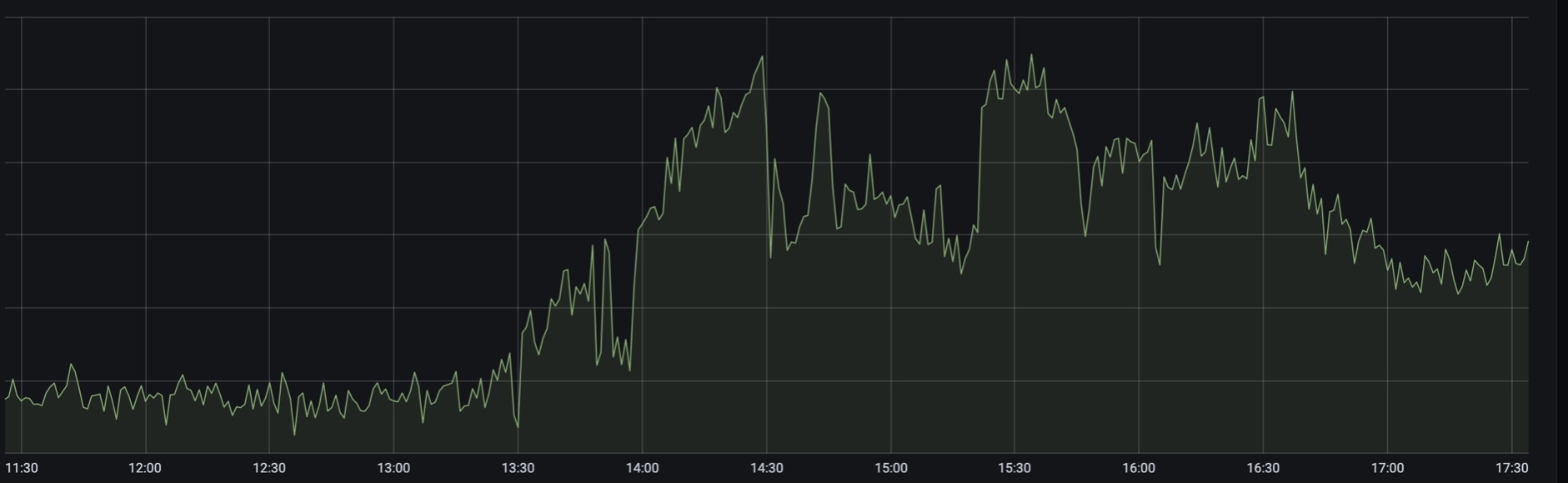
volta das 13h30, a carga de busca por passagens aéreas e ferroviárias aumentou drasticamente. Em algum lugar neste momento, a Russian Railways relatou interrupções no site e no aplicativo, e começamos a colocar urgentemente instâncias adicionais de back-ends em todos os data centers.
Mas, na verdade, os problemas começaram antes. Por volta das 8h, o monitoramento enviou um alerta sobre o fato de que em uma das réplicas do banco de dados temos algo suspeitamente muitos processos de longa duração. Mas perdemos, consideramos não muito importante.
Introdutório
Nossa infraestrutura cresceu significativamente ao longo de quase vinte anos de desenvolvimento. Os aplicativos vivem em três plataformas - o antigo código php em um monólito , a primeira versão dos microsserviços está em uma plataforma com orquestração própria, a segunda, estrategicamente correta, é OKD, onde estão os serviços php e nodejs. Em torno de tudo isso, dezenas de bases mysql com uma ligação para HA - a principal "guirlanda" servindo ao monólito, e muitos pares master-hotstandby para microsserviços. Além deles, memkesh, kafkas, mongas, rabanetes, elásticos, também estão longe de ser uma cópia única. Nginx e enviado como frontproxy . A coisa toda vive em três locais de rede e partimos do pressuposto de que a perda de qualquer um deles não afeta os usuários.
-: mysql
Temos três produtos carregados. A programação dos trens, onde há muito tráfego de entrada. A programação ferroviária para trens de longa distância e a compra e reserva de bilhetes de trem - há muito tráfego e a busca é mais difícil. Aviação com buscas muito difíceis, cache multi-estágio, muitas opções devido a transferências e bifurcações "mais ou menos 3 dias". Há muito tempo, todos os três produtos viviam apenas em um monólito, e então começamos a mover lentamente partes individuais para microsserviços. Os primeiros a serem desmontados foram os trens elétricos e, apesar de normalmente caírem sobre eles o pico de maio, a nova arquitetura é muito conveniente e fácil de escalar para o crescimento da carga. No caso da aviação, a maior parte do monólito foi roubada e, bem no momento do dia P, os testes A / B do sagest geográfico já estavam em andamento há uma semana. Comparamos duas versões da implementação - uma nova,no elasticsearch e no antigo mysql. Na época do lançamento, em 15 de abril, eles já haviam pegado uma série de problemas, mas logo foram concebidos, corrigiram o código e decidiram que não dispararia novamente.
Tomada. Deve-se notar que a versão antiga é sua própria implementação de pesquisa de texto completo e classificação no mysql. Não é a melhor solução, mas testada pelo tempo e quase sempre funcionando. Os problemas começam quando qualquer uma das tabelas está altamente fragmentada, então todas as consultas com sua participação começam a desacelerar e carregar pesadamente o sistema. E, obviamente, às 8h ultrapassamos esse limiar de fragmentação, que foi informado pelo alerta. A reação padrão para uma situação tão rara, mas ainda esperada, é tirar uma réplica maçante da carga (com nossa camada de proxy do proxysql, isso é fácil de fazer) e, em seguida, executar otimizar + analisar e devolvê-la de volta. Levando em consideração a reserva de energia durante os tempos normais sob carga normal, isso não causa problemas. Mas aqui, em um momento de silêncio, não processamos este alerta.
13h20
Por volta dessa época, soam as notícias sobre os feriados de maio e os dias não úteis.
Pico de tráfego por volta das 13h30
Como descobrimos mais tarde, poucos minutos após o anúncio do fim de semana adicional (que não é um fim de semana, mas um “fim de semana”), o tráfego começou a crescer. A carga foi abruptamente. No pico, estava 2,5 a 3 vezes do normal, e isso continuou por várias horas.
Fomos quase imediatamente bombardeados com “alertas de emergência” - alertas do nível de criticidade “acordar e consertar”. Em primeiro lugar, foi um alerta sobre o crescimento de 50 * erros que enviamos aos clientes do nosso frontproxy. Em um nível abaixo, um alerta para erros de conexão de banco de dados foi acionado e nos logs vimos algo assim: "DB: Tempo limite máximo de conexão atingido ao atingir o grupo de host 102 após 3162ms". Além disso, alertas sobre a falta de capacidade nos três grupos de servidores de aplicativos da antiga plataforma monolítica. Tempestade de alerta em sua forma mais pura.
A ideia dos motivos surgiu quase no mesmo instante, antes mesmo de entrar na programação com os pedidos recebidos - a notícia das "férias" já tinha aparecido na correspondência interna nos chats.
Tendo voltado um pouco aos seus sentidos em uma situação de Achtung quase completa, eles começaram a reagir. Escale servidores de aplicativos, lide com erros na interface entre o aplicativo e a base. Rapidamente nos lembramos do alerta que estivera “queimando” pela manhã e encontramos nossos velhos conhecidos da sela de geografia na lista de processos da observação enferma. Entramos em contato com a equipe da avia, e eles confirmaram que o crescimento do tráfego nos últimos dias de abril, que não chegou perto nos últimos 15 anos, é real. E isso não é um ataque, não é algum tipo de problema de equilíbrio, mas usuários naturais ao vivo. E sob seus pedidos animados, nossa réplica já sobrecarregada ficou completamente doente.
Alexey, nosso DBA, tirou a réplica da carga, acertou em processos de longa duração e seguiu o procedimento padrão de otimização de tabela. Isso tudo é rápido, alguns minutos, mas durante esse tempo, com tanto tráfego, as réplicas restantes ficaram ainda piores. Nós entendemos isso, mas o escolhemos como o menor dos males.
Quase em paralelo, por volta das 13:40, novos servidores de aplicativos começaram a ser despejados, percebendo que essa carga não é algo que não irá embora rapidamente por conta própria, mas ao invés disso, pode crescer, e o próprio processo para a parte monolítica não é muito rápido.
A manipulação da base ajudou por um tempo. Das 13h50 às 14h30, tudo estava calmo.
Segundo pico - por volta das 14:30
Naquele momento, o monitoramento nos informou que o site da Russian Railways estava fora do ar. Bem, isto é, na verdade, ele disse que os backends dos trens pioraram, e ficamos sabendo da Russian Railways mais tarde, quando a notícia foi divulgada . Em tempo real, foi assim para nós.

A carga parece estar relacionada a interrupções no site da Russian Railways
. Infelizmente, a maioria dos trens ainda vive em um monólito e só pode ser dimensionada no nível do aplicativo adicionando novos back-ends. E isso, como escrevi acima, é um procedimento lento e difícil de acelerar. Portanto, tudo o que faltava era esperar até que as automáticas já iniciadas funcionassem. Em microsserviços, tudo é muito mais simples, claro, mas o movimento em si ... embora seja uma história diferente.
A espera não foi enfadonha. Em cerca de 5 minutos, o gargalo do sistema de alguma forma ainda não totalmente clara "empurrou" da camada do aplicativo para a camada do banco de dados, seja para a própria base ou para o proxysql. E por volta das 14h40, paramos completamente de gravar no cluster principal do mysql. O que exatamente aconteceu lá, ainda não descobrimos, mas mudar o master para reserva hotstandby ajudou. E depois de 10 minutos devolvemos o registro. Na mesma época, eles decidiram transferir à força toda a carga do sadget para o elástico, sacrificando os resultados da campanha AB. O quanto ajudou, eles também não perceberam, mas certamente não piorou.
15:00
A gravação ganhou vida, parece que tudo deve estar bem, e a carga nas réplicas e no proxysql na frente delas é normal. Mas, por algum motivo, os erros durante as solicitações de leitura do aplicativo para o banco de dados não terminam. Em cerca de 15-20 minutos aderindo a gráficos em camadas diferentes e procurando pelo menos alguns padrões, percebemos que os erros vêm de apenas um proxysql. Reiniciou e os erros desapareceram. A causa raiz foi descoberta muito mais tarde, com uma análise detalhada da falha. Acontece que durante a última emergência, uma semana antes, durante o início da campanha AB sobre sagest, proxysql não fechou corretamente as conexões com uma das réplicas da guirlanda, que foi então manipulada. E nesta instância do proxysql, estupidamente nos deparamos com uma falta de portas para o tráfego de saída. Essa métrica, é claro, vai funcionar, mas nunca nos ocorreu desligar um alerta nela. Agora já está aí.
15:20
Todos os produtos foram restaurados, exceto trens.
15:50
Os últimos backends de trem foram estendidos. Normalmente não leva duas horas, mas uma hora, mas aqui eles próprios bagunçaram um pouco em uma situação estressante.
Como costuma acontecer, foi consertado em um lugar, quebrado em outro. Os back-ends começaram a aceitar mais conexões, os front-proxies começaram a diminuir as solicitações do cliente devido ao estouro de upstreams, como resultado, o tráfego interno entre serviços aumentou. E havia um serviço de autorização. Este é um microsserviço, mas não em OKD, mas em uma plataforma antiga. A escala é mais simples do que no monólito, mas pior do que no OKD. Nós o levantamos por cerca de 15 minutos, torcendo os parâmetros várias vezes e adicionando capacidades, mas no final também funcionou.
16:10
Uau, está tudo funcionando, você pode ir almoçar.
Lindas fotos
Eles são bonitos porque não são totalmente informativos, mas os eixos não foram testados pelo Conselho de Segurança.
Gráfico dos anos 500:

O quadro geral da carga por 2 dias:
Conclusões do capitão
- Obrigado por não esta noite.
- Você precisa fazer algo sobre os alertas. Já são muitos, mas, por um lado, às vezes ainda não chega, e por outro lado, alguns estão esgotados, inclusive pela quantidade. E o custo do suporte aumenta a cada novo alerta. Em geral, ainda há compreensão do problema, mas não há solução estratégica. Ele está escondido em algum lugar na junção de processos e ferramentas que estamos procurando. Mas já tratamos de alguns alertas taticamente.
- . , - proxysql , . , .
- , OKD . .
- . , , , .