
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
Então, suponha que você decida fundar uma start-up de IA para detectar câncer de mama (a propósito, o tipo mais comum de oncologia entre as mulheres) e vai criar um sistema que detectará com precisão sinais de patologia em exames de mamografia, assegure o médico contra erros e reduzir o tempo de diagnóstico ... Uma missão brilhante, não é?

Você montou uma equipe de programadores talentosos, engenheiros e analistas de ML, comprou equipamentos caros, alugou um escritório e elaborou uma estratégia de marketing. Tudo parece pronto para começar a mudar o mundo para melhor! Infelizmente, nem tudo é tão simples, porque você se esqueceu da coisa mais importante - sobre os dados. Sem eles, você não pode treinar uma rede neural ou outro modelo de aprendizado de máquina.
É aqui que reside um dos principais obstáculos - a quantidade e a qualidade dos conjuntos de dados disponíveis. Infelizmente, no campo da medicina diagnóstica, ainda existem muito poucos conjuntos de dados completos, verificados e de alta qualidade, e ainda menos deles estão publicamente disponíveis para pesquisadores e empresas de IA.
Considere a situação usando o mesmo exemplo de detecção do câncer de mama. Conjuntos de dados públicos mais ou menos de alta qualidade podem ser contados nos dedos de uma mão: DDSM (cerca de 2600 casos), InBreast (115), MIAS (161). Também existe o OPTIMAM e o BCDR com um procedimento bastante complicado e confuso para obter acesso.
E mesmo se você pudesse coletar uma quantidade suficiente de dados públicos, o próximo obstáculo espera por você: quase todos esses conjuntos de dados podem ser usados apenas para fins não comerciais. Além disso, a marcação neles pode ser completamente diferente - e não é um fato que seja adequada para sua tarefa. Em geral, sem coletar seus próprios conjuntos de dados e sua marcação, será possível fazer apenas um MVP, mas não um produto de alta qualidade, pronto para operar em condições de combate.
Então, você enviou solicitações a instituições médicas, levantou todas as suas conexões e contatos e recebeu uma coleção heterogênea de várias fotos em suas mãos. Não se alegre antes do tempo, você está bem no início do caminho! Na verdade, apesar da presença de um padrão unificado para o armazenamento de imagens médicas, o DICOM(Imagem Digital e Comunicações em Medicina), na vida real nem tudo é tão róseo. Por exemplo, as informações sobre o lado (Esquerda / Direita) e a projeção ( CC / MLO ) de uma imagem de mama podem ser armazenadas em diferentes fontes de dados em campos completamente diferentes. A única solução aqui é coletar dados de tantas fontes quanto possível e tentar levar em conta todas as opções possíveis na lógica do serviço.
O que você marca é o que você colhe
Finalmente chegamos à parte divertida - o processo de marcação de dados. O que o torna tão especial e inesquecível na área médica? Em primeiro lugar, o próprio processo de marcação é muito mais complicado e demorado do que na maioria das indústrias. Os raios X não podem ser enviados para Yandex.Toloka e você pode obter um conjunto de dados etiquetado por um centavo. Isso requer um trabalho árduo de médicos especialistas e é aconselhável dar cada imagem para marcação a vários médicos - e isso é caro e demorado.
Pior ainda: os especialistas frequentemente discordam e fornecem marcações completamente diferentes das mesmas imagens na saída. Os médicos têm diferentes qualificações, formação, nível de "suspeita". Alguém marca todos os objetos na imagem nitidamente ao longo do contorno, e alguém - com molduras largas. Finalmente, um deles está cheio de energia e entusiasmo, enquanto outro está marcando fotos em uma pequena tela de laptop após um turno de vinte horas. Todas essas discrepâncias naturalmente "enlouquecem" as redes neurais, e você não obterá um modelo de alta qualidade sob tais condições.
A situação também não melhora pelo fato de que a maioria dos erros e discrepâncias ocorrem precisamente nos casos mais complexos, os mais valiosos para o treinamento de neurônios. Por exemplo, pesquisamostram que a maioria dos erros que os médicos cometem ao fazer um diagnóstico em mamografias com aumento da densidade do tecido mamário, portanto, não é surpreendente que sejam os mais difíceis também para os sistemas de IA.
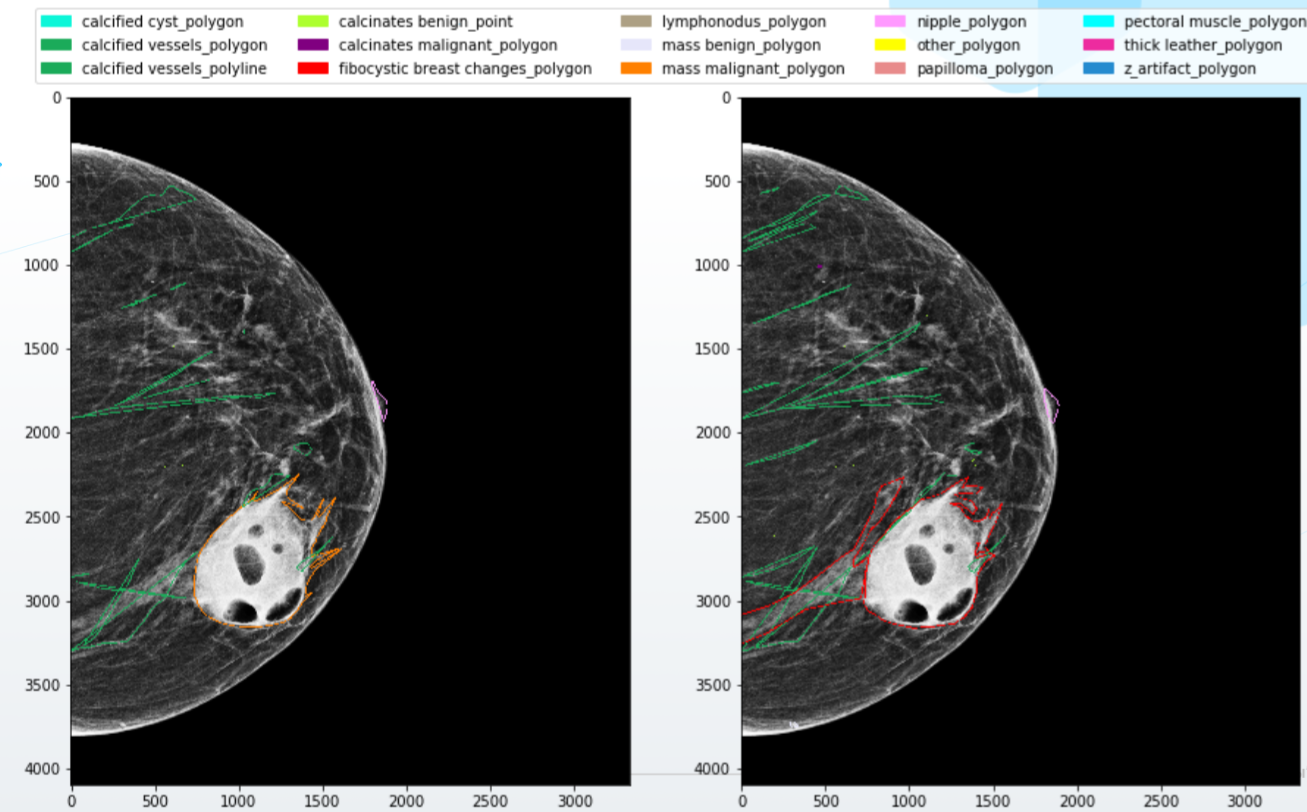
O que fazer? É claro que, em primeiro lugar, você precisa construir um sistema de interação de alta qualidade com os médicos. Escreva regras detalhadas para marcação, com exemplos e visualizações, forneça aos especialistas softwares e equipamentos de alta qualidade, anote a lógica para combinar conflitos menores na marcação e peça opinião adicional em caso de conflitos mais graves.
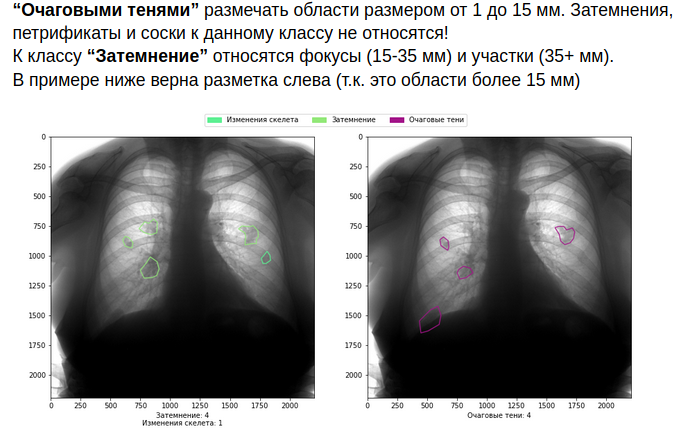
Como você pode imaginar, tudo isso aumenta o custo do markup. Mas se você não está pronto para tomá-los, é melhor não entrar no campo da medicina.
Obviamente, se você abordar o processo com sabedoria, os custos podem e devem ser reduzidos - por exemplo, por meio do aprendizado ativo. Nesse caso, o próprio sistema ML informa aos médicos quais imagens precisam ser marcadas adicionalmente para maximizar a qualidade do reconhecimento da patologia. Existem diferentes maneiras de avaliar a confiança de um modelo em suas previsões - Perda de Aprendizagem, Aprendizagem Ativa Discriminativa, Desistência de MC, entropia de probabilidades previstas, ramo de confiança e muitos outros. Qual é o melhor para usar, apenas os experimentos em seus modelos e conjuntos de dados serão mostrados.
Finalmente, você pode abandonar completamente a marcação de médicos e confiar apenas nos resultados finais confirmados - por exemplo, a morte ou recuperação do paciente. Talvez esta seja a melhor abordagem (embora haja muitas nuances aqui), mas ela só pode começar a funcionar em dez a quinze anos, na melhor das hipóteses, quando PACS (arquivamento de imagens e sistemas de comunicação) e sistemas de informação médica (MIS ) e quando dados suficientes tiverem sido acumulados. Mas mesmo neste caso, ninguém garante a pureza e a qualidade dos dados.
Bom modelo - bom pré-processamento

Viva! O modelo foi treinado, apresenta excelentes resultados e está pronto para ser pilotado. Foram celebrados acordos de cooperação com várias entidades médicas, o sistema foi instalado e configurado, foi realizada uma demonstração a médicos e apresentadas as capacidades do sistema.
E agora que acabou o primeiro dia de operação do sistema, você abre o painel com métricas com o coração apertado ... E você vê a seguinte imagem: um monte de solicitações ao sistema, com nenhum objeto detectado pelo sistema e, de claro, uma reação negativa dos médicos. Como assim? Afinal, o sistema se mostrou excelente em testes internos!
Após uma análise mais aprofundada, descobriu-se que nesta instituição médica existe algum tipo de máquina de raios-X que você não conhece, com suas próprias configurações e, como resultado, as imagens parecem completamente diferentes. A rede neural não foi treinada nessas imagens, então não é surpreendente que ela "falhe" nelas e não detecte nada. No mundo do aprendizado de máquina, esses casos são comumente chamados de dados fora de distribuição. Os modelos geralmente apresentam desempenho significativamente pior com esses dados, e esse é um dos principais problemas do aprendizado de máquina.
Exemplo ilustrativo: nossa equipe testou um modelo públicode pesquisadores da Universidade de Nova York, treinados em um milhão de imagens. Os autores do artigo argumentam que o modelo demonstrou alta qualidade de detecção de oncologia em mamografias e, especificamente, falam da taxa de precisão ROC-AUC na região de 0,88-0,89. Em nossos dados, o mesmo modelo demonstra resultados significativamente piores - de 0,65 a 0,70, dependendo do conjunto de dados.
A solução mais simples para este problema na superfície é coletar todos os tipos de imagens possíveis, de todos os dispositivos, com todas as configurações, marcá-los e treinar o sistema sobre eles. Desvantagens? Mais uma vez, longo e caro. Em alguns casos, você pode fazer sem marcação - o aprendizado não supervisionado virá em seu auxílio. Imagens não rotuladas são fornecidas ao neurônio de uma certa maneira, e o modelo "se acostuma" com suas características, o que permite detectar objetos em imagens semelhantes no futuro. Isso pode ser feito, por exemplo, usando pseudo-marcação de imagens não marcadas ou várias tarefas auxiliares.
No entanto, isso também não é uma panacéia. Além disso, este método exige que você colete todos os tipos de imagens existentes no mundo, o que, em princípio, parece uma tarefa impossível. E a melhor solução aqui seria usar o pré-processamento universal.
O pré-processamento é um algoritmo para processar dados de entrada antes de alimentá-los em uma rede neural. Este procedimento pode incluir mudanças automáticas de contraste e brilho, várias normalizações estatísticas e remoção de partes desnecessárias da imagem (artefatos).
Por exemplo, após muitos experimentos, nossa equipe conseguiu criar um pré-processamento universal para imagens de raios-X da glândula mamária, que traz quase todas as imagens de entrada a uma forma uniforme, o que permite que a rede neural as processe corretamente.

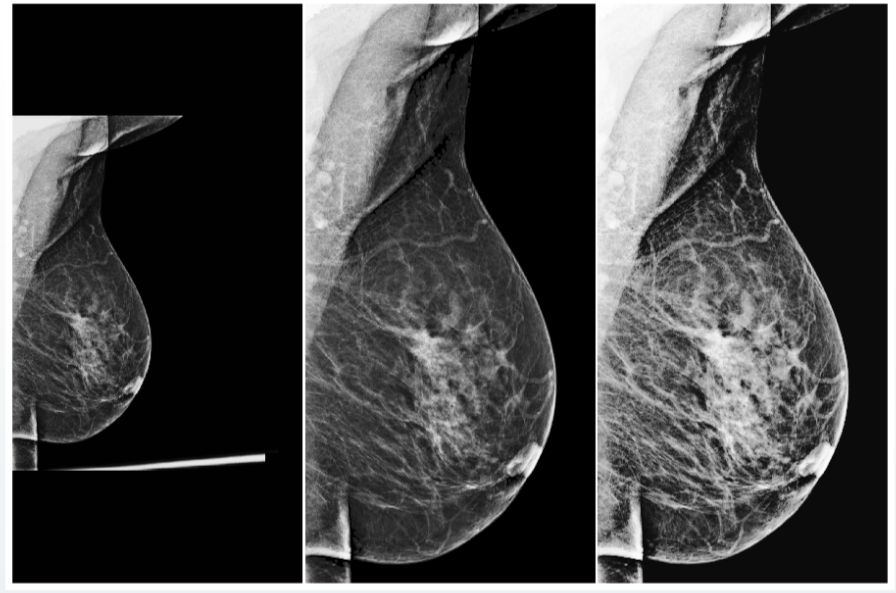
Mas mesmo com o pré-processamento universal, você não deve se esquecer das verificações de qualidade dos dados de entrada. Por exemplo, em conjuntos de dados fluorográficos, muitas vezes nos deparamos com imagens de teste, que incluíam bolsas, garrafas e outros objetos. Se o sistema atribui qualquer probabilidade de presença de patologia em tal imagem, isso claramente não aumenta a confiança da comunidade médica em seu modelo. Para evitar tais problemas, os sistemas de IA também devem sinalizar sua confiança nas previsões corretas e na validade dos dados de entrada.

Hardware diferente não é o único problema com a capacidade dos sistemas de IA de generalizar, generalizar e trabalhar com novos dados. Um parâmetro muito importante são as características demográficas do conjunto de dados. Por exemplo, se sua amostra de treinamento for dominada por russos com mais de 60 anos, ninguém pode garantir que o modelo funcionará corretamente em jovens asiáticos. É imperativo monitorar a similaridade dos indicadores estatísticos da amostra de treinamento e a população real para a qual o sistema será usado.
Se forem encontradas discrepâncias, é imperativo realizar testes e, muito provavelmente, treinamento adicional ou ajuste fino do modelo. É imperativo realizar monitoramento constante e revisão regular do sistema. No mundo real, um milhão de coisas podem acontecer: a máquina de raios X foi substituída, um novo assistente de laboratório veio que faz pesquisas de uma maneira diferente, multidões de migrantes de outro país inundaram a cidade de repente. Tudo isso pode levar à degradação da qualidade do seu sistema de IA.
No entanto, como você deve ter adivinhado, aprender não é tudo. O sistema precisa ser avaliado no mínimo, e as métricas padrão podem não ser aplicáveis na área médica. Isso também torna difícil avaliar os serviços concorrentes de IA. Mas esse é o tema da segunda parte do material - como sempre, com base em nossa experiência pessoal.