 Olá, Habitantes! Como extrair tudo de seus dados? Como tomar decisões baseadas em dados? Como organizar a ciência de dados dentro da empresa? Quem contratar um analista? Como levar os projetos de aprendizado de máquina e inteligência artificial ao nível superior? Roman Zykov sabe a resposta para essas e muitas outras perguntas, porque analisa dados há quase vinte anos. O histórico de Roman inclui a criação de sua própria empresa do zero com escritórios na Europa e América do Sul, que se tornou líder no uso de inteligência artificial (IA) no mercado russo. Além disso, o autor do livro criou análises em Ozon.ru a partir do zero. Este livro é direcionado ao leitor pensante que deseja experimentar a análise de dados e criar serviços baseados neles. Será útil para você se você for um gerente,quem deseja definir metas e gerenciar análises. Se você for um investidor, será mais fácil entender o potencial de uma startup. Quem "viu" sua startup encontrará aqui recomendações sobre como escolher a tecnologia certa e recrutar uma equipe. E o livro ajudará os especialistas em formação a ampliar seus horizontes e a começar a aplicar práticas nas quais não haviam pensado antes, e isso os diferencia dos profissionais em um campo tão difícil e volátil.
Olá, Habitantes! Como extrair tudo de seus dados? Como tomar decisões baseadas em dados? Como organizar a ciência de dados dentro da empresa? Quem contratar um analista? Como levar os projetos de aprendizado de máquina e inteligência artificial ao nível superior? Roman Zykov sabe a resposta para essas e muitas outras perguntas, porque analisa dados há quase vinte anos. O histórico de Roman inclui a criação de sua própria empresa do zero com escritórios na Europa e América do Sul, que se tornou líder no uso de inteligência artificial (IA) no mercado russo. Além disso, o autor do livro criou análises em Ozon.ru a partir do zero. Este livro é direcionado ao leitor pensante que deseja experimentar a análise de dados e criar serviços baseados neles. Será útil para você se você for um gerente,quem deseja definir metas e gerenciar análises. Se você for um investidor, será mais fácil entender o potencial de uma startup. Quem "viu" sua startup encontrará aqui recomendações sobre como escolher a tecnologia certa e recrutar uma equipe. E o livro ajudará os especialistas em formação a ampliar seus horizontes e a começar a aplicar práticas nas quais não haviam pensado antes, e isso os diferencia dos profissionais em um campo tão difícil e volátil.
Eu preciso ser capaz de programar?
Sim, preciso. No século 21, é desejável que todas as pessoas entendam como usar a programação em seu trabalho. Anteriormente, a programação estava disponível apenas para um círculo restrito de engenheiros. Com o tempo, a programação aplicada tornou-se mais acessível, democrática e conveniente.
Aprendi a programar sozinha quando criança. Meu pai comprou um computador "Partner 01.01" no final dos anos 1980, quando eu tinha cerca de onze anos, e comecei a me dedicar à programação. Primeiro, dominei a linguagem BASIC, depois cheguei ao montador. Estudei tudo, desde livros - então não havia ninguém para perguntar. O trabalho de base que foi feito na infância foi muito útil para mim na vida. Naquela época, meu instrumento principal era um cursor branco piscando em uma tela preta, os programas tinham que ser gravados em um gravador - tudo isso não pode ser comparado com as possibilidades que temos agora. O básico da programação não é tão difícil de aprender. Quando minha filha tinha cinco anos e meio, eu a coloquei em um curso de programação Scratch simples. Com minhas pequenas dicas, ela fez este curso e até conseguiu sua certificação de nível básico do MIT.
A programação de aplicativos é o que permite automatizar parte das funções de um funcionário. Os primeiros candidatos para automação são ações repetitivas.
Existem duas formas de análise. A primeira é usar ferramentas prontas (Excel, Tableau, SAS, SPSS, etc.), onde todas as ações são realizadas com o mouse, e o máximo de programação é escrever uma fórmula. A segunda é escrever em Python, R ou SQL. Essas são duas abordagens fundamentalmente diferentes, mas uma boa pessoa deve ser proficiente em ambas. Ao trabalhar com qualquer tarefa, você precisa encontrar um equilíbrio entre velocidade e qualidade. Isso é especialmente verdadeiro para a busca de insights. Conheci adeptos fervorosos da programação e obstinados que só podiam usar um mouse e, no máximo, um programa. Um bom especialista selecionará sua própria ferramenta para cada tarefa. Em um caso, ele vai escrever um programa, em outro ele vai fazer tudo no Excel. E, na terceira, combinará as duas abordagens: fará upload de dados para SQL, processará o conjunto de dados em Python e analisará em uma tabela dinâmica do Excel ou Google Docs.A velocidade de trabalho de um especialista tão avançado pode ser uma ordem de magnitude maior do que a de um especialista em linha. O conhecimento dá liberdade.
Ainda estudante, era fluente em várias linguagens de programação e até consegui trabalhar por um ano e meio como desenvolvedor de software. Os tempos eram difíceis - entrei no Instituto de Física e Tecnologia de Moscou em junho de 1998 e em agosto houve uma inadimplência. Era impossível viver de bolsa, não queria tirar dinheiro dos meus pais. No meu segundo ano, tive sorte, fui contratado como desenvolvedor em uma das empresas do MIPT - lá aprofundei meus conhecimentos sobre montador e C. Depois de algum tempo, consegui um emprego no suporte técnico da StatSoft Rússia - aqui melhorei minha análise estatística. Na Ozon.ru ele completou o treinamento e recebeu um certificado SAS, e também escreveu muito em SQL. A experiência de programação me ajudou muito - eu não tinha medo de algo novo, apenas peguei e fiz. Se eu não tivesse essa experiência de programação, não haveria muitas coisas interessantes na minha vida, incluindo a empresa Retail Rocket,que fundamos com meus parceiros.
Conjunto de Dados
Um conjunto de dados é um conjunto de dados, geralmente na forma de uma tabela, que foi descarregado do armazenamento (por exemplo, via SQL) ou obtido de outra forma. Uma tabela é composta de colunas e linhas, comumente chamadas de registros. No aprendizado de máquina, as próprias colunas são variáveis independentes, ou preditores, ou mais comumente recursos e variáveis dependentes, resultado. Você encontrará essa divisão na literatura. A tarefa do aprendizado de máquina é treinar um modelo que, usando as variáveis independentes (recursos), será capaz de prever corretamente o valor da variável dependente (via de regra, há apenas uma no conjunto de dados).
Os dois principais tipos de variáveis são categóricas e quantitativas. Uma variável categórica contém o texto ou codificação numérica de "categorias". Por sua vez, pode ser:
- Binário - pode assumir apenas dois valores (exemplos: sim / não, 0/1).
- Nominal - pode assumir mais de dois valores (exemplo: sim / não / não sei).
- Ordinal - quando a ordem é importante (por exemplo, a classificação do atleta, o número da linha nos resultados da pesquisa).
Uma variável quantitativa pode ser:
- Discreto (discreto) - o valor é calculado pela conta, por exemplo, a quantidade de pessoas na sala.
- Contínuo - qualquer valor do intervalo, por exemplo, peso da caixa, preço do produto.
Vejamos um exemplo. Existe uma tabela com preços de apartamentos (variável dependente), uma linha (registro) para um apartamento, cada apartamento possui um conjunto de atributos (independentes) com as seguintes colunas:
- O preço do apartamento é contínuo e dependente.
- A área do apartamento é contínua.
- O número de quartos é discreto (1, 2, 3, ...).
- O banheiro é combinado (sim / não) - binário.
- Número do andar - ordinal ou nominal (dependendo da tarefa).
- A distância ao centro é contínua.
Estatísticas descritivas
A primeira etapa após descarregar os dados do warehouse é fazer uma análise exploratória de dados, que inclui estatísticas descritivas e visualização de dados, possivelmente limpando os dados removendo outliers.
As estatísticas descritivas geralmente incluem estatísticas diferentes para cada uma das variáveis no conjunto de dados de entrada:
- O número de valores não ausentes.
- O número de valores exclusivos.
- Mínimo máximo.
- Mau.
- Mediana.
- Desvio padrão.
- Percentis - 25%, 50% (mediana), 75%, 95%.
Nem todos os tipos de variáveis podem ser calculados - por exemplo, a média só pode ser calculada para variáveis quantitativas. Os pacotes estatísticos e as bibliotecas de análise estatística já têm funções prontas para usar que contam as estatísticas descritivas. Por exemplo, a biblioteca Pandas Python tem uma função de descrição que exibirá imediatamente várias estatísticas para uma ou todas as variáveis no conjunto de dados:
s = pd.Series([4-1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
Embora este livro não pretenda ser um livro-texto sobre estatística, darei algumas dicas úteis. Freqüentemente, em teoria, presume-se que estamos trabalhando com dados normalmente distribuídos, cujo histograma se parece com um sino (Figura 4.1).
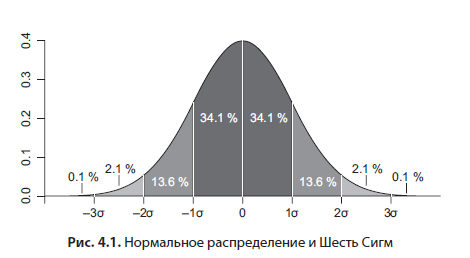
Eu recomendo fortemente verificar esta suposição pelo menos a olho nu. A mediana é o valor que divide a amostra pela metade. Por exemplo, se os percentis 25 e 75 estão em distâncias diferentes da mediana, isso já indica uma distribuição deslocada. Outro fator é a forte diferença entre média e mediana; em uma distribuição normal, eles praticamente coincidem. Freqüentemente, você lidará com uma distribuição exponencial ao analisar o comportamento do cliente - por exemplo, em Ozon.ru, o tempo entre pedidos sucessivos do cliente terá uma distribuição exponencial. A média e a mediana para isso diferem significativamente. Portanto, o número correto é a mediana, o valor que divide a amostra pela metade. No exemplo com Ozon.ru, este é o tempo durante o qual 50% dos usuários fazem o próximo pedido após o primeiro. A mediana também é mais robusta para outliers nos dados.Se você quiser trabalhar com médias, por exemplo, devido às limitações do pacote estatístico, e tecnicamente a média é calculada mais rápido que a mediana, então no caso de uma distribuição exponencial, você pode processá-la com o logaritmo natural. Para retornar à escala de dados original, você precisa processar a média resultante com o expoente usual.
O percentil é um valor que uma determinada variável aleatória não excede com uma probabilidade fixa. Por exemplo, a frase "o 25º percentil do preço das mercadorias é igual a 150 rublos" significa que 25% das mercadorias têm um preço menor ou igual a 150 rublos, os restantes 75% das mercadorias são mais caros do que 150 rublos.
Para uma distribuição normal, se a média e o desvio padrão são conhecidos, existem padrões teoricamente derivados úteis - 95% de todos os valores caem no intervalo a uma distância de dois desvios padrão da média em ambas as direções, ou seja, o a largura do intervalo é de quatro sigma. Você pode ter ouvido um termo como Six Sigma (Figura 4.1) - esta figura caracteriza a produção sem sucata. Assim, essa lei empírica decorre da distribuição normal: no intervalo de seis desvios-padrão em torno da média (três em cada direção), ajustam-se 99,99966% dos valores - qualidade ideal. Os percentis são muito úteis para localizar e remover outliers de dados. Por exemplo, ao analisar dados experimentais, você pode supor que todos os dados fora do 99º percentil são outliers e excluí-los.
Gráficos
Um bom gráfico vale mais que mil palavras. Os principais tipos de gráficos que utilizo:
- histogramas;
- gráfico de dispersão;
- gráfico de série temporal com uma linha de tendência;
- plotagem de caixa, plotagem de caixa e bigodes.
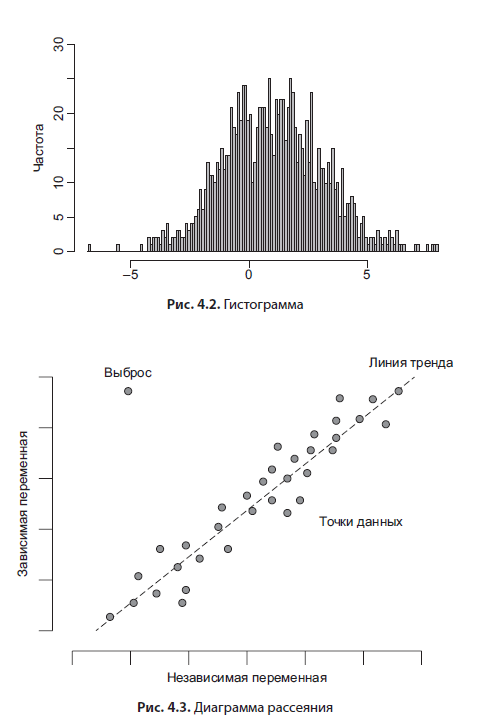
O histograma (Figura 4.2) é a ferramenta de análise mais útil. Ele permite que você visualize a distribuição de frequência da ocorrência de um valor (para uma variável categórica) ou divida uma variável contínua em intervalos (bins). O segundo é usado com mais frequência e, se você fornecer estatísticas descritivas adicionais a esse gráfico, terá uma imagem completa que descreve a variável na qual está interessado. O histograma é uma ferramenta simples e intuitiva.
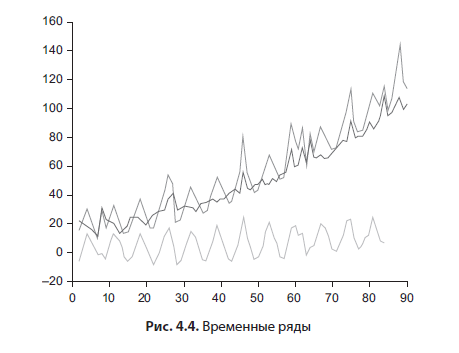
Um gráfico de dispersão (Figura 4.3) permite que você veja como duas variáveis dependem uma da outra. Ele é construído de forma simples: no eixo horizontal - a escala da variável independente, no eixo vertical - a escala da dependente. Os valores (registros) são marcados como pontos. Uma linha de tendência também pode ser adicionada. Em pacotes de estatísticas avançadas, você pode sinalizar outliers interativamente.
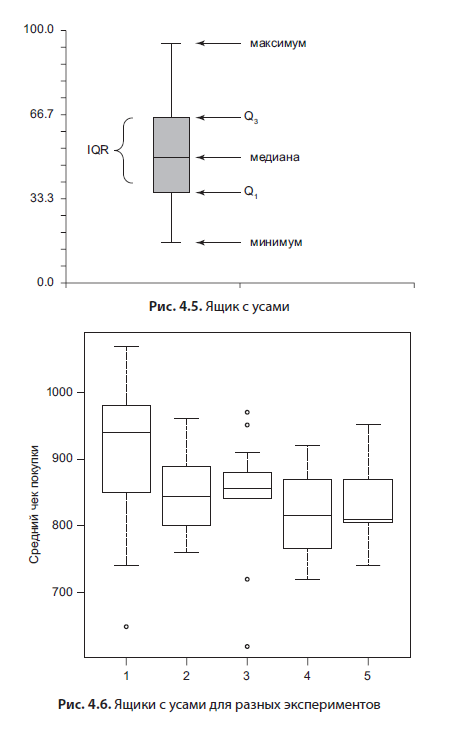
Os gráficos de séries temporais (Figura 4.4) são muito semelhantes aos gráficos de dispersão, nos quais a variável independente (no eixo horizontal) é o tempo. Normalmente, dois componentes podem ser distinguidos de uma série temporal - cíclica e tendência. Uma tendência pode ser construída sabendo a duração do ciclo, por exemplo, um de sete dias é um ciclo de vendas padrão em supermercados, você pode ver uma imagem repetida no gráfico a cada 7 dias. Em seguida, uma média móvel com um comprimento de janela igual ao ciclo é sobreposta no gráfico - e você obtém uma linha de tendência. Quase todos os pacotes estatísticos, Excel, Google Sheets podem fazer isso. Se você precisar obter o componente cíclico, subtraia a linha de tendência da série temporal. Com base nesses cálculos simples, os algoritmos mais simples para a previsão de séries temporais são construídos.
O gráfico de caixa (Fig. 4.5) é muito interessante; em certa medida, duplica os histogramas, pois também mostra uma estimativa da distribuição.
É composto por vários elementos: um bigode, que denotam o mínimo e o máximo, uma caixa, cuja borda superior é o 75º percentil, a borda inferior é o 25º percentil. No box, a linha é a mediana, o valor “no meio”, que divide a amostra pela metade. Este tipo de gráfico é útil para comparar resultados experimentais ou variáveis entre si. Um exemplo de tal gráfico está abaixo (Fig. 4.6). Acho que essa é a melhor maneira de visualizar os resultados dos testes de hipóteses.
Abordagem geral para visualização de dados
A visualização de dados é necessária para duas coisas: para explorar os dados e explicar as descobertas ao cliente. Freqüentemente, vários métodos são usados para apresentar os resultados: um simples comentário com alguns números, Excel ou outro formato de planilha, uma apresentação com slides. Todos os três métodos combinam conclusão e prova - ou seja, uma explicação de como essa conclusão foi alcançada. É conveniente expressar a prova em gráficos. Em 90% dos casos, os gráficos dos tipos descritos acima são suficientes para isso.
Os gráficos exploratórios e os gráficos de apresentação são diferentes uns dos outros. O objetivo da pesquisa é encontrar um padrão ou causa, via de regra, existem muitos deles, e acontece que são construídos ao acaso. O objetivo dos gráficos de apresentação é orientar o tomador de decisão (tomador de decisão) às conclusões do problema. Tudo é importante aqui - tanto o título do slide quanto sua sequência simples que leva à conclusão desejada. Um critério importante para o esquema de prova de inferência é a rapidez com que o cliente entenderá e concordará com você. Não precisa ser uma apresentação. Pessoalmente, prefiro um texto simples - algumas frases com conclusões, alguns gráficos e alguns números comprovando essas conclusões, nada mais.
Gene Zelazny, diretor de comunicação visual da McKinsey & Company, afirma em seu livro Speak the Language of Diagrams:
“O tipo de gráfico não é determinado pelos dados (dólares ou juros) ou por certos parâmetros (lucro, lucratividade ou salário). e sua ideia é o que você deseja colocar no diagrama. "
Recomendo que você preste atenção aos gráficos em apresentações e artigos - eles comprovam as conclusões do autor? Você gosta de tudo sobre eles? Eles poderiam ser mais convincentes?
E aqui está o que Jean Zelazny escreve sobre slides em apresentações:
"O uso generalizado de tecnologia de computador levou ao fato de que agora, em minutos, você pode fazer o que antes eram horas de trabalho árduo - e os slides são assados como tortas ... insípidos e sem gosto."
Fiz muitos relatórios: com e sem slides, curtos, de 5 a 10 minutos, e longos - por uma hora. Posso garantir que é muito mais difícil para mim fazer um texto convincente para uma apresentação curta sem slides do que para uma apresentação em PowerPoint. Veja os políticos que falam: a tarefa deles é convencer, quantos deles mostram slides em seus discursos? A palavra é mais convincente, os slides são apenas material visual. E é mais trabalhoso deixar sua palavra clara e convincente do que lançar slides. Eu me peguei pensando em como a apresentação ficaria ao redigir os slides. E ao escrever um relatório oral - quão convincentes são os meus argumentos, como trabalhar com a entonação, quão claro é o meu pensamento. Por favor considerevocê realmente precisa de uma apresentação? Você quer transformar uma reunião em slides enfadonhos em vez de tomar decisões?
“As reuniões devem se concentrar em relatórios curtos escritos em papel, em vez de resumos ou fragmentos de listas projetadas na parede”, diz Edward Tufty, um importante porta-voz de uma escola de visualização de dados, no PowerPoint Cognitive Style.
Análise de dados pareados
Aprendi sobre programação em pares com os desenvolvedores [30] Retail Rocket. É uma técnica de programação na qual o código-fonte é criado por pares de pessoas programando a mesma tarefa e sentadas na mesma estação de trabalho. Um programador senta-se ao teclado, o outro trabalha com a cabeça, está focado no quadro geral e olha continuamente para o código produzido pelo primeiro programador. Eles podem mudar de lugar de vez em quando.
E conseguimos adaptá-lo às necessidades de análise! Analytics, como a programação, é um processo criativo. Imagine que você precisa construir uma parede. Você tem um trabalhador. Se você adicionar mais um, a velocidade dobrará aproximadamente. No processo criativo, isso não funcionará. A velocidade de criação do projeto não dobrará. Sim, você pode decompor um projeto, mas agora estou discutindo uma tarefa que não pode ser decomposta e deve ser feita por uma pessoa. A abordagem emparelhada permite que você acelere esse processo muitas vezes. Uma pessoa está no teclado, a segunda está sentada ao lado dela. Duas cabeças estão trabalhando no mesmo problema. Quando resolvo problemas difíceis, falo comigo mesmo. Quando duas cabeças conversam, procuram um motivo melhor. Usamos o esquema de trabalho em pares para as tarefas a seguir.
- Quando é necessário transferir o conhecimento de um projeto de um funcionário para outro, por exemplo, foi contratado um recém-chegado. A “cabeça” será um funcionário que transfere conhecimento, “mãos” no teclado - para quem é transferido.
- Quando o problema é complexo e incompreensível. Então, dois funcionários experientes em um par resolverão o problema com muito mais eficiência do que um. Será mais difícil tornar a tarefa de análise unilateral.
Normalmente, durante o planejamento, transferimos uma tarefa para a categoria de pares, se ficar claro que se enquadra nos critérios de tal.
As vantagens da abordagem em pares são que o tempo é usado com muito mais eficiência, ambas as pessoas são muito focadas, disciplinam-se mutuamente. Tarefas complexas são resolvidas de forma mais criativa e uma ordem de magnitude mais rápida. Menos - é impossível trabalhar neste modo por mais do que algumas horas, você fica muito cansado.
Dívida técnica
Outra coisa importante que aprendi com os engenheiros da Retail Rocket é lidar com dívidas técnicas. A dívida técnica é trabalhar com projetos antigos, otimizando a velocidade de trabalho, mudando para novas versões de bibliotecas, removendo código antigo de testes de hipóteses, simplificação de engenharia de projetos. Todas essas tarefas ocupam um bom terço do tempo de desenvolvimento de análise. Citarei o diretor técnico da Retail Rocket Andrey Chizh:
“Ainda não conheci nenhuma empresa na minha prática (e são mais de 10 empresas em que trabalhei, e aproximadamente o mesmo número que conheço bem por dentro) , exceto para a nossa, que deveria haver tarefas para remover a funcionalidade, embora, provavelmente, tais existam. "
Eu também não conheci. Eu vi os "pântanos" dos projetos de software, onde coisas antigas interferem na criação de algo novo. O ponto crucial da dívida da tecnologia é que tudo o que você fez antes precisa ser atendido. É como a manutenção de um carro - precisa ser feita regularmente, caso contrário, o carro irá quebrar no momento mais inesperado. O código que não foi alterado ou atualizado por um longo tempo é um código incorreto. Normalmente, já funciona com o princípio de "funciona - não toque". Quatro anos atrás, conversei com um desenvolvedor do Bing. Ele disse que na arquitetura desse mecanismo de busca há uma biblioteca compilada, cujo código se perdeu. E ninguém sabe como restaurá-lo. Quanto mais tempo demorar, piores serão as consequências.
Como os analistas de foguetes de varejo atendem às dívidas de tecnologia:
- , . .
- - — , . , Spark , 1.0.0.
- - — .
- - — , , .
Lidar com dívidas técnicas é o caminho para a qualidade. Eu estava convencido disso trabalhando no projeto Retail Rocket. Do ponto de vista da engenharia, o projeto é feito como nas "melhores casas da Califórnia".
Mais detalhes sobre o livro podem ser encontrados no site da editora
» Índice
» Trecho
Para Habitantes desconto de 25% no cupom - Ciência de Dados No
ato do pagamento da versão em papel do livro, é enviado um e-book para o o email.