
Na linguística computacional moderna, a compreensão do significado do que é escrito ou dito é alcançada usando modelos de linguagem natural (NLU). Com o crescimento gradual do público de assistentes virtuais da Salyut, surge a questão de otimizar nossos serviços que trabalham com linguagem natural. Para fazer isso, é aconselhável usar um modelo NLU forte para resolver vários problemas de processamento de texto de uma vez. Neste artigo, mostraremos como você pode usar o aprendizado multitarefa para melhorar as representações vetoriais e treinar um modelo NLU mais geral usando SBERT.
Os serviços de processamento de texto altamente carregados resolvem uma série de tarefas diferentes da PNL:
- Reconhecendo intenções.
- Destacando entidades nomeadas.
- Análise sentimental.
- Análise de toxicidade.
- Pesquise por consultas semelhantes.
Cada uma dessas tarefas tem suas especificidades e, de modo geral, requer a construção e o treinamento de um modelo separado. No entanto, é impraticável manter e executar um modelo NLU separado para cada uma dessas tarefas - o tempo de processamento da solicitação e a memória consumida (vídeo) aumentam muito. Em vez disso, usamos um modelo NLU forte para extrair recursos genéricos do texto. Além desses recursos, aplicamos modelos relativamente leves (adaptadores), que resolvem problemas de PNL aplicados. Ao mesmo tempo, o NLU e os adaptadores podem ser executados em máquinas diferentes, o que torna mais fácil implantar e dimensionar soluções.

Mas como tornar os recursos identificados pelo modelo básico de NLU universais o suficiente para que um modelo de PNL de alta qualidade possa ser construído sobre eles? Vamos descobrir.
Por tradição, apresentamos a implementação de nossa abordagem em Python 3 e TensorFlow 1.15. Um guia passo a passo completo e exemplos de código podem ser encontrados aqui - Colab .
Também apresentamos em um modelo russo atualizado disponível ao público SBERT-NLU classe BERT-large [427 milhões de opções.] Versão Multitask : abraçandoface [tensorflow, pytorch] .
Aprendizagem multitarefa. Por que isso é necessário?
Durante a operação de modelos NLU, descobrimos que os recursos alocados por modelos treinados para uma tarefa (por exemplo, NLI ) podem ser reutilizados com bastante sucesso para outras tarefas downstream (por exemplo, para classificação ou análise sentimental). Para isso, um modelo leve (adaptador), afiado para resolver um novo problema, é treinado nos vetores selecionados pelo modelo base. Isso não muda o modelo básico.
Ao mesmo tempo, a qualidade de tais modelos de adaptadores geralmente ainda é pior do que se treinássemos nosso modelo NLU para cada tarefa. O motivo é que os novos dados são usados apenas para modelos de adaptadores e não melhoram o modelo básico. A aprendizagem multitarefa nos ajuda a lidar com isso.
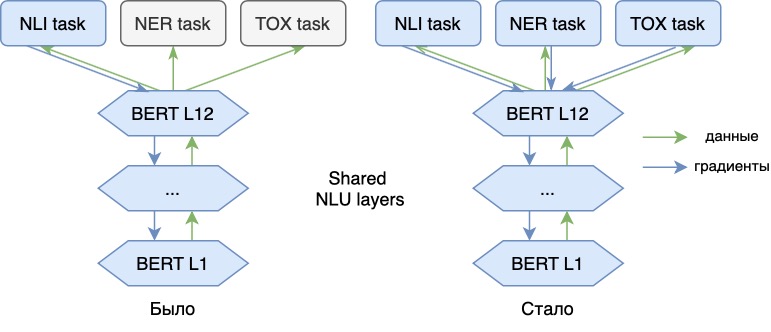
Agora treinamos o modelo de linguagem não apenas no problema principal de NLI, mas também em outros adicionais (NER, análise de toxicidade). Adicionar novas tarefas nos permite adicionar novos "significados" aos vetores do nosso modelo, tornando-os mais universais. Assim, o modelo poderá refletir em seus vetores informações, por exemplo, sobre os matizes emocionais da fala de uma frase ou sobre a classe gramatical de cada palavra do texto. Com representações vetoriais de tal modelo, esses problemas podem ser resolvidos de forma mais eficiente.
0. Experimento
Como exemplo, considere ensinar NLU em três tarefas:
- Representação de frase (NLI).
- Reconhecimento de entidade nomeada (NER).
- Análise de sentimentos.
Para ensinar a tarefa principal de vetorização de sentenças, nós, como da última vez , usamos um conjunto de dados para Inferência de Linguagem Natural , contendo pares de sentenças com rótulos que indicam uma consequência ("vinculação"), uma contradição ("contradição") ou a ausência de uma conexão semântica ("neutra") entre as frases. Para esses dados, com base no modelo de BERT, aprenderemos uma representação vetorial tal que a similaridade entre os pares de sentenças correspondentes será maior do que a similaridade entre conflitantes ou neutras entre si.
Vamos treinar o chefe do NER usando o conjunto de dadosda plataforma kaggle. Este modelo atribuirá cada token na proposta que está sendo processada a um dos vários tipos de entidades nomeadas IOB . Sua tarefa é uma classificação multiclasse.
Para o problema de análise de sentimento, vamos pegar os dados da competição Tweet Sentiment Extraction . A essência deste concurso é prever a cor emocional dos comentários nas postagens do Twitter. Existem três classes no conjunto de dados - cor positiva, neutra e negativa da réplica. Para este exemplo, vamos destacar apenas duas classes: positiva e negativa. A tarefa será uma classificação binária.
Usamos o inglês BERT-base pré-treinado como o modelo básico de vetorização.
Plano de experimento:
- Preparando conjuntos de dados.
- Implementação de gerador de lote.
- Determinação da função de perda.
- Construindo o modelo.
- Preparação do processo de validação.
- Treinamento de modelo.
- Discussão de resultados e conclusões.
1. Preparação de dados
Primeiramente, vamos carregar os conjuntos de dados necessários para treinar o modelo básico de vetorização de sentenças - [ SNLI , MNLI ] e para sua validação - [ STS SICK ]. Além disso, precisamos de um modelo de BERT em inglês pré-treinado. Felizmente, tudo isso é de domínio público:
Em seguida, vamos para a plataforma kaggle e baixamos os dados de lá para análise sentimental - aqui precisamos de train.csv. Para esses dados, vamos destacar exemplos negativos em uma classe separada e combinar o resto em um grupo comum (positivo, neutro):
Resta coletar os dados para NER e prepará-los no formato [text, ner_labels]:
2. Gerador de lote
Agora vamos escrever um procedimento para gerar um pacote de exemplos para treinar uma rede neural. Devido ao fato de que agora recebemos não um, mas já três
conjuntos de dados como entrada, também precisamos de mais geradores: para uma tarefa NLI, usando o gerador tripleto, geraremos triplos
[âncora, positivo, negativo]:
para problemas de classificação, NER e Toxic usam o mesmo gerador de dados gerando pares [amostra, etiqueta]. Aqui, selecionamos aleatoriamente vários exemplos com seus rótulos de classe dos conjuntos de dados fornecidos e formamos um pacote:
Finalmente, vamos combinar os três geradores em um gerador complexo comum que concatenará todos os três tipos de pacote de dados em um para treinar o modelo:
3. Função de perda
Agora, para cada tarefa, definimos nossa própria função de erro e, em seguida, os combinamos para a função de perda final:
- Também formularemos o problema de "convergência" de frases parafraseadas como um problema de classificação e usaremos a perda Softmax ligeiramente modificada, já conhecida em trabalhos anteriores, como uma função de erro :
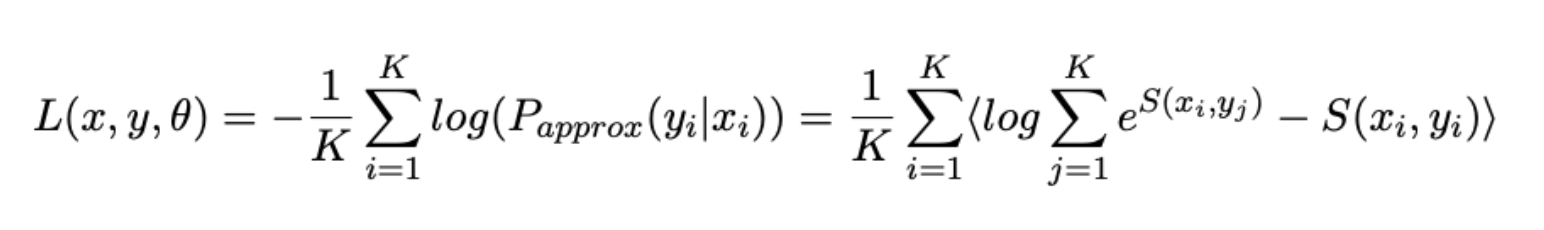
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
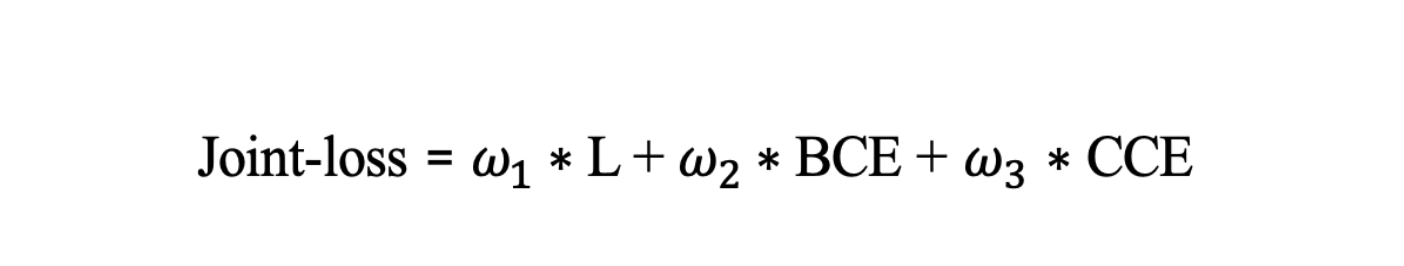
4.
Nosso modelo consiste na parte NLU principal (aqui usamos a base de BERT) e três adaptadores "cabeças", específicos para cada tarefa.
Para tarefas NLI e Toxic, usaremos embeddings de token médios da última camada de BERT (usamos pooling médio mascarado). Para a tarefa NER, usaremos embeddings de token da saída da 8ª camada do codificador. Ao ensinar representações no nível da sentença, os embeddings para problemas no nível do token são melhor retirados das camadas intermediárias do modelo.
Tem a seguinte aparência:

Arquitetura de modelo multitarefa
Código para montar o modelo:
5. Validação de resultados
Para validar o modelo de vetorização de sentenças, usamos os conjuntos de dados STS 2012–2016 e SICK 2014 .
Como SNLI, este conjunto de dados contém pares de sentenças. Vamos vetorizá-los com um modelo usando um modelo e estimar a similaridade entre as sentenças calculando a proximidade do cosseno entre seus vetores. Como métrica, calcularemos a correlação de classificação com rótulos do conjunto de dados.
Código de retorno de chamada contendo esta lógica:
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py .
A tarefa de determinar a toxicidade dos comentários será testada em relação à métrica AUC. O particionamento de dados é estratificado em relação à distribuição de classes.
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95 .
A qualidade da marcação NER será avaliada por duas métricas - precisão e medida F1.
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99 .
6. Processo de aprendizagem
Estamos na reta final. Agora temos: pipeline de dados, modelo e validação. Vamos passar para hiperparâmetros e recursos de aprendizagem.
De acordo com os clássicos, temos à disposição o Colab com acelerador de vídeo NVIDIA K80 (12GB) / T80 (16GB) - dependendo da sua atividade neste ambiente. Para que todo o nosso trabalho de arte multitarefa caiba na memória, é importante escolher o comprimento máximo correto da sequência processada (seq_len) e, é claro, o tamanho do lote.
Neste experimento, iremos novamente nos limitar a 24 tokens para a tarefa de frase, o que será suficiente para codificar a maioria dos dados usados no treinamento. Para sentimento e tarefa ner, use o mesmo comprimento de sequência.
Um aumento no tamanho do lote tem um efeito extremamente positivo na convergência do modelo - vamos escolher o máximo que caberá na memória do nosso GPU.
Como otimizador, usaremos o bom e velho Adam com uma pequena taxa de aprendizado . Vamos treinar o modelo antes da convergência, 25 épocas devem ser suficientes.
Parâmetros de treinamento:
- tamanho do lote = 96/72 para BERT-base (16 GB de memória ou 12 GB, respectivamente);
- max_seq_len = 24;
- Otimizador Adam;
- Taxa de aprendizagem ~ 2e-6;
- Métricas - [SpearmanR, F1, AUC];
- Número de épocas ~ 25.
Vamos comparar as métricas de adaptadores treinados com base nas versões antiga e nova do modelo SBERT.

Como você pode ver, devido ao treinamento adicional multitarefa, conseguimos aumentar significativamente a qualidade das tarefas adicionais NER e TOX. É importante que isso não prejudique a funcionalidade principal do modelo - as métricas nos conjuntos de dados STS e SICK permaneceram no mesmo nível.
7. Oportunidades para melhorias adicionais
Aumento
Como parte de nosso trabalho, usamos manipulações adicionais que ajudam a obter modelos mais precisos e estáveis.
Durante a geração do lote, aplicamos uma série de aumentos, entre os quais podem ser distinguidos os seguintes: no nível da letra, no nível da palavra, mudança de maiúsculas e minúsculas e remoção de pontuação.
No nível das letras, são:
1) remoção de "prvet";
2) repetir "saudações";
3) troca de dois símbolos adjacentes "Prievt";
4) substituição de uma tecla de fechamento no teclado "boas-vindas";
5) substituição por uma letra "olá" foneticamente próxima.
No nível da palavra, são:
1) trocar duas ou mais palavras;
2) inserção das palavras de parasitas - “bem, é o mesmo, por assim dizer”.
A fim de tornar o modelo mais resistente a alterações de maiúsculas e minúsculas e pontuação, a pontuação pode ser removida em alguns exemplos. Para um token aleatório, o registro pode ser alterado.
Aumentos relacionados à mudança de palavras e símbolos são aplicados para 3% do lote, e com pontuação e capitalização - para 30%.
8. Resultados e conclusões
Neste artigo, nos familiarizamos com o conceito de Multitask Leaning e aplicamos esse conhecimento para melhorar as representações vetoriais do modelo de linguagem.
Usando esses métodos, melhoramos o modelo NLU para o idioma russo SBERT-multitask e o publicamos . Treinamos ainda mais esta versão do modelo para resolver problemas de NER, análise de sentimento e análise de toxicidade.
Medimos as métricas para ambas as versões do modelo SBERT no benchmark dos modelos de língua russa RussianGLUE . Embora as tarefas RuGLUE não tenham participado do processo de retreinamento multitarefa, as métricas da segunda versão do modelo aumentaram ligeiramente. Ensinar o modelo a um problema ampliou seus horizontes e melhorou a qualidade em outros.

Pretendemos desenvolver ainda mais os modelos de linguagem natural SBERT. Entre as direções podem ser distinguidas: aceleração e destilação , melhoria da arquitetura básica e a adição de novas tarefas. Falaremos sobre eles nos próximos artigos. Se você está interessado em tecnologias de PNL e deseja implementá-las em novos produtos para um público amplo, venha até nós para uma entrevista .
Desejamos a você o melhor em sua pesquisa!
Obrigado por sua ajuda na preparação dos materiais para este artigo. Andriljo e Ibragim_bad...