Veja a postagem anterior aqui .
Regressão
Embora possa ser útil saber que as duas variáveis estão correlacionadas, não podemos usar essas informações sozinhas para prever o peso de nadadores olímpicos na presença de dados de altura, ou vice-versa. Ao estabelecer a correlação, medimos a força e o sinal da conexão, mas não a inclinação, ou seja, inclinação. Para gerar uma previsão, você precisa saber a taxa esperada de mudança em uma variável para uma determinada mudança de unidade em outra.
Gostaríamos de derivar uma equação que relaciona o valor específico de uma variável, a chamada variável independente, ao valor esperado de outra variável dependente. Por exemplo, se nossa equação linear prediz o peso para uma determinada altura, o crescimento é nossa variável independente e dependente do peso .
As linhas descritas por essas equações são chamadas de linhas de regressão . Este termo foi cunhado pelo polímata britânico do século 19, Sir Francis Galton. Ele e seu aluno Carl Pearson, que derivou o coeficiente de correlação, desenvolveram um grande número de métodos para estudar relações lineares no século 19, que ficaram conhecidos coletivamente como métodos de análise de regressão.
Lembre-se de que correlação não implica causalidade, e os termos “dependente” e “independente” não significam qualquer causação implícita. Eles são apenas nomes para valores matemáticos de entrada e saída. Um exemplo clássico é a correlação extremamente positiva entre o número de caminhões de bombeiros enviados para extinguir um incêndio e os danos causados pelo incêndio. Obviamente, enviar caminhões de bombeiros para extinguir um incêndio não causa danos por si só. Ninguém aconselharia a redução do número de veículos enviados para extinguir um incêndio como forma de reduzir os danos. Em tais situações, devemos procurar uma variável adicional que estaria causalmente relacionada a outras variáveis e explicar a correlação entre elas. Neste exemplo, pode ser do tamanho do incêndio... Essas causas subjacentes são chamadas de variáveis de confusão porque distorcem nossa capacidade de determinar a relação entre as variáveis dependentes.
Equações lineares
As duas variáveis, que podemos denotar como x e y , podem estar estrita ou vagamente relacionadas entre si. A relação simples entre a variável independente x e a variável dependente y é simples, que é expressa pela seguinte fórmula:

a b . a , b — , . , a = 32 b = 1.8. a b, :

10° x 10:

, , 10° 50°F, . Python pandas, , :
''' '''
celsius_to_fahrenheit = lambda x: 32 + (x * 1.8)
def ex_3_11():
''' '''
df = pd.DataFrame({'C':s, 'F':s.map(celsius_to_fahrenheit)})
df.plot('C', 'F', legend=False, grid=True)
plt.xlabel(' ')
plt.ylabel(' ')
plt.show()
:
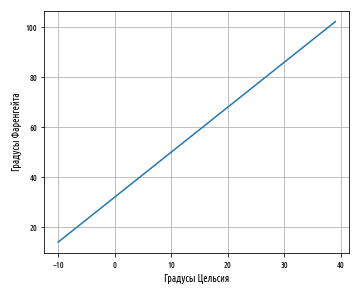
, 0 32 . a — y, x 0.
b; 2. , . , , .
, , . y x. , , , , :

, ε — , , a b x y. y — ŷ, — :

. - , , , . , , , ( ).
a b , x , . , , , x y.
, , , , , . , , .
, , , . , , , .
, , . , . Ordinary Least Squares (OLS), :

, , , . , , , :
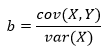
(a) — , X Y:

a b — , .
covariance
, variance
mean
, . :
def slope(xs, ys):
''' ( )'''
return xs.cov(ys) / xs.var()
def intercept(xs, ys):
''' ( Y)'''
return ys.mean() - (xs.mean() * slope(xs, ys))
def ex_3_12():
''' ( )
'''
df = swimmer_data()
X = df[', ']
y = df[''].apply(np.log)
a = intercept(X, y)
b = slope(X, y)
print(': %f, : %f' % (a,b))
: 1.691033, : 0.014296
0.0143 1.6910.
— ( ), () . np.exp
, np.log
. , 5.42 . , , .
, y x. , 1.014 . . , , , .
regression_line
x, ŷ a b.
''' '''
regression_line = lambda a, b: lambda x: a + (b * x) # fn(a,b)(x)
def ex_3_13():
'''
'''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=7)
s = pd.Series(range(150,210))
df = pd.DataFrame( {0:s, 1:s.map(regression_line(a, b))} )
df.plot(0, 1, legend=False, grid=True, ax=ax)
plt.xlabel(', .')
plt.ylabel(' ')
plt.show()
regression_line
x, a + bx.
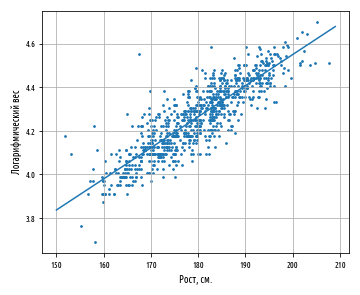
, , ŷ y.
def residuals(a, b, xs, ys):
''' '''
estimate = regression_line(a, b) #
return pd.Series( map(lambda x, y: y - estimate(x), xs, ys) )
constantly = lambda x: 0
def ex_3_14():
''' '''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
y = residuals(a, b, X, y)
ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=12)
s = pd.Series(range(150,210))
df = pd.DataFrame( {0:s, 1:s.map(constantly)} )
df.plot(0, 1, legend=False, grid=True, ax=ax)
plt.xlabel(', .')
plt.ylabel('')
plt.show()
— , Y X. , :
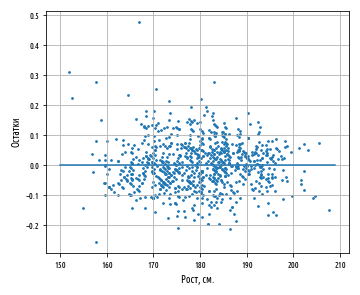
, , -, , . , . , , .
, , , . , . , , . , .
, . . , , , .. . , , , .
. , , , , .
R-
, , .. , . R2, R-, 0 1 . .
, R2 1, Y X. R2 :
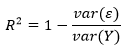
var(ε) — var(Y) — Y. , - . , . var(Y), .. .
, , a + bx. .
var(ε)/var(Y) — , . . , . R2 — , .
r, R2 , . , .
R2 . — , R2. R2 .
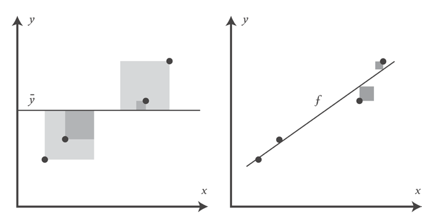
, , , , f. , y. R2 y:
def r_squared(a, b, xs, ys):
''' (R-)'''
r_var = residuals(a, b, xs, ys).var()
y_var = ys.var()
return 1 - (r_var / y_var)
def ex_3_15():
''' R-
'''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
return r_squared(a, b, X, y)
0.75268223613272323
0.753. , 75% , 2012 ., .
( ), R2 r :
r , Y X, R2 0.52, .. 0.25.
, . , . .
. , , β (), :

- , β1 = a β2 = b , x1 1, β1 — , , x1 () , .
β, , :

x1 xn , y. β1 βn , .
, : , , , . , , .
, x. pandas, , : .
Os exemplos de código fonte para este post está no meu Github repo . Todos os dados de origem são retirados do repositório do autor do livro.
O tópico do próximo post, post # 3 , será operações de matriz, equação normal e colinearidade.