Esta postagem final é sobre análise de variância. Veja a postagem anterior aqui .
Análise de variação
Análise de variância (variância), que na literatura especial também é chamada de ANOVA do inglês. ANalysis Of VAriance é um conjunto de métodos estatísticos usados para medir a significância estatística das diferenças entre os grupos. Ele foi desenvolvido pelo estatístico extremamente talentoso Ronald Fisher, que também popularizou o teste de significância estatística em seus trabalhos de pesquisa de testes biológicos.
Observação... Nas postagens anteriores e nesta série de postagens, o termo “variância” foi usado em nosso termo aceito “variância” e o termo “variância” foi indicado entre parênteses em alguns lugares. Isso não é coincidência. No exterior existem termos emparelhados "variância" e "covariância" e, em teoria, deveriam ser traduzidos com uma raiz, por exemplo, como "variância" e "covariância", mas na verdade, temos uma ligação emparelhada quebrada, e eles são traduzido como "variância" e "covariância" completamente diferentes. Mas isso não é tudo. "Dispersão" (variação estatística) no exterior é um conceito genérico separado de dispersão, ou seja, o grau em que a distribuição se estende ou se contrai e as medidas de variância estatística são variância, desvio padrão e intervalo interquartil. Dispersão, como conceito genérico de dispersão, e variância, como uma de suas medidas,medir a distância da média são dois conceitos diferentes. Mais adiante no texto para variação, o termo geralmente aceito "variação" será usado em todo o texto. No entanto, essa discrepância na terminologia deve ser levada em consideração.
Nossos testes de estatística z e estatística t enfocaram as médias da amostra como o mecanismo principal para diferenciar as duas amostras. Em cada caso, procuramos a discrepância nas médias, dividida pelo nível de discrepância que poderíamos razoavelmente esperar e quantificada pelo erro padrão.
A média não é o único indicador de amostra que pode indicar uma discrepância entre as amostras. Na verdade, a variância da amostra também pode ser usada como um indicador de discrepância estatística.
, página por página e combinada")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
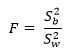
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
Na próxima série de postagens, se os leitores desejarem, aplicaremos o que aprendemos sobre variância e o teste F a amostras individuais. Apresentaremos um método de análise de regressão e o usaremos para encontrar correlações entre variáveis em uma amostra de atletas olímpicos.