
A natureza não tem mau tempo, todo tempo é graça. A letra dessa música lírica pode ser entendida figurativamente, interpretando o clima como uma relação entre as pessoas. Você pode entender literalmente, o que também é verdade, porque não haveria inverno com neve e frio, não valorizaríamos tanto o verão e vice-versa. Mas os veículos não tripulados são desprovidos de sentimentos líricos e perspectiva poética, para eles nem todo o tempo é bom, especialmente o inverno. Um dos principais problemas enfrentados pelos desenvolvedores de "veículos robóticos" é a diminuição da precisão dos sensores que dizem ao carro para onde ir em más condições climáticas. Cientistas da Universidade Tecnológica de Michigan criaram um banco de dados das condições meteorológicas nas estradas "através dos olhos" de veículos não tripulados. Esses dados eram necessários para entender o que precisa ser alterado ou melhorado para que a visão dos veículos robóticos durante uma tempestade de neve não seja pior,do que em um dia claro de verão. Quão ruim o tempo afeta os sensores de veículos não tripulados, que método de resolução do problema os cientistas propõem e qual é sua eficácia? Encontraremos respostas para essas perguntas no relatório dos cientistas. Vai.
Base de pesquisa
A operação de carros autônomos pode ser comparada a uma equação na qual existem muitas variáveis que devem ser levadas em consideração, sem exceção, para obter o resultado correto. Pedestres, outros carros, a qualidade da superfície da estrada (visibilidade das linhas divisórias), a integridade dos sistemas do próprio drone, etc. Muitas pesquisas de cientistas, declarações provocativas de políticos, artigos cortantes de jornalistas baseiam-se na conexão entre um veículo não tripulado (doravante simplesmente um carro ou um carro) e um pedestre. Isso é bastante lógico, porque uma pessoa e sua segurança devem vir em primeiro lugar, especialmente dada a imprevisibilidade de seu comportamento. As disputas morais e éticas sobre quem será o culpado se um carro bater em um pedestre que pulou na estrada continuam até hoje.
No entanto, se removermos a variável "pedestre" de nossa equação figurativa, ainda haverá muitos fatores potencialmente perigosos. O clima é um deles. Obviamente, com mau tempo (chuva ou neve), a visibilidade pode diminuir tanto que às vezes você só tem que parar, porque não é realista dirigir. A visão dos carros, é claro, é difícil de comparar com a visão de uma pessoa, mas seus sensores sofrem com a visibilidade reduzida tanto quanto nós. Por outro lado, os carros possuem um arsenal mais amplo desses sensores: câmeras, radares de ondas milimétricas (MMW), sistema de posicionamento global (GPS), estabilizador giroscópico (IMU), detecção e alcance de luz (LIDAR) e até sistemas ultrassônicos. Apesar dessa variedade de sentidos, os carros autônomos ainda ficam cegos durante o mau tempo.
Para entender qual é o problema, os cientistas propõem-se a considerar aspectos cuja combinação de uma forma ou de outra afeta uma possível solução para este problema: segmentação semântica, detecção de um caminho passável (adequado) e combinação de sensores.
Com a segmentação semântica, em vez de detectar um objeto em uma imagem, cada pixel é classificado individualmente e atribuído à classe que o pixel melhor representa. Em outras palavras, a segmentação semântica é uma classificação em nível de pixel. A segmentação semântica clássica - rede neural convolucional (CNN da rede neural convolucional A ) - consiste em redes de codificação e decodificação.
A rede de codificação reduz a resolução dos dados de entrada e extrai funções, e a rede de decodificação usa essas funções para recuperar e aumentar a amostragem dos dados de entrada e, finalmente, atribui uma classe a cada pixel.
Os dois componentes principais na decodificação de redes são a chamada camada MaxUnpooling e a camada de convolução Transpose. A camada MaxUnpooling (um análogo da camada MaxPooling - uma operação de agrupamento com uma função máxima) é necessária para reduzir a dimensão dos dados processados.
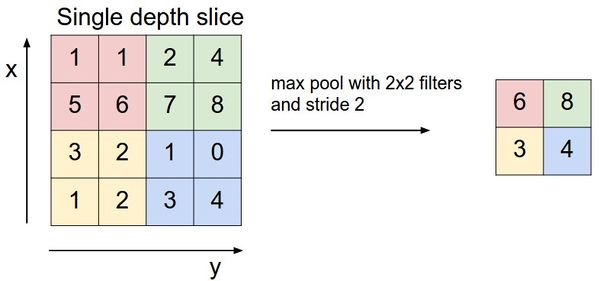
Um exemplo da operação MaxPooling.
Existem vários métodos para distribuir valores (ou seja, puxar) que têm o objetivo comum de armazenar os locais dos valores máximos na camada MaxPooling e usar esses locais para colocar os valores máximos de volta em locais correspondentes no camada MaxUnpooling correspondente. Essa abordagem requer que a rede de codecs seja simétrica, em que cada nível MaxPooling no codificador tem um nível MaxUnpool correspondente no lado do decodificador.
Outra abordagem é colocar os valores em um local predeterminado (por exemplo, no canto superior esquerdo) na área para a qual o kernel aponta. Foi esse método que foi usado na modelagem, que será discutido um pouco mais tarde.
Uma camada convolucional transposta é o oposto de uma camada convolucional regular. Consiste em um núcleo móvel que varre a entrada e convolve os valores para preencher a imagem de saída. O volume de saída de ambas as camadas, MaxUnpooling e Transpose, pode ser controlado ajustando o tamanho do kernel, preenchimento e pitch.
O segundo aspecto, que desempenha um papel importante na resolução do problema do mau tempo, é a detecção de um caminho transitável.
Um caminho percorrível é um espaço no qual um carro pode se mover com segurança no sentido físico, ou seja, detecção de faixa de rodagem. Este aspecto é extremamente importante para várias situações: estacionamento, sinalização ruim da estrada, visibilidade ruim, etc.
De acordo com os cientistas, a detecção de um caminho transitável pode ser implementada como uma etapa preliminar para detectar uma pista ou qualquer objeto. Esse processo decorre da segmentação semântica, cujo objetivo é gerar uma classificação pixel a pixel após o treinamento em um conjunto de dados mapeado por pixel.
O terceiro aspecto, mas não menos importante, é a fusão de sensores. Isso significa literalmente combinar dados de vários sensores para obter uma imagem mais completa e reduzir os prováveis erros e imprecisões nos dados de sensores individuais. Existe um agrupamento homogêneo e heterogêneo de sensores. Um exemplo do primeiro seria o uso de vários satélites para refinar uma posição GPS. Um exemplo do segundo é a combinação de dados da câmera, LiDAR e Radar para carros autônomos.
Cada um dos sensores acima, individualmente, mostra resultados excelentes, mas apenas em condições climáticas normais. Em condições de trabalho mais duras, suas deficiências tornam-se evidentes.
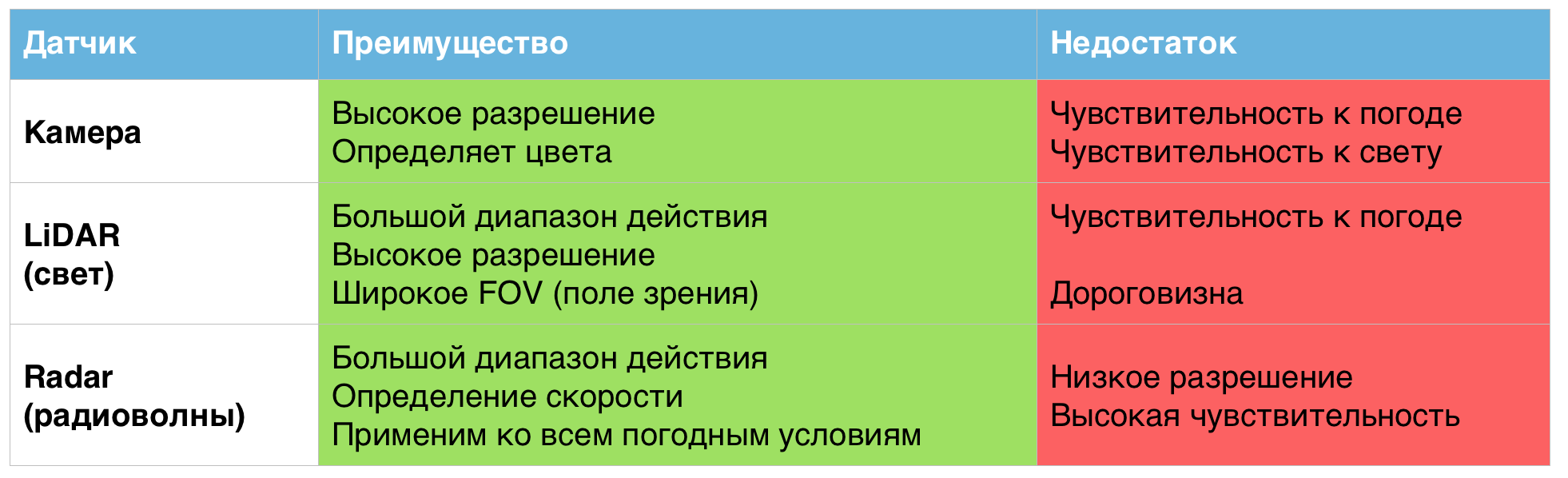
Uma tabela das vantagens e desvantagens dos sensores usados em veículos não tripulados.
É por isso que, segundo os cientistas, combinar esses sensores em um único sistema pode ajudar a resolver problemas associados a más condições climáticas.
Coleção de dados
Neste estudo, como mencionado anteriormente, as redes neurais convolucionais e a fusão de sensores foram usadas para resolver o problema de encontrar um caminho para dirigir em condições climáticas adversas. O modelo proposto é uma rede neural convolucional profunda multi-threaded (um thread por sensor) que reduzirá a amostragem dos mapas de função (o resultado da aplicação de um filtro à camada anterior) de cada fluxo, combinará os dados e, em seguida, aumentará novamente a mapas para realizar a classificação pixel a pixel.
Para realizar mais trabalhos, incluindo cálculos, modelagem e testes, muitos dados eram necessários. Quanto mais, melhor, dizem os próprios cientistas, e isso é bastante lógico quando se trata da operação de vários sensores (câmeras, LiDAR e Radar). Entre os muitos conjuntos de dados já existentes, o DENSE foi escolhido, que cobre a maioria das nuances necessárias para a pesquisa.
DENSOtambém é um projeto que visa resolver os problemas de encontrar um caminho em condições climáticas severas. Os cientistas que trabalharam no DENSE viajaram cerca de 10.000 km pelo norte da Europa, gravando dados de várias câmeras, vários LiDARs, radares, GPS, IMUs, sensores de atrito de estrada e câmeras de imagem térmica. O conjunto de dados consiste em 12.000 amostras, que podem ser divididas em subgrupos menores que descrevem condições específicas: dia + neve, noite + nevoeiro, dia + céu limpo, etc.
Porém, para que o modelo funcionasse corretamente, foi necessário corrigir os dados do DENSE. As imagens da câmera original no conjunto de dados têm 1920 x 1024 pixels e foram reduzidas para 480 x 256 para treinamento e teste de modelo mais rápidos.
Os dados LiDAR são armazenados em um formato de matriz NumPy que precisava ser convertido em imagens, dimensionado (até 480 x 256) e normalizado.
Os dados do radar são armazenados em arquivos JSON, um arquivo para cada quadro. Cada arquivo contém um dicionário de objetos detectados e vários valores para cada objeto, incluindo coordenadas x, coordenadas y, distância, velocidade, etc. Este sistema de coordenadas é paralelo ao plano do veículo. Para convertê-lo em um plano vertical, apenas a coordenada y precisa ser considerada.
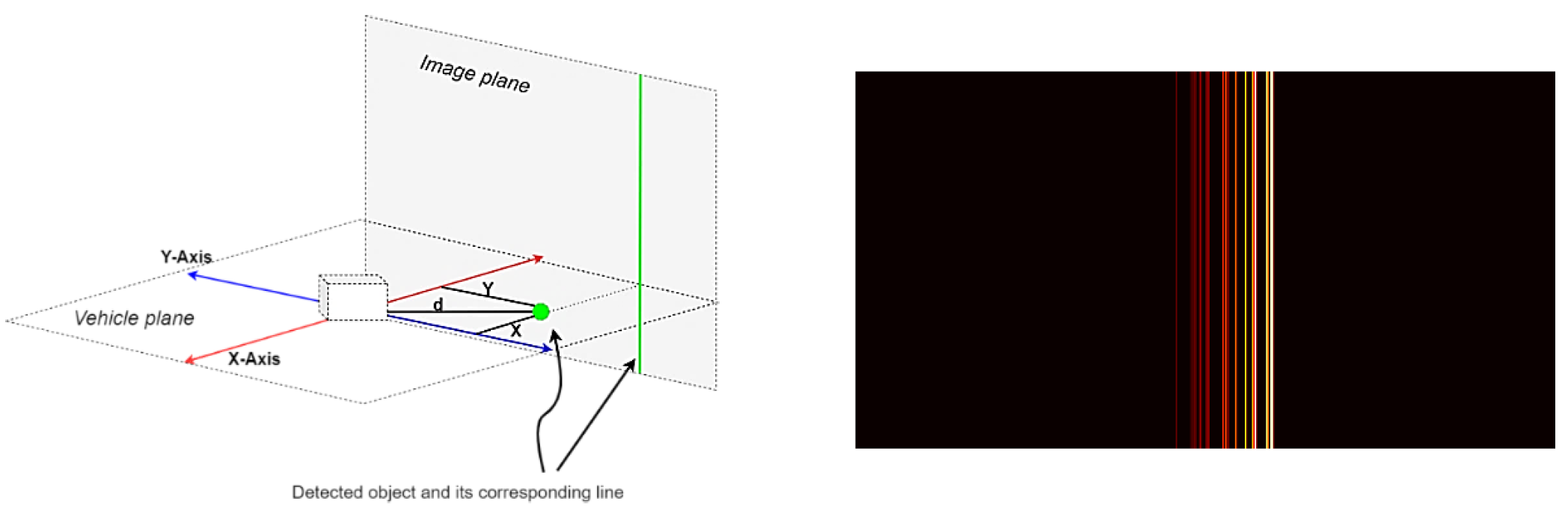
Imagem # 1: projeção da coordenada y no plano da imagem (esquerda) e o quadro de radar processado (direita).
As imagens resultantes foram dimensionadas (até 480 x 256) e normalizadas.
Desenvolvendo um modelo CNN
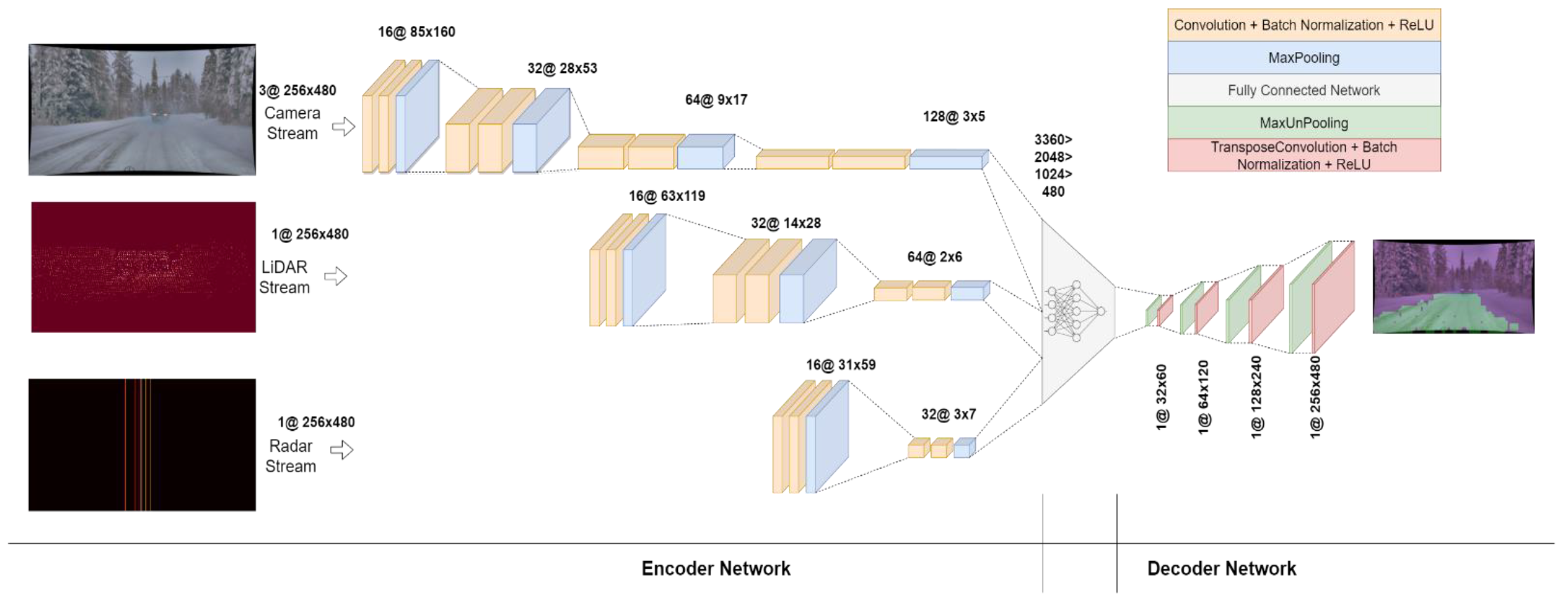
Imagem # 2: A arquitetura do modelo da CNN.
A rede foi projetada para ser o mais compacta possível, já que redes profundas de codecs requerem muitos recursos computacionais. Por esse motivo, a rede de decodificação não foi projetada com tantas camadas quanto a rede de codificação. A rede de codificação consiste em três fluxos: câmera, LiDAR e radar.
Como as imagens da câmera contêm mais informações, o fluxo da câmera é mais profundo do que os outros dois. Ele consiste em quatro blocos, cada um dos quais consiste em duas camadas convolucionais - uma camada de normalização de lote e uma camada ReLU, seguida por uma camada MaxPooling.
Os dados LiDAR não são tão massivos quanto os dados das câmeras, portanto, seu fluxo consiste em três blocos. Da mesma forma, o fluxo Radar é menor do que o fluxo LiDAR, portanto, consiste em apenas dois blocos.
A saída de todos os fluxos é modificada e combinada em um vetor unidimensional que é conectado a uma rede de três camadas ocultas com ativação ReLU. Os dados são então convertidos em uma matriz bidimensional, que é passada para uma rede de decodificação que consiste em quatro MaxUnpool consecutivos e etapas de convolução transpostas para fazer uma amostra dos dados para um tamanho de entrada (480x256).
Resultados de treinamento / teste de modelo da CNN
O treinamento e os testes foram feitos no Google Colab usando GPU. O subconjunto de dados marcados à mão consistia em 1000 câmeras, LiDAR e amostras de dados de radar - 800 para treinamento e 200 para teste.
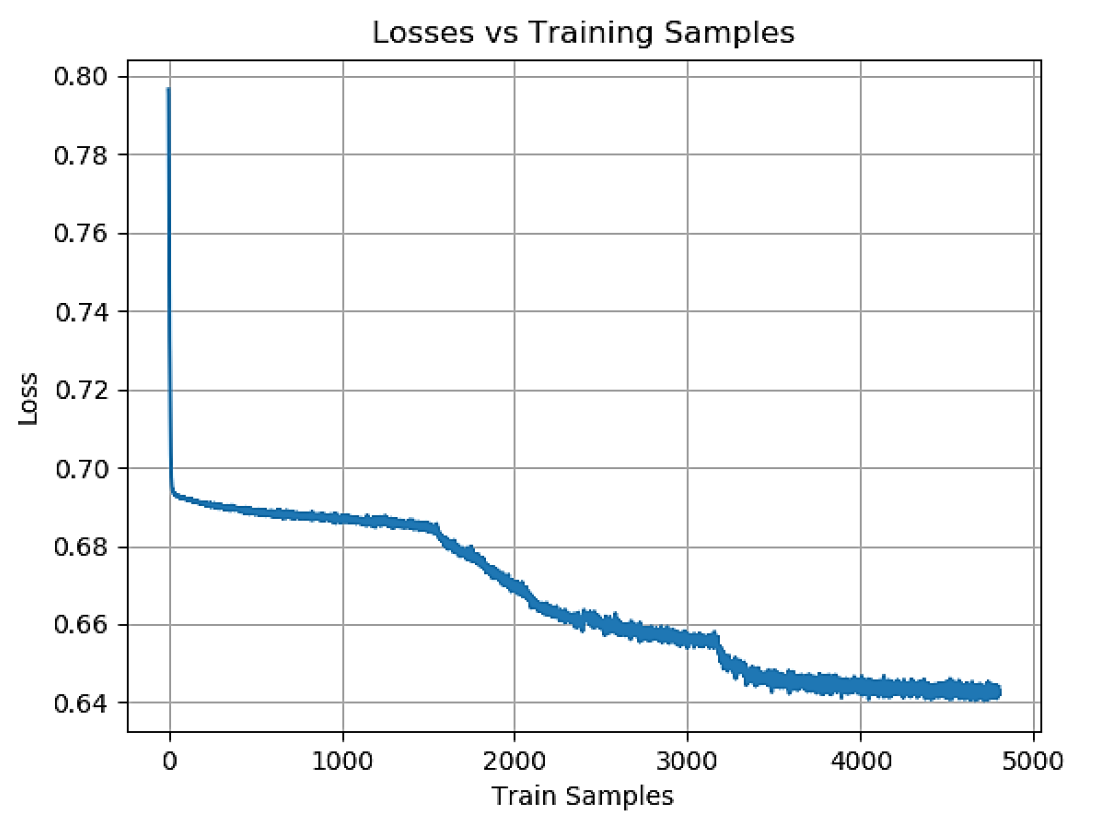
Imagem nº 3: Perda em amostras de treinamento durante a fase de treinamento.
A saída do modelo foi pós-processada com expansão e erosão da imagem com diferentes tamanhos de kernel para reduzir a quantidade de ruído na saída de classificação de pixel.
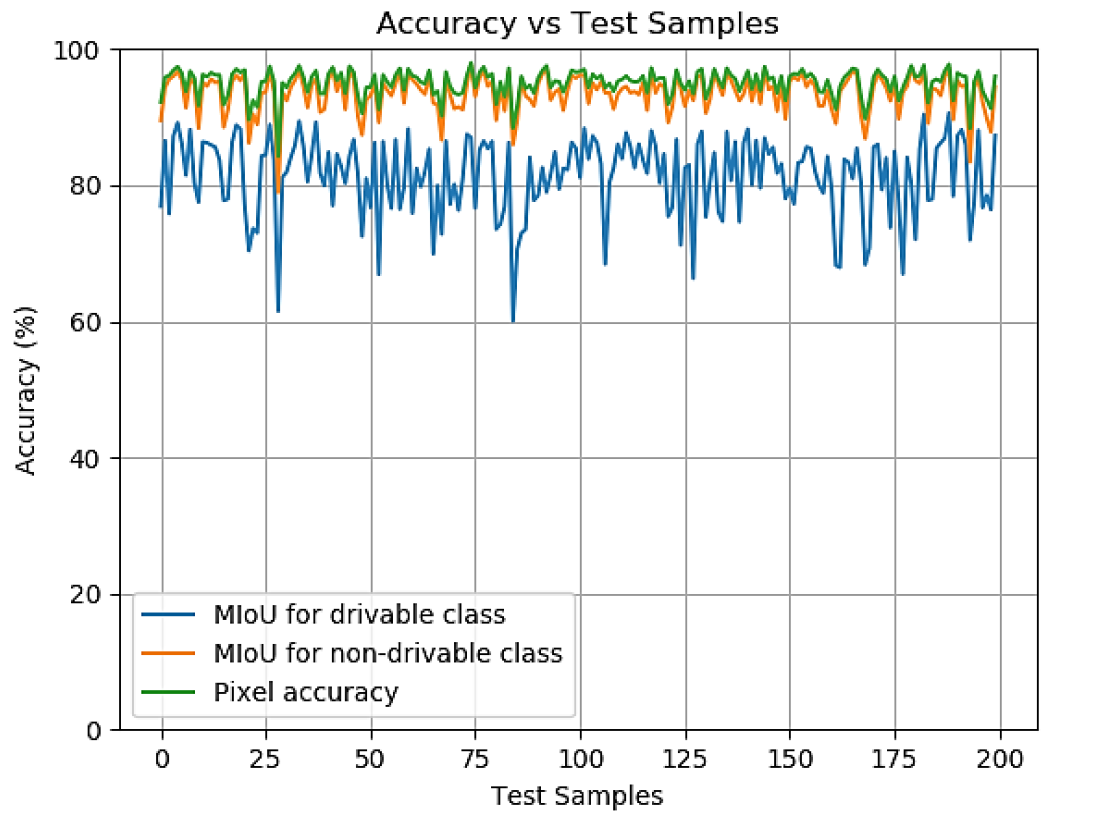
Imagem nº 4: precisão em amostras de teste durante a fase de teste.
Os cientistas observam que o indicador mais simples de precisão do sistema é o pixel, ou seja, a proporção de pixels definidos corretamente e pixels definidos incorretamente para o tamanho da imagem. A precisão do pixel foi calculada para cada amostra no conjunto de teste, e a média desses valores representa a precisão geral do modelo.
No entanto, esse número não é o ideal. Em alguns casos, uma determinada classe está subrepresentada na amostra, da qual a precisão do pixel será significativamente maior (do que realmente é) devido ao fato de que não há pixels suficientes para testar o modelo para uma determinada classe. Portanto, foi decidido usar adicionalmente MIoU - a proporção média da área de interseção para a área de união.
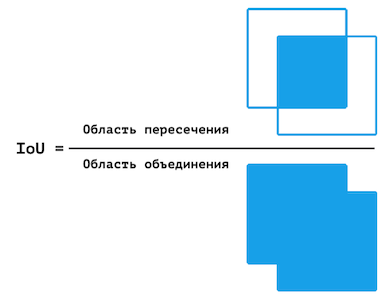
Representação visual da IoU.
Semelhante à precisão do pixel, a precisão IoU é calculada para cada quadro, e a precisão final é a média desses valores. No entanto, MIoU é calculado para cada classe separadamente.

Tabela de valores de precisão.

Imagem # 5
A imagem acima mostra quatro quadros selecionados do movimento da neve da câmera, LiDAR, radar, dados de solo e saída do modelo. É evidente a partir dessas imagens que o modelo pode delinear a circunferência geral da área em que o veículo pode se mover com segurança. O modelo ignora quaisquer linhas e bordas que poderiam ser interpretadas como bordas da faixa de rodagem. O modelo também funciona bem em condições de baixa visibilidade (por exemplo, nevoeiro).
O modelo também evita pedestres, outros carros e animais, embora esse não tenha sido o objetivo principal deste estudo em particular. No entanto, este aspecto particular precisa ser melhorado. No entanto, como o sistema consiste em menos camadas, ele aprende muito mais rápido do que seus predecessores.
Para um conhecimento mais detalhado das nuances do estudo, recomendo que você leia o relatório dos cientistas e dados adicionais a ele.
Epílogo
A atitude em relação aos carros autônomos é ambígua. Por outro lado, o carro-robô nega riscos como o fator humano: motorista bêbado, imprudência, atitude irresponsável em relação às regras de trânsito, pouca experiência de direção, etc. Em outras palavras, o robô não se comporta como um humano. Isso é bom, não é? Sim e não. Os veículos autônomos superam os motoristas de carne e osso em muitos aspectos, mas não em todos. O mau tempo é um excelente exemplo disso. É claro que não é fácil para uma pessoa dirigir durante uma tempestade de neve, mas para veículos não tripulados isso era quase irreal.
Nesse trabalho, os cientistas chamaram a atenção para esse problema, propondo tornar as máquinas um pouco mais humanas. O fato é que uma pessoa também possui sensores que trabalham em equipe para garantir que ela receba o máximo de informações sobre o ambiente. Se os sensores de um veículo não tripulado também funcionarem como um único sistema, e não como elementos separados dele, será possível obter mais dados, ou seja, para melhorar a precisão de encontrar o caminho transitável.
Claro, mau tempo é um termo coletivo. Para alguns, neve leve é mau tempo, mas para outros é uma tempestade de granizo. Pesquisas e testes adicionais do sistema desenvolvido devem ensiná-lo a reconhecer a estrada em todas as condições climáticas.
Obrigado pela atenção, fiquem curiosos e tenham uma boa semana de trabalho, pessoal. :)
Um pouco de publicidade
Obrigado por ficar com a gente. Você gosta de nossos artigos? Quer ver mais conteúdo interessante? Apoie-nos fazendo um pedido ou recomendando a amigos VPS em nuvem para desenvolvedores a partir de US $ 4,99 , um análogo exclusivo de servidores de nível de entrada que inventamos para você: The Whole Truth About VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps a partir de US $ 19 ou como dividir o servidor corretamente? (opções disponíveis com RAID1 e RAID10, até 24 núcleos e até 40 GB DDR4).
O Dell R730xd 2x é mais barato no data center Maincubes Tier IV em Amsterdã? Apenas temos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda!Dell R420 - 2x E5-2430 2.2 Ghz 6C 128 GB DDR3 2x960 GB SSD 1 Gbps 100 TB - a partir de $ 99! Leia sobre como construir a infraestrutura do Bldg. classe com o uso de servidores Dell R730xd E5-2650 v4 a um custo de 9.000 euros por um centavo?