"Não vejo nada nela", disse eu, devolvendo o chapéu para Sherlock Holmes.
"Não, Watson, você vê, mas você não se dá ao trabalho de refletir sobre o que vê.
Arthur Conan Doyle. Carbúnculo azul
Na série anterior para iniciantes (primeiro post aqui ) de um remix do livro Clojure for Data Science in Python de Henry Garner, várias abordagens numéricas e visuais foram apresentadas para entender o que é uma distribuição normal. Discutimos várias estatísticas descritivas, como média e desvio padrão, e como elas podem ser usadas para resumir grandes quantidades de dados em poucas palavras.
Um conjunto de dados geralmente é uma amostra de uma população maior ou população geral. Às vezes, essa população é muito grande para ser totalmente medida. Às vezes, é de natureza incomensurável porque é infinito em tamanho ou porque não pode ser acessado diretamente. Em qualquer caso, somos obrigados a tirar conclusões com base nos dados de que dispomos.
Nesta série de 4 postagens, veremos a implicação estatística de como você pode ir além da simples descrição de amostras e, em vez disso, descrever a população da qual foram retiradas. Analisaremos mais de perto nosso grau de confiança nas conclusões que extraímos dos dados de amostra. Vamos revelar a essência de uma abordagem robusta para a solução de problemas no campo da ciência de dados, que é o teste de hipóteses estatísticas, que só traz cientificidade ao estudo dos dados.
Além disso, no decorrer da apresentação, pontos problemáticos associados à deriva terminológica nas estatísticas domésticas, por vezes obscurecendo o significado e substituindo conceitos, serão destacados. No final da postagem final, você pode votar a favor ou contra a próxima série de postagens. Até então ...
, AcmeContent, .
AcmeContent
, , , AcmeContent . -, .
, AcmeContent - — . , -. , , - , - , AcmeContent , .
(dwell time)— , - , .
(bounce) — , — .
, , - - - - - - AcmeContent.
, : scipy, pandas matplotlib. pandas Excel, read_excel
. . pandas read_csv
, URL- .
- AcmeContent — - . :
ex_N_M, ex - example (), N - M - . . , .. - . , .
def load_data( fname ):
return pd.read_csv('data/ch02/' + fname, '\t')
def ex_2_1():
return load_data('dwell-times.tsv').head()
( Python Jupyter), , :
|
|
date |
dwell-time |
0 |
2015-01-01T00:03:43Z |
74 |
1 |
2015-01-01T00:32:12Z |
109 |
2 |
2015-01-01T01:52:18Z |
88 |
3 |
2015-01-01T01:54:30Z |
17 |
4 |
2015-01-01T02:09:24Z |
11 |
… |
… |
… |
, .
, dwell-time hist:
def ex_2_2():
load_data('dwell-times.tsv')['dwell-time'].hist(bins=50)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
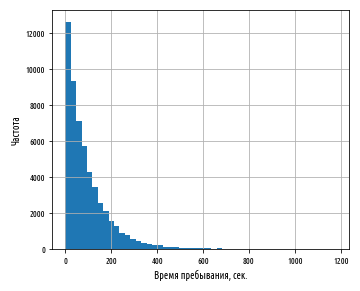
, ; . ( - 0 .). X , , .
, , , Y . , , . , « », . , , .
, , . , 10, , 5 10 4 . , — 30 10 20 . — .
Y logy=True
pandas plot.hist
:
def ex_2_3():
load_data('dwell-times.tsv')['dwell-time'].plot.hist(bins=20, logy=True)
plt.xlabel(' , .')
plt.ylabel(' ')
plt.show()
pandas , 10 . , , -. , - ( , loglog=True
).
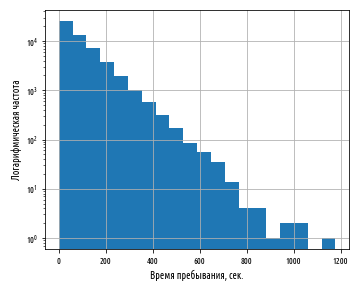
, — . , 10, , , .
— .
( ) , . , , , .
, — . , , . , — , -.
. :
def ex_2_4():
ts = load_data('dwell-times.tsv')['dwell-time']
print(': ', ts.mean())
print(': ', ts.median())
print(' :', ts.std())
: 93.2014074074074
: 64.0
: 93.96972402519819
. , . — .
.
( ). . , -, , , -, . 93 ., , 93 ., - .
, , - 93 . , , - 93 ., 5 . , .
x .
, . , ( ).
64 ., - . 93 . , . 6 . , . .
- . , , . Python, pandas — to_datetime.
, date-time, , , 1- Series
pandas , . , errors='ignore'
, . , mean_dwell_times_by_date
resample
. -, . 'D'
, mean
. , dt.resample('D').mean()
:
def with_parsed_date(df):
''' date date-time'''
df['date'] = pd.to_datetime(df['date'], errors='ignore')
return df
def filter_weekdays(df):
''' '''
return df[df['date'].index.dayofweek < 5] # ..
def mean_dwell_times_by_date(df):
''' '''
df.index = with_parsed_date(df)['date']
return df.resample('D').mean() #
def daily_mean_dwell_times(df):
''' - '''
df.index = with_parsed_date(df)['date']
df = filter_weekdays(df)
return df.resample('D').mean()
, :
def ex_2_5():
df = load_data('dwell-times.tsv')
mus = daily_mean_dwell_times(df)
print(': ', float(means.mean()))
print(': ', float(means.median()))
print(' : ', float(means.std()))
: 90.21042865056198
: 90.13661202185793
: 3.7223429053200348
90.2 . , , . , 3.7 . , , . :
def ex_2_6():
df = load_data('dwell-times.tsv')
daily_mean_dwell_times(df)['dwell-time'].hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
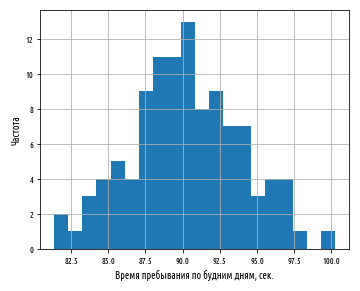
, 90 . 3.7 . , , .. , .
, . , , .
, , .
, - , — , , , . , , .
. , , . ( dropna, , ):
def ex_2_7():
''' '''
df = load_data('dwell-times.tsv')
means = daily_mean_dwell_times(df)['dwell-time'].dropna()
ax = means.hist(bins=20, normed=True)
xs = sorted(means) #
df = pd.DataFrame()
df[0] = xs
df[1] = stats.norm.pdf(xs, means.mean(), means.std())
df.plot(0, 1, linewidth=2, color='r', legend=None, ax=ax)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
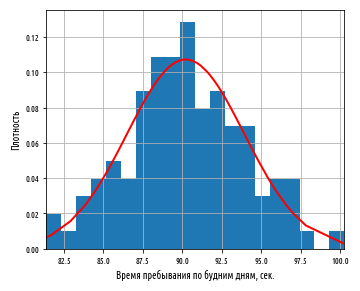
, , , 3.7 . , , 90 . , . 3.7 . — , , .
, (Standard Error, . SE) , , .
— .
, 6 . , , :

σx — , x, n — . , . . , — , :
def variance(xs):
''' () n <= 30'''
x_hat = xs.mean()
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x : (x – x_hat) ** 2
return sum( map(square_deviation, xs) ) / n
def standard_deviation(xs):
return sp.sqrt(variance(xs))
def standard_error(xs):
return standard_deviation(xs) / sp.sqrt(len(xs))
:
. , , , .
, , , . , .
O tópico da próxima postagem, postagem # 2 , será a diferença entre as amostras e a população, bem como o intervalo de confiança. Sim, é o intervalo de confiança , não o intervalo de confiança.