
Na primeira parte , falei sobre o que são os simuladores em geral e também sobre os níveis de modelagem. Agora, com base nesse conhecimento, proponho me aprofundar um pouco e falar sobre a simulação de plataforma completa, como montar trilhas, o que fazer com elas posteriormente, bem como a emulação microarquitetônica ciclo a ciclo.
Simulador de plataforma completa ou "Um em campo não é um guerreiro"
Se você precisar investigar a operação de um dispositivo específico, por exemplo, uma placa de rede ou gravar um firmware ou driver para esse dispositivo, esse dispositivo poderá ser modelado separadamente. No entanto, usá-lo isoladamente do restante da infraestrutura não é muito conveniente. Para iniciar o driver correspondente, você precisará de um processador central, memória, acesso ao barramento para transferência de dados e assim por diante. Além disso, o driver precisa de um sistema operacional (SO) e pilha de rede. Além disso, um gerador de pacotes e um servidor de resposta separados podem ser necessários.
O simulador de plataforma completa cria um ambiente para a execução de uma pilha de software completa, que inclui tudo, desde o BIOS e o gerenciador de inicialização até o próprio sistema operacional e seus vários subsistemas, como a mesma pilha de rede, drivers e aplicativos em nível de usuário. Para isso, implementa modelos de software da maioria dos dispositivos de computador: processador e memória, disco, dispositivos de entrada e saída (teclado, mouse, monitor) e a mesma placa de rede.
Abaixo está um diagrama de blocos do chipset x58 da Intel. Em um simulador de computador de plataforma completa neste chipset, é necessário implementar a maioria dos dispositivos listados, incluindo aqueles localizados dentro do IOH (Hub de Entrada / Saída) e ICH (Hub do Controlador de Entrada / Saída), que não são desenhados em detalhes no diagrama de blocos. Embora, como mostra a prática, não haja tão poucos dispositivos que não sejam usados pelo software que vamos executar. Modelos de tais dispositivos não precisam ser criados.

Na maioria das vezes, simuladores de plataforma completa são implementados no nível de instrução do processador (ISA, consulte o artigo anterior) Isso permite criar de forma relativamente rápida e barata o próprio simulador. O nível ISA também é bom porque permanece mais ou menos constante, ao contrário, por exemplo, do nível API / ABI, que muda com mais frequência. Além disso, a implementação no nível da instrução permite executar o chamado software binário não modificado, ou seja, executar o código já compilado sem nenhuma alteração, exatamente como é usado no hardware real. Em outras palavras, você pode fazer uma cópia (“despejo”) do disco rígido, especificá-la como a imagem do modelo em um simulador de plataforma completa e pronto! - O sistema operacional e outros programas são carregados no simulador sem nenhuma ação adicional.
Desempenho do simulador

Como mencionado acima, o processo de simular todo o sistema como um todo, ou seja, todos os seus dispositivos, é um evento bastante rápido. Se você também implementar tudo isso em um nível muito detalhado, por exemplo, microarquitetura ou lógica, a execução se tornará extremamente lenta. Mas o nível de instruções é uma escolha adequada e permite que o sistema operacional e os programas sejam executados em velocidades suficientes para que o usuário interaja confortavelmente com eles.
Aqui será apenas pertinente abordar o tópico desempenho do simulador. Geralmente é medido em IPS (instruções por segundo), mais precisamente em MIPS (milhões de IPS), ou seja, o número de instruções do processador executadas pelo simulador por segundo. Ao mesmo tempo, a velocidade da simulação também depende do desempenho do sistema no qual a simulação em si trabalha. Portanto, pode ser mais correto falar de uma "desaceleração" do simulador em comparação com o sistema original.
Os simuladores de plataforma completa mais comuns no mercado, como QEMU, VirtualBox ou VmWare Workstation, têm bom desempenho. Pode até não ser perceptível para o usuário que o trabalho está sendo realizado no simulador. Isso se deve aos recursos especiais de virtualização implementados nos processadores, algoritmos de tradução binária e outras coisas interessantes. Este é o tópico completo de um artigo separado, mas, se brevemente, a virtualização é um recurso de hardware dos processadores modernos que permite que os simuladores não simulem instruções, mas executem-nas diretamente em um processador real, a menos que, obviamente, as arquiteturas do simulador e do processador sejam semelhantes. Tradução binária é a tradução do código da máquina convidada no código do host e a execução subsequente em um processador real. Como resultado, a simulação é apenas um pouco mais lenta, uma vez a cada 5 a 10,e geralmente geralmente funciona na mesma velocidade que o sistema real. Embora isso seja influenciado por muitos fatores. Por exemplo, se queremos simular um sistema com várias dezenas de processadores, a velocidade diminui imediatamente várias dezenas de vezes. Por outro lado, simuladores como o Simics em versões recentes suportam hardware host multiprocessador e efetivamente paralelizam núcleos simulados com núcleos reais de processador.nas versões recentes, simuladores como o Simics suportam hardware host multiprocessador e efetivamente paralelizam núcleos simulados com núcleos de um processador real.simuladores como o Simics nas versões mais recentes suportam hardware host multiprocessador e efetivamente paralelizam núcleos simulados com núcleos reais de processador.
Se falamos sobre a velocidade da simulação microarquitetônica, geralmente é de várias ordens de magnitude, cerca de 1000 a 10000 vezes, mais lenta que a execução em um computador comum, sem simulação. E as implementações no nível dos elementos lógicos são ainda mais lentas em várias ordens de magnitude. Portanto, o FPGA é usado como um emulador nesse nível, o que pode aumentar significativamente o desempenho.
O gráfico abaixo mostra a dependência aproximada da velocidade da simulação nos detalhes do modelo.
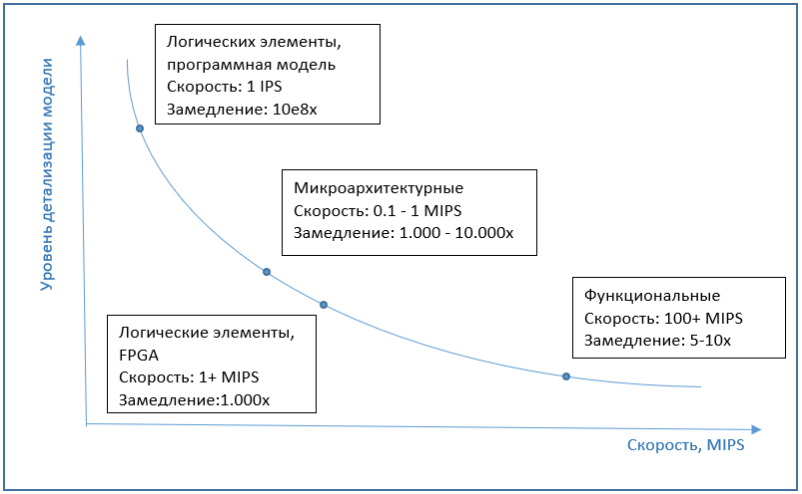
Simulação de relógio por ciclo
Apesar da baixa velocidade de execução, simulações microarquiteturais são bastante comuns. A modelagem dos blocos internos do processador é necessária para simular com precisão o tempo de execução de cada instrução. Isso pode levar a mal-entendidos - porque parece, por que não pegar e programar o tempo de execução de cada instrução. Mas esse simulador funcionará de maneira muito imprecisa, pois o tempo de execução da mesma instrução pode diferir de uma chamada para outra.
O exemplo mais simples é uma instrução de acesso à memória. Se o local da memória solicitada estiver disponível no cache, o tempo de execução será mínimo. Se o cache não possuir essas informações (“cache miss”, cache miss), isso aumentará bastante o tempo de execução da instrução. Portanto, é necessário um modelo de cache para simulação precisa. No entanto, o negócio não se limita ao modelo de cache. O processador não irá apenas esperar que os dados sejam recebidos da memória se não estiverem no cache. Em vez disso, começará a executar as próximas instruções, escolhendo aquelas que não dependem do resultado da leitura da memória. Essa é a chamada execução fora de ordem (OOO) necessária para minimizar o tempo de inatividade do processador. A simulação dos blocos de processadores correspondentes ajudará a levar tudo isso em consideração ao calcular o tempo de execução das instruções. Entre essas instruções sendo executadas,enquanto aguarda o resultado da leitura da memória, pode ocorrer uma operação de ramificação condicional. Se o resultado do preenchimento da condição for desconhecido no momento, o processador não interrompe a execução, mas faz uma "suposição", executa a transição correspondente e continua a executar preventivamente as instruções do local de transição. Esse bloco, chamado de preditor de ramificação, também deve ser implementado no simulador de microarquitetura.
A figura abaixo mostra os principais blocos do processador, não é necessário conhecê-lo, é mostrada apenas para mostrar a complexidade da implementação da microarquitetura.
A operação de todas essas unidades em um processador real é sincronizada por sinais especiais de relógio, da mesma forma que ocorre no modelo. Esse simulador microarquitetural é chamado de precisão do ciclo. Seu principal objetivo é prever com precisão o desempenho do processador que está sendo desenvolvido e / ou calcular o tempo de execução de um determinado programa, por exemplo, alguma referência. Se os valores forem inferiores ao necessário, será necessário refinar os algoritmos e os blocos do processador ou otimizar o programa.
Como mostrado acima, a simulação ciclo a ciclo é muito lenta, por isso é usada apenas ao examinar determinados momentos da operação do programa, onde é necessário descobrir a velocidade real da execução do programa e estimar o desempenho futuro do dispositivo cujo protótipo é simulado.
Ao mesmo tempo, um simulador funcional é usado para simular o restante do tempo do programa. Como esse uso combinado acontece na realidade? Primeiro, é lançado um simulador funcional, no qual o SO e tudo o que é necessário para executar o programa em estudo são carregados. Afinal, não estamos interessados no próprio sistema operacional ou nos estágios iniciais de lançamento do programa, sua configuração e assim por diante. No entanto, também não podemos pular essas partes e ir direto para a execução do programa a partir do meio. Portanto, todas essas etapas preliminares são executadas em um simulador funcional. Após a execução do programa até o momento de seu interesse, existem duas opções possíveis. Você pode substituir o modelo por um modelo push-pull e continuar a execução. Modo de simulação, no qual o código executável é usado (ou seja, arquivos de programa compilados regulares),chamado simulação orientada à execução. Esta é a simulação mais comum. Outra abordagem também é possível - simulação orientada a rastreamento.
Simulação baseada em trilhas
Consiste em duas etapas. Usando um simulador funcional ou em um sistema real, um log de ações do programa é coletado e gravado em um arquivo. Esse log é chamado de rastreamento. Dependendo do que está sendo investigado, a rota pode incluir instruções executáveis, endereços de memória, números de porta, informações sobre interrupções.
O próximo passo é "reproduzir" o rastreamento, quando o simulador de ciclo por relógio lê o rastreamento e executa todas as instruções escritas nele. No final, obtemos o tempo de execução de uma determinada parte do programa, bem como várias características desse processo, por exemplo, a porcentagem de acertos do cache.
Uma característica importante do trabalho com traços é o determinismo, ou seja, iniciando a simulação da maneira descrita acima, repetidamente reproduzimos a mesma sequência de ações. Isso possibilita, alterando os parâmetros do modelo (os tamanhos do cache, buffers e filas) e usando diferentes algoritmos internos ou ajustando-os, para investigar como esse ou aquele parâmetro afeta o desempenho do sistema e qual opção fornece os melhores resultados. Tudo isso pode ser feito com um modelo de dispositivo protótipo antes de criar um protótipo de hardware real.
A complexidade dessa abordagem está na necessidade de pré-executar o aplicativo e coletar o rastreamento, bem como o enorme tamanho do arquivo com o rastreamento. As vantagens incluem o fato de que é suficiente simular apenas a parte do dispositivo ou plataforma de interesse, enquanto a simulação de execução geralmente requer um modelo completo.
Portanto, neste artigo, examinamos os recursos da simulação de plataforma completa, falamos sobre a velocidade das implementações em diferentes níveis, simulação ciclo a ciclo e rastreamentos. No próximo artigo, descreverei os principais cenários para o uso de simuladores, tanto para fins pessoais quanto do ponto de vista do desenvolvimento em grandes empresas.