
Obviamente, o NSPK não é uma startup, mas essa atmosfera prevaleceu na empresa nos primeiros anos de sua existência, e esses foram anos muito interessantes. Meu nome é Dmitry Kornyakov , apoio a infraestrutura Linux com requisitos de alta disponibilidade há mais de 10 anos. Ele se juntou à equipe do NSPK em janeiro de 2016 e, infelizmente, não viu o começo da existência da empresa, mas veio no estágio de grandes mudanças.
Em geral, podemos dizer que nossa equipe fornece 2 produtos para a empresa. O primeiro é a infraestrutura. O correio deve ser enviado, o DNS deve funcionar e os controladores de domínio devem permitir servidores em que não caem. O cenário de TI da empresa é enorme! Estes são sistemas críticos para negócios e missão; os requisitos de disponibilidade para alguns são de 99.999. O segundo produto são os próprios servidores, físicos e virtuais. Os existentes precisam ser monitorados, e novos são regularmente fornecidos a clientes de vários departamentos. Neste artigo, quero me concentrar em como desenvolvemos a infraestrutura responsável pelo ciclo de vida dos servidores.
O início do caminho
No início do caminho, nossa pilha de tecnologias era assim: controladores de domínio
OS CentOS 7
FreeIPA
Automation - Ansible (+ Tower), Cobbler
Tudo isso estava localizado em três domínios, espalhados por vários data centers. Em um data center - sistemas de escritório e locais de teste, no restante, PROD.
Em algum momento, a criação dos servidores ficou assim:
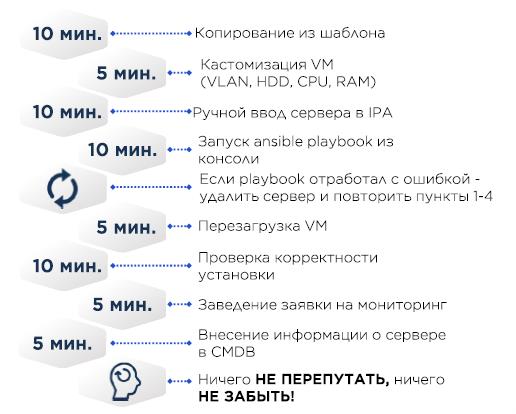
No modelo mínimo do VM CentOS e no mínimo necessário, como o /etc/resolv.conf correto, o restante ocorre através do Ansible.
CMDB - Excel.
Se o servidor for físico, em vez de copiar a máquina virtual, o sistema operacional foi instalado usando o Cobbler - os endereços MAC do servidor de destino são adicionados à configuração do Cobbler, o servidor recebe um endereço IP via DHCP e o SO é derramado.
No começo, tentamos fazer algum tipo de gerenciamento de configuração no Cobbler. Mas com o tempo, isso começou a trazer problemas com a portabilidade das configurações para outros data centers e para o código Ansible para preparar a VM.
Naquela época, muitos de nós percebemos o Ansible como uma extensão conveniente do Bash e não economizamos em construções usando a concha sed. Em geral Bashsible. Isso levou ao fato de que, se por algum motivo o manual de instruções não funcionasse no servidor, era mais fácil excluir o servidor, corrigi-lo e executar novamente. De fato, não havia versão de script, portabilidade de configuração também.
Por exemplo, queríamos alterar algumas configurações em todos os servidores:
- Alteramos a configuração nos servidores existentes no segmento lógico / data center. Às vezes, não da noite para o dia - os requisitos de disponibilidade e a lei de grandes números não permitem que todas as alterações sejam aplicadas de uma só vez. E algumas mudanças são potencialmente destrutivas e exigem a reinicialização de tudo - dos serviços ao próprio sistema operacional.
- Fixação no Ansible
- Fixação no Sapateiro
- Repita N vezes para cada segmento lógico / data center
Para que todas as mudanças ocorram sem problemas, muitos fatores tiveram que ser considerados e as mudanças estão ocorrendo constantemente.
- Refatorando código ansible, arquivos de configuração
- Alterando as melhores práticas internas
- Alterações após a análise de incidentes / acidentes
- Alteração dos padrões de segurança, internos e externos. Por exemplo, o PCI DSS é atualizado com novos requisitos todos os anos
Crescimento da infraestrutura e o início do caminho O
número de servidores / domínios lógicos / datacenters cresceu e, com eles, o número de erros nas configurações. Em algum momento, chegamos a três direções, nas quais precisamos desenvolver o gerenciamento de configuração:
- Automação. Na medida do possível, o fator humano em operações repetitivas deve ser evitado.
- . , . . – , .
- configuration management.
Resta adicionar algumas ferramentas.
Escolhemos o GitLab CE como nosso repositório de código, principalmente para os módulos CI / CD embutidos.
Cofre de segredos - Cofre de Hashicorp, incl. para a ótima API.
Testando configurações e funções ansible - Molecule + Testinfra. Os testes são executados muito mais rapidamente se estiverem conectados ao mitogênio ansível. Paralelamente, começamos a escrever nosso próprio CMDB e um orquestrador para implantação automática (na imagem acima do Cobbler), mas essa é uma história completamente diferente, que meu colega e o principal desenvolvedor desses sistemas contará no futuro.
Nossa escolha:
Molécula + Testinfra
Ansible + Torre + AWX Server
World + DITNET (In-house)
Sapateiro
Gitlab + Corredor do
GitLab Hashicorp Vault

Falando de papéis ansíveis. No início, estava sozinho, depois de várias refatorações, existem 17. Eu recomendo dividir o monólito em funções idempotentes, que podem ser executadas separadamente, você pode adicionar tags adicionalmente. Dividimos os papéis por funcionalidade - rede, registro, pacotes, hardware, molécula etc. Em geral, aderimos à estratégia abaixo. Não insisto que essa seja a única verdade, mas funcionou para nós.
- Copiar servidores da "imagem de ouro" é ruim!
A principal desvantagem é que você não sabe exatamente em que estado as imagens estão agora e que todas as alterações ocorrerão em todas as imagens em todos os farms de virtualização. - Use os arquivos de configuração padrão no mínimo e concorde com outros departamentos sobre os arquivos principais do sistema pelos quais você é responsável , por exemplo:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Nossa implementação
Portanto, os papéis ansíveis estavam prontos, modelados e verificados pelos linters. E até gits são criados em todos os lugares. Mas a questão da entrega confiável de código para diferentes segmentos permaneceu em aberto. Decidimos sincronizar com scripts. É assim:

Após a mudança, o CI é iniciado, um servidor de teste é criado, as funções são roladas, testadas com uma molécula. Se tudo estiver ok, o código vai para o ramo de produção. Mas não estamos aplicando o novo código aos servidores existentes na máquina. Esse é um tipo de rolha necessária para a alta disponibilidade de nossos sistemas. E quando a infraestrutura se torna enorme, a lei de grandes números entra em jogo - mesmo se você tiver certeza de que a mudança é inofensiva, isso pode levar a tristes conseqüências.
Há também muitas opções para criar servidores. Acabamos escolhendo scripts python personalizados. E para o IC ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"É para isso que chegamos, o sistema continua a viver e a se desenvolver.
- 17 funções possíveis para configurar o servidor. Cada uma das funções foi projetada para resolver uma tarefa lógica separada (log, auditoria, autorização do usuário, monitoramento etc.).
- Teste de função. Molécula + TestInfra.
- Desenvolvimento próprio: CMDB + Orchestrator.
- Tempo de criação do servidor ~ 30 minutos, automatizado e praticamente independente da fila de tarefas.
- O mesmo estado / nome da infraestrutura em todos os segmentos - playbooks, repositórios, elementos de virtualização.
- Verificação diária do status dos servidores com geração de relatórios sobre discrepâncias com o padrão.
Espero que minha história seja útil para aqueles que estão no início da jornada. Qual pilha de automação você está usando?