
Em uma série de artigos, quero refutar os equívocos associados ao gerenciamento de memória e dar uma olhada mais profunda em sua estrutura em algumas linguagens de programação modernas - Java, Kotlin, Scala, Groovy e Clojure. Esperançosamente, este artigo ajudará você a descobrir o que está acontecendo nos bastidores dessas linguagens. Primeiro, veremos o gerenciamento de memória na Java Virtual Machine (JVM) , que é usado em Java, Kotlin, Scala, Clojure, Groovy e outras linguagens. No primeiro artigo, também cobri a diferença entre uma pilha e um heap, o que é útil para entender este artigo.
Estrutura de memória JVM
Primeiro, vamos dar uma olhada na estrutura de memória da JVM. Essa estrutura é usada desde o JDK 11 . É a memória que está disponível para o processo JVM, ela é alocada pelo sistema operacional:
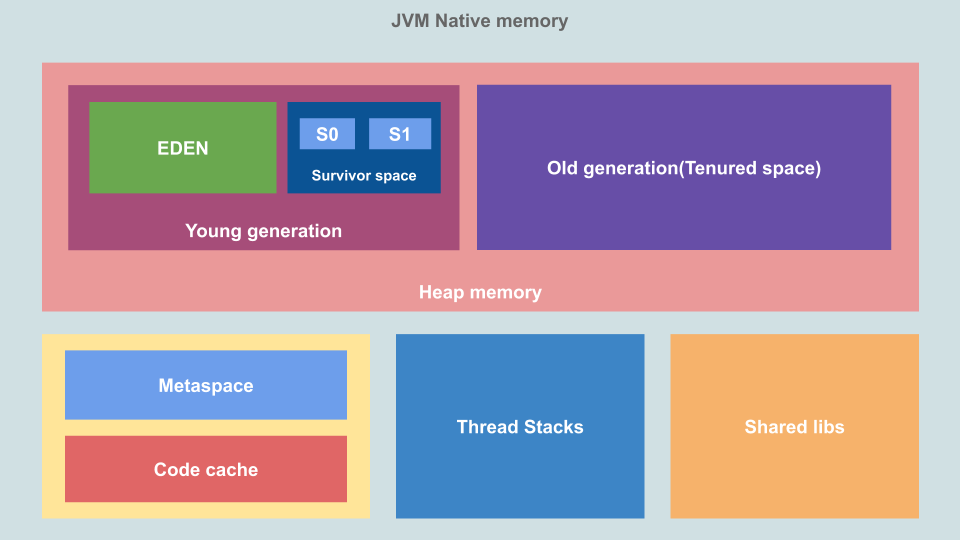
Esta é a memória nativa alocada pelo SO e seu tamanho depende do sistema, processador e JRE. Quais são as áreas e para que se destinam?
Heap
É aqui que a JVM armazena objetos e dados dinâmicos. Esta é a maior área de memória e é onde o coletor de lixo funciona. O tamanho do heap pode ser controlado com os sinalizadores
Xms
(tamanho inicial) e
Xmx
(tamanho máximo). O heap não é transferido para a máquina virtual como um todo, alguma parte é reservada como espaço virtual, devido ao qual o heap pode crescer no futuro. O acervo está dividido em espaços da geração "jovem" e "velha".
- A geração jovem , ou "novo espaço": a área em que vivem novos objetos. É dividido em Eden Space e Survivor Space. A área de controle da geração jovem, “ o jovem catador » (GC Menor), que também é chamado de “o jovem» (GC Jovem).
- Paraíso : é onde a memória é alocada quando criamos novos objetos.
- Área do sobrevivente : é onde os objetos que sobraram do coletor de lixo secundário são armazenados. A área é dividida em duas metades, S0 e S1 .
- Geração antiga , ou "armazenamento" (Espaço Tenured): Inclui objetos que atingiram o limite máximo de armazenamento durante a vida de um coletor de lixo júnior. Este espaço é administrado por um GC Major.
Pilhas de linha
Esta é uma área de pilha na qual uma pilha é alocada por encadeamento. É aqui que os dados estáticos específicos do thread são armazenados, incluindo quadros de método e função e ponteiros para objetos. O tamanho da memória da pilha pode ser definido usando um sinalizador
Xss
.
Metaspace
Isso faz parte da memória nativa, por padrão não tem limite superior. Em versões anteriores da JVM, essa memória é chamada de espaço de geração permanente ( Espaço de Geração Permanente (PermGen)) . Os carregadores de classes armazenaram definições de classes nele. Se esse espaço aumentar, o sistema operacional pode mover os dados armazenados aqui da RAM para a memória virtual, o que pode tornar o aplicativo lento. Isso pode ser evitado definindo o tamanho do MetaSpace por meio de sinalizadores
XX:MetaspaceSize
e
-XX:MaxMetaspaceSize
, neste caso, o aplicativo pode emitir um erro de memória.
Cache de código
É aqui que o compilador Just In Time (JIT) armazena blocos compilados de código que você precisa acessar com freqüência. Normalmente a JVM interpreta o bytecode em código de máquina nativo, porém o código compilado pelo compilador JIT não precisa ser interpretado, ele já está em formato nativo e armazenado em cache nesta área de memória.
Bibliotecas compartilhadas
É aqui que o código nativo de qualquer biblioteca compartilhada é armazenado. Essa área da memória é carregada pelo sistema operacional apenas uma vez para cada processo.
Uso de memória JVM: pilha e heap
Agora, vamos dar uma olhada em como o programa executável usa as partes mais importantes da memória. Vamos usar o código abaixo. Ele não é otimizado para correção, portanto, ignore problemas como variáveis intermediárias desnecessárias, modificadores incorretos e muito mais. Seu trabalho é visualizar o uso da pilha e do heap.
class Employee {
String name;
Integer salary;
Integer sales;
Integer bonus;
public Employee(String name, Integer salary, Integer sales) {
this.name = name;
this.salary = salary;
this.sales = sales;
}
}
public class Test {
static int BONUS_PERCENTAGE = 10;
static int getBonusPercentage(int salary) {
int percentage = salary * BONUS_PERCENTAGE / 100;
return percentage;
}
static int findEmployeeBonus(int salary, int noOfSales) {
int bonusPercentage = getBonusPercentage(salary);
int bonus = bonusPercentage * noOfSales;
return bonus;
}
public static void main(String[] args) {
Employee john = new Employee("John", 5000, 5);
john.bonus = findEmployeeBonus(john.salary, john.sales);
System.out.println(john.bonus);
}
}
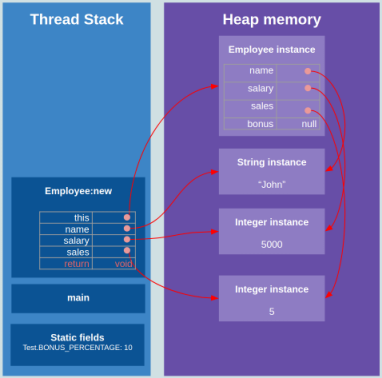
Aqui você pode ver como o programa acima é executado e como a pilha e o heap são usados:
https://files.speakerdeck.com/presentations/9780d352c95f4361 Budapc6fa164554afc / JVM_memory_use.pdf
Como você pode ver:
- Cada chamada de função é enviada para o encadeamento da pilha de execução como um bloco de quadros.
- Todas as variáveis locais, incluindo argumentos e valores de retorno, são armazenadas na pilha dentro dos blocos de quadro de função.
- int .
- Employee, Integer String , . .
- , , .
- , .
- ().
- , .
A pilha é gerenciada automaticamente pelo sistema operacional, não pela JVM. Portanto, não há necessidade de ter um cuidado especial com ele. Mas o heap não é mais gerenciado dessa maneira e, como essa é a maior área da memória que contém dados dinâmicos, ele pode crescer exponencialmente e o programa pode ocupar toda a memória com o tempo. Além disso, o heap se torna gradualmente fragmentado, diminuindo assim o desempenho dos aplicativos. O JVM ajudará a resolver esses problemas. Ele gerencia automaticamente o heap usando a coleta de lixo.
Gerenciamento de memória JVM: coleta de lixo
Vamos dar uma olhada no gerenciamento automático de heap, que desempenha um papel muito importante no desempenho do aplicativo. Quando um programa tenta alocar mais memória na pilha do que está disponível (dependendo do valor
Xmx
), obtemos erros de falta de memória .
A JVM gerencia o heap usando a coleta de lixo. Para abrir espaço para a criação de um novo objeto, a JVM limpa a memória ocupada por objetos órfãos, ou seja, objetos que não são mais direta ou indiretamente referenciados na pilha.
O coletor de lixo JVM é responsável por:
- Obtendo memória do sistema operacional e devolvendo-a ao sistema operacional.
- Transferência de memória alocada para o aplicativo mediante solicitação.
- Determine quais partes da memória alocada ainda estão em uso pelo aplicativo.
- Reivindicação de memória não utilizada para uso pelo aplicativo.
Os coletores de lixo na JVM funcionam em uma base geracional (os objetos no heap são agrupados por idade e limpos durante diferentes estágios). Existem muitos algoritmos de coleta de lixo diferentes, mas Mark & Sweep é o mais comumente usado .
Marca e varredura do coletor de lixo
A JVM usa um encadeamento daemon separado que é executado em segundo plano para a coleta de lixo. Este processo começa quando certas condições são atendidas. O coletor Mark & Sweep geralmente funciona em dois estágios, às vezes um terceiro é adicionado, dependendo do algoritmo usado.

- Marcação : primeiro, o coletor determina quais objetos estão em uso e quais não estão. Aqueles usados ou acessados por ponteiros de pilha são recursivamente marcados como vivos.
- Remoção : O coletor percorre o heap e remove todos os objetos que não estão marcados como vivos. Esses locais de memória são marcados como livres.
- Compressão : Depois de remover os objetos não usados, todos os objetos sobreviventes são movidos para que fiquem juntos. Isso reduz a fragmentação e acelera a alocação de memória para novos objetos.
Esse tipo de coletor também é chamado de stop-the-world, pois enquanto são removidos, ocorrem pausas no aplicativo.
A JVM oferece vários algoritmos de coleta de lixo diferentes para escolher e, dependendo do seu JDK, pode haver ainda mais opções (por exemplo, o coletor Shenandoah no OpenJDK). Autores de diferentes implementações visam a diferentes objetivos:
- Taxa de transferência : tempo gasto na coleta de lixo, não executando o aplicativo. O ideal é que a taxa de transferência seja alta, ou seja, as pausas da coleta de lixo são curtas.
- Duração das pausas : Quanto tempo o coletor de lixo interfere na execução do aplicativo. Idealmente, as pausas devem ser muito curtas.
- Tamanho do heap : Idealmente, deve ser pequeno.
Colecionadores em JDK 11
JDK 11 é a versão LTE atual. Abaixo está uma lista dos coletores de lixo disponíveis nele, e a JVM escolhe um por padrão, dependendo do hardware e sistema operacional atuais. Sempre podemos forçar um seletor a ser selecionado usando um botão de opção
-XX
.
- : , , .
-XX:+UseSerialGC
. - : , . , / .
-XX:+UseParallelGC
. - Garbage-First (G1): ( ). , . .
-XX:+UseG1GC
. - Z: , , JDK11. . , stop-the-world. , / ( ).
-XX:+UseZGC
.
Independentemente de qual coletor é selecionado, a JVM usa dois tipos de montagem - o coletor júnior e o coletor sênior.
Montador Júnior
Ele mantém a limpeza e compactação do espaço da geração mais jovem. Ele é iniciado quando a JVM não pode obter a memória necessária no céu para acomodar um novo objeto. Inicialmente, todas as áreas do heap estão vazias. O paraíso se enche primeiro, seguido pela área dos sobreviventes e, no final, pelo armazenamento.
Você pode ver o processo desse coletor aqui:
https://files.speakerdeck.com/presentations/f4783404769145f4b990154d0cc05629/JVM_minor_GC.pdf
- Digamos que já existam objetos no paraíso (os blocos 01 a 06 estão marcados como sendo usados).
- O aplicativo cria um novo objeto (07).
- JVM , , JVM .
- ( ), — ().
- JVM S0 S1 «» (To Space), S0. «» , , , .
- , .
- , - , ( 07 13 ).
- (14).
- JVM , , JVM .
- , , « ».
- JVM «» S1, S0 «». «» «» (S1), , . , «», , (premature promotion). , .
- «» (S0), .
- Isso é repetido a cada sessão de colecionador júnior, os sobreviventes se movem entre S0 e S1 e sua idade aumenta. Quando atinge o "limite máximo" especificado, que é 15 por padrão, o objeto é movido para o "armazenamento".
Vimos como o colecionador júnior limpa a memória no espaço da geração mais jovem. Este é um processo de parar o mundo, mas é tão rápido que sua duração geralmente pode ser negligenciada.
Montador Sênior
Monitora a limpeza e compactação do espaço da antiga geração (armazenamento). É executado sob uma das seguintes condições:
- O desenvolvedor chama no programa
System
.gc()
ouRuntime.getRunTime().gc()
. - A JVM decide que o armazenamento está sem memória porque está cheio como resultado de sessões anteriores do coletor júnior.
- Se, durante a execução do coletor júnior, o JVM não conseguir memória suficiente no paraíso ou na área de sobrevivência.
- Se definirmos um parâmetro na JVM
MaxMetaspaceSize
e não houver memória suficiente para carregar novas classes.
O processo de trabalho do coletor sênior é mais simples do que o júnior:
- Digamos que muitas sessões de colecionador júnior tenham se passado e o armazenamento esteja quase cheio. A JVM decide executar o coletor mais antigo.
- No armazenamento, ele percorre recursivamente o gráfico do objeto a partir de ponteiros da pilha e marca os objetos usados como (memória usada), o resto como lixo (perdido). Se o colecionador sênior foi lançado durante o trabalho do colecionador júnior, então seu trabalho cobre o espaço da geração mais jovem (paraíso e a área dos sobreviventes) e o cofre.
- O coletor remove todos os objetos órfãos e recupera a memória.
- Se não houver objetos deixados no heap durante o trabalho do coletor mais antigo, a JVM também recupera a memória do metaspace, removendo as classes carregadas dele, se for uma coleta de lixo completa.
Conclusão
Abordamos a estrutura e o gerenciamento de memória da JVM. Este não é um artigo completo, não falamos sobre muitos dos conceitos e maneiras mais complexos de customizar para casos de uso específicos. Você pode ler mais detalhes aqui .
Mas para a maioria dos desenvolvedores de JVM (Java, Kotlin, Scala, Clojure, JRuby, Jython) essa quantidade de informações será suficiente. Esperançosamente, agora você pode escrever um código melhor, criar aplicativos mais eficientes, evitando vários problemas com vazamentos de memória.