
Meu nome é Sasha, na SberDevices eu trabalho com reconhecimento de fala e como os dados podem torná-lo melhor. Neste artigo, falarei sobre o novo conjunto de dados de fala do Golos, que consiste em arquivos de áudio e transcrições correspondentes. A duração total das gravações é de aproximadamente 1240 horas, a taxa de amostragem é de 16 kHz. No momento, este é o maior corpus de gravações de áudio em russo, marcadas à mão. Lançamos o corpus sob uma licença próxima ao CC Attribution ShareAlike , que permite que seja usado tanto para pesquisa científica quanto para fins comerciais. Vou falar sobre em que consiste o conjunto de dados, como foi montado e quais resultados pode alcançar.
Estrutura do conjunto de dados Golos
Ao criar o conjunto de dados, fomos guiados pelo desejo de resolver o problema de inicialização a frio, quando os dados de usuários reais ainda não estavam disponíveis. Em última análise, foi isso que tornou possível colocá-lo à disposição do público, uma vez que não existe a fala dos usuários reais.
As gravações de áudio no conjunto de dados são coletadas de duas fontes. A primeira fonte é uma plataforma de crowdsourcing, por isso a chamamos de Crowd Domain. A segunda fonte são as gravações criadas no estúdio usando o dispositivo de destino SberPortal. Possui um sistema de microfone especial, e este é um dos dispositivos em que nosso reconhecimento de voz deve funcionar.
Chamamos essa fonte de domínio Farfield, uma vez que a distância do usuário até o dispositivo geralmente é muito grande. Para a gravação via SberPortal em estúdio, usamos três distâncias: 1, 3 e 5 metros do usuário até o dispositivo. Cada domínio possui uma parte de treinamento e teste, a estrutura resultante é mostrada na tabela:
| Domínios | Parte de treinamento | Parte de teste |
|---|---|---|
| Multidão | 979 796 arquivos | 1095 horas | 9994 arquivos | 11,2 horas |
| Campo distante | 124 003 arquivos | 132,4 horas | 1916 arquivos | 1,4 horas |
| Total | 1 103 799 arquivos | 1227,4 horas | 11910 arquivos | 12,6 horas |
Não há informações pessoais no conjunto de dados, como idade, sexo ou ID do usuário - tudo é impessoal. As partes de treinamento e teste podem conter a fala do mesmo usuário.
| Estatísticas \ Domínios | Multidão | Campo distante |
|---|---|---|
| número | 979796 arquivos | 124003 arquivos |
| Média | 4,0 seg. | 3,8 seg. |
| Desvio padrão | 1,9 seg. | 1,6 seg. |
| 1º percentil | 1,4 seg. | 2,0 seg. |
| 50º percentil | 3,7 seg. | 3,5 seg. |
| 95º percentil | 7,3 seg. | 6,8 seg. |
| 99º percentil | 10,5 seg. | 9,6 seg. |
A tabela acima fornece algumas informações estatísticas sobre as entradas: média, desvio padrão e percentis. Para maior clareza, a figura mostra dois histogramas da distribuição de comprimentos de registro:
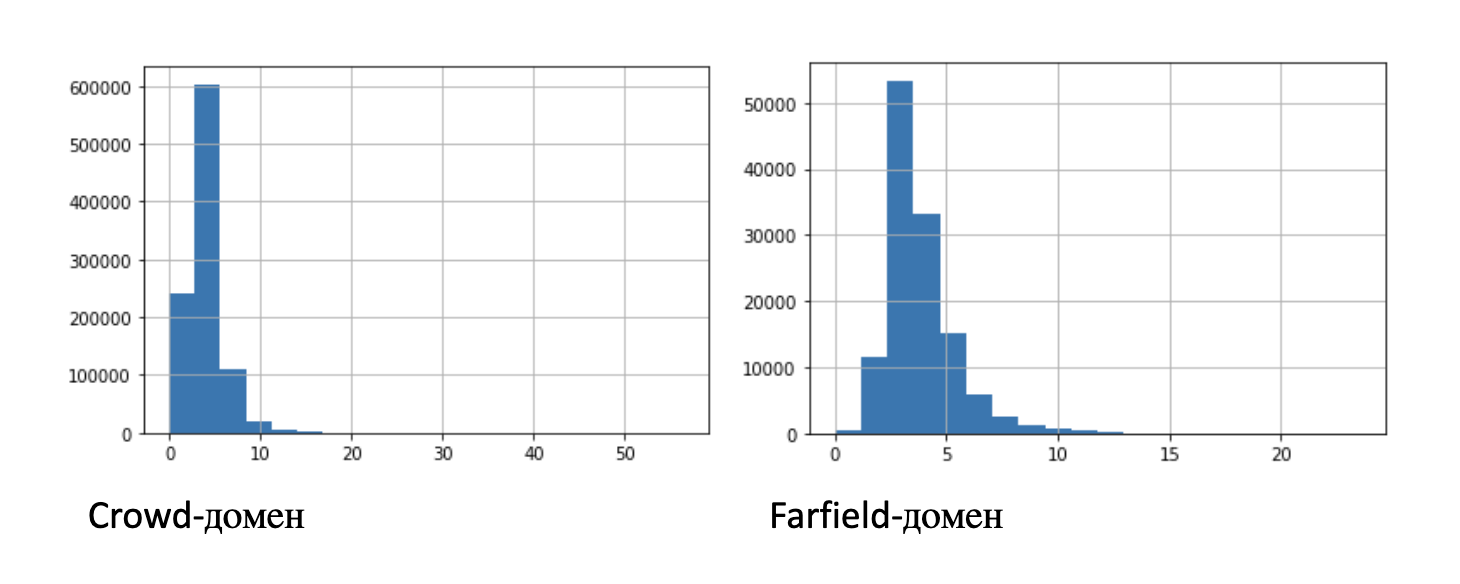
Para experimentos com um número limitado de registros, identificamos subconjuntos de duração mais curta: 100 horas, 10 horas, 1 hora, 10 minutos.
Coleção de dados
Na SberDevices, estamos desenvolvendo a família de assistentes virtuais Salute, portanto, geramos uma fala semelhante às solicitações de um assistente do usuário. Criamos um sistema de modelos para descrever solicitações em vários domínios - música, filmes, pedidos de produtos e outros. São expressões que descrevem a estrutura de uma solicitação e a decompõem em componentes. Usando modelos, podemos gerar consultas razoáveis, treinar novamente o modelo acústico, criar um modelo de linguagem com base nessas consultas e muito mais.
Modelos de amostra:
| Modelo | Exemplo |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Jogue o livro verde do filme |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | Você tem um livro verde do cinema |
| [command_demands_ip] + [film_title_ip] | Você tem um livro verde |
| [film_title_ip] + [command_demands_vp] | colocar livro verde |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | filme o livro verde colocado |
| [film_title_ip] | livro verde |
| [command_demands_vp] + [film_title_ip] | ligue o livro verde |
| [film_syn_ip] + [film_title_ip] | livro verde do filme |
| [command_demands_vp] + [film_title_ip] | Ligue o livro verde |
| ... | ... |
Entre colchetes - a designação da entidade correspondente. Além disso, na tabela para duas entidades “film_title_ip” e “film_title_vp” existem opções possíveis para preenchê-la:
| film_title_ip | film_title_vp |
|---|---|
| obsessão | obsessão |
| a fuga | a fuga |
| a bela e A Fera | A bela e a fera |
| ilha | ilha |
| Jane Eyre | Jane Eyre |
| Morro dos Ventos Uivantes | Morro dos Ventos Uivantes |
| ... | ... |
O processo de criação de um conjunto de dados de áudio com tags consiste em vários estágios:
- Etapa 1. Primeiro, criamos modelos para um determinado domínio.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
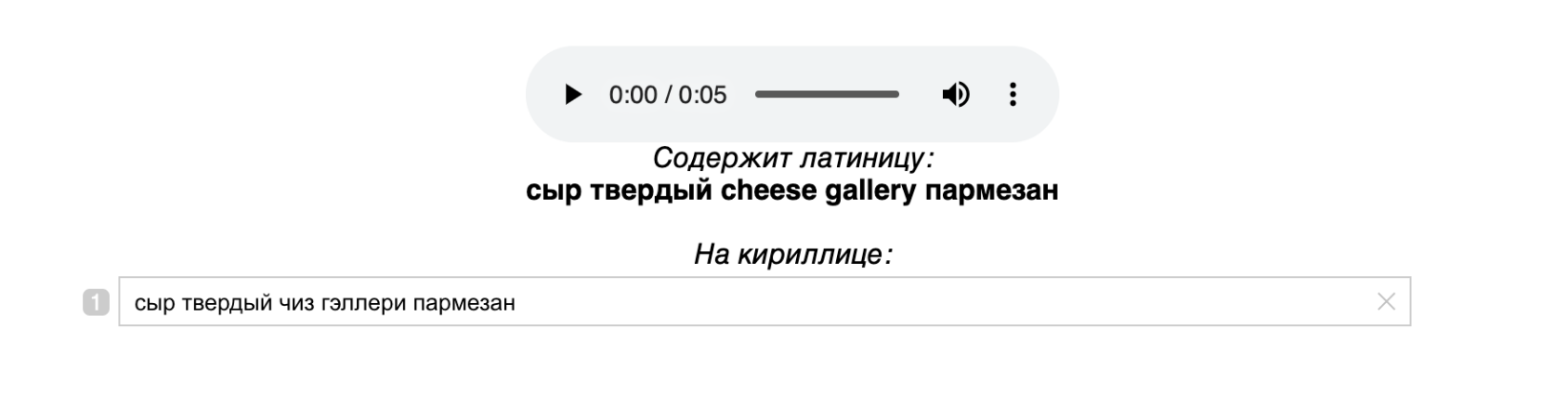
, . .
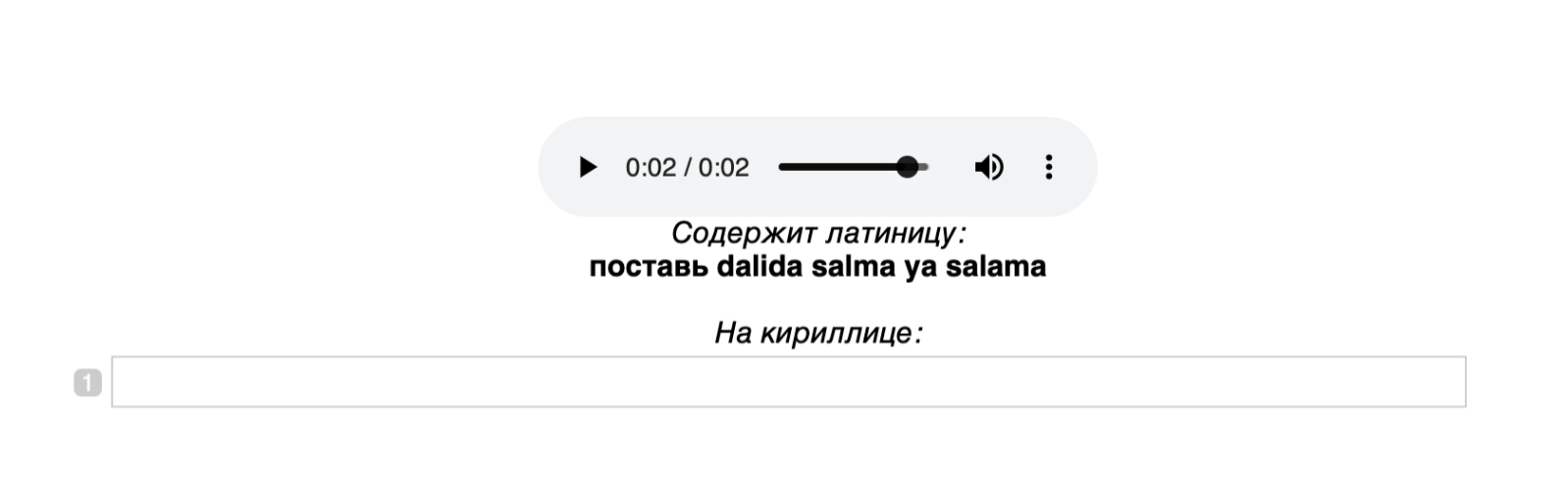
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
O processo descrito de criação de um conjunto de dados permite que você faça a marcação com a melhor qualidade possível, o que o distingue de outros criados automaticamente ou semiautomática. Usamos esses dados para criar um sistema de reconhecimento de voz em nossos dispositivos. Devido à alta qualidade das marcações, a precisão do sistema resultante é comparável à de um humano. Todos os dados, juntamente com modelos acústicos e de linguagem treinados para reconhecimento de fala, estão disponíveis na página do projeto no GitHub , bem como no ML Space da Sbercloud , um serviço para treinamento de modelos de aprendizado de máquina, onde nosso conjunto de dados pode ser baixado diretamente na interface . Falaremos mais sobre o uso do ML Space e como o usamos para ensinar modelos de reconhecimento de fala no próximo artigo.
Atualmente, há muitos dados abertos em inglês, mas não existia um conjunto de dados em russo de alta qualidade. Agora, um corpus também está disponível em russo, que pode ser usado para reconhecimento e síntese de fala, e o modelo treinado nele mostra uma qualidade muito alta. Acreditamos que o conjunto de dados Golos permitirá que a comunidade científica russa avance ainda mais rapidamente no aprimoramento das tecnologias de fala em russo.