Veja a postagem anterior aqui .
Amostras e populações
Em ciência estatística, os termos “amostra” e “população” têm significados especiais. Uma população, ou população geral, é todo o conjunto de objetos que um pesquisador deseja compreender ou sobre os quais tirar conclusões. Por exemplo, na segunda metade do século 19, o fundador da genética Gregor Johan Mendel) registrou observações sobre plantas de ervilha. Apesar de ter estudado variedades de plantas muito específicas em condições de laboratório, sua tarefa era compreender os mecanismos básicos subjacentes à hereditariedade de absolutamente todas as variedades de ervilhas possíveis.
Em ciência estatística, um grupo de objetos do qual uma amostra é retirada é considerado uma população, independentemente de os objetos em estudo serem seres vivos ou não.
Como a população pode ser grande - ou infinita, como no caso das ervilhas de Mendel - devemos estudar amostras representativas e tirar conclusões sobre toda a população como um todo. Para fazer uma distinção clara entre atributos mensuráveis de amostras e atributos indisponíveis de uma população, usamos o termo estatística com referência a atributos de amostra e falamos sobre parâmetros com referência a atributos de população .
Estatísticas são atributos que podemos medir com base em amostras. Os parâmetros são atributos de uma população que estamos tentando derivar estatisticamente.
Na realidade, estatísticas e parâmetros diferem devido ao uso de símbolos diferentes em fórmulas matemáticas:
Medir |
|
|
|
|
n |
N |
|
x̅ |
μx |
|
Sx |
σx |
|
Sx̅ |
|
, , Sx, σx. — , , . , , , n ≥ 30.
. , , , 1 :
def ex_2_8():
'''
'''
may_1 = '2015-05-01'
df = with_parsed_date( load_data('dwell-times.tsv') )
filtered = df.set_index( ['date'] )[may_1]
se = standard_error( filtered['dwell-time'] )
print(' :', se)
: 3.627340273094217
, — 3.6 . 3.7 . , , , , .
, , , , — , , , . , , .
« » « », , .
. «confidence» , . (trust), . . -
, , . , , , . .
95% — 95% , . , 5%- , .
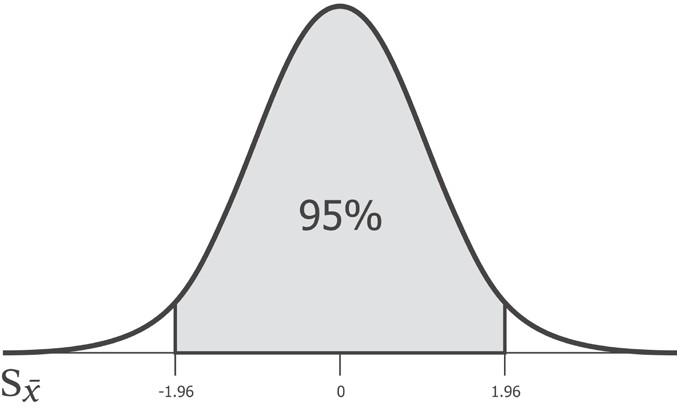
, 95% -1.96 1.96 . , , 1.96 95%- . z-.
z- , z-. , z- — .
1.96 , . , , scipy stats.norm.ppf
. confidence_interval
p 0 1. 95%- 0.95. 2 (2.5% 95%):
def confidence_interval(p, xs):
''' '''
mu = xs.mean()
se = standard_error(xs)
z_crit = stats.norm.ppf(1 - (1-p) / 2)
return [mu - z_crit * se, mu + z_crit * se]
def ex_2_9():
'''
'''
may_1 = '2015-05-01'
df = with_parsed_date( load_data('dwell-times.tsv') )
filtered = df.set_index( ['date'] )[may_1]
ci = confidence_interval(0.95, filtered['dwell-time'])
print(' : ', ci)
: [83.53415272762004, 97.753065317492741]
, 95% , 83.53 97.75 . , , , .
- AcmeContent - . , -. .
, , , , :
def ex_2_10():
''' ,
'''
ts = load_data('campaign-sample.tsv')['dwell-time']
print('n: ', ts.count())
print(': ', ts.mean())
print(': ', ts.median())
print(' : ', ts.std())
print(' : ', standard_error(ts))
ex_2_10()
n: 300
: 130.22
: 84.0
: 136.13370714388034
: 7.846572839994115
, , — 130 . 90 . , , 2 , , . , 95%- , confidence_interval, :
def ex_2_11():
''' ,
'''
ts = load_data('campaign-sample.tsv')['dwell-time']
print(' :', confidence_interval(0.95, ts))
: [114.84099983154137, 145.59900016845864]
95%- 114.8 145.6 . 90 . , - , . , .
, , , .
, , . , , , ( ) .
, « » (Literary Digest) 1936 . - : 2.4 . . — - . . 57% . , 62% .
. « » , . , , , , . — , . , .
, - . , . « » , , .
campaign_sample.tsv, , 6 2015 . , pandas:
''' '''
d = pd.to_datetime('2015 6 6')
d.weekday() in [5,6]
True
, . , , , — — , .
— :
def ex_2_12():
'''
, '''
df = load_data('dwell-times.tsv')
means = mean_dwell_times_by_date(df)['dwell-time']
means.hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
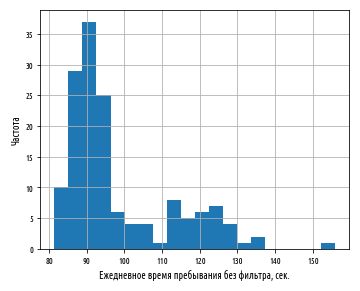
. , . , , .
. , , , , . , , .
. , . :
def ex_2_13():
''' ,
'''
df = with_parsed_date( load_data('dwell-times.tsv') )
df.index = df['date']
df = df[df['date'].index.dayofweek > 4] # -
weekend_times = df['dwell-time']
print('n: ', weekend_times.count())
print(': ', weekend_times.mean())
print(': ', weekend_times.median())
print(' : ', weekend_times.std())
print(' : ', standard_error(weekend_times))
n: 5860
: 117.78686006825939
: 81.0
: 120.65234077179436
: 1.5759770362547678
( 6- ) 117.8 . 95%- . , 130 . , , .
( - ), . , . , .
, №3.