
Existem mais de 600 pizzarias na Dodo Pizza em 13 países do mundo, e a maioria dos processos nas pizzarias é controlada pelo sistema de informações Dodo IS , que nós mesmos escrevemos e mantemos. Portanto, a confiabilidade e a estabilidade do sistema são importantes para a sobrevivência.
Agora, a estabilidade e a confiabilidade do sistema de informações da empresa são suportadas pela equipe do SRE ( Site Reliability Engineering ), mas esse nem sempre foi o caso.
Antecedentes: Mundos Paralelos de Desenvolvedores e Infraestruturas
Por muitos anos, desenvolvi-me como um desenvolvedor fullstack típico (e um pouco de scrum master), aprendi a escrever um bom código, apliquei as práticas da Extreme Programming e reduzi cuidadosamente o número de WTF nos projetos que toquei. Porém, quanto mais experiência adquiri no desenvolvimento de software, mais percebi a importância de sistemas confiáveis de monitoramento e rastreamento para aplicativos, logs de alta qualidade, testes automáticos totais e mecanismos que garantem alta confiabilidade dos serviços. E, cada vez mais, ele começou a olhar "por cima do muro" para a equipe de infraestrutura.
Quanto melhor eu entendia o ambiente em que meu código trabalha, mais me surpreendia: testes automatizados para tudo e para todos, CI, lançamentos frequentes, refatoração segura e propriedade coletiva de códigos no mundo do software há muito tempo que são comuns e familiares. Ao mesmo tempo, no mundo da "infraestrutura" ainda é normal a falta de testes automáticos, para fazer alterações nos sistemas de produção em um modo semi-manual, e a documentação geralmente está apenas na cabeça dos indivíduos, mas não no código.
Essa lacuna cultural e tecnológica causa não apenas perplexidade, mas também problemas: na interseção de desenvolvimento, infraestrutura e negócios. É difícil lidar com alguns dos problemas na infraestrutura devido à proximidade com o hardware e ferramentas relativamente pouco desenvolvidas. Mas o resto pode ser derrotado se você começar a olhar para todos os seus manuais Ansible e scripts Bash como um produto de software completo e aplicar os mesmos requisitos a eles.
Triângulo de Problemas das Bermudas
No entanto, começarei de longe - com os problemas para os quais todas essas danças são necessárias.
Problemas do desenvolvedor
Há dois anos, percebemos que uma grande cadeia de pizzas não pode viver sem seu próprio aplicativo móvel e decidimos escrevê-lo:
- montar uma grande equipe;
- escrevemos um aplicativo conveniente e bonito em seis meses;
- apoiou o grande lançamento com deliciosas promoções;
- e no primeiro dia eles caíram em segurança sob carga.
Havia, é claro, muitos cardumes no início, mas acima de tudo me lembro de um. No momento do desenvolvimento, um servidor fraco foi implantado na produção, quase uma calculadora, que processava solicitações do aplicativo. Antes do anúncio público do aplicativo, ele precisava ser aumentado - vivemos no Azure, e isso foi resolvido com o clique de um botão.
Mas ninguém apertou esse botão: a equipe de infraestrutura nem sabia que algum tipo de aplicativo seria lançado hoje. Eles decidiram que era da responsabilidade da equipe de aplicativos supervisionar a produção do serviço "não crítico". E o desenvolvedor de back-end (este foi seu primeiro projeto no Dodo) decidiu que os caras da infraestrutura estão fazendo isso em grandes empresas.
Esse desenvolvedor era eu. Então deduzi para mim uma regra óbvia, mas importante:
, , , . .
Não é difícil agora. Nos últimos anos, apareceu um grande número de ferramentas que permitem aos programadores olhar para o mundo da exploração e não quebrar nada: Prometheus, Zipkin, Jaeger, pilha ELK, Kusto.
No entanto, muitos desenvolvedores ainda têm sérios problemas com os chamados infrastructure / DevOps / SRE. Como resultado, programadores:
dependem da equipe de infraestrutura. Causa dor, mal-entendido, às vezes ódio mútuo.
Eles projetam seus sistemas isoladamente da realidade e não levam em consideração onde e como seu código será executado. Por exemplo, a arquitetura e o design de um sistema que está sendo desenvolvido para a vida na nuvem serão diferentes do design de um sistema hospedado no local.
Eles não entendem a natureza dos bugs e problemas associados ao seu código.Isso é especialmente perceptível quando problemas estão relacionados ao carregamento, balanceamento de consultas, desempenho da rede ou do disco rígido. Os desenvolvedores nem sempre têm esse conhecimento.
Não é possível otimizar dinheiro e outros recursos da empresa que são usados para manter seu código. Em nossa experiência, acontece que a equipe de infraestrutura simplesmente enche o problema com dinheiro, por exemplo, aumentando o tamanho do servidor de banco de dados na produção. Portanto, os problemas de código geralmente nem chegam aos programadores. É que, por algum motivo, a infraestrutura começa a custar mais.
Problemas de infraestrutura
Há também dificuldades "do outro lado".
É difícil gerenciar dezenas de serviços e ambientes sem código de qualidade. Atualmente, temos mais de 450 repositórios no GitHub. Alguns deles não precisam de suporte operacional, outros estão mortos e salvos para o histórico, mas uma parte significativa contém serviços que precisam ser suportados. Eles precisam ser hospedados em algum lugar, precisam de monitoramento, coleta de logs, pipelines uniformes de CI / CD.
Para gerenciar tudo isso, recentemente usamos o Ansible ativamente. Nosso repositório Ansible continha:
- 60 papéis;
- 102 cartilhas;
- ligação em Python e Bash;
- testes manuais no Vagrant.
Tudo isso foi escrito por uma pessoa inteligente e bem escrito. Mas, assim que outros desenvolvedores da infra-estrutura e programadores começaram a trabalhar ativamente com esse código, os playbooks quebraram e as funções foram duplicadas e "cobertas de musgo".
O motivo foi que esse código não utilizou muitas das práticas padrão no mundo do desenvolvimento de software. Ele não possuía um pipeline de CI / CD e os testes eram complicados e lentos; portanto, todos estavam com preguiça ou "sem tempo" para executá-los manualmente, sem falar em escrever novos. Esse código está condenado se mais de uma pessoa trabalhar nele.
É difícil responder efetivamente a incidentes sem o conhecimento do código.Quando um alerta chega às 15h no PagerDuty, você precisa procurar um programador que explique o que e como. Por exemplo, que esses erros 500 afetam o usuário, enquanto outros estão relacionados ao serviço secundário, os clientes finais não o veem e você pode deixar assim até a manhã seguinte. Mas às três da manhã é difícil acordar os programadores, por isso é aconselhável entender como o código que você suporta funciona.
Muitas ferramentas requerem incorporação no código do aplicativo. Os funcionários da infraestrutura sabem o que precisa ser monitorado, como registrar e quais coisas prestar atenção no rastreamento. Mas eles geralmente não podem incorporar tudo isso no código do aplicativo. E aqueles que não sabem o que e como incorporar.
"Telefone quebrado".Explicar o que e como monitorar pela centésima vez é desagradável. É mais fácil escrever uma biblioteca compartilhada para passá-la aos programadores para reutilização em seus aplicativos. Mas, para isso, você precisa escrever código no mesmo idioma, no mesmo estilo e com as mesmas abordagens usadas pelos desenvolvedores de seus aplicativos.
Problemas de negócios
Os negócios também têm dois grandes problemas que precisam ser resolvidos.
Perdas diretas por instabilidade do sistema relacionadas à confiabilidade e disponibilidade.
Em 2018, tivemos 51 incidentes críticos, e elementos críticos do sistema não funcionaram por mais de 20 horas no total. Em termos monetários, são 25 milhões de rublos de perdas diretas devido a pedidos não entregues e não entregues. E quanto perdemos na confiança de funcionários, clientes e franqueados é impossível calcular, não é avaliado em dinheiro.
Custos de suporte para a infraestrutura atual. Ao mesmo tempo, a empresa estabeleceu uma meta para nós para 2018: reduzir o custo da infraestrutura por pizzaria em 3 vezes. Mas nem os programadores nem os engenheiros de DevOps em suas equipes chegaram nem perto de resolver esse problema. Há razões para isso:
- , ;
- , operations ( DevOps), ;
- , .
?
Como resolver todos esses problemas? Encontramos a solução na Engenharia de confiabilidade do site do Google. Quando lemos, entendemos - é disso que precisamos.
Mas há uma ressalva - para implementar tudo isso, leva anos e você precisa começar em algum lugar. Considere os dados de origem que tínhamos originalmente.
Toda a nossa infraestrutura vive quase inteiramente no Microsoft Azure. Existem vários clusters de vendas independentes espalhados por diferentes continentes: Europa, América e China. Existem suportes de carga que repetem a produção, mas vivem em um ambiente isolado, além de dezenas de ambientes DEV para equipes de desenvolvimento.
Já tivemos boas práticas de SRE:
- mecanismos para monitorar aplicativos e infraestrutura (spoiler: em 2018, pensávamos que eram bons, mas agora reescrevemos tudo);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
Mas também havia problemas que eu queria resolver:
a equipe de infraestrutura estava sobrecarregada. Não houve tempo e esforço suficientes para melhorias globais devido ao sistema operacional atual. Por exemplo, queríamos por um longo tempo, mas não conseguimos nos livrar do Elasticsearch em nossa pilha ou duplicar a infraestrutura de outro provedor de nuvem para evitar riscos (aqueles que já experimentaram o multicloud podem rir aqui).
Caos no código. O código de infraestrutura era caótico, espalhado por diferentes repositórios e não documentado em nenhum lugar. Tudo se baseava no conhecimento dos indivíduos e nada mais. Este foi um problema gigantesco de gerenciamento de conhecimento.
"Existem programadores e engenheiros de infraestrutura".Apesar de termos uma cultura DevOps bastante bem desenvolvida, ainda havia essa separação. Duas classes de pessoas com experiências completamente diferentes que falam idiomas diferentes e usam ferramentas diferentes. Eles, é claro, são amigos e se comunicam, mas geralmente não se entendem por causa de experiências completamente diferentes.
Equipes de integração do SRE
Para resolver esses problemas e de alguma forma começar a avançar para o SRE, lançamos um projeto de integração. Só que não era uma integração clássica - treinar novos funcionários (recém-chegados) para adicionar pessoas à equipe atual. Foi a criação de uma nova equipe de engenheiros e programadores de infraestrutura - o primeiro passo para uma estrutura SRE de pleno direito.
Alocamos quatro meses ao projeto e estabelecemos três metas:
- Treine os programadores no conhecimento e nas habilidades necessárias para as atividades operacionais e de deveres na equipe de infraestrutura.
- Escreva IaC - uma descrição de toda a infraestrutura no código. E deve ser um produto de software completo com testes de CI / CD.
- Recrie toda a infraestrutura desse código e esqueça clicar manualmente em máquinas virtuais com o mouse no Azure.
Participantes: 9 pessoas, 6 delas da equipe de desenvolvimento, 3 da infraestrutura. Durante 4 meses, eles tiveram que sair do trabalho normal e mergulhar nas tarefas designadas. Para dar suporte à “vida” nos negócios, outras três pessoas da infraestrutura permaneceram em serviço, envolvidas em sistemas operacionais e cobrindo a parte traseira. Como resultado, o projeto foi visivelmente ampliado e levou mais de cinco meses (de maio a outubro de 2019).
Dois pilares da integração: aprendizado e prática
A integração consistia em duas partes: aprendendo e trabalhando na infraestrutura em código.
Treinamento. Pelo menos 3 horas por dia foram alocadas para treinamento:
- ler artigos e livros da lista de referências: Linux, redes, SRE;
- em palestras sobre ferramentas e tecnologias específicas;
- para clubes de tecnologia, por exemplo, Linux, onde lidamos com casos e casos difíceis.
Outra ferramenta de aprendizado é a demonstração interna. Esta é uma reunião semanal em que todos (que têm algo a dizer) em 10 minutos conversam sobre uma tecnologia ou conceito que implementaram em nosso código em uma semana. Por exemplo, Vasya mudou o pipeline para trabalhar com os módulos Terraform e Petya reescreveu o conjunto de imagens usando o Packer.
Após a demonstração, iniciamos discussões sobre cada tópico no Slack, onde os participantes interessados podiam discutir tudo de forma assíncrona com mais detalhes. Portanto, evitamos longas reuniões para 10 pessoas, mas ao mesmo tempo todos da equipe entendiam bem o que estava acontecendo com nossa infraestrutura e para onde estávamos indo.

Prática. A segunda parte da integração é a criação / descrição da infraestrutura no código . Esta parte foi dividida em várias etapas.
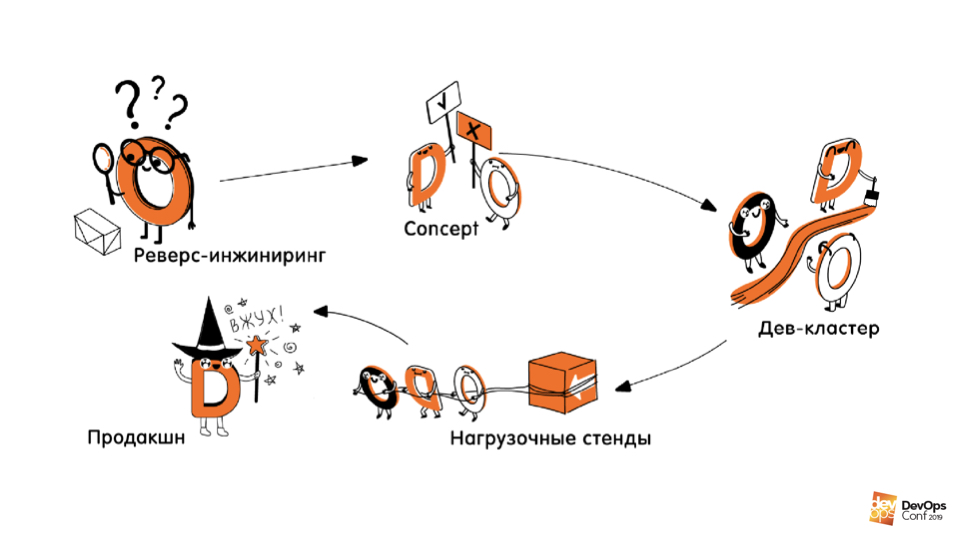
Engenharia reversa de infraestrutura.Esse é o primeiro estágio em que analisamos o que é implantado, onde, como o que funciona, onde quais serviços funcionam, onde quais máquinas e seus tamanhos. Tudo estava totalmente documentado.
Conceitos. Experimentamos diferentes tecnologias, linguagens, abordagens, descobrimos como podemos descrever nossa infraestrutura, quais ferramentas devem ser usadas para isso.
Escrevendo código. Isso incluía escrever o próprio código, criar pipelines de CI / CD, testes e criar processos em torno de tudo. Escrevemos o código que descrevia e sabia como criar nossa infraestrutura de desenvolvimento do zero.
Recriar stands para teste e produção de carga.Esta é a quarta etapa que deveria ocorrer após a integração, mas foi adiada por enquanto, já que o lucro com isso, curiosamente, é muito menor do que com as donzelas que são criadas / recriadas com muita frequência.
Em vez disso, mudamos para as atividades do projeto: nos dividimos em pequenas sub-equipes e enfrentamos os projetos de infraestrutura global para os quais nunca tínhamos chegado. E, claro, eles estavam de plantão.
Nossas ferramentas IaC
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Práticas Extremas de Programação em Infraestrutura
A principal coisa que nós, como programadores, trouxemos conosco são as práticas de Programação Extrema que usamos em nosso trabalho. O XP é uma metodologia ágil de desenvolvimento de software que combina as melhores abordagens, práticas e valores de desenvolvimento.
Não há um único programador que não tenha usado pelo menos algumas das práticas de programação extrema, mesmo que ele não saiba. Ao mesmo tempo, no mundo da infraestrutura, essas práticas são ignoradas, apesar de se sobreporem muito às práticas do Google SRE.
Há um artigo separado sobre como adaptamos o XP para infraestrutura .. Mas, em poucas palavras: as práticas XP funcionam para código de infraestrutura, embora com restrições, adaptações, mas funcionam. Se você deseja aplicá-las em casa, convide pessoas com experiência na aplicação dessas práticas. A maioria dessas práticas é descrita de uma maneira ou de outra no mesmo livro sobre SRE .
Poderia ter corrido bem, mas não funciona dessa maneira.
Problemas técnicos e antropogênicos a caminho
Havia dois tipos de problemas dentro do projeto:
- Técnico : limitações do mundo “ferro”, falta de conhecimento e ferramentas brutas que precisavam ser utilizadas porque não existem outras. Estes são problemas comuns para qualquer programador.
- Humano : a interação das pessoas em uma equipe. Comunicação, tomada de decisão, treinamento. Com isso, foi pior, então precisamos nos aprofundar nos detalhes.
Começamos a desenvolver a equipe de integração da maneira que faríamos com qualquer outra equipe de programadores. Esperávamos que houvesse as etapas usuais de construção de uma equipe da Takman : assalto, normalização e, no final, iremos para a produtividade e o trabalho produtivo. Portanto, não nos preocupamos que, a princípio, houvesse algumas dificuldades de comunicação, tomada de decisão, dificuldades para chegar a um acordo.
Dois meses se passaram, mas a fase de assalto continuou. Apenas mais perto do final do projeto, percebemos que todos os problemas com os quais lutamos e que não percebíamos como relacionados entre si eram resultado de um problema raiz comum - dois grupos de pessoas completamente diferentes se reuniram em uma equipe:
- Programadores experientes com anos de experiência para os quais desenvolveram suas abordagens, hábitos e valores no trabalho.
- Outro grupo do mundo da infraestrutura com sua própria experiência. Eles têm solavancos diferentes, hábitos diferentes e também pensam que sabem como viver corretamente.
Houve um choque de duas visões sobre a vida em uma equipe. Nós não vimos isso imediatamente e não começamos a trabalhar com isso, como resultado, perdemos muito tempo, energia e nervos.
Mas essa colisão não pode ser evitada. Se você chamar no projeto fortes programadores e fracos engenheiros de infraestrutura, terá uma troca de conhecimento unidirecional. Pelo contrário, também não funciona - alguns engolem outros e é isso. E você precisa obter algum tipo de mistura, para estar preparado para o fato de que a "retificação" pode ser muito longa (no nosso caso, conseguimos estabilizar a equipe apenas um ano depois, enquanto nos despedíamos de um dos engenheiros tecnicamente mais fortes).
Se você deseja formar uma equipe assim, não se esqueça de ligar para um coach Agile, um scrum master ou um psicoterapeuta forte - o que você preferir. Talvez eles ajudem.
Resultados de integração
Com base nos resultados do projeto de integração (que terminou em outubro de 2019), nós:
- Criamos um produto de software completo que gerencia nossa infraestrutura de DEV, com seu próprio pipeline de CI, testes e outros atributos de um produto de software de qualidade.
- Dobramos o número de pessoas que estão prontas para trabalhar e removemos a carga da equipe atual. Depois de mais seis meses, essas pessoas tornaram-se SREs completas. Agora eles podem apagar o fogo do prod, consultar uma equipe de programadores da NFT ou escrever sua própria biblioteca para desenvolvedores.
- SRE. , , .
- : , , , .
: ,
Algumas idéias do desenvolvedor. Não pise no nosso ancinho, salve a si e aos outros nervos e tempo.
Infraestrutura está no passado. Quando eu estava no meu primeiro ano (15 anos atrás) e comecei a aprender JavaScript, eu tinha o NotePad ++ e o Firebug para depuração. Mesmo assim, era necessário fazer coisas complexas e bonitas com essas ferramentas.
Sinto o mesmo agora quando trabalho com infraestrutura. As ferramentas atuais estão sendo formadas, muitas delas ainda não foram lançadas e possuem a versão 0.12 (hello Terraform), e muitas delas quebram regularmente a compatibilidade com versões anteriores.
Para mim, como desenvolvedor corporativo, é absurdo usar essas coisas na produção. Mas simplesmente não existem outros.
Leia a documentação.Como programador, eu acessava docas relativamente raramente. Eu conhecia minhas ferramentas profundamente: minha linguagem de programação favorita, minha estrutura e banco de dados favoritos. Todas as ferramentas adicionais, por exemplo, bibliotecas, geralmente são escritas no mesmo idioma, o que significa que você sempre pode consultar o código-fonte. O IDE sempre informará quais parâmetros são necessários e onde. Mesmo se eu estiver errado, eu vou descobrir rapidamente executando testes rápidos.
Isso não funcionará na infraestrutura, há um grande número de tecnologias diferentes que você precisa conhecer. Mas é impossível saber tudo profundamente, e muito foi escrito em idiomas desconhecidos. Portanto, leia (e escreva) cuidadosamente a documentação - sem esse hábito, eles não ficam muito tempo aqui.
Comentários no código de infraestrutura são inevitáveis.No mundo do desenvolvimento, os comentários são um sinal de código incorreto. Eles rapidamente se tornam obsoletos e começam a mentir. Isso é um sinal de que o desenvolvedor não conseguiu expressar seus pensamentos de outra maneira. Ao trabalhar com infraestrutura, os comentários também são um sinal de código incorreto, mas você não pode ficar sem eles. Para ferramentas díspares que são fracamente conectadas entre si e que não sabem nada uma da outra, o comentário é indispensável.
Freqüentemente, sob o código, configurações comuns e DSL são ocultas. Nesse caso, toda a lógica ocorre em algum lugar mais profundo, onde não há acesso. Isso muda muito a abordagem do código, testando e trabalhando com ele.
Não tenha medo de deixar os desenvolvedores entrarem na infraestrutura.Eles podem trazer práticas e abordagens úteis (e recentes) do mundo do desenvolvimento de software. Use as práticas e abordagens do Google, descritas no livro sobre SRE, beneficie-se e seja feliz.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .