessárias - número da linha, mensagem de erro, StackTrace etc.
Bem, na verdade, a análise em si:
// !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
Entendimento:
O mais importante aqui é o método
evaluateString- ele permite que você execute o código que passamos como uma string sourceCode. O fileNamenome do arquivo é indicado em - será exibido com erros, a unidade é o número da linha para começar a contar, o último argumento é o domínio de segurança, mas como não precisamos dele, definimos null.
optimizationLevel e maximumInterpreterStackDepth
Um parâmetro
optimizationLevelcom um valor de 1 a 9 permite que você habilite certas “otimizações” de código (análise de fluxo de dados, análise de fluxo de tipo etc.), que transformarão uma simples verificação de erro de sintaxe em uma operação que consome muito tempo, e não precisamos dela.
Se você usá-lo com o valor 0 , todas essas "otimizações" não serão aplicadas; no entanto, se bem entendi, o Rhino ainda utilizará alguns dos recursos que não são necessários para a simples verificação de erros, o que significa que não nos convém.
Resta apenas um valor negativo - ao especificar -1 , ativamos o modo "intérprete", que é exatamente o que precisamos. A documentação diz que esta é a maneira mais rápida e econômica de executar o Rhino.
O parâmetro
maximumInterpreterStackDepthpermite limitar o número de chamadas recursivas.
Vamos imaginar o que acontece se você não especificar este parâmetro:
- O usuário escreverá o seguinte código:
function recurse() { recurse(); } recurse(); - O Rhino executará o código e em um segundo nosso aplicativo falhará
OutOfMemoryError. O fim.
Exibindo erros
Como eu disse anteriormente, assim que recebermos o que
ParseResultcontém RhinoException, teremos todos os dados necessários para exibir, incluindo o número da linha - basta chamar o método lineNumber().
Agora vamos escrever a extensão de linha ondulada vermelha que copiei no StackOverflow . Há muito código, mas a lógica é simples - desenhe duas pequenas linhas vermelhas em ângulos diferentes.
ErrorSpan.kt
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
Agora você pode escrever um método para instalar o span na linha do problema:
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
É importante lembrar que, como o resultado vem com um atraso, o usuário pode ter tempo para apagar algumas linhas de código e, em seguida,
lineNumberpode se tornar inválido.
 Portanto, para não receber,
Portanto, para não receber, IndexOutOfBoundsExceptionadicionamos um cheque logo no início. Bem, então, de acordo com o esquema familiar, calculamos o primeiro e o último caractere da string e depois definimos o intervalo.
O principal é não esquecer de limpar o texto das extensões já definidas em
afterTextChanged:
fun clearErrorSpans() {
val spans = text.getSpans<ErrorSpan>(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
Por que os editores de código ficam atrasados?
Em dois artigos, escrevemos um bom editor de código herdando
EditTexte MultiAutoCompleteTextView, mas não podemos nos orgulhar de desempenho ao trabalhar com arquivos grandes.
Se você abrir o mesmo TextView.java para 9k + linhas de código, qualquer editor de texto escrito de acordo com o mesmo princípio que o nosso ficará.
P: Por que o QuickEdit não fica para trás então?
A: Porque sob o capô, ele não usa nem
EditText, nem TextView.
Recentemente, os editores de código no CustomView estão ganhando popularidade ( aqui e ali , bem, ou aqui e ali, existem muitos). Historicamente, o TextView tem muita lógica redundante que os editores de código não precisam. As primeiras coisas que vêm à mente são o preenchimento automático , Emoji , Drawables compostos , links clicáveis etc.
Se eu entendi direito, os autores das bibliotecas simplesmente se livraram de tudo isso, como resultado, obtiveram um editor de texto capaz de trabalhar com arquivos de um milhão de linhas sem muita carga no thread da interface do usuário. (Embora eu possa estar parcialmente enganado, não entendi muito a fonte).
Há outra opção, mas na minha opinião menos atraente - editores de código no WebView ( aqui e ali, existem muitos deles também). Não gosto deles porque a interface do usuário no WebView parece pior que a nativa e eles também perdem para os editores no CustomView em termos de desempenho.
Conclusão
Se sua tarefa é escrever um editor de código e chegar ao topo do Google Play, não perca tempo e pegue uma biblioteca pronta no CustomView. Se você deseja obter uma experiência única, escreva tudo usando widgets nativos.
Também deixarei um link para o código-fonte do meu editor de código no GitHub , onde você encontrará não apenas os recursos que falei nesses dois artigos, mas também muitos outros que foram deixados sem atenção.
Obrigado!