
O trabalho de uma rede neural é baseado na manipulação de matrizes. Para o treinamento, uma variedade de métodos são usados, muitos dos quais surgiram do método de gradiente descendente, onde é necessário ser capaz de lidar com matrizes, para calcular gradientes (derivados em relação a matrizes). Se você olhar sob o capô de uma rede neural, poderá ver cadeias de matrizes, que geralmente parecem intimidantes. Simplificando, “a matriz está esperando por todos nós”. É hora de nos conhecermos melhor.
Para fazer isso, tomaremos as seguintes etapas:
Vamos considerar manipulações com matrizes: transposição, multiplicação, gradiente;
;
.
NumPy . , , , , . , , , - , , , . , - : , .
-
- , , , . , , , Google TensorFlow.
, , , , ,  ,
,  ;
;  - .
- .
import numpy as np # numpy
a=np.array([1,2,5])
a.ndim # , = 1
a.shape # (3,)
a.shape[0] # = 3
 . , , 0 2 .
. , , 0 2 .
b=np.array([3,4,7])
np.dot(a,b) # = 46
a*b # array([ 3, 8, 35])
np.sum(a*b) # = 46
( ) -  ,
,  . ,
. ,  - 0- 2- . , .
- 0- 2- . , .
A=np.array([[ 1, 2, 3],
[ 2, 4, 6]])
A # array([[1, 2, 3],
# [2, 4, 6]])
A[0, 2] # , = 3
A.shape # (2, 3) 2 , 3


 ,
,  . ,
. , 
 (
( 
 )
)
B=np.array([[7, 8, 1, 3],
[5, 4, 2, 7],
[3, 6, 9, 4]])
A.shape[1] == B.shape[0] # true
A.shape[1], B.shape[0] # (3, 3)
A.shape, B.shape # ((2, 3), (3, 4))
C = np.dot(A, B)
C # array([[26, 34, 32, 29],
# [52, 68, 64, 58]]);
# , C[0,1]=A[0,0]B[0,1]+ A[0,1]B[1,1]+A[0,2]B[2,1]=1*8+2*4+3*6=34
C.shape # (2, 4)
 , :
, :
np.dot(B, A) # ValueError: shapes (3,4) and (2,3) not aligned: 4 (dim 1) != 2 (dim 0)

 , .
, .
, . , 
 .
.  . , , ,
. , , ,  ,
,  - ( NumPy).
- ( NumPy).  . ,
. ,  .
.
a = np.reshape(a, (3,1)) # , a.shape = (3,) (3,1),
b = np.reshape(b, (3,1)) # ,
D = np.dot(a,b.T)
D # array([[ 3, 4, 7],
# [ 6, 8, 14],
# [15, 20, 35]])
, . , .
, , . (cost function). , . . , (learning rate), , (epoch). , . (), . . , , , .

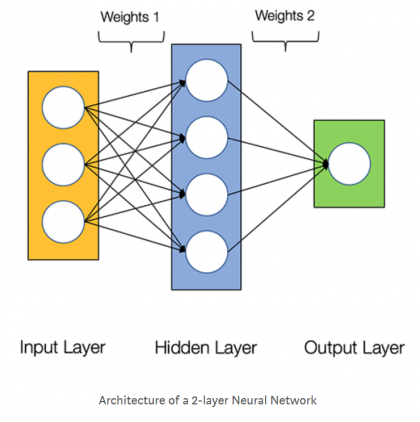
- (samples) . . , (), ( ) - (samples), - (features).
, ( ). (, …) , , . , .
!
, , . , “ ” . , , . , , . , , , .
, 10 . , (10, 3). “ ”, . , . , :
, , 0 50 ;
X=np.random.randint(0, 50, (10, 3))
0 1;
X=np.random.rand(10, 3)

 . , ,
. , ,  ;
;X=4*np.random.randn(10, 3) + 2

 , .
, .
, 

 , . , , . , , ,
, . , , . , , , 
 . ,
. ,  . ,
. , 
 , - - , . . ,
, - - , . . , 
 (
(  ,
,  )
)  ,
,  ,
,  ; , ,
; , ,  , . ,
, . ,  ,
,  . ,
. ,  . ,
. ,  10- (samples) . :
10- (samples) . :

, . (bias).
. : , , , .
X=np.random.randint(0, 50, (10, 3))
w1=2*np.random.rand(3,4)-1 # -1 +1
w2=2*np.random.rand(4,1)-1
Y=np.dot(np.dot(x,w1),w2) #
Y.shape # (10, 1)
Y.T.shape # (1, 10)
(np.dot(Y.T,Y)).shape # (1, 1), ,
. -1 +1, “” ( ).
.  “ ”, - .
“ ”, - .



 - ,
- ,  . ,
. ,  .
.
, . .
. - . , . , .
- , . 
 , “ ” - . , , . , , . : - , , - . (, 16 ), , . . ,
, “ ” - . , , . , , . : - , , - . (, 16 ), , . . , , , ,
, , ,  , . , .
, . , .


 - (learning rate). , . . - , , . , - .
- (learning rate). , . . - , , . , - .
.

 -
-  . ,
. ,  ,
,  . : .
. : .

, ,  , .
, .
. . , , .
,  ,
,

,  . , :
. , :


, , ,  .
. 
 , -
, -  .
. 
 -
-  . ,
. , 
 , .
, .
deltaW2=2*np.dot(np.dot(X,w1).T,Y)
deltaW2.shape # (4,1)
 .
.


, “ ”, “ ” - 
 . , , . : “” ( ), , .
. , , . : “” ( ), , .
 :
:  .
.
. ,, , , . . , . , . , , :  ,
, 

 .
.
,

:

 , . ,
, . ,

,

, - .  :
:  ,
,  . ,
. ,

“*” . , 
 , ,
, ,  , ; ,
, ; ,  .
.
. 
 . , , . NumPy .
. , , . NumPy .
def f1(x): #
return np.power(x,2)
def graf1(x): #
return 2*x
def f2(x): #
return np.power(x,3)
def gradf2(x): #
return 3*np.power(x,2)
A=np.dot(X,w1) #
B=f1(A) #
C=np.dot(B,w2) #
Y=f2() #
deltaW2=2*np.dot(B.T, Y*gradf2(C))
deltaW2.shape # (4,1)
 , . - .
, . - .

 . :
. :


,


,  ,
, 
 , “”,
, “”,  .
.
“” ,

![\ delta W ^ {(1)} = 2 (XT) \ cdot [[(\ widetilde {Y} * f_2 ^ {'} (C)) \ cdot (W ^ {(2)}. T)] * f_1 ^ {'} (A)].](https://habrastorage.org/getpro/habr/upload_files/cfb/a83/1aa/cfba831aa8bf857c4c5a7d0da07a17cc.svg)
,  ,
,  ,
,  .
.
.
deltaW1=2*np.dot(X.T, np.dot(Y*gradf2(C),w2.T)*gradf1(A))
deltaW1.shape # (3,4)
. .
“, - . -!” ? , , , . , . - , , . ! , , - . , , .
, . James Loy - , , , , , . . , , , . “-”, , , . , TensorFlow Keras. , a fonte original (há uma tradução para o russo).
Escreva códigos, mergulhe em fórmulas, leia livros, faça perguntas a si mesmo.
Quanto às ferramentas, são Jupyter Notebook ( regras do Anaconda !), Colab ...