A postagem 2 para iniciantes é sobre estatísticas descritivas, agrupamento de dados e distribuição normal. Todas essas informações servirão de base para uma análise mais aprofundada dos dados eleitorais.
Estatísticas descritivas
Estatísticas descritivas, ou estatísticas, são números usados para resumir e descrever dados. Para ilustrar o que queremos dizer, vamos dar uma olhada na coluna Eleitorado. Mostra o número total de eleitores registrados em cada distrito:
def ex_1_6():
''' ""'''
return load_uk_scrubbed()['Electorate'].count()
650
Já limpamos a coluna filtrando os valores vazios ( nan
) do conjunto de dados e, portanto, o exemplo anterior deve retornar o número total de constituintes.
Estatísticas descritivas, chamadas de estatísticas resumidas , são diferentes abordagens para medir as propriedades de sequências de números. Eles ajudam a caracterizar a sequência e podem servir como um guia para análises posteriores. Vamos começar com as duas estatísticas mais básicas que podemos calcular a partir de uma sequência de números - sua média e variância.
Mau
A maneira mais comum de calcular a média de um conjunto de dados é fazer a média. A média é, na verdade, uma das várias maneiras de medir o centro da distribuição de dados. O valor médio de uma série numérica é calculado em Python da seguinte maneira:
def mean(xs):
''' '''
return sum(xs) / len(xs)
mean
:
def ex_1_7():
''' ""'''
return mean( load_uk_scrubbed()['Electorate'] )
70149.94
, pandas mean, . :
load_uk_scrubbed()['Electorate'].mean()
— . , — , . , , .
def median(xs):
''' '''
n = len(xs)
mid = n // 2
if n % 2 == 1:
return sorted(xs)[mid]
else:
return mean( sorted(xs)[mid-1:][:2] )
:
def ex_1_8():
''' ""'''
return median( load_uk_scrubbed()['Electorate'] )
70813.5
pandas , median
.
, . , , 50, , .
, , 5048, 50.
«» . , , , . :

s2 — , .

, square_deviation
, xs
. mean, .
def variance(xs):
''' ,
n <= 30'''
mu = mean(xs)
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) ) / n
Python **
.
, .. , , .. « ». . , «», . , :
def standard_deviation(xs):
''' '''
return sp.sqrt( variance(xs) )
def ex_1_9():
''' ""'''
return standard_deviation( load_uk_scrubbed()['Electorate'] )
7672.77
pandas , var
std
. , , , ddof=0
, , :
load_uk_scrubbed()['Electorate'].std( ddof=0 )
, .. , . 0 1, 0.5 .
:
[10 11 15 21 22.5 28 30]
, 21 . 0.5-. , 0.0 (), 0.25, 0.5, 0.75 1.0 . , . .
. pandas quantile
. .
def ex_1_10():
''' :
xs,
p- '''
q = [0, 1/4, 1/2, 3/4, 1]
return load_uk_scrubbed()['Electorate'].quantile(q=q)
0.00 21780.00
0.25 65929.25
0.50 70813.50
0.75 74948.50
1.00 109922.00
Name: Electorate, dtype: float64
, , . (0.25) (0.75) , . , .
, , (binning). , Counter
( , ) , . , - , (bins).
, . . , , :

15 x, 5 . , , , , — . Python nbin
:
def nbin(n, xs):
''' '''
min_x, max_x = min(xs), max(xs)
range_x = max_x - min_x
fn = lambda x: min( int((abs(x) - min_x) / range_x * n), n-1 )
return map(fn, xs)
, 0-14 5 :
list( nbin(5, range(15)) )
[0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4]
, , Counter
, . :
def ex_1_11():
'''m 5 '''
series = load_uk_scrubbed()['Electorate']
return Counter( nbin(5, series) )
Counter({2: 450, 3: 171, 1: 26, 0: 2, 4: 1})
(0 4) , — , , , . .
— . , , , , . , .
, , pandas hist
, .
def ex_1_12():
'''
'''
load_uk_scrubbed()['Electorate'].hist()
plt.xlabel(' ')
plt.ylabel('')
plt.show()
:
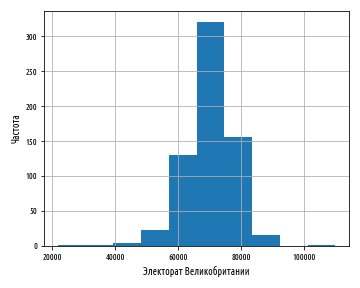
, , , bins
:
def ex_1_13():
'''
200 '''
load_uk_scrubbed()['Electorate'].hist(bins=200)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, . , , :
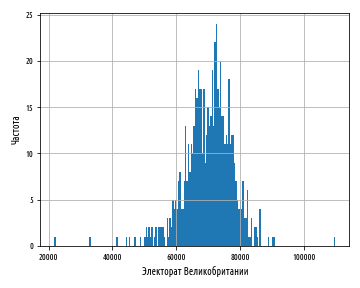
— , , .
def ex_1_14():
'''
20 '''
load_uk_scrubbed()['Electorate'].hist(bins=20)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
20 :

, 20 , , .
, . . — , . , ; , . , , .
, , . .
, , , . , , , .
- , . , , , . , .
: . , . .
. , , , , .
. , scipy stats.uniform.rvs
: . , 0 1 .
def ex_1_15():
'''
'''
xs = stats.uniform.rvs(0, 1, 10000)
pd.Series(xs).hist(bins=20)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, Series
pandas .
:
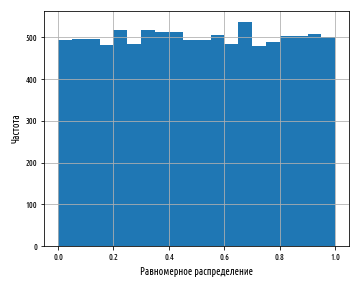
, , . , , . , , , , , . .
, , .
def bootstrap(xs, n, replace=True):
'''
n '''
return np.random.choice(xs, (len(xs), n), replace=replace)
def ex_1_16():
''' '''
xs = stats.uniform.rvs(loc=0, scale=1, size=10000)
pd.Series( map(sp.mean, bootstrap(xs, 10)) ).hist(bins=20)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :
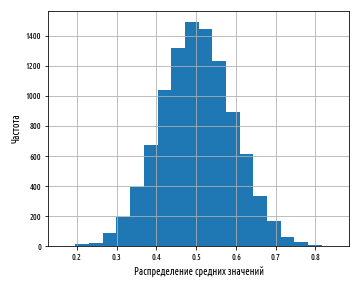
0 1 , . , .
, , , , , .
20- , 1733 . M, , . . , , scipy , :
def ex_1_17():
'''
'''
xs = stats.norm.rvs(loc=0, scale=1, size=10000)
pd.Series(xs).hist(bins=20)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, sp.random.normal
loc
– , scale
– size
– . :

Por padrão, a média e o desvio padrão para uma distribuição normal são 0 e 1, respectivamente.
Os exemplos de código fonte para este post está no meu Github repo . Todos os dados de origem são retirados do repositório do autor do livro.
A próxima parte, parte 3 , da série de postagens "Python, Data Science and Choices" é dedicada à geração de distribuições, suas propriedades e gráficos para sua análise comparativa.