O que é a fala humana? São palavras cujas combinações permitem que você expresse essa ou aquela informação. Surge a pergunta: como sabemos quando uma palavra termina e outra começa? A pergunta é bastante estranha, muitos pensam, porque desde o nascimento ouvimos o discurso das pessoas ao nosso redor, aprendemos a falar, escrever e ler. A bagagem acumulada do conhecimento linguístico, é claro, desempenha um papel importante, mas, além disso, existem redes neurais no cérebro que dividem o fluxo da fala em palavras e / ou sílabas componentes. Hoje, vamos nos familiarizar com um estudo em que cientistas da Universidade de Genebra (Suíça) criaram um modelo de decodificação de fala para neurocomputadores, prevendo palavras e sílabas. Quais processos cerebrais se tornaram a base do modelo, o que significa a grande palavra "previsão",e qual a eficácia do modelo criado? As respostas para essas perguntas nos aguardam no relatório dos cientistas. Ir.
Base de estudo
Para nós, seres humanos, a fala humana é bastante compreensível e articulada (na maioria das vezes). Mas para uma máquina, isso é apenas um fluxo de informações acústicas, um sinal sólido que precisa ser decodificado antes de ser entendido.
O cérebro humano age da mesma maneira, apenas acontece de maneira extremamente rápida e imperceptível para nós. Os cientistas acreditam que a base deste e de muitos outros processos cerebrais são certas oscilações neuronais, bem como suas combinações.
Em particular, o reconhecimento de fala está associado a uma combinação de oscilações teta e gama, pois permite coordenar hierarquicamente a codificação de fonemas em sílabas sem conhecimento prévio de sua duração e origem temporal, ou seja, processamento upstream * em tempo real.
* (bottom-up) — , .O reconhecimento natural da fala também depende muito dos sinais contextuais, que permitem prever o conteúdo e a estrutura temporal do sinal da fala. Estudos anteriores mostraram que o mecanismo de previsão desempenha um papel importante durante a percepção da fala contínua. Este processo está associado a vibrações beta.
Outro componente importante do reconhecimento de fala pode ser chamado de codificação preditiva, quando o cérebro constantemente gera e atualiza um modelo mental do ambiente. Este modelo é usado para gerar previsões para entrada de toque comparadas com a entrada de toque real. A comparação do sinal previsto e real leva à identificação de erros que servem para atualizar e revisar o modelo mental.
Em outras palavras, o cérebro está sempre aprendendo algo novo, atualizando constantemente o modelo do mundo ao seu redor. Esse processo é considerado crítico no processamento de sinais de fala.
Os pesquisadores observam que muitos estudos teóricos apóiam as abordagens ascendente e descendente * do processamento de fala.
Downward processing * ( top-down ) - análise dos componentes do sistema para a submissão de seus subsistemas compostos pela engenharia reversa.Um modelo de neurocomputador desenvolvido anteriormente, envolvendo a combinação de redes teta e excitatórias / inibidoras gama realistas, foi capaz de pré-processar a fala para que ela pudesse ser corretamente decodificada.
Outro modelo, baseado apenas na codificação preditiva, poderia reconhecer com precisão elementos individuais da fala (como palavras ou frases completas, se vistas como um único elemento da fala).
Portanto, ambos os modelos funcionaram, apenas em direções diferentes. Um focado no aspecto de análise de fala em tempo real e o outro focado no reconhecimento de segmentos de fala isolados (nenhuma análise é necessária).
Mas e se combinarmos os princípios básicos desses modelos radicalmente diferentes em um? Segundo os autores do estudo que estamos considerando, isso melhorará o desempenho e aumentará o realismo biológico dos modelos de processamento de fala de neurocomputadores.
Em seu trabalho, os cientistas decidiram verificar se um sistema de reconhecimento de fala baseado em codificação preditiva pode obter algum benefício com os processos de oscilações neurais.
Eles desenvolveram o modelo de computador neural Precoss (a partir de codificação preditiva e oscilações para fala ) com base na estrutura de codificação preditiva, que adicionou funções teta e gama-vibracional para lidar com a natureza contínua da fala natural.
O objetivo específico deste trabalho foi encontrar uma resposta para a questão de saber se a combinação de codificação preditiva e oscilações neurais pode ser benéfica para a identificação operacional de componentes silábicos de sentenças naturais. Em particular, foram examinados os mecanismos pelos quais as oscilações teta podem interagir com os fluxos de informação para cima e para baixo, e foi avaliado o impacto dessa interação na eficiência do processo de decodificação de sílabas.
Arquitetura do modelo Precoss
Uma função importante do modelo é que ele deve ser capaz de usar os sinais / informações temporais presentes no discurso contínuo para determinar os limites da sílaba. Os cientistas sugeriram que modelos generativos internos, incluindo previsões temporais, deveriam se beneficiar de tais sinais. Para acomodar essa hipótese, bem como os processos repetitivos que ocorrem durante o reconhecimento de fala, foi utilizado um modelo de codificação preditiva contínua.
O modelo desenvolvido separa claramente “o que” e “quando”. "O que" se refere à identidade de uma sílaba e sua representação espectral (não temporal, mas sequência ordenada de vetores espectrais); "Quando" se refere à previsão do tempo e duração das sílabas.
Como resultado, as previsões assumem duas formas: o início de uma sílaba, sinalizada pelo módulo teta; e duração da sílaba, sinalizada por oscilações teta exógenas / endógenas, que definem a duração da sequência unitária sincronizada com gama (diagrama abaixo).
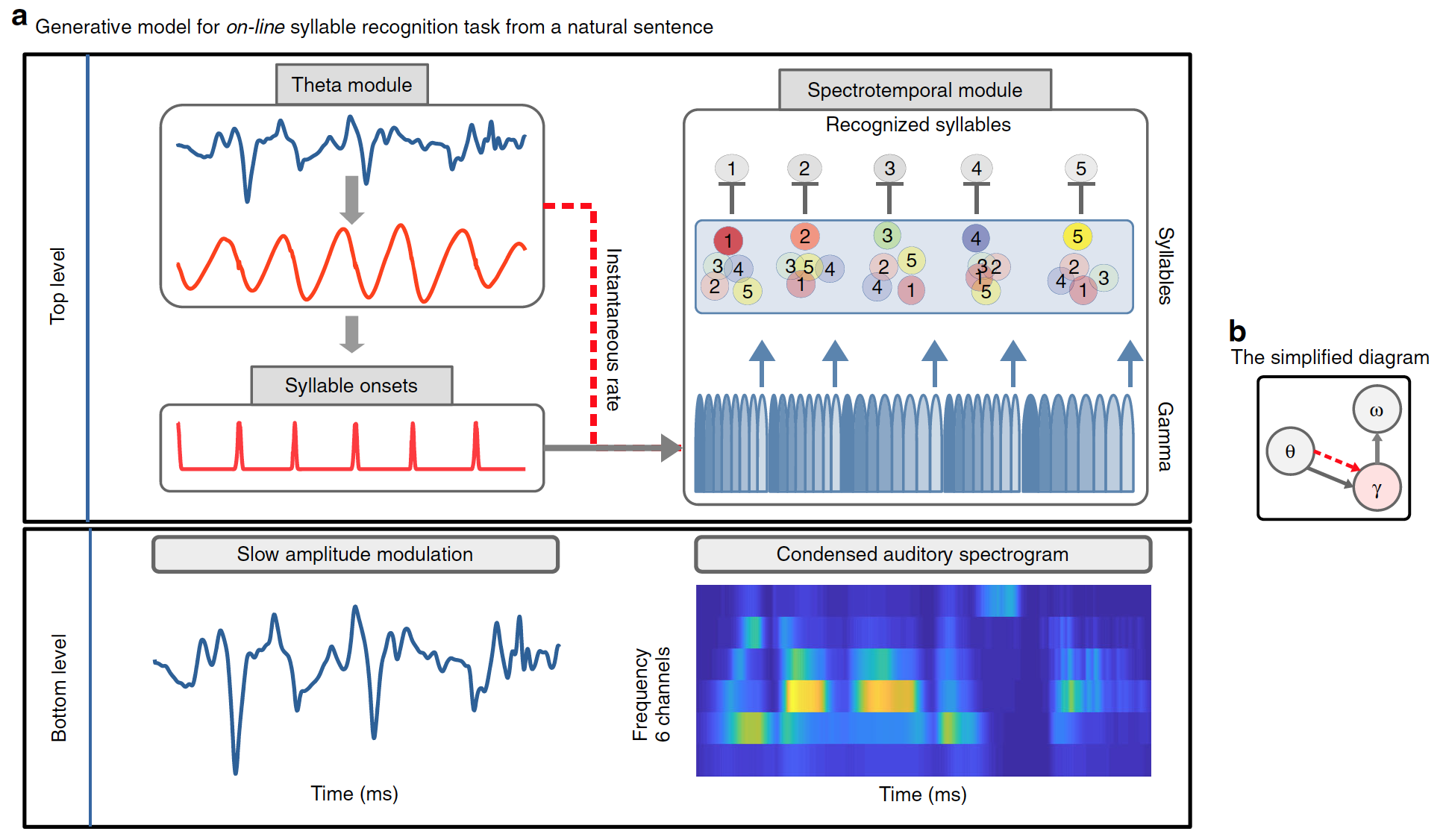
Imagem # 1 A
Precoss extrai um sinal sensorial das representações internas de sua fonte, referindo-se a um modelo generativo. Nesse caso, a entrada sensorial corresponde à modulação de amplitude lenta do sinal de fala e ao espectrograma auditivo de 6 canais da sentença natural completa, que o modelo gera internamente a partir de quatro componentes:
- balanço teta;
- uma unidade de modulação de amplitude lenta em um módulo teta;
- pool de unidades de sílabas (quantas sílabas estiverem presentes na frase introdutória natural, isto é, de 4 a 25);
- banco de oito unidades gama no módulo espectrotemporal.
Juntas, as unidades de sílabas e a forma de onda gama geram previsões de cima para baixo sobre o espectrograma de entrada. Cada uma das oito unidades gama representa uma fase em uma sílaba; eles são ativados sequencialmente e a sequência de ativação inteira é repetida. Portanto, cada unidade de sílaba está associada a uma sequência de oito vetores (um por unidade gama) com seis componentes cada (um por canal de frequência). O espectrograma acústico de uma sílaba individual é gerado pela ativação da unidade de sílaba correspondente durante toda a duração da sílaba.
Enquanto o bloco de sílaba codifica um padrão acústico específico, os blocos gama usam temporariamente a previsão espectral correspondente para a duração da sílaba. Informações sobre o comprimento de uma sílaba são fornecidas pela onda teta, pois sua velocidade instantânea afeta a velocidade / duração da sequência gama.
Finalmente, os dados acumulados sobre a sílaba pretendida devem ser excluídos antes de processar a próxima sílaba. Para fazer isso, o último (oitavo) bloco gama, que codifica a última parte de uma sílaba, redefine todas as unidades de sílabas para um nível geral baixo de ativação, o que permite que novas evidências sejam coletadas.
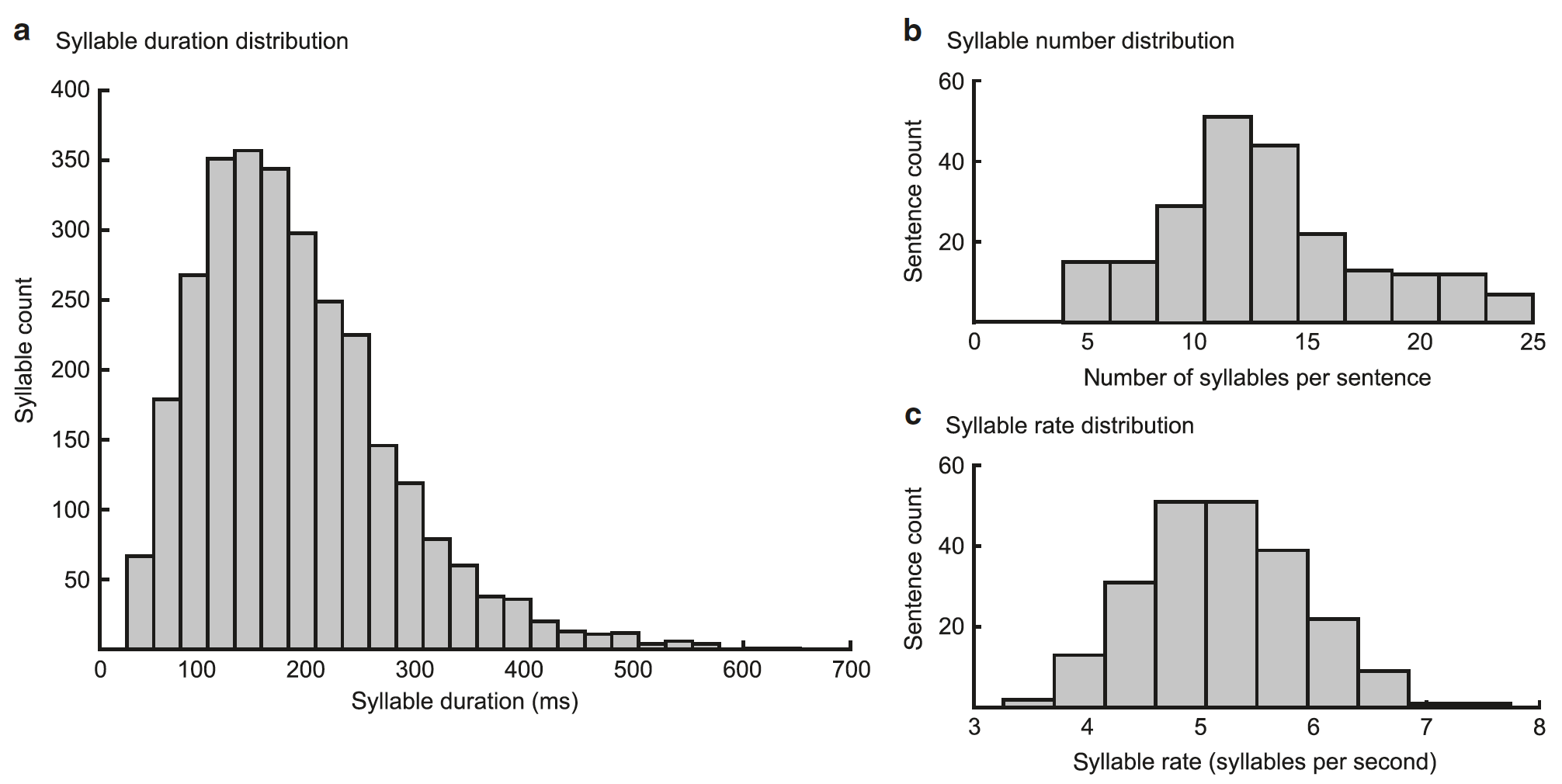
Imagem No. 2
O desempenho do modelo depende se a sequência gama coincide com o início de uma sílaba e se a sua duração corresponde à duração de uma sílaba (50–600 ms, média = 182 ms).
A avaliação do modelo em relação à sequência de sílabas é fornecida por unidades de sílabas, que, juntamente com unidades gama, geram os padrões espectrais-temporais esperados (o resultado do modelo), que são comparados com o espectrograma introdutório. O modelo atualiza suas estimativas sobre a sílaba atual para minimizar a diferença entre o espectrograma gerado e o real. O nível de atividade aumenta nessas unidades silábicas, cujo espectrograma corresponde à entrada sensorial e diminui em outras. Idealmente, minimizar o erro de previsão em tempo real leva ao aumento da atividade em uma unidade distinta da sílaba correspondente à sílaba de entrada.
Resultados simulados
O modelo apresentado acima inclui oscilações teta fisiologicamente motivadas, que são controladas por modulações de amplitude lenta do sinal de fala e transmitem informações sobre o início e a duração da sílaba para o componente gama.
Essa relação teta-gama fornece um alinhamento temporal das previsões geradas internamente com os limites da sílaba encontrados nos dados de entrada (opção A na imagem # 3).
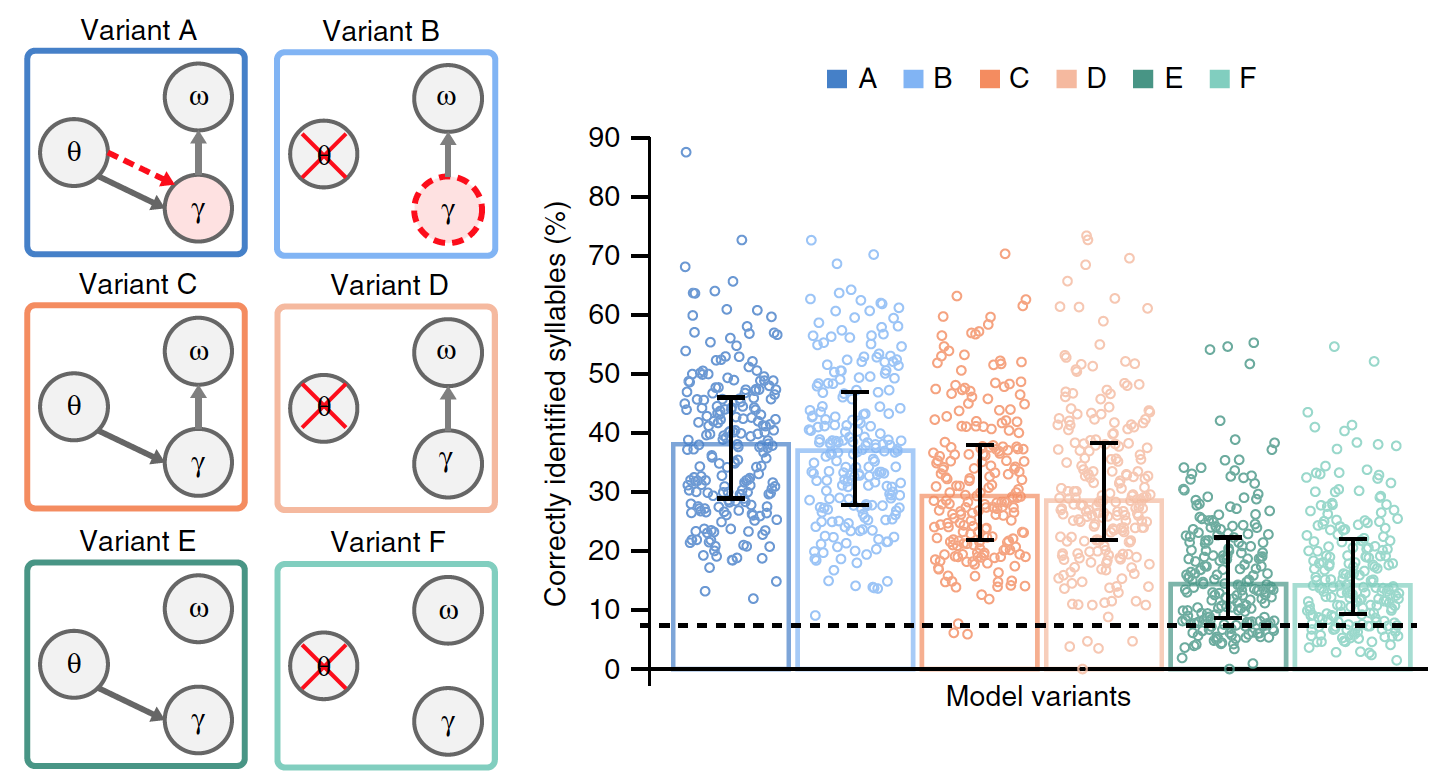
Imagem No. 3
Para avaliar a relevância da sincronização de sílabas com base na modulação de amplitude lenta, foi realizada uma comparação do modelo A com a opção B, em que a atividade teta não é modelada por vibrações, mas decorre da auto-repetição da sequência gama.
No modelo B, a duração da sequência gama não é mais controlada exogenamente (devido a fatores externos) por oscilações teta, mas endogenamente (devido a fatores internos) utiliza a taxa gama preferida, que, quando a sequência é repetida, leva à formação de um ritmo teta interno. Como no caso de oscilações teta, a duração da sequência gama tem uma velocidade preferida na faixa teta, que pode potencialmente se adaptar a durações variáveis de sílabas. Nesse caso, é possível testar o ritmo teta resultante da repetição da sequência gama.
Para avaliar com mais precisão os efeitos específicos da gama teta de composição e despejo dos dados acumulados em unidades de sílaba, foram feitas versões adicionais dos modelos anteriores A e B.
As opções C e D foram distinguidas pela ausência de uma taxa de radiação gama preferida. As variantes E e F diferiram adicionalmente das variantes C e D pela ausência de redefinição dos dados da sílaba acumulada.
De todas as variantes do modelo, apenas A possui uma verdadeira relação teta-gama, onde a atividade gama é determinada pelo módulo teta, enquanto que no modelo B, a taxa gama é definida endogenamente.
Foi necessário estabelecer qual das variantes do modelo é a mais eficaz, para a qual os resultados de seu trabalho foram comparados na presença de dados de entrada comuns (sentenças naturais). O gráfico na imagem acima mostra o desempenho médio de cada um dos modelos.
Diferenças significativas estavam presentes entre as opções. Comparado aos modelos A e B, o desempenho foi significativamente menor nos modelos E e F (23% em média) e C e D (15%). Isso indica que apagar os dados acumulados sobre a sílaba anterior antes de processar a nova sílaba é um fator crítico na codificação do fluxo da sílaba na fala natural.
A comparação das opções A e B com as opções C e D mostrou que a conexão teta-gama, seja estímulo (A) ou endógena (B), melhora significativamente o desempenho do modelo (uma média de 8,6%).
De um modo geral, experimentos com diferentes versões dos modelos mostraram que funcionava melhor quando as unidades de sílaba eram redefinidas após cada sequência de unidades gama (com base em informações internas sobre a estrutura espectral da sílaba) e quando a taxa de radiação gama era determinada por acoplamento teta-gama.
O desempenho do modelo com sentenças naturais, portanto, não depende da sinalização precisa do início das sílabas através de oscilações teta controladas pelo estímulo, nem do mecanismo exato da comunicação teta-gama.
Como os próprios cientistas admitem, essa é uma descoberta bastante surpreendente. Por outro lado, a falta de diferenças de desempenho entre a relação teta-gama dirigida por estímulos e endógena reflete que a duração das sílabas na fala natural está muito próxima das expectativas do modelo, caso em que não haverá vantagem para o sinal teta acionado diretamente pela entrada.
Para entender melhor uma mudança inesperada de eventos, os cientistas conduziram outra série de experimentos, mas com sinais de fala compactados (x2 e x3). Como os estudos comportamentais mostram, o entendimento da fala compactada em x2 vezes praticamente não muda, mas cai significativamente quando compactado em três vezes.
Nesse caso, a conexão teta-gama estimulada pode ser extremamente útil para analisar e decodificar sílabas. Os resultados da simulação são apresentados abaixo.

Imagem # 4
Como esperado, o desempenho geral caiu à medida que a taxa de compactação aumentou. Para comprimir x2, ainda não havia diferença significativa entre o estímulo e as ligações teta-gama endógenas. Mas no caso da compactação x3, há uma diferença significativa. Isso sugere que a oscilação teta impulsionada por estímulo, dirigindo o link teta-gama, foi mais benéfica para a codificação de sílabas do que uma taxa teta estabelecida endogenamente.
Segue-se que a fala natural pode ser processada com um gerador de teta endógeno relativamente fixo. Mas, para sinais de fala de entrada mais complexos (ou seja, quando a velocidade da fala muda constantemente), é necessário um gerador de teta controlado, que transmite informações precisas de tempo sobre as sílabas para o codificador gama (o início da sílaba e a duração da sílaba).
A capacidade do modelo de reconhecer com precisão as sílabas na sentença de entrada não leva em consideração a complexidade variável dos vários modelos comparados. Portanto, um Critério de Informação Bayesiano (BIC) foi avaliado para cada modelo. Esse critério determina quantitativamente o compromisso entre a precisão e a complexidade do modelo (imagem nº 5).
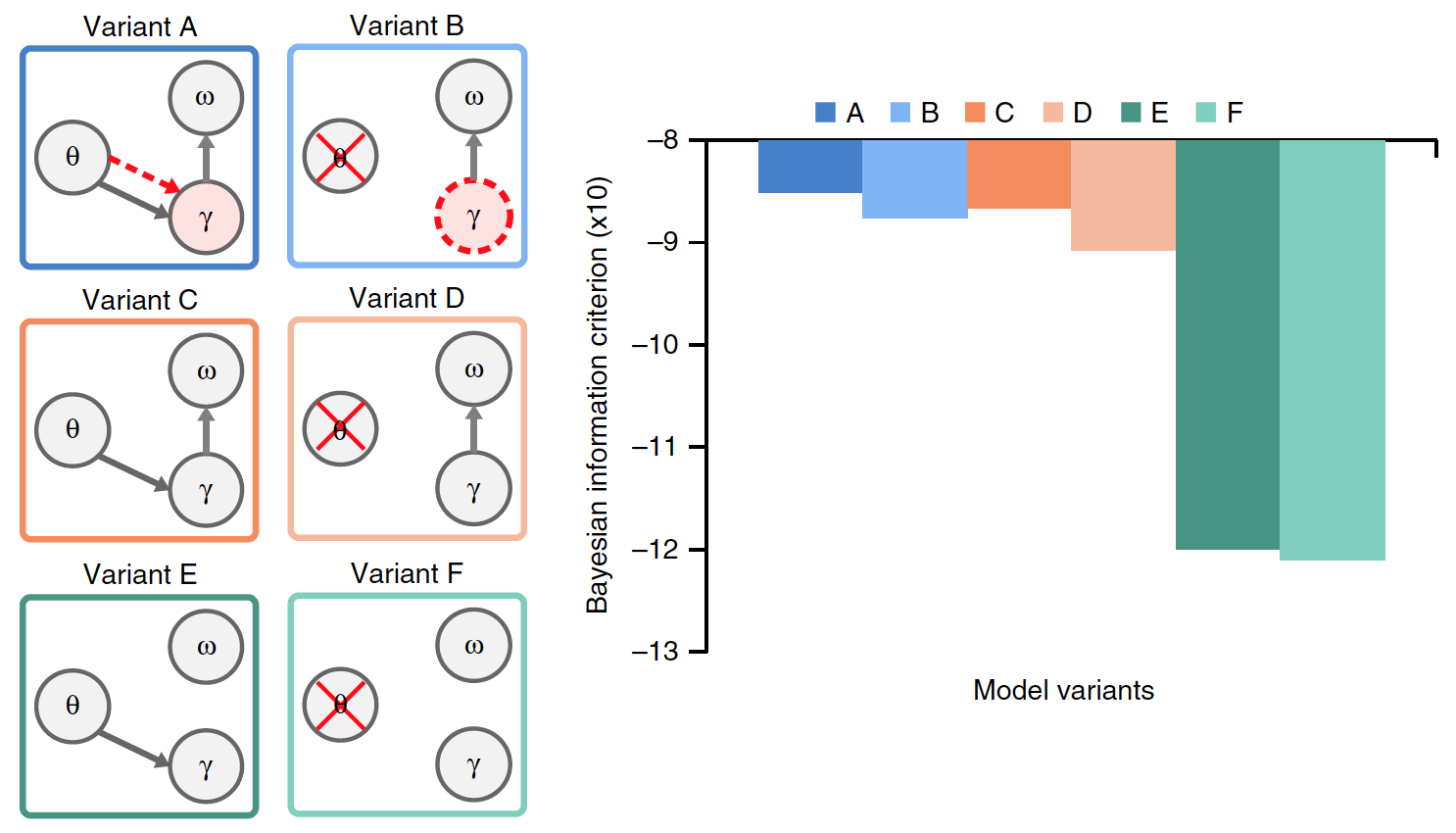
Imagem # 5
A opção A apresentou os maiores valores de BIC. Uma comparação anterior dos modelos A e B não conseguiu distinguir com precisão o desempenho. No entanto, graças ao critério BIC, ficou claro que a variante A fornece reconhecimento de sílaba mais confiante do que o modelo sem oscilações teta acionadas por estímulos (modelo B).
Para um conhecimento mais detalhado das nuances do estudo, recomendo examinar o relatório de cientistas emateriais adicionais para ele.
Epílogo
Resumindo os resultados acima, podemos dizer que o sucesso do modelo depende de dois fatores principais. O primeiro e mais importante é o despejo de dados acumulados com base nas informações do modelo sobre o conteúdo da sílaba (neste caso, sua estrutura espectral). O segundo fator é a relação entre os processos teta e gama, o que garante que a atividade gama seja incluída no ciclo teta, correspondendo à duração esperada de uma sílaba.
Em essência, o modelo desenvolvido imitava o trabalho do cérebro humano. O som que entra no sistema foi modulado por uma onda teta, remanescente da atividade neuronal. Isso permite definir os limites das sílabas. Além disso, ondas gama mais rápidas ajudam a codificar a sílaba. No processo, o sistema oferece possíveis sílabas e ajusta a seleção, se necessário. Saltando entre o primeiro e o segundo níveis (teta e gama), o sistema descobre a versão correta da sílaba e depois é redefinido para zero para iniciar o processo novamente para a próxima sílaba.
Durante os testes práticos, 2888 sílabas foram decodificadas com sucesso (foram usadas 220 frases de fala natural, inglês).
Este estudo não apenas combinou duas teorias opostas, colocando-as em prática como um sistema único, mas também tornou possível entender melhor como nosso cérebro percebe sinais de fala. Parece-nos que percebemos a fala "como ela é", ou seja, sem nenhum processo de suporte complicado. No entanto, dados os resultados da simulação, verifica-se que as oscilações teta e gama neurais permitem que nosso cérebro faça pequenas previsões sobre qual sílaba ouvimos, com base na qual a percepção da fala é formada.
Quem quer que diga alguma coisa, mas o cérebro humano às vezes parece muito mais misterioso e incompreensível do que os cantos inexplorados do Universo ou as profundezas sem esperança do Oceano Mundial.
Obrigado pela atenção, continuem curiosos e tenham uma boa semana de trabalho, pessoal. :)
Um pouco de publicidade
Obrigado por ficar com a gente. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos amigos o VPS na nuvem para desenvolvedores a partir de US $ 4,99 , um análogo exclusivo de servidores de nível básico que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10 GB DDR4 480 GB SSD 1 Gbps de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Apenas temos 2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre Como construir a infraestrutura do bldg. classe usando servidores Dell R730xd E5-2650 v4 que custam 9.000 euros por centavo?