Hoje vou contar por que a entrega terceirizada nem sempre é boa, por que você precisa de transparência no processo e como criamos uma plataforma em um ano e meio que ajuda nossos entregadores a entregar pedidos. Também compartilharei três histórias do mundo do desenvolvimento.

Na foto, está a equipe da plataforma de correio, há dez meses. Naquela época, ela era colocada em uma sala. Agora somos 5 vezes mais.
Por que fizemos tudo isso
Ao desenvolver a plataforma de correio, queríamos atualizar três coisas principais.
O primeiro é a qualidade . Quando trabalhamos com serviços de entrega externos, a qualidade não pode ser controlada. A empresa contratante promete que haverá tal e tal entregabilidade, mas um certo número de pedidos pode não ser entregue. E queríamos reduzir a porcentagem de atrasos ao mínimo, para que quase todos os pedidos fossem entregues no prazo.
O segundo é a transparência... Quando algo dá errado (há transferências, prazos), não sabemos por que aconteceram. Não podemos ir e falar: "Gente, vamos fazer assim." Nós próprios não vemos e não podemos mostrar ao cliente quaisquer coisas adicionais. Por exemplo, que o pedido chegará não às oito, mas em 15 minutos. Isso ocorre porque não existe esse nível de transparência no processo.
O terceiro é dinheiro... Quando trabalhamos com um empreiteiro, existe um contrato que especifica os valores. E podemos alterar esses números dentro da estrutura do contrato. E quando somos responsáveis por todo o processo de a a z, então você pode ver quais partes do sistema são projetadas de forma economicamente não lucrativa. E você pode, por exemplo, alterar o provedor de SMS ou o formato do fluxo do documento. Ou você pode notar que os mensageiros têm uma quilometragem muito alta. E se você construir rotas mais próximas, no final você será capaz de entregar mais pedidos. Graças a isso, você também pode economizar dinheiro - a entrega se tornará mais eficiente.
Esses foram os três objetivos que definimos como a cabeça de tudo.
Qual é a aparência da plataforma
Vamos ver o que temos.
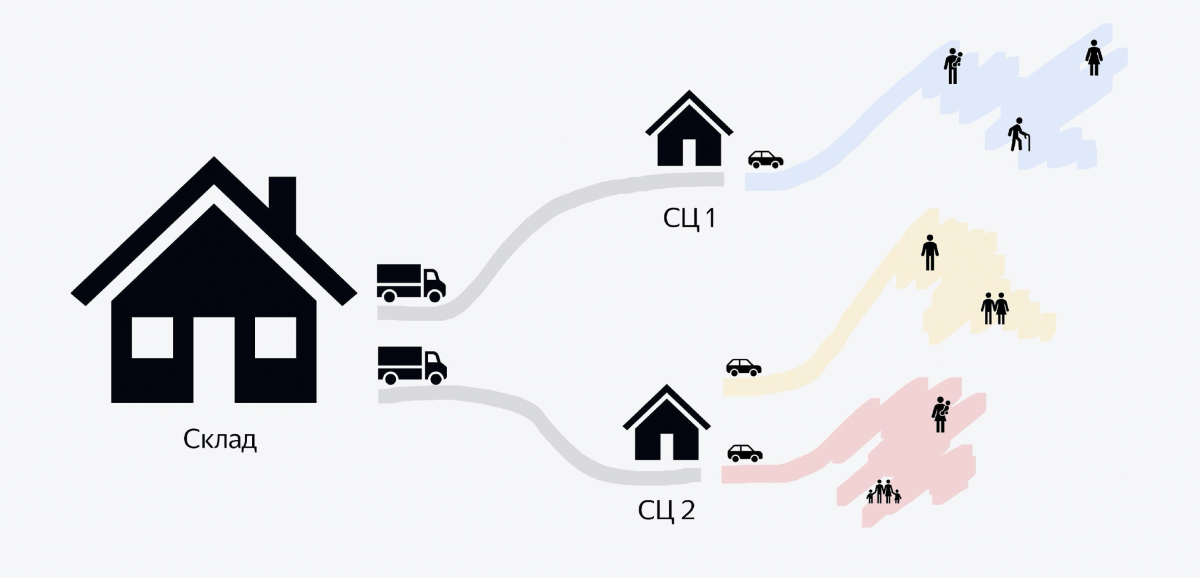
A imagem mostra um diagrama do processo. Temos grandes depósitos que mantêm centenas de milhares de pedidos. Caminhões lotados de pedidos saem de cada depósito à noite. Pode haver de 5 a 6 mil pedidos. Esses caminhões viajam para edifícios menores chamados centros de triagem. Neles, em poucas horas, uma grande pilha de pedidos se transforma em pequenas pilhas para os mensageiros. E quando os mensageiros chegam em carros pela manhã, cada mensageiro sabe que precisa pegar um monte com este código QR, carregá-lo em seu carro e ir para a entrega.
E o back-end sobre o qual quero falar neste artigo é sobre a última parte do processo, quando os pedidos são levados aos clientes. Tudo o que está antes disso, por enquanto, vamos deixar de lado.
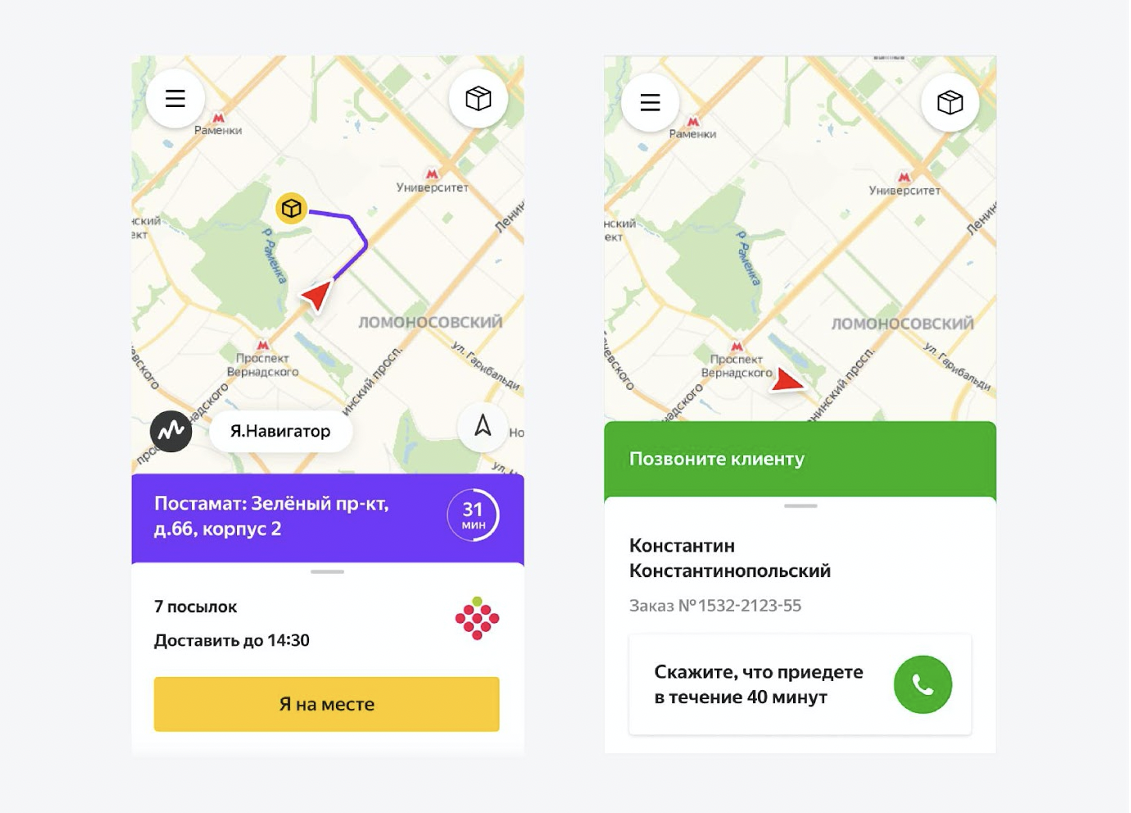
Como o mensageiro vê isso. Os
mensageiros têm um aplicativo Android escrito em React Native. E neste aplicativo, eles veem o dia inteiro. Eles entendem claramente a sequência: qual endereço ir primeiro, qual depois. Quando ligar para um cliente, quando levar devoluções à central de triagem, como começar o dia, como encerrá-lo. Eles veem tudo no aplicativo e praticamente não fazem perguntas desnecessárias. Nós os ajudamos muito. Basicamente, eles estão apenas fazendo atribuições.
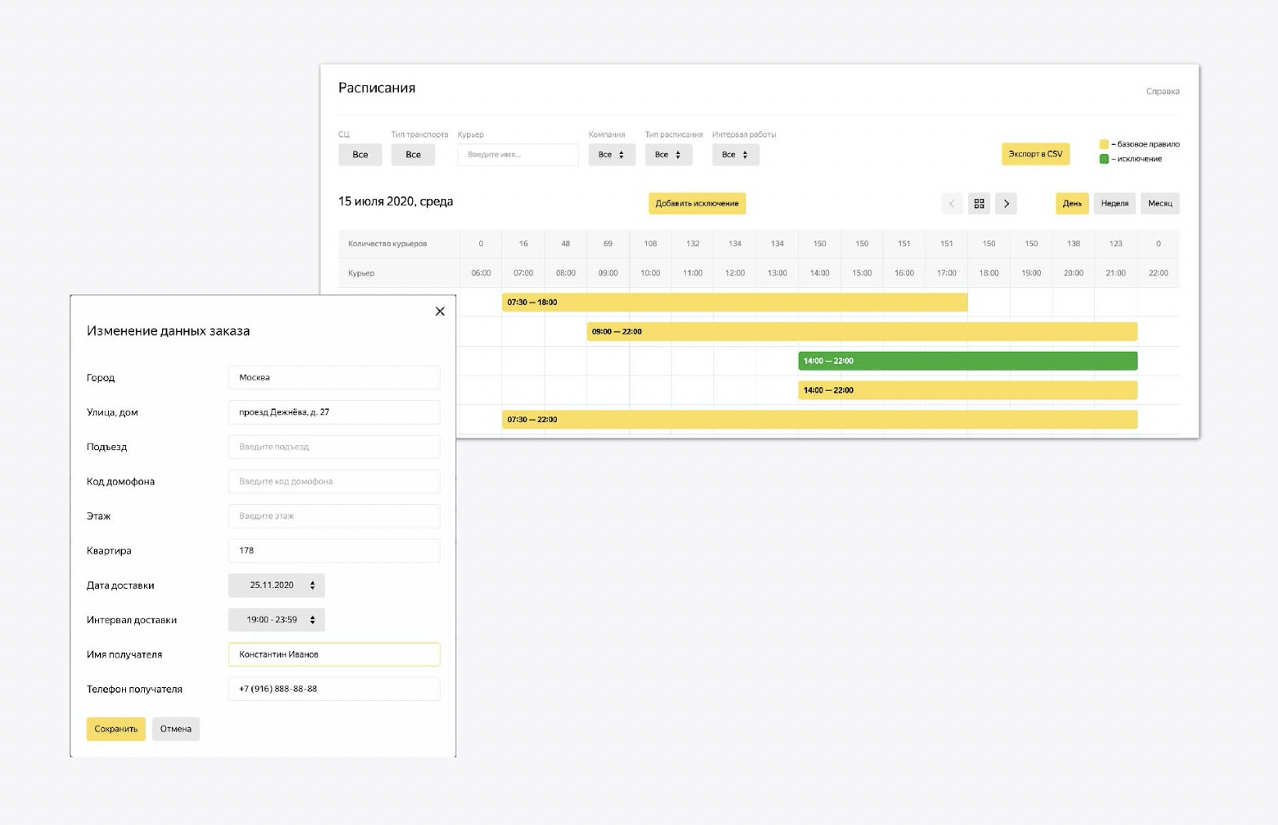
Além disso, existem controles na plataforma. Este é um painel de administração multifuncional que reutilizamos de outro serviço Yandex. Nesta área administrativa, você pode configurar o estado do sistema. Fazemos upload de dados sobre novos correios lá, alteramos os intervalos de trabalho. Podemos ajustar o processo de criação de tarefas para amanhã. Quase tudo que você precisa é regulamentado.
A propósito, sobre o back-end. Nós do Market amamos muito o Java, principalmente a versão 11. E todos os serviços de back-end, que serão discutidos, são escritos em Java.
Arquitetura
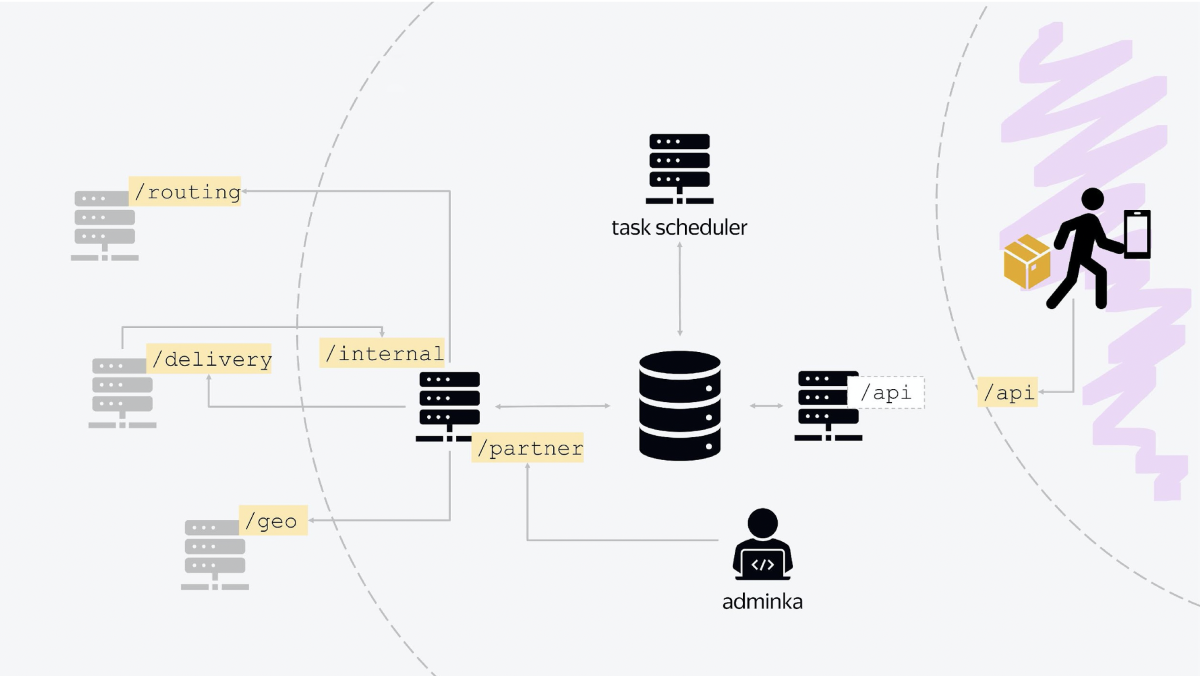
Existem três nós principais na arquitetura de nossa plataforma. O primeiro é responsável pela comunicação com o mundo exterior. O aplicativo de correio “bate” no balanceador, que é trazido, comunicando-se com ele usando a API JSON HTTP padrão. Na verdade, este nó é responsável por toda a lógica do dia atual, quando os entregadores transferem algo, cancelam algo, emitem pedidos, recebem novas tarefas.
O segundo nó é um serviço que se comunica com os serviços internos Yandex. Todos os serviços são serviços RESTful clássicos com comunicação padrão. Quando você faz um pedido no Market, depois de um tempo chegará a você um documento em formato JSON, onde tudo estará escrito: quando entregamos, para quem entregamos, em que intervalo. E vamos salvar esse estado no banco de dados. É simples.
Além disso, o segundo nó também se comunica com outros serviços internos, não com o Market, mas com o Yandex. Por exemplo, para esclarecer geocoordenadas, vamos para o geosserviço. Para enviar uma notificação push, vamos para o serviço que envia push e SMS. Usamos outro serviço para autorização. Outro serviço de cálculo de roteamento para amanhã. Assim, toda a comunicação com os serviços internos é realizada.
Este nó também é um ponto de entrada, ele tem uma API na qual nosso painel de administração bate. Ele tem seu próprio ponto de extremidade, que é chamado, digamos, / parceiro. E nosso painel de administração, todo o estado do sistema, é configurado através da comunicação com este serviço.
O terceiro nó é a base de tarefas em segundo plano. Aqui o Quartz 2 é usado, existem tarefas que são lançadas na coroa com diferentes condições para diferentes pontos, para diferentes centros de classificação. Há tarefas de atualizar o dia, tarefas de fechar o dia, começar um novo dia.
E no centro de tudo está o banco de dados, que, de fato, armazena todo o estado. Todos os serviços estão incluídos em um banco de dados.
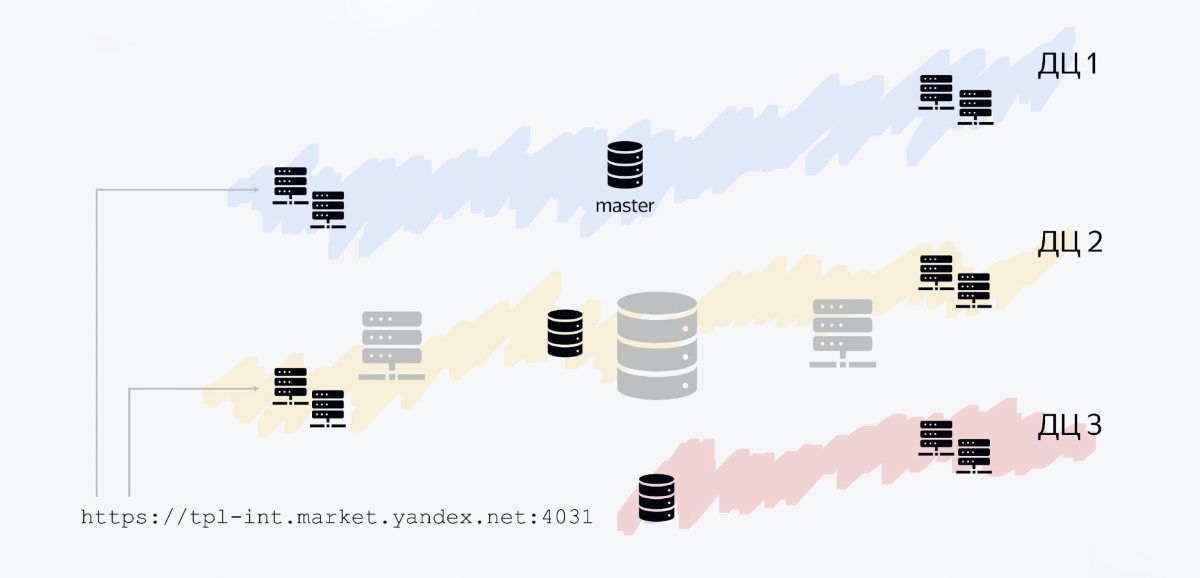
tolerância ao erro
Yandex tem vários data centers e nosso serviço é distribuído regionalmente em três data centers. O que isso parece.
O banco de dados consiste em três hosts, cada um em seu próprio data center. Um host é o mestre, os outros dois são réplicas. Escrevemos para o mestre, lemos as falas. Todos os outros serviços Java também são processos Java executados em vários datacenters.
Um dos nós é nossa API. Funciona em todos os três datacenters, porque o fluxo de mensagens é maior do que nos serviços internos. Além disso, esse layout permite dimensionar horizontalmente com bastante facilidade.
Por exemplo, se o tráfego de entrada aumenta nove vezes, você pode otimizar, mas também pode "inundar" esse negócio com ferro, abrindo mais nós que irão processar o tráfego de entrada.
O balanceador simplesmente terá que dividir o tráfego em um número maior de pontos que atendam às solicitações. E agora, por exemplo, não temos um nó, mas dois nós em cada data center.
Nossa arquitetura nos permite lidar até com casos como o desligamento de um dos data centers. Por exemplo, decidimos realizar um exercício e desligamos o data center em Vladimir - e nosso serviço continua funcionando, nada muda. Os hosts de banco de dados que estão lá desaparecem e o serviço permanece em operação.
O balanceador entende depois de um tempo: sim, não tenho um único host ativo neste data center, e ele não redireciona mais o tráfego para lá.
Todos os serviços em Yandex são organizados de forma semelhante, todos nós sabemos como sobreviver à falha de um dos centros de dados. Já descrevemos como isso é implementado, o que é degradação normal e como os serviços Yandex lidam com o desligamento de um dos data centers .
Então isso era arquitetura. E agora as histórias começam.
A primeira história - sobre Yandex.Rover
Recentemente, tivemos uma outra conferência, onde a Rover recebeu muita atenção. Vou continuar o tópico.
Certa vez, os caras da equipe Yandex.Rover vieram até nós e se ofereceram para testar a hipótese de que as pessoas gostariam de receber pedidos de uma forma tão extraordinária.
Yandex.Rover é um pequeno robô do tamanho de um cachorro comum. Você pode colocar comida lá, algumas caixas de pedidos - ele vai andar pela cidade e trazer pedidos sem ajuda humana. Existe um lidar, o robô entende sua posição no espaço. Ele sabe como entregar pedidos pequenos.
E pensamos: por que não? Esclarecemos os detalhes do experimento: naquela época era necessário testar a hipótese de que as pessoas gostariam. E decidimos entregar 50 pedidos em uma semana e meia em um modo muito leve.
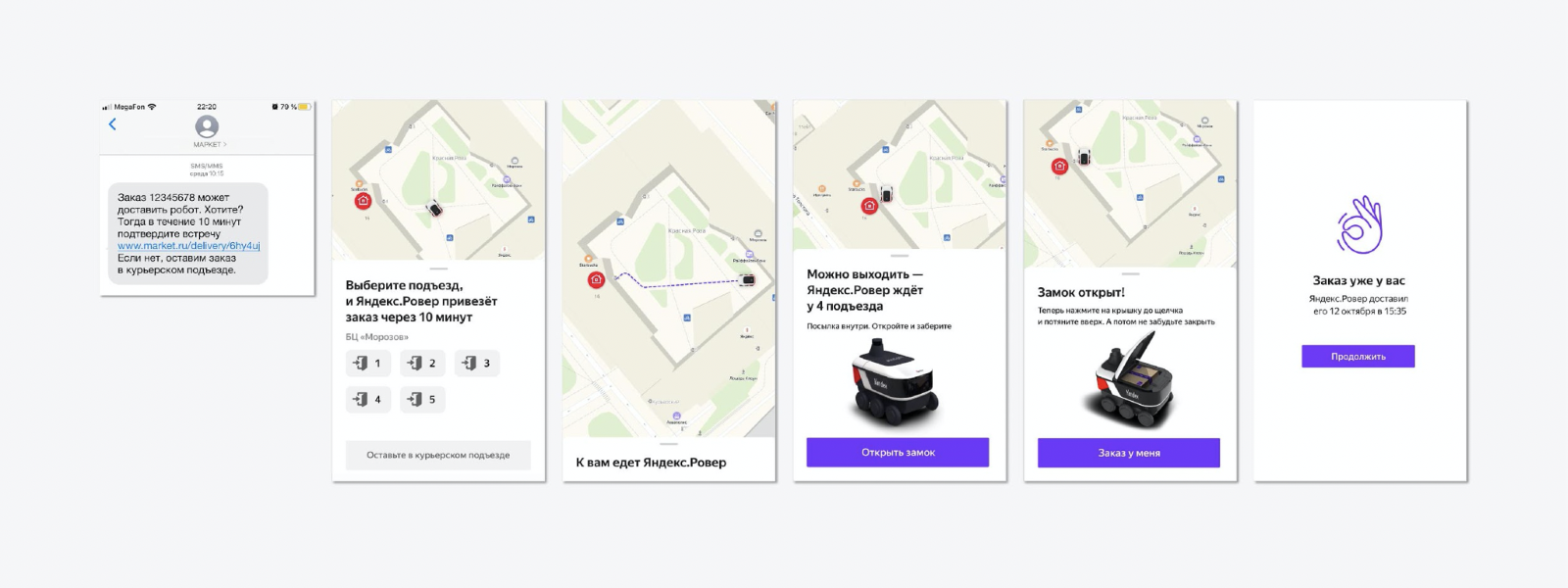
Chegamos ao fluxo mais simples, quando uma pessoa recebe um SMS com uma proposta de método de entrega fora do padrão - não é o mensageiro que o traz, mas o Rover. Todo o experimento ocorreu no pátio de Yandex. O homem estava escolhendo a entrada pela qual o Rover iria subir. Quando o robô chegou, a tampa foi aberta, o cliente anotou o pedido, fechou a tampa e o Rover saiu para um novo pedido. É simples.
Em seguida, fomos para a equipe de Rover para negociar uma API.
Existem métodos simples na API Rover: abra a tampa, feche a tampa, vá até um determinado ponto, obtenha um estado. Clássico. Também JSON. Muito simples.
O que também é muito importante: tanto essas pequenas histórias quanto quaisquer grandes histórias são melhor feitas por meio de sinalizadores de recursos. Na verdade, você tem um interruptor pelo qual pode ativar essa história em produção. Quando você não precisar mais dele, o experimento foi concluído com sucesso ou não, ou você percebeu alguns bugs, basta eliminá-lo. E você não precisa fazer outra implantação da nova versão do código para produção. Essa coisa torna a vida muito mais fácil.
Parece que tudo é simples e tudo deve funcionar. Não tem nada para desenvolver aí por duas semanas, dá pra fazer em poucos dias. Mas veja onde o cachorro está enterrado.
Todos os processos são principalmente síncronos. O homem aperta um botão, a tampa se abre. O homem aperta o botão, a tampa fecha. Mas um desses processos é assíncrono. No momento em que o Rover vai até você, é necessário ter algum tipo de processo em segundo plano que rastreie se o robô voltou ao ponto.
E neste momento enviaremos um SMS para a pessoa, por exemplo, que o Rover está esperando no local. Isso não pode ser feito de forma síncrona e você precisa resolver o problema de alguma forma.
Existem muitas abordagens diferentes. Nós o tornamos o mais simples possível.
Decidimos que podemos executar o encadeamento ou tarefa Java em segundo plano mais comum no Executer. Este thread de segundo plano é iniciado imediatamente para rastrear o processo. E assim que o processo for concluído, enviamos uma notificação.
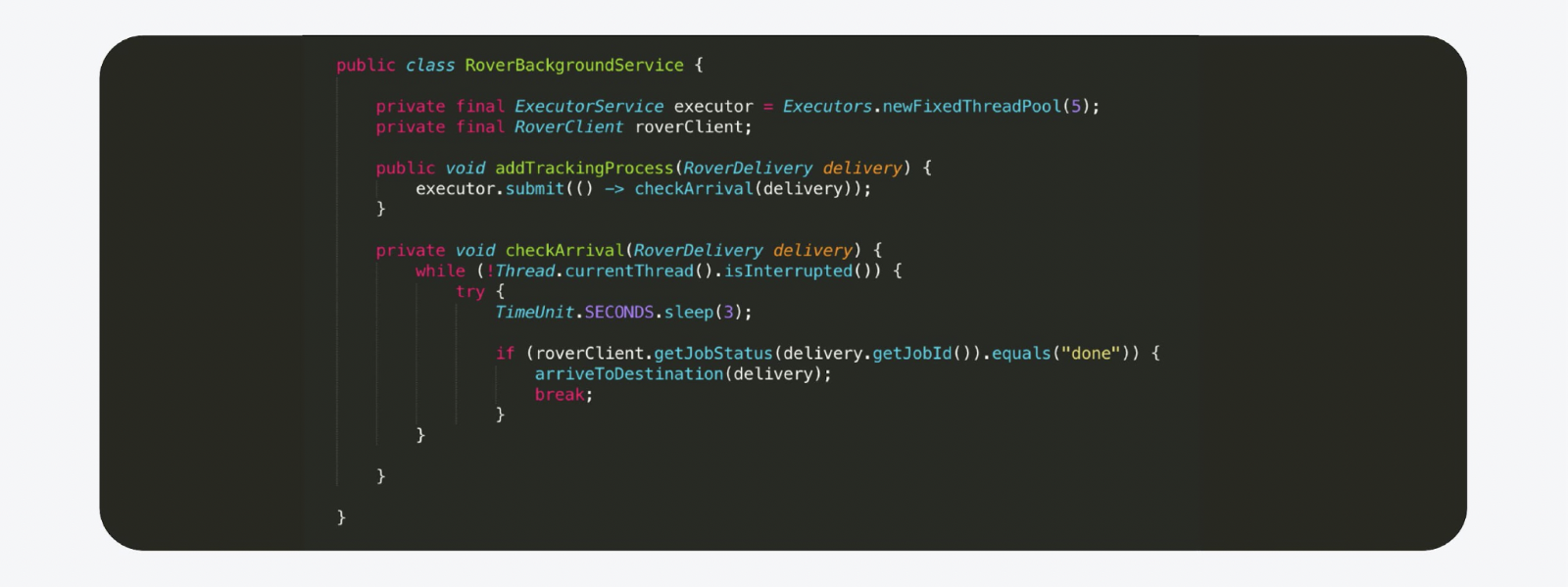
Por exemplo, é assim. Esta é praticamente uma cópia do código de produção, com exceção dos comentários eliminados. Mas há um porém. Você não pode fazer sistemas sérios dessa maneira. Digamos que estamos lançando uma nova versão para o back-end. O host reinicia, o estado é perdido e é isso, o Rover vai para o infinito, ninguém mais o vê.
Mas por que? Se sabemos que nossa meta é entregar 50 pedidos em uma semana e meia, escolhemos o horário em que monitoramos o back-end. Se algo der errado, você pode alterar algo manualmente. Para tal, esta solução é mais do que suficiente. E esta é a moral da primeira história.
Existem situações para as quais você precisa fazer a versão mínima da funcionalidade. Não há necessidade de cercar um jardim e fazer engenharia excessiva. É melhor torná-lo o mais alienado possível. Para não mudar muito a lógica dos objetos internos. E o excesso de complexidade, dívida técnica desnecessária não se acumulou.
A segunda história - sobre bancos de dados
Mas, primeiro, algumas palavras sobre como as entidades principais são organizadas. Existe um serviço Yandex.Routing que cria rotas para os mensageiros no final do dia.
Cada rota consiste em pontos no mapa. E em cada ponto os mensageiros têm uma tarefa. Isso pode ser uma tarefa para emitir um pedido, ou ligar para um cliente, ou na carga da manhã na central de triagem, pegar todos os pedidos.
Além disso, os clientes recebem um link de rastreamento pela manhã. Eles podem abrir o mapa e ver como o mensageiro viaja até eles. O cliente também pode escolher a entrega por Rover, que mencionei anteriormente.
Agora vamos ver como essas entidades podem ser exibidas no banco de dados. Isso é feito, por exemplo, assim.
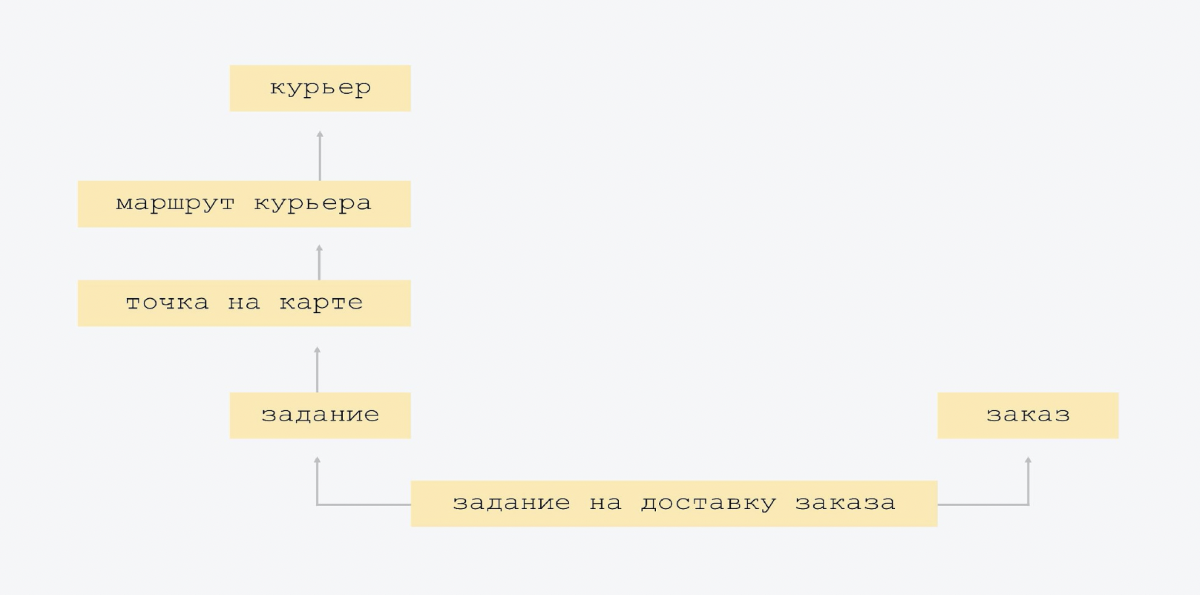
Este é um modelo de dados muito bom. Não inventamos uma única entidade nova e não colapsamos fortemente as existentes.
O diagrama mostra que a seta de baixo para cima mostra a rota do mensageiro, conhece o mensageiro de quem é a rota. O sinal de rota do correio contém o link do ID do correio. E a placa superior não sabe disso. Temos a conectividade mais simples, não há grande interseção de entidades. Quando todos sabem sobre todos, é mais difícil de controlar e, muito provavelmente, haverá redundância. Portanto, temos o esquema mais simples possível.
O único "exagero" que fizemos no início da criação da plataforma é esse. Tínhamos um tipo de atribuição de entrega. Mas percebemos que no futuro haverá outras tarefas. E colocamos um pouco de flexibilidade arquitetônica: temos tarefas, e um dos tipos de tarefas é a entrega de pedidos.
Em seguida, adicionamos rastreamento e Rover. Apenas dois comprimidos. No rastreamento, o mensageiro envia suas coordenadas, nós as gravamos em uma placa separada. E há rastreamento de pedido com seu próprio modelo de estado, há coisas adicionais, como "SMS deixou / não foi embora." Você não deve adicionar isso diretamente à tarefa. É melhor colocá-lo em um prato separado, porque esse rastreamento não é necessário para todos os tipos de tarefas.
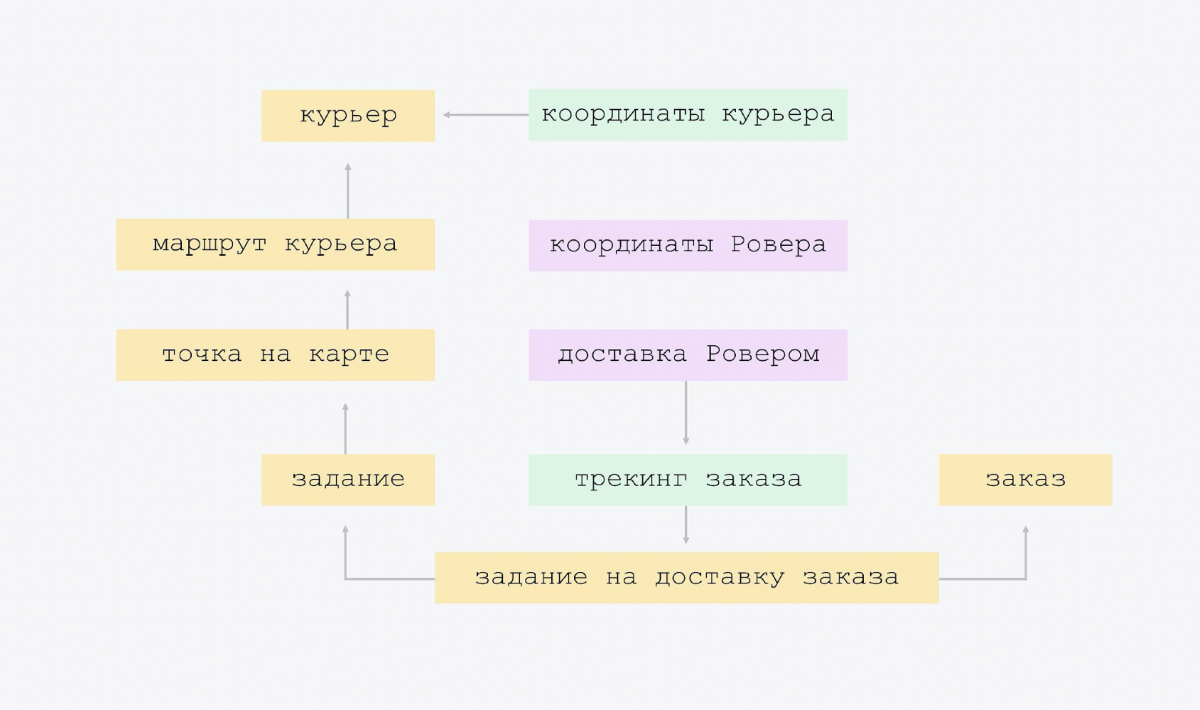
Em Rover - suas coordenadas e entrega. Nossa entrega por Rover é como rastreamento para Rover. Você pode adicioná-lo ao pedido de rastreamento, mas por quê? Afinal, quando nos livrarmos desse experimento, quando ele for desativado, essas opções permanecerão para sempre na essência do rastreamento. Haverá campos nulos.
Pode surgir a pergunta: por que fazer uma placa com coordenadas? Um Rover entrega cinco pedidos por dia. Você não precisa armazenar coordenadas no banco de dados, você pode simplesmente ir para a API Rover e obtê-las em tempo de execução.
O resultado final é que isso foi feito inicialmente. Esta placa não estava lá, imediatamente fomos ao serviço e levamos tudo. Mas durante os testes, vimos que muitas pessoas abrem um mapa com um Rover móvel, e a carga neste serviço aumenta muitas vezes. Digamos que sete pessoas abram. E ali na página a cada dois segundos o Java Script pede as coordenadas. E os colegas nos escreveram no chat: “De onde vem essa carga? Você tem uma pessoa lá para andar de skate. "
E depois disso, adicionamos um sinal. Começamos a somar as coordenadas ali, o horário em que foram recebidas. E agora, se as pessoas vêm até nós com muita frequência para obter as coordenadas e dois segundos não se passaram desde o último recebimento, nós os retiramos do prato. Acontece que esse cache no nível do banco de dados.
Essa história poderia ser feita com 20 tabelas. Duas mesas podem ser usadas: correio e pedido. Mas, no primeiro caso, seria um excesso de engenharia e, no segundo caso, seria muito difícil de manter. Lógica complexa, difícil de testar.
E mais longe. A estrutura das bases de dados, que fizemos há um ano e meio, o núcleo dessas entidades permanece o mesmo até hoje. E tivemos muita sorte em poder escolher essas entidades nas quais a base não precisava ser refeita. Não houve necessidade de redesenhar significativamente os bancos de dados, fazer migrações complexas e, em seguida, lançar esta versão, testá-la por um longo tempo e, em seguida, alterar a estrutura raiz.
O ponto da história é que existem aspectos aos quais é melhor prestar atenção extra. O primeiro é preste atenção especial à estrutura da API e do banco de dados . Tente perceber que tipo de entidades você tem na vida real. Tente digitalizar essa estrutura da mesma maneira. Tente não encurtá-lo muito, não expandi-lo muito.
Em segundo lugar, existem erros que são caros de corrigir . Os erros no nível da API são mais difíceis de corrigir do que os erros no nível do banco de dados, porque geralmente há muitos clientes usando a API. E quando você muda muito a API, você tem que:
- alcance todos os clientes, assegure a compatibilidade com versões anteriores;
- implantar a nova API, mudar todos os clientes para a nova API;
- elimine o código antigo sobre clientes, elimine o código antigo no backend.
Isso é muito caro.
Erros no código geralmente são absurdos em comparação com isso. Você acabou de reescrever o código e executar os testes. Os testes são verdes - você empurrou para o mestre. Preste atenção especial à API do banco de dados.
E não importa o quanto você tente manter o controle do banco de dados, com o tempo ele se tornará algo incontrolável. Na imagem, você pode ver um décimo de nosso banco de dados, que agora existe.
Há um conselho. Quando você desenvolve algo muito rapidamente, há imprecisões no banco de dados, às vezes falta uma chave estrangeira ou aparece um campo duplicado. Portanto, às vezes, uma vez a cada dois ou três meses, basta olhar apenas para a base. O mesmo Intellij IDEA pode gerar circuitos legais. E aí você pode ver tudo.
Seu banco de dados deve ser adequado. É muito fácil fazer uma lista de seis tickets em uma hora: adicione uma chave estrangeira aqui, ali um índice. Não importa o quanto você tente, alguns detritos inevitavelmente se acumularão.
A terceira história é sobre qualidade
Há coisas que são mais bem executadas bem desde o início. É importante agir de acordo com o princípio "faça normalmente, vai ficar tudo bem."
Por exemplo, temos um processo que é crítico para a plataforma. O dia todo estamos cobrando pedidos para amanhã, mas à noite uma nota é acionada que depois das 22:00 não estamos cobrando pedidos, mas antes da 01:00 estamos nos preparando para amanhã. Em seguida, começa a distribuição dos pedidos aos centros de triagem. Vamos para Yandex.Routing, ele constrói rotas.
E se esse trabalho preparatório falhar, todo o amanhã estará em questão. Amanhã os mensageiros não terão para onde ir. Eles não criaram um estado. Este é o processo mais crítico em nossa plataforma. E esses processos importantes não podem ser feitos em uma base residual, com recursos mínimos.
Lembro que tivemos um momento em que esse processo falhou, e por várias semanas quase metade da equipe do chat estava resolvendo esses problemas, todo mundo estava salvando o dia, retrabalhando algo, reiniciando.
Compreendemos que, se o processo não for concluído das dez da noite à uma da manhã, os centros de triagem nem saberão como classificar os pedidos em que pilhas. Tudo ficará ocioso lá. Os mensageiros sairão mais tarde e teremos falhas de qualidade.
É melhor executar esses processos da melhor maneira possível imediatamente, pensando em cada etapa em que algo pode dar errado. E coloque o máximo de canudo em todos os lugares.
Vou falar sobre uma das opções de como você pode configurar esse processo.
Este processo é multicomponente. O cálculo das rotas e sua publicação podem ser divididos em partes e, por exemplo, podem ser criadas filas. Então, temos várias filas que são responsáveis pelas seções de trabalho concluídas. E há consumidores nessas filas que ficam sentados à espera de mensagens.
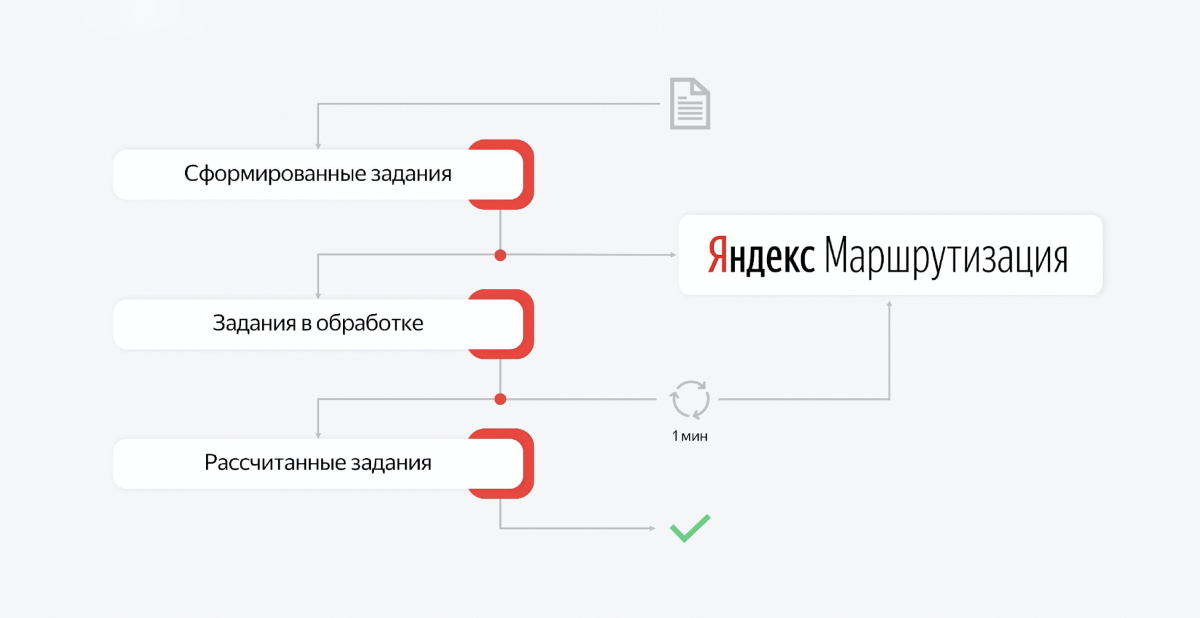
Por exemplo, o dia acabou, queremos calcular as rotas de amanhã. Em primeiro lugar, enviamos um pedido: criamos uma tarefa e iniciamos o cálculo. O consumidor capta a primeira mensagem e vai para o serviço de roteamento. Esta é uma API assíncrona. O consumidor recebe uma resposta de que a tarefa foi executada.
Ele coloca esse ID na base e coloca um novo trabalho na fila com tarefas em processamento. E isso é tudo. A mensagem desaparece da primeira fila, o segundo consumidor "acorda". Ele pega a segunda tarefa para processamento e sua tarefa é ir regularmente ao roteamento e verificar se essa tarefa ainda não foi concluída para o cálculo.
A tarefa do nível "criar rotas para 200 mensageiros que entregarão vários milhares de pedidos em Moscou" leva de meia hora a uma hora. Esta é uma tarefa muito difícil. E os caras desse serviço são muito legais, eles resolvem o problema algorítmico mais complexo que leva muito tempo.
Como resultado, o consumidor da segunda fila simplesmente verificará, verificará, verificará. Depois de algum tempo, a tarefa estará concluída. Quando a tarefa é concluída, recebemos uma resposta na forma de estrutura necessária para as rotas e turnos de amanhã para os mensageiros.
Colocamos o que foi calculado na terceira prioridade. A mensagem desaparece da segunda fila. E o terceiro consumidor "acorda", pega esse contexto do serviço Yandex.Routing e, com base nisso, cria o estado de amanhã. Ele cria pedidos para mensageiros, ele cria pedidos, cria turnos. Isso também dá muito trabalho. Ele passa algum tempo nisso. E quando tudo é criado, esta transação termina e o trabalho é removido da fila.
Se algo der errado em algum lugar neste processo, o servidor será reiniciado. Após a restauração subsequente, veremos simplesmente o ponto em que terminamos. Digamos que a primeira fase e a segunda tenham passado. E vamos passar para o terceiro.
Com essa arquitetura, nos últimos meses, tudo está indo bem, sem problemas. Mas antes houve uma tentativa sólida. Não está claro onde o processo falhou, quais status foram alterados no banco de dados e assim por diante.
Há coisas que você não deve economizar. Existem coisas com as quais você vai economizar um monte de células nervosas se fizer tudo bem feito na hora.
O que fizemos offline
Descrevi a maior parte do que está acontecendo em nossa plataforma. Mas algo permaneceu nos bastidores.
Aprendemos sobre softwares que ajudam os transportadores a entregar pedidos em um dia. Mas alguém deveria fazer esses montes para mensageiros. Em um centro de triagem, as pessoas precisam classificar uma grande máquina de pedidos em pequenas pilhas. Como isso é feito?
Esta é a segunda parte da plataforma. Nós escrevemos todo o software nós mesmos. Agora temos terminais com os quais os lojistas leem o código das caixas e os colocam nas células apropriadas. Existe uma lógica bastante complicada. Este back-end não é muito mais simples do que o que já falei.
Essa segunda peça do quebra-cabeça foi necessária para permitir, em conjunto com a primeira, estender o processo a outras cidades. Caso contrário, teríamos que procurar um contratante em cada nova cidade que pudesse providenciar a troca de alguns Excels pelo correio, ou integrar com nossa API. E isso demoraria muito.
Quando tivermos a primeira e a segunda peças do quebra-cabeça, podemos simplesmente alugar um prédio, contratar mensageiros em carros. Diga a eles como empurrar, o que empurrar, como escolher, qual caixa colocar onde, e é isso. Graças a isso, já lançamos em sete cidades, temos mais de dez centros de triagem.
E a abertura de nossa plataforma em uma nova cidade leva muito pouco tempo. Além disso, aprendemos não apenas a entregar pedidos a pessoas específicas. Sabemos entregar encomendas em pontos de recolha com a ajuda de transportadores. Também escrevemos software para eles. E nesses pontos também damos ordens às pessoas.
Resultados
No começo, eu disse porque começamos a criar nossa própria plataforma de correio. Agora vou contar o que conquistamos. É incrível, mas usando nossa plataforma conseguimos chegar perto de quase 100% acertando o intervalo. Por exemplo, na última semana, a qualidade da entrega em Moscou foi de cerca de 95–98%. Isso significa que em 95–98% dos casos não estamos atrasados. Encaixamo-nos no intervalo escolhido pelo cliente. E não poderíamos nem sonhar com tal precisão quando contávamos apenas com serviços de entrega externos. Portanto, agora estamos expandindo gradualmente nossa plataforma para todas as regiões. E vamos melhorar a capacidade de entrega.
Obtivemos uma transparência irreal. Também precisamos dessa transparência. Tudo é registrado conosco: todas as ações, todo o processo de emissão de um pedido. Temos a oportunidade de voltar na história por cinco meses e comparar algumas métricas com as atuais.
Mas também demos transparência aos clientes. Eles veem um mensageiro vindo até eles. Eles podem interagir com ele. Eles não precisam ligar para o serviço de suporte, dizer: "Onde está o meu correio?"
Além disso, acabou otimizando custos, pois temos acesso a todos os elementos da rede. Como resultado, agora custa um quarto a menos para entregar um pedido do que antes, quando trabalhávamos com serviços externos. Sim, o custo de entrega do pedido diminuiu 25%.
E se você resumir todas as idéias que foram discutidas, o seguinte pode ser distinguido.
Você deve entender claramente em que estágio de desenvolvimento está seu serviço atual, seu projeto atual. E se este é um negócio estabelecido, usado por milhões de pessoas, usado, talvez em vários países, você não pode fazer tudo no mesmo nível que com a Rover.
Mas se você tem um experimento ... O experimento é diferente porque a qualquer momento, se não mostrarmos os resultados prometidos, podemos ser encerrados. Não decolou. E tudo bem.
E ficamos nesse regime por cerca de dez meses. Tínhamos intervalos de relatórios, a cada dois meses tínhamos que mostrar o resultado. E nós fizemos isso.
Nesse modo, parece-me que você não tem o direito de fazer algo investindo no longo prazo e não obtendo nada no curto prazo. É impossível estabelecer uma base tão forte para o futuro neste formato de trabalho, porque o futuro simplesmente não pode vir.
E qualquer desenvolvedor competente, líder técnico, deve constantemente escolher entre trabalhar com muletas ou construir uma nave espacial imediatamente.
Resumindo, tente mantê-lo o mais simples possível, enquanto deixa espaço para expansão.
Existe um primeiro nível quando você precisa fazer isso de forma bastante simples. E tem o primeiro nível com um asterisco, quando você mantém a simplicidade, mas deixa pelo menos um pouco de espaço de manobra para que possa ser expandido. Com essa mentalidade, parece-me que os resultados serão muito melhores.
E a última coisa. Eu falei sobre o Rover que é bom fazer tais processos usando sinalizadores de recursos. Aconselho você a ouvir a palestra de Maria Kuznetsova do Java Meetup. Ela contou como os sinalizadores de recursos são organizados em nosso sistema e monitoramento.