Eu costumava ser um líder de equipe e estava encarregado de alguns serviços críticos. E se algo desse errado neles, interrompia processos de negócios reais. Por exemplo, os pedidos deixaram de ir para a montagem no armazém.
Recentemente, me tornei líder de direção e agora estou no comando de três equipes, em vez de uma. Cada um deles executa um sistema de TI. Eu quero entender o que está acontecendo em cada sistema e o que pode quebrar.
Neste artigo vou falar sobre
- o que monitoramos
- como monitoramos
- e o mais importante, o que fazemos com os resultados dessas observações.

Lamoda tem muitos sistemas. Todos eles são liberados, algo muda neles, algo acontece com a técnica. E quero ter pelo menos a ilusão de que podemos localizar facilmente o colapso. Sou constantemente bombardeado com alertas que tento descobrir. A fim de evitar abstrações e ir para detalhes, vou lhe contar o primeiro exemplo.
De tempos em tempos, algo explode: Crônicas de um incêndio
Em uma manhã quente de verão sem declarar guerra, como é geralmente o caso, o monitoramento funcionou para nós. Usamos Icinga como um alerta. Alert disse que ainda temos 50 GB de disco rígido no servidor DBMS. Provavelmente, 50 gigabytes é uma gota no oceano e terminará muito rapidamente. Decidimos ver exatamente quanto espaço livre restava. Você precisa entender que essas não são máquinas virtuais, mas servidores de ferro, e a base está sob carga pesada. Há um SSD de 1,5 terabyte. Em breve, essa memória chegará ao fim: durará 20 a 30 dias. Isso é muito pouco, você precisa resolver rapidamente o problema.
Além disso, verificamos quanta memória foi realmente consumida em 1-2 dias. Acontece que 50 gigabytes duram cerca de 5-7 dias. Depois disso, o serviço que funciona com esse banco de dados terminará previsivelmente. Começamos a pensar nas consequências: o que arquivaremos com urgência, os dados que excluiremos. O departamento de análise de dados possui todos os backups, para que você possa descartar com segurança tudo o que for anterior a 2015.
Tentamos excluí-lo e lembramos que o MySQL não funcionará dessa maneira com um chute parcial. Os dados excluídos são ótimos, mas o tamanho do arquivo alocado para a tabela e para o banco de dados não muda. O MySQL então usa esse espaço. Ou seja, o problema não foi resolvido, não havia mais espaço.
Tentamos uma abordagem diferente: migrar rótulos de SSDs de final rápido para outros mais lentos. Para fazer isso, selecione os tablets que pesam muito, mas com uma carga pequena, e use o monitoramento Percona. Mudamos as tabelas e já estamos pensando em mudar os próprios servidores. Após a segunda jogada, o servidor ocupa não 4, mas 4 terabytes de SSD.
Apagamos esse incêndio: organizamos uma mudança e, é claro, monitoramos o local. Agora, o aviso será acionado não em 50 gigabytes, mas em meio terabyte, e o valor crítico de monitoramento será acionado em 50 gigabytes. Mas, na realidade, isso é apenas um cobertor cobrindo a parte traseira. Vai durar um pouco. Mas se permitirmos uma repetição da situação sem quebrar a base em partes e sem pensar em fragmentar, tudo terminará mal.
Suponha que alteramos ainda mais o servidor. Em algum momento, foi necessário reiniciar o mestre. Provavelmente, erros aparecerão neste caso. No nosso caso, o tempo de inatividade foi de cerca de 30 segundos. Mas os pedidos estão chegando, nenhum lugar para escrever, erros caíram, o monitoramento funcionou. Usamos o sistema de monitoramento Prometheus - e vemos nele que a métrica de 500 erros ou o número de erros ao criar um pedido saltou. Mas não sabemos os detalhes: qual ordem não foi criada e coisas assim.
Além disso, direi como trabalhamos com o monitoramento para não entrar em tais situações.
Revisão do monitoramento e descrição clara do serviço de suporte
Temos várias direções e indicadores que estamos monitorando. Existem TVs em todo o escritório, nas quais existem diversos rótulos técnicos e comerciais, que, além dos desenvolvedores, são monitorados pelo serviço de suporte.
Neste artigo, falo sobre como o temos e adiciono o que queremos chegar. Isso também se aplica ao monitoramento de revisões. Se fizermos regularmente um inventário de nossa "propriedade", poderemos atualizar tudo o que estiver desatualizado e corrigi-lo, impedindo a repetição do fakap. Isso requer uma lista coerente.
Temos configurações com alertas no repositório, onde agora existem 4678 linhas. A partir desta lista, é difícil entender do que cada monitoramento específico está falando. Digamos que nossa métrica se chame db_disc_space_left. O serviço de suporte não entenderá imediatamente do que se trata. Algo sobre espaço livre, ótimo.
Queremos ir mais fundo. Examinamos a configuração desse monitoramento e entendemos de onde ele vem.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
Essa métrica possui um nome, suas próprias limitações, quando incluir o monitoramento de aviso, um alerta para relatar uma situação crítica. Usamos uma convenção de nomenclatura para métricas. No início de cada métrica está o nome do sistema. Graças a isso, a área de responsabilidade fica clara. Se a pessoa responsável pelo sistema iniciar a métrica, fica imediatamente claro para quem ir.
Os alertas são colocados em telegramas ou folga. O serviço de suporte reage a eles primeiro 24/7. Os caras olham o que exatamente explodiu, se esta é uma situação normal. Eles têm instruções:
- aqueles que são dados para substituir,
- e instruções que são fixadas em confluência continuamente. Pelo nome do monitoramento explodido, é possível encontrar o que isso significa. Para os mais críticos, é descrito o que está quebrado, quais são as consequências, quem precisa ser levantado.
Também temos turnos em equipes responsáveis pelos principais sistemas. Cada equipe tem alguém que está constantemente disponível. Se algo acontecer, eles o pegam.
Quando o alerta é acionado, a equipe de suporte precisa descobrir rapidamente todas as informações principais. Seria bom ter um link para a descrição do monitoramento anexada à mensagem de erro. Por exemplo, para que exista essa informação:
- uma descrição desse monitoramento em termos compreensíveis e relativamente simples;
- o endereço onde está localizado;
- uma explicação sobre qual é a métrica;
- consequências: como terminará se não corrigirmos o erro;
- , , . , , . -, .
Também seria conveniente ver imediatamente a dinâmica do tráfego na interface do Prometheus.
Eu gostaria de fazer essas descrições para cada monitoramento. Eles ajudarão a criar uma revisão e fazer ajustes. Estamos introduzindo esta prática: já existe um link para confluência com essas informações na configuração do icing. Eu tenho trabalhado em um sistema por quase 4 anos, basicamente não existem tais descrições para ele. Portanto, agora estou coletando conhecimento juntos. As descrições também resolvem a falta de conhecimento da equipe.
Temos instruções para a maioria dos alertas, onde está escrito o que leva a um certo impacto nos negócios. É por isso que devemos resolver rapidamente a situação. A gravidade dos possíveis incidentes é determinada pelo serviço de suporte junto à empresa.
Vou dar um exemplo: se o monitoramento do consumo de RAM no servidor RabbitMQ do serviço de processamento de pedidos for acionado, isso significa que o serviço de fila poderá falhar em algumas horas ou até minutos. Por sua vez, isso interromperá muitos processos de negócios. Como resultado, os clientes aguardam, sem sucesso, pedidos, notificações por SMS / push, alterações de status e muito mais.
Discussões sobre o monitoramento com os negócios geralmente ocorrem após incidentes graves. Se algo der errado, coletamos uma comissão com representantes da direção, que foi fisgada por nossa libertação ou incidente. Na reunião, analisamos as causas do incidente, como garantir que ele nunca aconteça novamente, que danos sofremos, quanto dinheiro perdemos e em quê.
Acontece que você precisa conectar uma empresa para resolver problemas criados para os clientes. Aqui discutimos ações proativas: que tipo de monitoramento iniciar para que isso não ocorra novamente.
O serviço de suporte monitora os valores das métricas usando um bot de telegrama. Quando surge um novo monitoramento, o responsável pelo suporte precisa de uma ferramenta simples para descobrir onde está a falha e o que fazer a respeito. O link para a descrição no alerta resolve esse problema.
Eu vejo o fakap como na realidade: usando o Sentry para interrogar
Não basta apenas descobrir o erro, você deseja ver os detalhes. Nosso caso de uso padrão é o seguinte: lançamos o release e recebemos alertas da pilha K8S. Graças ao monitoramento, analisamos o status dos lares: quais versões do aplicativo foram lançadas, como a implantação foi concluída e se está tudo bem.
Então, olhamos para o RMM, o que temos com a base e com uma carga nela. Para Grafana e placas, analisamos o número de conexões com o Rabbit. Ele é legal, mas sabe como vazar quando a memória acaba. Monitoramos essas coisas e depois checamos a Sentinela. Ele permite que você assista on-line como o próximo fiasco se desenrola com todos os detalhes. Nesse caso, o monitoramento pós-lançamento informa o que quebrou e como.
Nos projetos PHP, usamos um cliente raven e o enriquecemos adicionalmente com dados. Sentinela é tudo muito bem agregado. E vemos a dinâmica de cada fakap, com que frequência isso acontece. E também examinamos exemplos, quais solicitações não foram bem-sucedidas e quais extensões foram lançadas.
Parece algo assim. Vejo que na próxima versão de erros houve muito mais do que o habitual. Vamos verificar o que exatamente está quebrado. E então, se necessário, obteremos as ordens com falha de acordo com o contexto e as corrigiremos.
Temos uma coisa legal - ligar para Jira. Este é um rastreador de tickets: pressionei um botão e Jira criou uma tarefa de erro com um link para o Sentry e um rastreamento de pilha desse erro. A tarefa está marcada com certos rótulos.
Um dos desenvolvedores trouxe uma iniciativa sensata - “Projeto limpo, Sentinela limpa”. No planejamento, toda vez que lançamos pelo menos 1-2 tarefas criadas a partir do Sentry no sprint. Se algo está quebrado no sistema o tempo todo, o Sentry está cheio de milhões de pequenos erros estúpidos. Nós os limpamos regularmente para não perder acidentalmente os realmente graves.
Incendeia por qualquer motivo: nos livramos do monitoramento, no qual todos são martelados
- Acostumando-se a erros
Se algo está constantemente piscando e parece quebrado, dá a sensação de uma norma falsa. A central de atendimento pode ser iludida ao pensar que a situação é adequada. E quando algo sério avariar, será ignorado. Como numa fábula sobre um garoto gritando: “Lobos, lobos!”.
O caso clássico é o nosso projeto, responsável pelo processamento de pedidos. Ele trabalha com o sistema de automação de armazém e transfere dados para lá. Esse sistema geralmente é lançado às 7 horas da manhã, após o qual começamos a monitorar. Todo mundo está acostumado a isso e pontuações, o que não é muito bom. Seria sensato desativar esses controles. Por exemplo, para vincular a liberação de um sistema específico e alguns alertas por meio do Prometheus, apenas não ative o alarme extra.
- O monitoramento não leva em consideração os indicadores de negócios
O sistema de processamento de pedidos transfere dados para o armazém. Adicionamos monitoramento a este sistema. Nenhum deles disparou, e parece que está tudo bem. O contador indica que os dados estão saindo. Este caso usa sabão. Na realidade, o contador pode ficar assim: a parte verde é de trocas de entrada, a parte amarela é de saída.
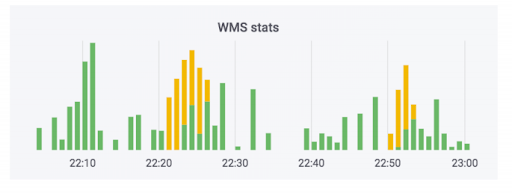
Tivemos um caso em que os dados realmente agradaram, mas sim curvas. Os pedidos não foram pagos, mas foram marcados como pagos. Ou seja, o comprador poderá buscá-las gratuitamente. Parece assustador. Mas o oposto é mais divertido: uma pessoa vem buscar uma ordem paga e é solicitada a pagar novamente por causa de um erro no sistema.
Para evitar essa situação, monitoramos não apenas a tecnologia, mas também as métricas de negócios. Temos um monitoramento específico que monitora o número de pedidos que exigem pagamento após o recebimento. Quaisquer saltos sérios nessa métrica serão exibidos se algo der errado.
O monitoramento de indicadores de negócios é uma coisa óbvia, mas eles geralmente são esquecidos quando novos serviços são lançados, inclusive nós. Todos cobrem os novos serviços com métricas puramente técnicas relacionadas a discos, processos, o que for. Como uma loja on-line, temos uma coisa crítica - o número de pedidos criados. Sabemos quanto as pessoas costumam comprar, ajustadas para promoções de marketing. Portanto, monitoramos esse indicador durante os lançamentos.
Outra coisa importante: quando um cliente solicita repetidamente a entrega no mesmo endereço, não o atormentamos ao nos comunicar com a central de atendimento, mas confirmamos automaticamente o pedido. A falha no sistema afeta muito a experiência do cliente. Também monitoramos essa métrica, pois as liberações de diferentes sistemas podem influenciá-la fortemente.
Estamos assistindo o mundo real: nos preocupamos com um sprint saudável e com nosso desempenho
Para que a empresa acompanhe diferentes indicadores, escrevemos um pequeno sistema de painel em tempo real. Foi originalmente feito para um propósito diferente. A empresa tem um plano para quantos pedidos queremos vender em um dia específico do próximo mês. Este sistema mostra a conformidade dos planos e feitos de fato. Para o gráfico, ela pega os dados do banco de dados de produção, lê a partir daí em tempo real.
Uma vez que nossa réplica se desfez. Não havia monitoramento, então não tivemos tempo de descobrir. Mas os negócios perceberam que não estávamos cumprindo o plano para 10 unidades de pedidos convencionais e começaram a comentar. Começamos a entender as razões. Aconteceu que dados irrelevantes estavam sendo lidos a partir da réplica quebrada. É um caso em que uma empresa observa indicadores interessantes e nos ajudamos quando surgem problemas.
Vou falar sobre outro monitoramento do mundo real, que está em desenvolvimento há muito tempo e está sendo constantemente ajustado por cada equipe. Temos um Jira Viewer - permite monitorar o processo de desenvolvimento. O sistema é extremamente simples: o framework PHP Symfony, que acessa o Jira Api e extrai dados de lá sobre tarefas, sprints etc., dependendo do que foi fornecido como entrada. Jira Viewer escreve regularmente métricas relacionadas a equipes e seus projetos no Prometeus. Lá eles são monitorados, alertas e, a partir daí, exibidos na Grafana. Graças a este sistema, seguimos o trabalho em andamento.
- Monitoramos quanto tempo a tarefa está em andamento desde o momento em andamento até a implementação no produto. Se o número for muito grande, em teoria, isso indica um problema com processos, equipe, descrições de tarefas e assim por diante. A vida de uma tarefa é uma métrica importante, mas não é suficiente por si só.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- Monitorei na minha equipe o número de solicitações pull dos desenvolvedores fora do horário de trabalho. Particularmente depois das 20h. E quando a métrica dispara, esse é um sinal alarmante: uma pessoa não tem tempo para algo ou investe muito esforço e, mais cedo ou mais tarde, simplesmente queimará.
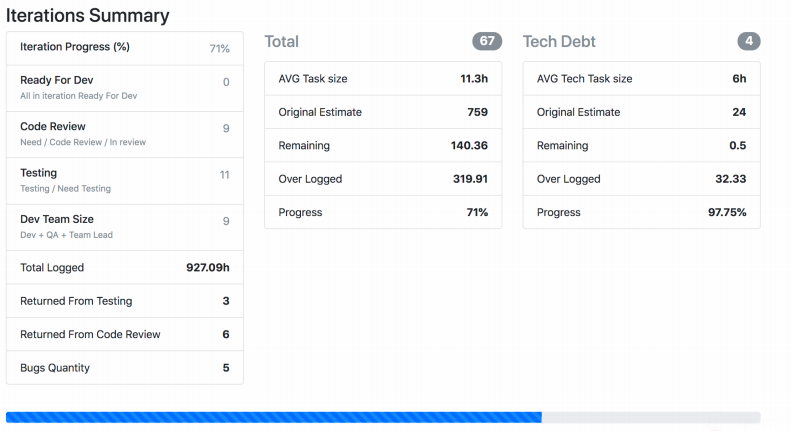
A captura de tela mostra como o Jira Viewer exibe dados. Esta é uma página na qual há um resumo dos status das tarefas do sprint, quanto pesa cada uma e outras coisas semelhantes. Essas coisas também se reúnem e voam para Prometeu.
Não apenas métricas técnicas: o que já monitoramos, o que podemos monitorar e por que tudo isso é necessário
Para juntar tudo, sugiro monitorar a tecnologia e as métricas relacionadas a processos, desenvolvimento e negócios juntos. Métricas técnicas por si só não são suficientes.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .