
YELP é uma rede internacional que ajuda as pessoas a encontrar negócios e serviços locais com base em feedback, preferências e recomendações. Nos artigos atuais, uma determinada análise será realizada utilizando a plataforma Neo4j, tanto no SGBD de grafos, quanto na linguagem python.
O que veremos:
- como trabalhar com Neo4j e grandes conjuntos de dados usando YELP como exemplo;
- como o conjunto de dados YELP pode ser útil;
- em parte: quais são as características das novas versões do Neo4j e por que o livro "Graph Algorithms" 2019 de O'REILLY já está desatualizado.
O que é YELP e conjunto de dados yelp
A rede YELP cobre atualmente 30 países, a Federação Russa ainda não está incluída em seu número. O idioma russo não é compatível com a rede. A própria rede contém uma quantidade bastante volumosa de informações sobre vários tipos de empresas, bem como avaliações sobre elas. Além disso, yelp pode ser chamado com segurança de rede social, pois contém dados sobre usuários que deixaram comentários. Não há dados pessoais lá, apenas nomes. No entanto, os usuários formam comunidades, grupos ou podem ser ainda mais unidos nesses grupos e comunidades de acordo com vários critérios. Por exemplo, pelo número de estrelas (estrelas) que foram atribuídas ao ponto (restaurante, posto de gasolina, etc.) que você visitou.
YELP se descreve da seguinte forma:
- 8.635.403 avaliações
- 160.585 empresas
- 200.000 imagens
- 8 megalópoles
1.162.119 recomendações de 2.189.457 usuários.
Mais de 1,2 milhão de parafernálias de negócios: horário de funcionamento, estacionamento, disponibilidade e muito mais.
Desde 2013, o Yelp regularmente hospeda a competição do conjunto de dados do Yelp, incentivando todos a
explorar e explorar o conjunto de dados aberto do Yelp.
O conjunto de dados em si está disponível no link O
conjunto de dados é bastante volumoso e depois de descompactado consiste em 5 arquivos json:
Tudo ficaria bem, mas apenas YELP carrega dados brutos e não processados e, para começar a trabalhar com eles, é necessário um pré-processamento.
Instalação e configuração rápida do Neo4j
Para a análise, Neo4j será usado, vamos usar os recursos do gráfico DBMS e sua linguagem de cifra simples para trabalhar com o conjunto de dados.
Sobre o Neo4j como um banco de dados gráfico repetidamente escrito no Habre ( aqui e aqui para um artigo para iniciantes), então reenvie não faz sentido.
Para começar a trabalhar com a plataforma, você precisa baixar a versão desktop (cerca de 500Mb) ou trabalhar na sandbox online. No momento em que este artigo foi escrito, o Neo4j Enterprise 4.2.6 for Developers estava disponível, bem como outras versões anteriores para instalação.
Além disso, a opção será usada - trabalhar na versão desktop no ambiente Windows (Neo4j Desktop 1.4.5, versões do banco de dados 4.2.5, 4.2.1).
Apesar de a versão mais recente ser a 4.2.6, é melhor não instalá-la ainda, pois todos os plug-ins usados no neo4j ainda não foram atualizados para ela. A versão anterior - 4.2.5 será suficiente.
Depois de instalar o pacote baixado, você precisará:
- crie um novo banco de dados local, especificando o usuário neo4j e a senha 123 (por que exatamente eles serão explicados abaixo),
foto

- instale os plug-ins de que você precisa - APOC, Graph Data Science Library.
foto

- verifique se o banco de dados inicia e se o navegador abre quando você clica no botão iniciar
foto


* - habilite o modo offline para que o banco de dados não tente sugerir novas versões seriamente.
foto

Carregando dados no Neo4j
Se tudo correu bem com a instalação do Neo4j, você pode seguir em frente e existem três maneiras.
A primeira é percorrer um longo caminho desde a importação de dados do zero para o banco de dados, incluindo sua limpeza e transformação iniciais.
A segunda maneira é carregar o banco de dados concluído do dump e começar a trabalhar com ele.
A terceira maneira é carregar o banco de dados concluído diretamente na pasta com o banco de dados recém-criado.
Como resultado, em todos os casos, você deve obter um banco de dados com os seguintes parâmetros:

e o esquema final:
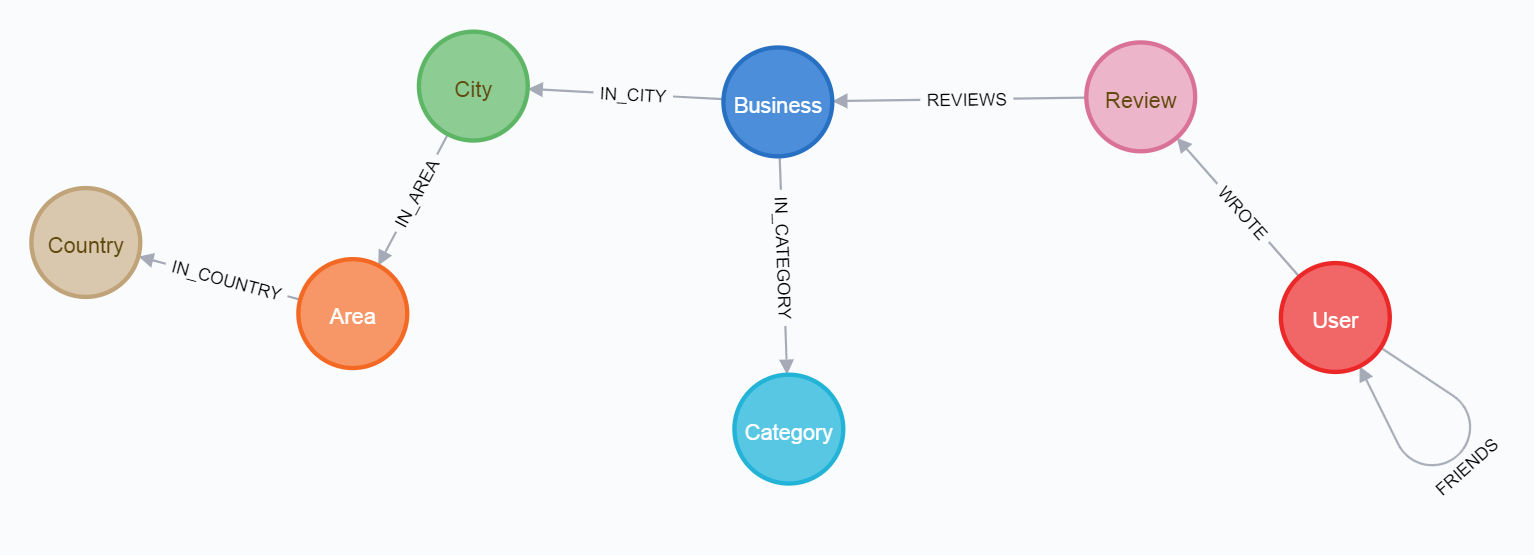
Para percorrer o primeiro caminho, é melhor ler primeiro o artigo sobre o meio .
* Muito obrigado a TRAN Ngoc Thach por isso.
E use um caderno jupyter pronto (adaptado por mim para windows) - link .
O processo de importação não é fácil e leva muito tempo -

Não há problemas com a memória, mesmo se você tiver apenas 8GB de Ram, já que a importação em lote é usada.
No entanto, você precisará criar um arquivo de swap de 10GB, pois ao verificar os dados importados, o jupyter trava, há uma menção a este ponto no notebook jupyter acima.
A segunda maneira é mais fácil.
Crie um banco de dados, vá para a pasta com seu neo4j-admin (cada banco de dados tem seu próprio) e execute:
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
onde G: \ neo4j \ dumps \ neo4j.dump é o caminho para o dump do banco de dados.
A terceira forma é a mais rápida e foi descoberta por acidente. Implica copiar um banco de dados neo4j pronto diretamente para um banco de dados neo4j existente. Das desvantagens (descobertas até agora) - você não pode fazer backup do banco de dados usando Neo4j (neo4j-admin dump --database = neo4j --to = D: \ neo4j \ neo4j.dump). No entanto, isso pode ser devido a diferenças nas versões - na versão 4.2.1, o banco de dados foi copiado da versão 4.2.5. Além disso, aparecem artefatos no esquema geral do banco de dados, mas não afetam sua operação.
Como este método é implementado:
- abra a aba Gerenciar do banco de dados onde a importação será feita
foto


- vá para a pasta com o banco de dados e copie a pasta de dados lá, sobrescrevendo as possíveis correspondências
foto

Nesse caso, não deve ser iniciado o próprio banco de dados, onde foi feita a cópia.
- Reinicie o Neo4j.
E é aqui que a senha de login que foi usada anteriormente (neo4j, 123) será útil para evitar conflitos.
Depois de iniciar o banco de dados copiado, um banco de dados com um conjunto de dados yelp estará disponível:

Assistindo YELP
Você pode estudar o YELP no navegador Neo4j e enviando consultas ao banco de dados a partir do mesmo caderno jupyter.
Devido ao fato de o banco de dados ser gráfico, o navegador será acompanhado por uma imagem visual agradável na qual esses gráficos serão exibidos.
Para começar a se familiarizar com o YELP, é necessário fazer uma reserva de que o banco de dados conterá apenas 3 países US, KG e CA:

Você pode visualizar o esquema do banco de dados escrevendo uma solicitação na linguagem de cifragem no navegador neo4j:
CALL db.schema.visualization()
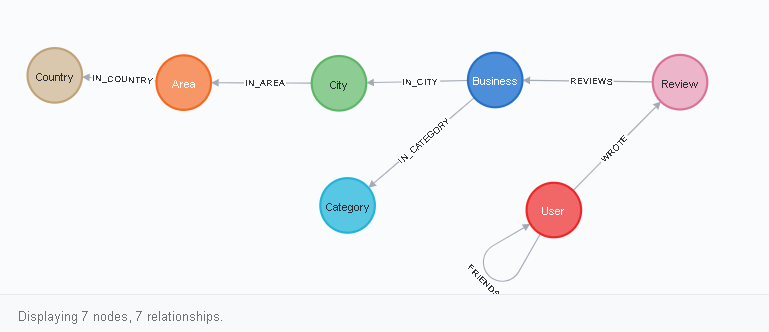
Como ler este diagrama? Tudo parece assim. O nó User possui um link para si mesmo do tipo FRIENDS, bem como um link WROTE para o nó Review. Rewiew, por sua vez, tem uma conexão REVIEWS com Negócios e assim por diante. Você pode ver isso visualmente após clicar em um dos vértices (rótulos dos nós), por exemplo, em Usuário: o

banco de dados selecionará quaisquer 25 usuários e os mostrará:

Se você clicar no ícone correspondente diretamente no usuário, então todos serão mostradas conexões diretas dele, e assim como conexões para usuário de dois tipos - AMIGOS e REVISÃO, então todos eles aparecerão:
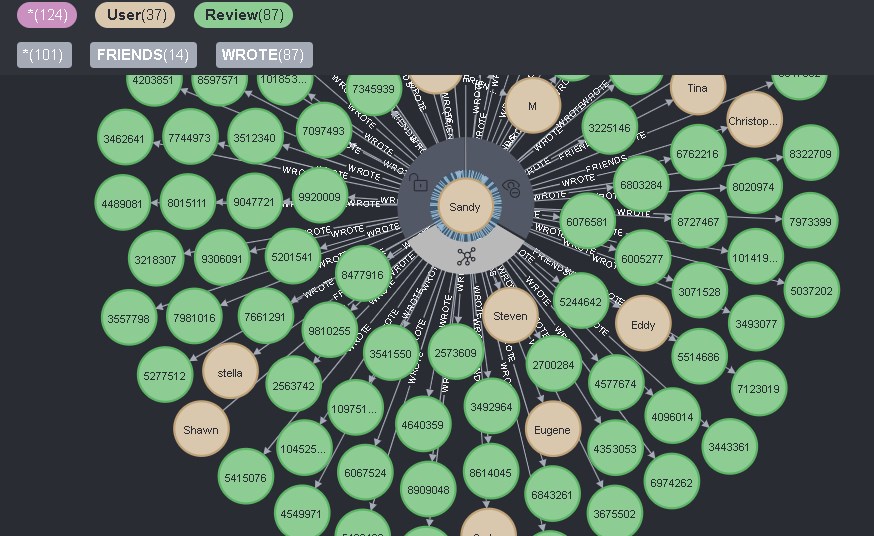
Isto é conveniente e inconveniente ao mesmo tempo. Por um lado, você pode ver todas as informações sobre o usuário com um clique, mas ao mesmo tempo, você não pode remover informações desnecessárias com este clique.
Mas não há nada com que se preocupar, você pode encontrar este usuário e apenas todos os seus amigos por id:
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

Da mesma forma, você pode ver quais comentários uma determinada pessoa escreveu:

YELP armazena comentários já de 2010! Utilidade duvidosa, mas mesmo assim.
Para ler esses comentários, você precisa mudar para a visualização de texto clicando em A -

Vamos olhar o lugar que Sandy escreveu há cerca de 10 anos e encontrá-lo em yelp.com -

Esse lugar realmente existe - www.yelp.com/ biz / cafe-sushi- cambridge ,
e aqui está a própria Sandy com sua própria crítica - www.yelp.com/biz/cafe-sushi-cambridge?q=I%20was%20really%20excited
foto

Consultas Python em Neo4j db do notebook jupyter
Ele usará parcialmente as informações do livro gratuito mencionado "Graph Algorithms" 2019 de O'REILLY. Em parte porque a sintaxe do livro está desatualizada em muitos lugares.
A base com a qual trabalharemos deve ser lançada, enquanto não há necessidade de lançar o navegador neo4j propriamente dito.
Importando bibliotecas:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
Conexão DB:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
Vamos contar o número de vértices para cada rótulo no banco de dados:
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Saída:
+ ---------- + --------- +
| etiqueta | contagem |
| ---------- + --------- |
| País | 3 |
| Área | 15
| Cidade | 355
| Categoria | 1330 |
| Negócios | 160585 |
| Usuário | 2189457 |
| Revisão | 8635403 |
+ ---------- + --------- +
Parece ser verdade, em nosso banco de dados existem 3 países, como vimos anteriormente através do navegador neo4j.
E este código contará o número de links (arestas):
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Saída:
+ ------------- + --------- +
| relType | contagem |
| ------------- + --------- |
| IN_COUNTRY | 15
| IN_AREA | 355
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| AVALIAÇÕES | 8635403 |
| WROTE | 8635403 |
| AMIGOS | 8985774 |
+ ------------- + --------- +
Acho que o princípio é claro. Finalmente, vamos escrever uma solicitação e renderizá-la.
Os 10 melhores hotéis em Vancouver com mais críticas
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
O resultado deve ser semelhante a este - o

eixo X representa a classificação por estrelas do hotel, e o eixo Y representa a porcentagem total de cada classificação.
Como o conjunto de dados YELP pode ser útil
Entre as vantagens estão as seguintes :
- um campo de informações bastante rico em termos de conteúdo. Em particular, você pode apenas coletar comentários com 1.0 ou 5.0 estrelas e enviar spam para qualquer empresa. H'm. Um pouco na direção errada, mas o vetor está claro;
- o conjunto de dados é grande, o que cria dificuldades adicionais agradáveis em termos de teste de desempenho de várias plataformas de mineração de dados;
- os dados apresentados têm uma certa retrospectiva e, a princípio, é possível entender como o empreendimento mudou, a partir das análises sobre ele;
- os dados podem ser usados como benchmarks para as empresas, desde que haja endereços disponíveis;
- os usuários no conjunto de dados geralmente formam estruturas interconectadas interessantes que podem ser consideradas como são, sem transformar os usuários em um social artificial. rede e não coletar esta rede de outras redes sociais existentes. redes.
Contras :
- apenas três países em 30 estão representados e há uma suspeita de que isso não seja totalmente,
- as avaliações são armazenadas por 10 anos, o que pode distorcer e muitas vezes estragar as características de uma empresa existente,
- há poucos dados sobre os usuários, eles são impessoais, portanto, os sistemas de recomendação baseados no conjunto de dados serão claramente coxos,
- Os links FRIENDS usam gráficos direcionados, ou seja, Anya é amiga -> Petya. Acontece que Petya não é amigo de Anya. Isso pode ser resolvido programaticamente, mas ainda é inconveniente.
- o conjunto de dados é apresentado "bruto" e requer um esforço considerável para pré-processá-lo.
Neo4j
O Neo4j é atualizado dinamicamente e a nova versão da interface usada no Neo4j Desktop 1.4.5 não é muito conveniente, na minha opinião. Em particular, há uma falta de clareza em termos de informação sobre o número de nós e links na base de dados, que existia nas versões anteriores. Além disso, a interface para navegar pelas guias ao trabalhar com o banco de dados foi alterada e você também precisa se acostumar com isso.
O principal incômodo nas atualizações é a integração de algoritmos de gráfico no plugin Graph Data Science Library. Eles eram anteriormente chamados de algoritmos de gráfico neo4j .
Após a integração, muitos algoritmos mudaram sua sintaxe significativamente. Por esse motivo, estudar o livro 2019 Graph Algorithms de O'REILLY pode ser difícil.
Despejo de banco de dados do Yelp para neo4j - download...