
Um ótimo recurso foi adicionado recentemente à linha principal do compilador Clang . Usando os atributos
[[clang::musttail]]
ou ,
__attribute__((musttail))
agora você pode obter chamadas finais garantidas em C, C ++ e Objective-C.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Compilador online )
Normalmente, essas chamadas são associadas à programação funcional, mas só estou interessado nelas do ponto de vista do desempenho. Em alguns casos, com a ajuda deles, você pode obter um código melhor do compilador - pelo menos com as tecnologias de compilação disponíveis - sem recorrer a um montador.
O uso dessa abordagem na análise do protocolo de serialização deu resultados surpreendentes: fomos capazes de analisar em velocidades superiores a 2 Gb / s. , mais de duas vezes mais rápido que a melhor solução anterior. Este aumento de velocidade será útil em muitas situações, então seria incorreto limitar-se apenas à instrução "chamadas finais == aceleração dupla". No entanto, esses desafios são um elemento-chave que tornou possíveis esses ganhos de velocidade.
Eu direi quais são as vantagens das chamadas finais, como analisamos o protocolo usando-as e como podemos estender essa técnica aos intérpretes. Acho que graças a ele, os intérpretes de todas as principais linguagens escritas em C (Python, Ruby, PHP, Lua, etc.) podem obter ganhos de desempenho significativos. A principal desvantagem está relacionada à portabilidade: hoje
musttail
é uma extensão de compilador não padrão. Embora eu espere que pegue, levará algum tempo antes que a extensão se espalhe o suficiente para que o compilador C em seu sistema a suporte. Ao construir, você pode sacrificar a eficiência em troca da portabilidade se ela
musttail
não estiver disponível.
Tail Call Basics
Uma chamada final é uma chamada para qualquer função na posição final, a última ação antes de a função retornar um resultado. Ao otimizar as chamadas finais, o compilador compila a instrução para a chamada final
jmp
, não
call
. Isso não executa ações de sobrecarga que normalmente permitiriam ao receptor
g()
retornar ao chamador
f()
, como criar um novo quadro de pilha ou passar um endereço de retorno. Em vez disso, ele
f()
se refere diretamente a
g()
ele como se fosse parte de si mesmo e
g()
retorna o resultado diretamente ao chamador
f()
. Esta otimização é segura porque o stack frame
f()
não é mais necessário após o início da chamada final, pois tornou-se impossível acessar qualquer variável local
f()
.
Mesmo que pareça trivial, essa otimização tem dois recursos importantes que abrem novas possibilidades para escrever algoritmos. Primeiro, ao executar n chamadas finais consecutivas, a pilha de memória é reduzida de O (n) para O (1). Isso é importante porque a pilha é limitada e o estouro pode travar o programa. Portanto, sem essa otimização, alguns algoritmos são perigosos. Em segundo lugar,
jmp
elimina a sobrecarga de
call
e, como resultado, a chamada de função torna-se tão eficiente quanto qualquer outro branch. Ambos os recursos permitem que as chamadas finais sejam usadas como uma alternativa eficiente às estruturas de controle iterativo convencionais como
for
e
while
.
Essa ideia não é nada nova e remonta a 1977, quando Guy Steele escreveu um artigo inteiro no qual argumentou que as chamadas de procedimento são mais limpas do que as arquiteturas
GOTO
, enquanto a otimização das chamadas de cauda não perde velocidade. Foi um dos "Trabalhos Lambda" escritos entre 1975 e 1980, que formulou muitas das ideias por trás do Lisp e do Scheme.
A otimização da chamada final não é novidade, mesmo para o Clang. Ele poderia otimizá-los antes, como o GCC e muitos outros compiladores. Na verdade, o atributo
musttail
neste exemplo não altera a saída do compilador: o Clang já otimizou as chamadas finais para
-O2
.
Novo aqui é uma garantia . Embora os compiladores geralmente sejam bem-sucedidos na otimização das chamadas finais, essa é a "melhor coisa possível" e você não pode confiar nela. Em particular, a otimização certamente não funcionará em compilações não otimizadas: o compilador online . Neste exemplo, a chamada
call
final é compilada em , portanto, estamos de volta a uma pilha de tamanho O (n). É por isso que precisamos
musttail
: Até que tenhamos uma garantia do compilador de que nossas chamadas finais sempre serão otimizadas em todos os modos de montagem, não será seguro escrever algoritmos com tais chamadas para iteração. E manter o código que só funciona com otimizações habilitadas é uma restrição muito difícil.
O problema com loops de intérprete
Compiladores são uma tecnologia incrível, mas não são perfeitos. Mike Pall, o autor de LuaJIT, decidiu escrever o interpretador LuaJIT 2.x em linguagem assembly, não C, e ele chamou isso de o principal fator que tornou o interpretador tão rápido . Mais tarde, Paul explicou com mais detalhes por que os compiladores C têm dificuldade em encontrar os principais loops do interpretador . Dois pontos principais:
- , .
- , .
Essas observações refletem bem nossa experiência na otimização da análise do protocolo de serialização. E as chamadas de cauda nos ajudarão a resolver os dois problemas.
Você pode achar estranho comparar loops de interpretador com analisadores de protocolo de serialização. No entanto, sua similaridade inesperada é determinada pela natureza do formato de conexão do protocolo: é um conjunto de pares de valores-chave nos quais a chave contém o número do campo e seu tipo. A chave funciona como um opcode no interpretador: ela nos diz qual operação precisa ser realizada para analisar este campo. Os números de campo no protocolo podem ir em qualquer ordem, portanto, você precisa estar pronto para pular para qualquer parte do código a qualquer momento.
Seria lógico escrever tal analisador usando um loop
while
com uma expressão aninhada
switch
... Essa tem sido a melhor abordagem para analisar um protocolo de serialização durante o tempo de vida do protocolo. Por exemplo, aqui está o código de análise da versão C ++ atual . Se representarmos o fluxo de controle graficamente, obteremos o seguinte esquema:
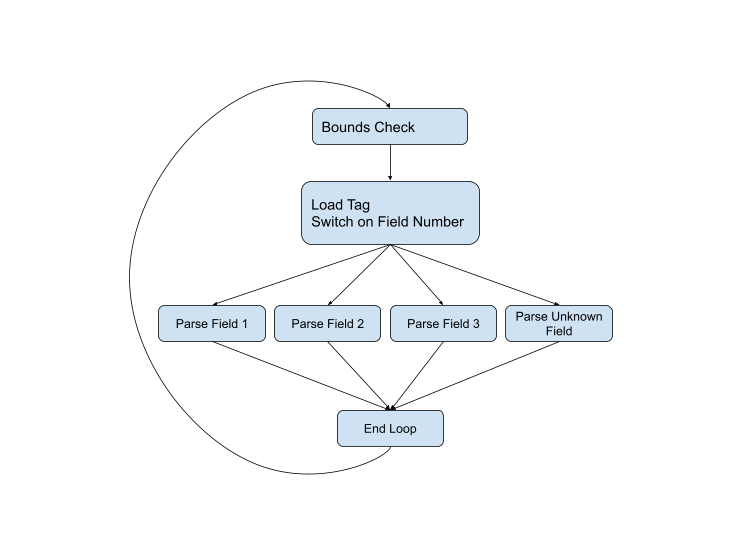
Mas o diagrama não está completo, porque podem surgir problemas em quase todas as fases. O tipo de campo pode estar errado ou os dados podem estar corrompidos, ou podemos simplesmente pular para o final do buffer atual. O diagrama completo é semelhante a este:
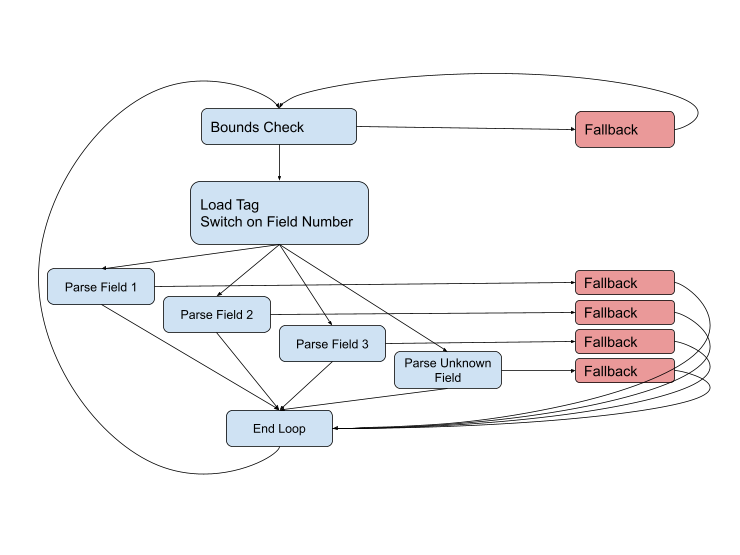
Precisamos permanecer nos atalhos (azul) o máximo possível, mas quando nos depararmos com uma situação difícil, teremos que lidar com isso usando o código de fallback. Esses caminhos são geralmente mais longos e complexos do que os caminhos rápidos, eles envolvem mais dados e costumam usar chamadas estranhas para outras funções para lidar com casos ainda mais complexos.
Em teoria, se você combinar esse esquema com o perfil, o compilador obterá todas as informações de que precisa para gerar o código mais adequado. Mas, na prática, com esse tamanho de função e o número de conexões, muitas vezes temos que lutar com o compilador. Ele lança fora uma variável importante que queremos armazenar no registrador. Ele aplica a manipulação do quadro de pilha que queremos envolver na chamada para a função de fallback. Ele concatena caminhos de código idênticos que queremos manter separados para previsão de ramificação. Tudo parece tentar tocar piano com luvas.
Melhorar os loops do intérprete com chamadas finais
O raciocínio descrito acima é em grande parte uma reformulação das observações de Paulo sobre os principais ciclos do intérprete . Mas, em vez de nos lançarmos ao montador, descobrimos que a arquitetura sob medida pode nos dar o controle de que precisamos para obter um código quase ótimo de C. Trabalhei nisso com meu colega Gerben Stavenga, que criou a maior parte da arquitetura. Nossa abordagem é semelhante ao interpretador wasm3 WebAssembly , que chama esse padrão de "metamáquina" .
Nós colocar o código para o nosso 2 gigabit analisador em UPB, uma pequena biblioteca protobuf em C. Está totalmente funcionando e passa em todos os testes de conformidade com o protocolo de serialização, mas ainda não foi implantada em nenhum lugar e a arquitetura não foi implementada na versão C ++ do protocolo. Mas quando a extensão veio para o Clang
musttail
(e o upb foi atualizado para usá-lo ), uma das principais barreiras para a implementação completa de nosso analisador rápido caiu.
Mudamos de uma grande função de análise e aplicamos sua própria função pequena para cada operação. Cada função final chama a próxima operação na sequência. Por exemplo, aqui está uma função para analisar um único campo de tamanho fixo (o código é simplificado em comparação com upb, removi muitos pequenos detalhes da arquitetura).
O código
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Para uma função tão pequena e simples, o Clang gera um código quase impossível de superar:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Observe que não há prólogo ou epílogo, nenhuma preempção de registro, nenhum uso de pilha. As únicas saídas são
jmp
de duas chamadas finais, mas nenhum código é necessário para passar parâmetros, porque os argumentos já estão nos registradores corretos. Talvez a única melhoria possível que vemos aqui seja um salto condicional para uma chamada final, em
jne fallback
vez de
jne
uma chamada subsequente
jmp
.
Se você visse uma desmontagem desse código sem informações simbólicas, não perceberia que essa era a função inteira. Também poderia ser a unidade básica de uma função maior. E é exatamente isso que fazemos: pegamos o loop do interpretador, que é uma função grande e complexa, e o programamos bloco a bloco, passando o fluxo de controle entre eles por meio de chamadas finais. Temos controle total sobre a distribuição de registros no limite de cada bloco (pelo menos seis registros), e como a função é simples o suficiente e não antecipa registros, alcançamos nosso objetivo de armazenar o estado mais importante ao longo de todos os caminhos.
Podemos otimizar de forma independente cada sequência de instruções. E o compilador também lidará com todas as sequências de forma independente, porque elas estão localizadas em funções separadas (se necessário, você pode evitar inlining com
noinline
). É assim que resolvemos o problema descrito acima, em que o código dos caminhos alternativos degrada a qualidade do código dos atalhos. Colocando os caminhos lentos em funções completamente separadas, a estabilidade da velocidade dos caminhos rápidos pode ser garantida. O belo montador permanece o mesmo, não é afetado por nenhuma mudança em outras partes do analisador.
Se aplicarmos este padrão ao exemplo de Paul de LuaJIT , então podemos aproximadamente correlacionar seu assembler manuscrito com pequenas degradações na qualidade do código :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
O montador resultante:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
A única melhoria que vejo aqui, além do acima, é
jne fallback
que por algum motivo o compilador não deseja gerar
jmp qword ptr [rsi + 8*rax]
, em vez disso, ele carrega
rax
e, em seguida, executa
jmp rax
. Esses são pequenos problemas de codificação que espero que o Clang resolva em breve, sem muita dificuldade.
Limitações
Uma das principais desvantagens dessa abordagem é que todas essas belas sequências de linguagem assembly são catastroficamente pessimizadas na ausência de chamadas finais. Qualquer chamada não customizada criará um frame de pilha e colocará muitos dados na pilha.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
De repente, nós entendemos isso
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Para evitar isso, tentamos chamar outras funções apenas por meio de chamadas inlining ou tail. Isso pode ser entediante se a operação tiver muitos lugares nos quais uma situação incomum que não é um erro possa ocorrer. Por exemplo, quando analisamos o protocolo de serialização, as variáveis inteiras geralmente têm um byte de comprimento, mas as mais longas não são um erro. O processamento embutido de tais situações pode degradar a qualidade do caminho rápido se o código de fallback for muito complexo. Mas a chamada final da função de fallback não facilita o retorno à operação ao lidar com uma anormalidade, portanto, a função de fallback deve ser capaz de concluir a operação. Isso leva à duplicação e à complicação do código.
Idealmente, este problema pode ser resolvido adicionando __attribute __ ((preserve_most))em uma função de fallback seguida por uma chamada normal, não uma chamada final. O atributo
preserve_most
torna o receptor responsável por preservar quase todos os registros. Isso permite delegar a tarefa de registros antecipados para funções de fallback, se necessário. Experimentamos esse atributo, mas encontramos problemas misteriosos que não conseguimos resolver. Talvez tenhamos cometido um erro em algum lugar, vamos voltar a isso no futuro.
A principal limitação é que
musttail
não é portátil. Eu realmente espero que o atributo crie raízes, seja implementado no GCC, Visual C ++ e outros compiladores, e um dia até seja padronizado. Mas isso não vai acontecer em breve, mas o que devemos fazer agora?
Quando a expansão
musttail
não está disponível, você precisa executar pelo menos um correto
return
sem uma chamada final para cada iteração teórica do loop . Ainda não implementamos esse fallback na biblioteca upb, mas acho que vai se transformar em uma macro que, dependendo da disponibilidade,
musttail
fará chamadas finais ou simplesmente retornará.