Muitos projetos agora usam arquitetura de microsserviço. Também não somos exceção e, há mais de 2 anos, tentamos construir RBS para pessoas jurídicas em um banco usando microsserviços.

Autores do artigo: ctimas e Alexey_Salaev
A importância da arquitetura de microsserviço
Nosso projeto é uma RBS para pessoas jurídicas. Muitos processos diferentes sob o capô e uma interface minimalista agradável. Mas não foi sempre assim. Durante muito tempo utilizamos uma solução de um empreiteiro, mas um belo dia decidiu-se desenvolver o nosso produto.
No início do projeto, houve muitas discussões: qual abordagem escolher? como construir nosso novo sistema RBS? Tudo começou com as discussões “monólito vs microsserviços”: discutiu as possíveis linguagens de programação usadas, discutiu sobre os frameworks (“devo usar o spring cloud?”, “Qual protocolo devo escolher para comunicação entre microsserviços?”). Essas perguntas, via de regra, têm um número limitado de respostas e simplesmente escolhemos abordagens e tecnologias específicas dependendo das necessidades e capacidades. E a resposta à pergunta "Como escrever microsserviços próprios?" não era totalmente simples.
Muitos podem dizer: “Por que desenvolver um conceito de arquitetura geral para o microsserviço em si? Existe uma arquitetura corporativa e uma arquitetura de projeto, e um vetor geral de desenvolvimento. Se você atribuir uma tarefa à equipe, ela a concluirá, o microsserviço será escrito e executará suas tarefas. Afinal, essa é a essência dos microsserviços - independência. " E eles estarão absolutamente certos! Mas com o tempo, as equipes se tornam maiores, portanto, o número de microsserviços e funcionários está crescendo e há menos veteranos. Novos desenvolvedores chegam e precisam imergir no projeto, alguns desenvolvedores mudam de equipe. Além disso, as equipes deixam de existir com o tempo, mas seus microsserviços continuam ativos e, em alguns casos, precisam ser melhorados.
Ao desenvolver o conceito geral da arquitetura de microsserviço, deixamos uma grande reserva para o futuro:
- ;
- ;
- : .
Todos que trabalham com microsserviços estão bem cientes de seus prós e contras, um dos quais é a capacidade de substituir rapidamente uma implementação antiga por uma nova. Mas quão pequeno deve ser um microsserviço para que possa ser facilmente substituído? Onde está o limite que determina o tamanho do microsserviço? Como não fazer um mini monólito ou nanserviço? E você sempre pode ir direto para o lado das funções que executam uma pequena parte da lógica e criar processos de negócios, construindo a ordem de chamada dessas funções ...
Decidimos destacar microsserviços por domínios de negócios (por exemplo, o microsserviço para pagamentos em rublos) e construir os próprios microsserviços de acordo com as tarefas deste domínio.
Vamos considerar um exemplo de processo de negócios padrão para qualquer banco - "criar uma ordem de pagamento"

Você pode ver que uma solicitação de cliente aparentemente simples é um conjunto bastante grande de operações. Este cenário é aproximado, algumas etapas são omitidas por simplicidade, algumas das etapas ocorrem no nível dos componentes da infraestrutura e não atingem a lógica de negócio principal no serviço do produto, a outra parte das operações funciona de forma assíncrona. O resultado final é que temos um processo que em um determinado momento pode usar muitos serviços vizinhos, usar a funcionalidade de diferentes bibliotecas, implementar algum tipo de lógica dentro de si mesmo e salvar dados em vários armazenamentos.
Olhando mais de perto, você pode ver que o processo de negócios é bastante linear e no curso de seu trabalho, ele precisará obter alguns dados em algum lugar ou de alguma forma processar os dados que possui, e isso pode exigir o trabalho com fontes de dados externas microsserviços, bancos de dados) ou lógica (bibliotecas).

Alguns microsserviços não se enquadram nesse conceito, mas o número desses microsserviços na porcentagem geral é pequeno e chega a cerca de 5%.
Arquitetura limpa
Depois de examinar diferentes abordagens para organizar o código, decidimos tentar uma abordagem de “arquitetura limpa”, organizando o código em nossos microsserviços como camadas.
No que se refere à própria "arquitetura limpa", mais de um livro foi escrito, há muitos artigos tanto na Internet quanto na Habré ( artigo 1 , artigo 2 ), mais de uma vez seus prós e contras foram discutidos.
Um diagrama popular que pode ser encontrado neste tópico foi desenhado por Bob Martin em seu livro Clean Architecture:

Aqui, o gráfico de pizza à esquerda no centro mostra a direção das dependências entre as camadas, e modestamente no canto direito você pode ver o direção do fluxo de execução.
Essa abordagem, como, de fato, em qualquer tecnologia de programação, tem seus prós e contras. Mas, para nós, há muito mais aspectos positivos do que negativos ao usar essa abordagem.
Implementação de “arquitetura limpa” no projeto
Redesenhamos este diagrama com base em nosso cenário.
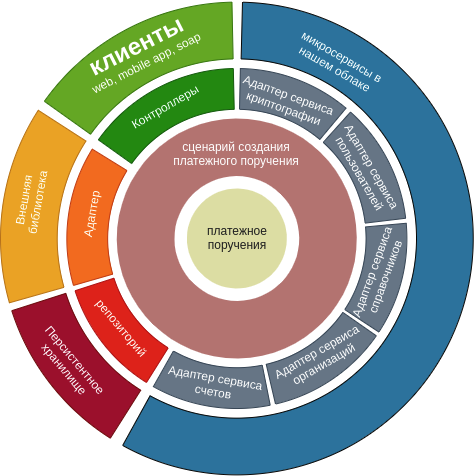
Naturalmente, este diagrama reflete um cenário. Muitas vezes acontece que um microsserviço executa mais operações em uma entidade de domínio, mas, para ser justo, muitos adaptadores podem ser reutilizados.
Diferentes abordagens podem ser usadas para separar o microsserviço em camadas, mas escolhemos a divisão em módulos no nível do criador do projeto. A implementação no nível do módulo fornece uma percepção visual mais fácil do projeto e também fornece outra camada de proteção para projetos contra o uso indevido do estilo arquitetônico.
Pela experiência, percebemos que quando está imerso em um projeto, um novo desenvolvedor só precisa se familiarizar com a parte teórica e pode navegar de forma fácil e rápida em quase qualquer microsserviço.
Usamos Gradle para construir nossos microsserviços em Java, portanto, as camadas principais são formadas como um conjunto de seus módulos:

Agora nosso projeto consiste em módulos que implementam contratos ou os utilizam. Para que esses módulos comecem a funcionar e a resolver problemas, precisamos implementar injeção de dependência e criar um ponto de entrada que iniciará nosso aplicativo inteiro. E aqui há uma questão interessante no livro Uncle Bob "Pure architecture" existem capítulos inteiros que nos falam sobre os detalhes, modelos e frameworks, mas não construímos sua arquitetura em torno do framework ou do banco de dados, nós os usamos como um dos componentes ...
Quando precisamos salvar a entidade, nos referimos ao banco de dados, por exemplo, para que nosso script receba as implementações de contrato de que precisa no momento da execução, usamos o framework que dá o nosso arquitetura DI.
Há tarefas em que precisamos implementar um microsserviço sem banco de dados, ou podemos abandonar o DI, porque a tarefa é muito simples e é mais rápido resolvê-la de frente. E se vamos realizar todo o trabalho com o banco de dados no módulo "repositório", então onde usamos o framework para preparar todo o DI para nós? Não há tantas opções: ou adicionamos uma dependência a cada módulo de nossa aplicação ou tentamos selecionar a DI inteira como um módulo separado.
Escolhemos uma nova abordagem de módulo separada e a chamamos de “infraestrutura” ou “aplicativo”.
Verdade, quando tal módulo é introduzido, o princípio é ligeiramente violado, segundo o qual direcionamos todas as dependências do centro para a camada de domínio, uma vez que ele deve ter acesso a todas as classes do aplicativo.
Não funcionará adicionar uma camada de infraestrutura à nossa cebola na forma de uma camada, simplesmente não há lugar para isso lá, mas aqui você pode olhar tudo de um ângulo diferente, e acontece que temos um círculo “ Infraestrutura ”e nossa cebola folhada está aí ... Para maior clareza, vamos tentar separar um pouco as camadas para torná-las mais visíveis:

Adicione um novo módulo e observe a árvore de dependências na camada de infraestrutura para ver as dependências finais entre os módulos:

Agora tudo o que resta é adicionar o Estrutura de DI em si. Usamos Spring em nosso projeto, mas isso não é obrigatório, você pode pegar qualquer framework que implemente DI (por exemplo, micronauta).
Como construir um microsserviço e onde estará a parte do código - já decidimos, e vale a pena olhar para o cenário de negócios novamente, porque há outro ponto interessante.
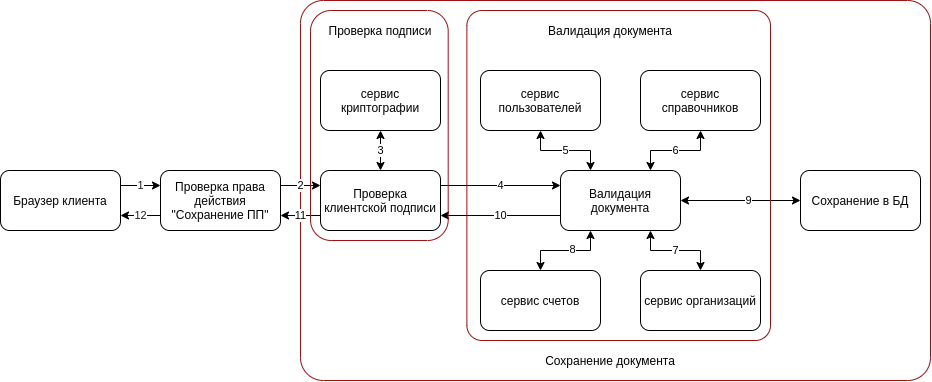
O diagrama mostra que a verificação do direito de ação não pode ser realizada no script principal. Esta é uma tarefa separada que não depende do que acontecerá a seguir. A verificação de assinatura pode ser movida para um microsserviço separado, mas aqui há muitas contradições ao definir o limite do microsserviço e decidimos apenas adicionar outra camada à nossa arquitetura.
Em camadas separadas, é necessário destacar as etapas que podem ser repetidas em nossa aplicação, por exemplo, verificação de assinatura. Este procedimento pode ocorrer durante a criação, alteração ou assinatura de um documento. Muitos scripts principais iniciam as operações menores primeiro e, em seguida, apenas o script principal. Portanto, é mais fácil para nós isolar operações menores em pequenos scripts, divididos em camadas para que possam ser reutilizados de forma mais conveniente.
Essa abordagem torna a lógica de negócios mais fácil de entender e, com o tempo, será formado um conjunto de blocos de construção de pequenas empresas que podem ser reutilizados.
Não há muito a dizer sobre o código de adaptadores, controladores e repositórios. eles são bastante simples. Os adaptadores para outro microsserviço usam um cliente gerado a partir de um swagger, um Spring RestTemplate ou um cliente Grpc. Em repositórios - uma das variações de uso do Hibernate ou outros ORMs. Os controladores obedecerão à biblioteca que você usará.
Conclusão
Neste artigo, queremos mostrar por que estamos construindo uma arquitetura de microsserviço, quais abordagens usamos e como desenvolvemos. O nosso projecto é jovem e está apenas no início do seu percurso, mas já agora podemos destacar os principais pontos do seu desenvolvimento do ponto de vista da arquitectura do próprio microsserviço.
Estamos construindo microsserviços multimódulos, onde as vantagens incluem:
- , - , , - , ;
- , , - ;
- , Api, , , , ;
- , , , , .
Não sem, é claro, uma mosca na sopa. Por exemplo, o mais óbvio é que muitas vezes cada módulo funciona com seus próprios modelos pequenos. Por exemplo, no controlador você terá uma descrição dos demais modelos, e no repositório haverá entidades de banco de dados. Nesse caso, você precisa mapear muitos objetos uns para os outros, mas ferramentas como “mapstruct” permitem que você faça isso de forma rápida e confiável.
Além disso, as desvantagens incluem o fato de que você precisa monitorar constantemente outros desenvolvedores, porque existe a tentação de fazer menos trabalho do que custa. Por exemplo, mover o framework um pouco além de um módulo, mas isso leva à erosão da responsabilidade deste framework em toda a arquitetura, o que no futuro pode afetar negativamente a velocidade das melhorias.
Essa abordagem para implementar microsserviços é adequada para projetos com uma longa vida útil e projetos com comportamento complexo. Já que a implantação de toda a infraestrutura leva tempo, mas no futuro compensa com estabilidade e melhorias rápidas.