
Olá, Habr!
Neste artigo, veremos algumas abordagens simples de previsão de série temporal.
O material apresentado no artigo, a meu ver, complementa bem a primeira semana do curso "Problemas Aplicados de Análise de Dados" do MIPT e Yandex. No curso indicado, é possível obter conhecimentos teóricos suficientes para resolver os problemas de previsão das séries de dinâmicas, e como uma consolidação prática do material, propõe-se utilizar o modelo ARIMA da biblioteca scipy para gerar uma previsão salarial no idioma russo Federação para o próximo ano. No artigo, também geraremos uma previsão salarial, mas ao mesmo tempo utilizaremos não a biblioteca scipy , mas sim a biblioteca sklearn . O truque é que o scipy já tem um modelo ARIMA , mas o sklearn não tem um modelo pronto, então temos que trabalhar muito com canetas. Assim, para resolver o problema, de certo modo, precisaremos descobrir como o modelo funciona por dentro. Além disso, como material adicional, no artigo, o problema de previsão é resolvido usando uma rede neural de camada única da biblioteca pytorch .
Todo o código é escrito em python 3 no notebook jupyter . Além disso, o notebook é projetado de forma que ao invés de dados sobre salários, você possa substituir muitas outras séries de dinâmicas, por exemplo, dados sobre preços de açúcar, alterar o período de previsão, validação e treinamento, adicionar outros fatores externos e formar um previsão apropriada. Em outras palavras, um simples simulador autoescrito é utilizado no trabalho, com o auxílio do qual é possível prever várias séries de dinâmicas. O código pode ser visto aqui
Esboço do artigo
- Breve descrição do simulador.
- Uma solução direta é prever séries temporais usando apenas dados "brutos" de valores anteriores das séries temporais.
- Adicionando variáveis exógenas.
- Correção de heterocedasticidade através do logaritmo dos dados iniciais.
- Trazendo a linha para uma estacionária.
- Previsão com uma rede neural de camada única.
- Comparação de abordagens.
- Links Úteis
Breve descrição do simulador
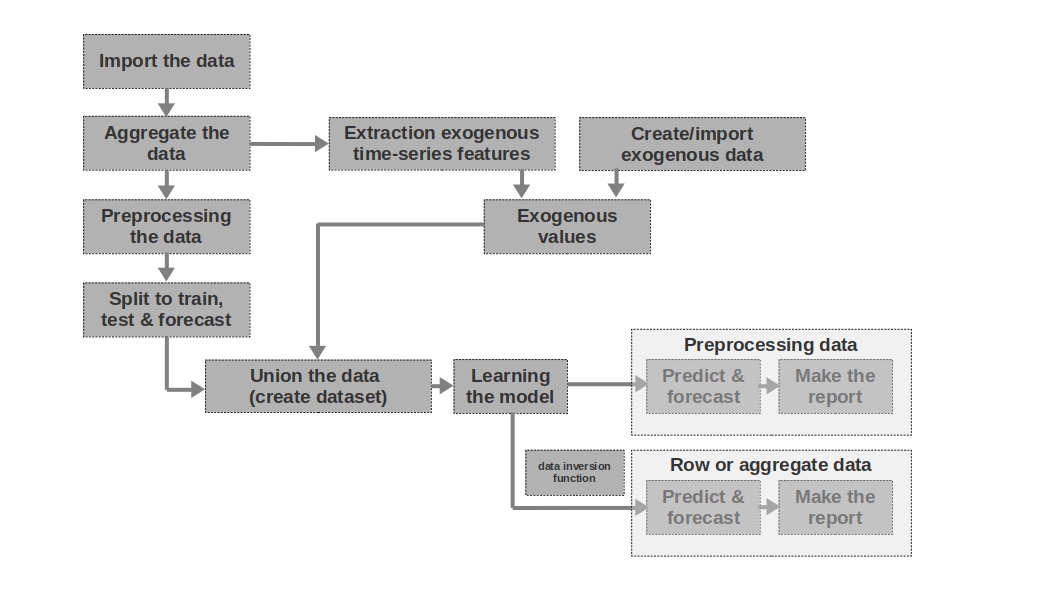
Importe os dados
Tudo é simples aqui - nós importamos os dados. Às vezes acontece que os dados brutos são suficientes para formar uma previsão mais ou menos inteligível. A primeira e a segunda previsões do artigo são modeladas com base em dados brutos, ou seja, os dados brutos sobre salários em períodos anteriores são usados para prever salários.
Agregue os dados
O artigo não usa agregação de dados porque não é necessário. No entanto, os dados muitas vezes podem ser apresentados em intervalos de tempo desiguais. Nesse caso, você só precisa agregá-los. Por exemplo, dados de negociação de títulos, moedas e outros instrumentos financeiros devem ser agregados. Normalmente, o valor médio no intervalo é obtido, mas o máximo, mínimo, desvio padrão e outras estatísticas também são possíveis.
Pré-processamento dos dados
No nosso caso, estamos falando principalmente de pré-processamento de dados, devido ao qual a série temporal adquire a propriedade de homocedasticidade (pelo logaritmo dos dados) e se torna estacionária (pela diferenciação das séries).
Divida para treinar, testar e prever
Neste bloco de código, a série temporal é dividida em períodos de treinamento, teste e previsão, adicionando-se uma nova coluna com os valores correspondentes "treinar", "testar", "prever". Ou seja, não criamos três tabelas separadas para cada período, mas simplesmente adicionamos uma coluna, com base na qual dividiremos ainda mais os dados.
Extração de recursos exógenos de séries temporais
Pode ser útil isolar recursos externos (exógenos) adicionais de uma série temporal. Por exemplo, indique se é um dia de folga ou não, indique o número de dias em um mês (ou o número de dias úteis em um mês), etc. Como regra, esses sinais são "retirados" da série temporal sem qualquer intervenção manual.
Criar / importar dados exógenos
Nem todas as informações podem ser “extraídas” da série temporal. Às vezes, dados externos adicionais podem ser necessários. Por exemplo, alguns eventos episódicos que têm um forte impacto nos valores da série temporal. Tais eventos podem ser as datas de início das hostilidades, a imposição de sanções, desastres naturais, etc. A obra não considera tais fatores, mas deve-se ter em mente a possibilidade de seu uso.
Valores exógenos
Neste bloco de código, combinamos todos os dados exógenos em uma tabela.
Unir os dados (criar conjunto de dados)
Neste bloco de código, combinamos os valores da série temporal e recursos exógenos em uma tabela. Ou seja, estamos preparando um conjunto de dados, com base no qual treinaremos o modelo, testaremos a qualidade e faremos uma previsão.
Aprendendo o modelo
Tudo está claro aqui - estamos apenas treinando o modelo.
Dados de pré-processamento: previsão e previsão
Se usamos dados pré-processados para treinar o modelo (logarítmico, processado pela função box-coque, série estacionária, etc.), então a qualidade do modelo é avaliada primeiro nos dados pré-processados e apenas em seguida, nos dados "brutos". Se não pré-processamos os dados, esta etapa é ignorada.
Dados de linha: previsão e previsão
Esta etapa é a última. Se o modelo foi treinado em dados pré-processados, por exemplo, nós os proclamamos, então para obter a previsão dos salários em rublos, e não o logaritmo dos rublos, devemos traduzir a previsão de volta para rublos.
Também gostaria de observar que o artigo usa uma série temporal unidimensional para prever salários. No entanto, nada impede que você use uma série multidimensional, por exemplo, somando dados sobre a taxa de câmbio do rublo para o dólar ou alguma outra série.
Decisão na testa
Assumiremos que os dados sobre salários no passado podem se aproximar dos salários no futuro. Em outras palavras, o tamanho dos salários, por exemplo, em janeiro depende de quais eram os salários em dezembro, novembro, outubro, ...
Vamos pegar os valores dos salários nos últimos 12 meses para prever os salários no 13º mês. Em outras palavras, para cada valor alvo, teremos 12 recursos.
Os sinais serão enviados para a entrada Ridge Regression da biblioteca sklearn. Tomamos os parâmetros padrão do modelo, exceto o parâmetro alfa, que foi definido como 0, ou seja, de fato, estamos usando regressão regular.
Esta é uma solução direta - é a mais simples :) Existem situações em que você precisa fornecer pelo menos algum resultado com muita urgência, mas simplesmente não há tempo para qualquer pré-processamento ou não há experiência suficiente para processar ou adicionar dados rapidamente. Em tais situações, você pode usar dados brutos como uma linha de base para construir uma previsão. Olhando para o futuro, observo que a qualidade do modelo acabou sendo comparável à qualidade dos modelos que usam pré-processamento de dados.
Vamos ver o que temos.
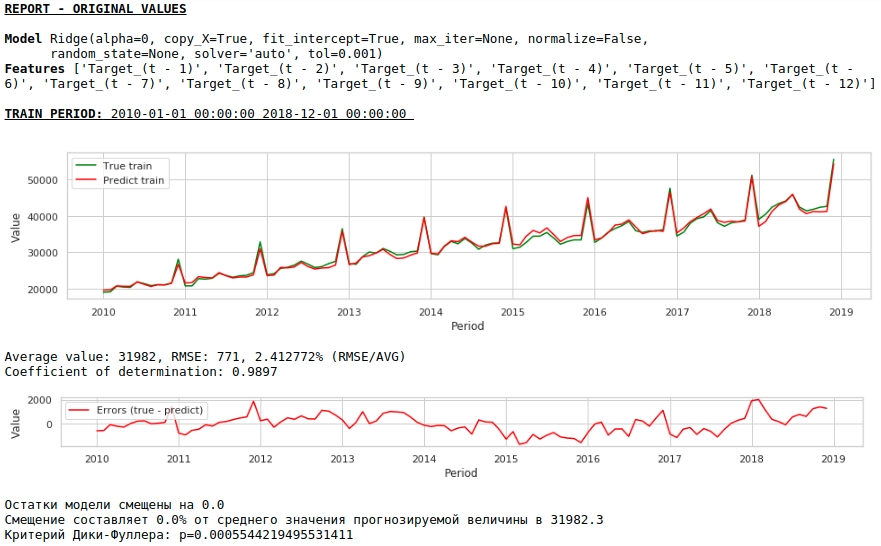
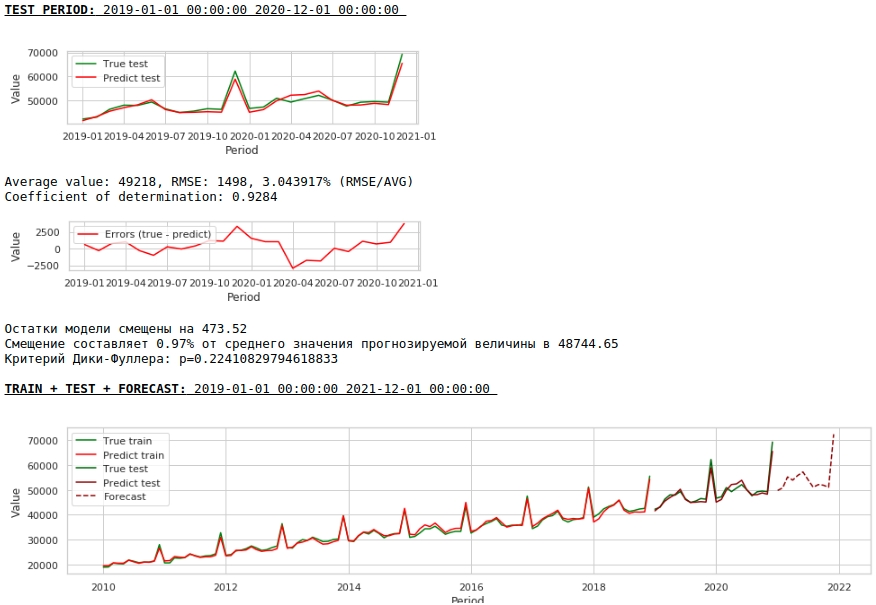
À primeira vista, o resultado parece, embora imperfeito, mas próximo da realidade.
De acordo com os valores dos coeficientes de regressão, o valor do salário é o que tem maior influência na previsão de salários há exatamente um ano.
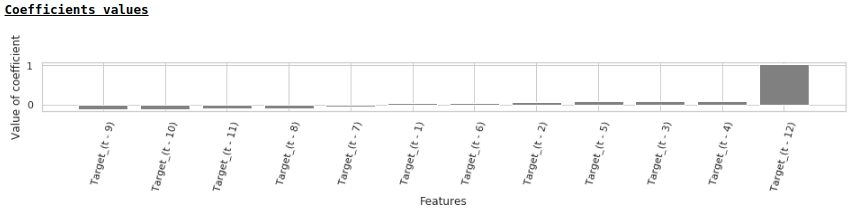
Vamos tentar adicionar variáveis exógenas ao modelo.
Adicionando variáveis exógenas
Usaremos 2 sinais externos: o número de dias em um mês e o número do mês (de 1 a 12). Binarizamos o atributo "Número do mês", como resultado obtemos 12 colunas para cada mês com valores 0 ou 1.
Vamos formar um novo conjunto de dados e olhar a qualidade do modelo.
Assistindo gráficos
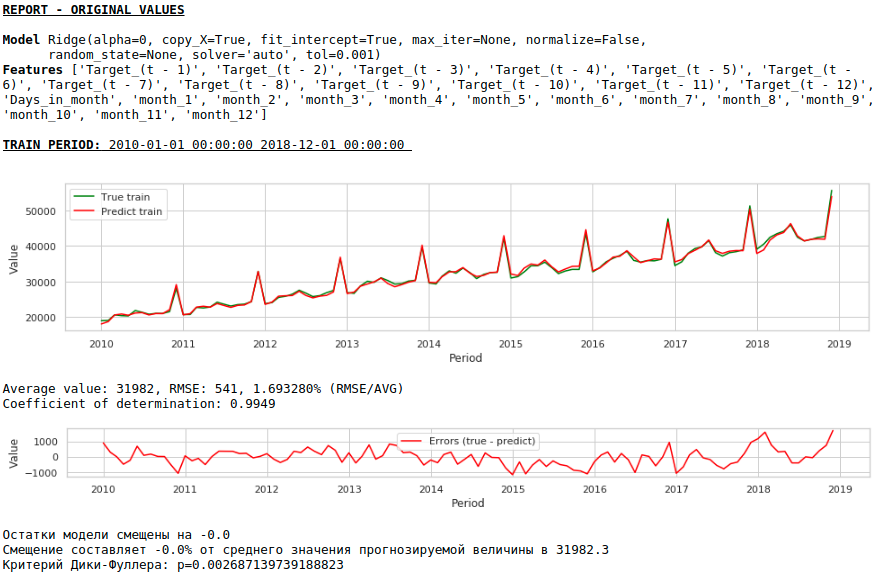
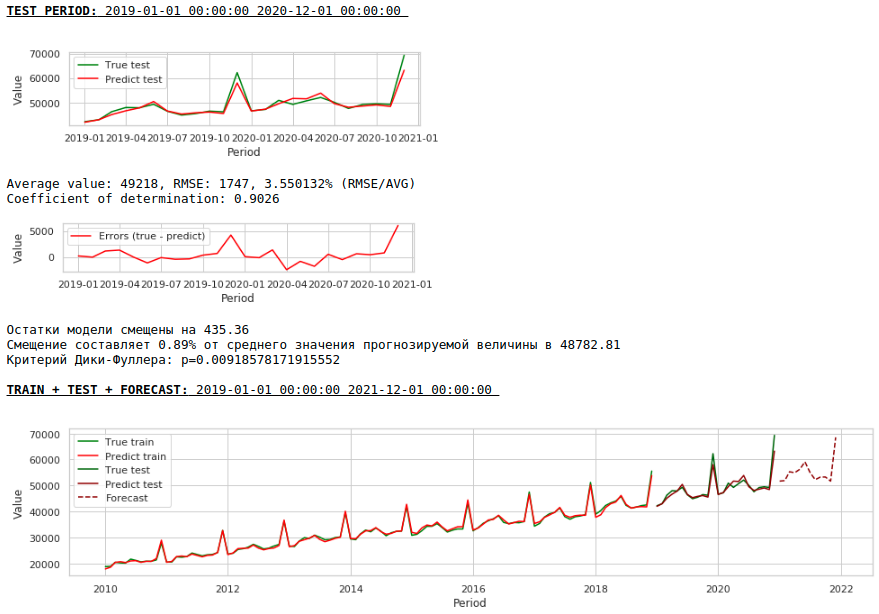
A qualidade é inferior. Visualmente, é perceptível que a previsão não parece totalmente plausível em termos de crescimento salarial em dezembro.
Vamos agora fazer o primeiro pré-processamento de dados.
Correção de heterocedasticidade.
Se olharmos o gráfico de salários para o período de 2010 a 2020, podemos ver que a distribuição dos salários dentro do ano entre os meses aumenta a cada ano.
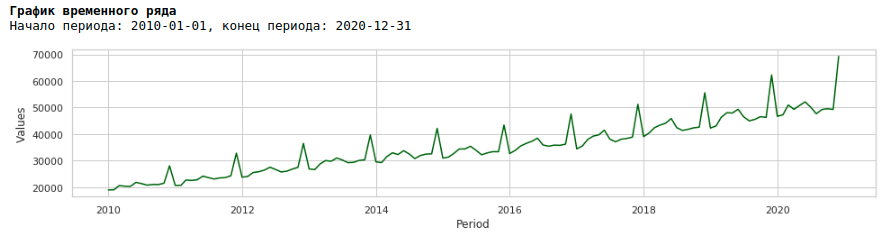
Um aumento anual na variância de mês a mês leva à heterocedasticidade. Para melhorar a qualidade da previsão, devemos nos livrar dessa propriedade dos dados e trazê-los à homocedasticidade.
Para fazer isso, usaremos o logaritmo usual e veremos como a série logarítmica se parece.
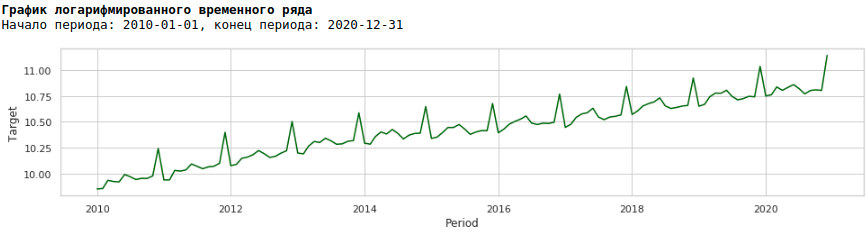
Vamos treinar o modelo na série logarítmica
Assistindo gráficos
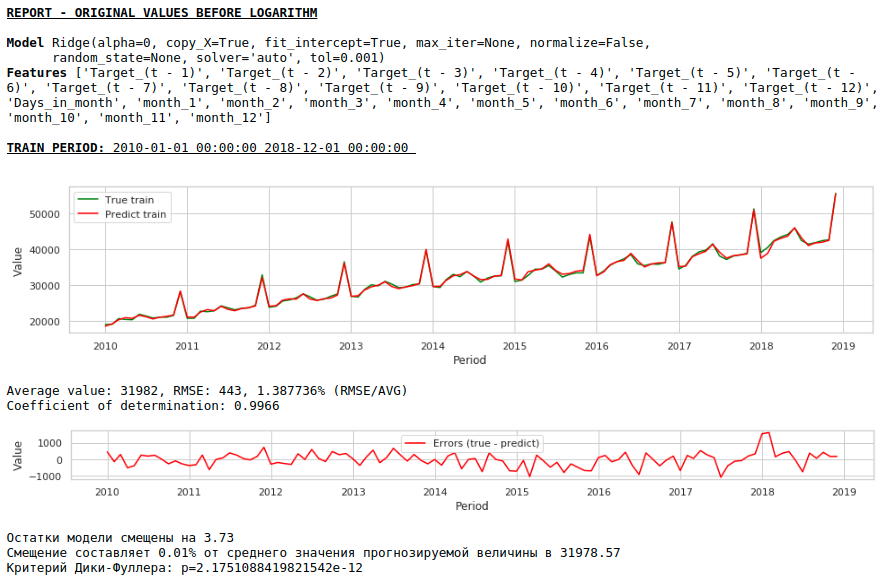
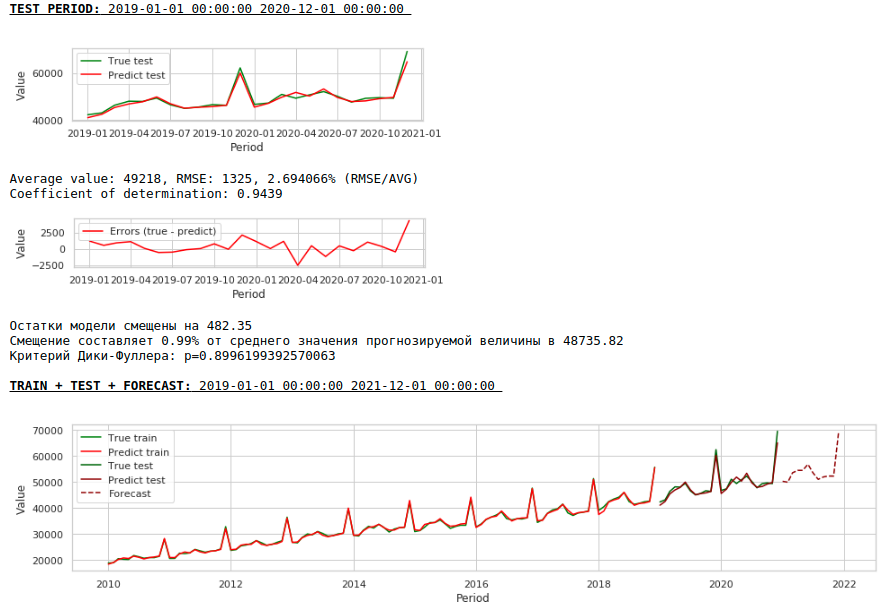
Como resultado, a qualidade das previsões nas amostras de treinamento e teste melhorou, no entanto, a previsão para 2021 parece visualmente menos plausível em comparação com a previsão do primeiro modelo. Muito provavelmente, o uso de fatores exógenos degrada o modelo.
Trazendo uma linha para um estacionário
Vamos reduzir a série a uma estacionária da seguinte maneira:
- Determine a diferença entre o valor do salário-alvo e o valor de um ano atrás: t - (t-12) = dif_1
- Determine a diferença entre o valor recebido e deslocado em 1 mês: dif_1 - (dif_1-1) = dif_2
Como resultado, obtemos a seguinte série temporal.
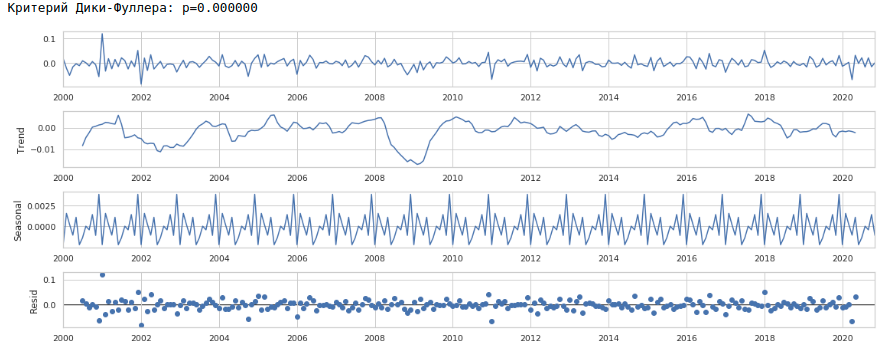
A série realmente parece estacionária, isso também é indicado pelo valor do critério Dickey-Fuller.
Não é necessário esperar uma boa qualidade de predições nas amostras de treinamento e teste nos dados processados, ou seja, em uma série estacionária, pois de fato, neste caso, o modelo deveria predizer os valores de ruído branco. Mas para nós, para prever salários, não é necessário usar a regressão, uma vez que, ao reduzir a série a uma estacionária, nós, em termos simples, determinamos uma fórmula de aproximação da variável-alvo. Mas não vamos nos desviar dos cânones e usar um modelo de regressão, além disso, temos fatores exógenos.
Vamos ver o que aconteceu.
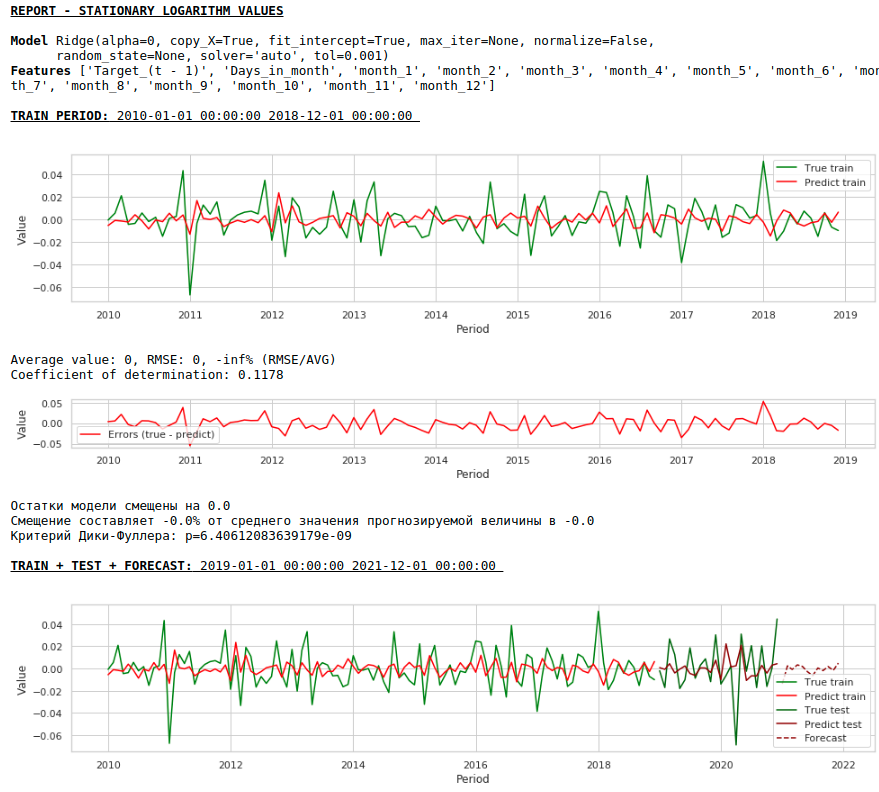
É assim que se parece a previsão de uma série estacionária. Como esperado - não muito bom :)
E aqui está a previsão e previsão de salários.
Assistindo gráficos
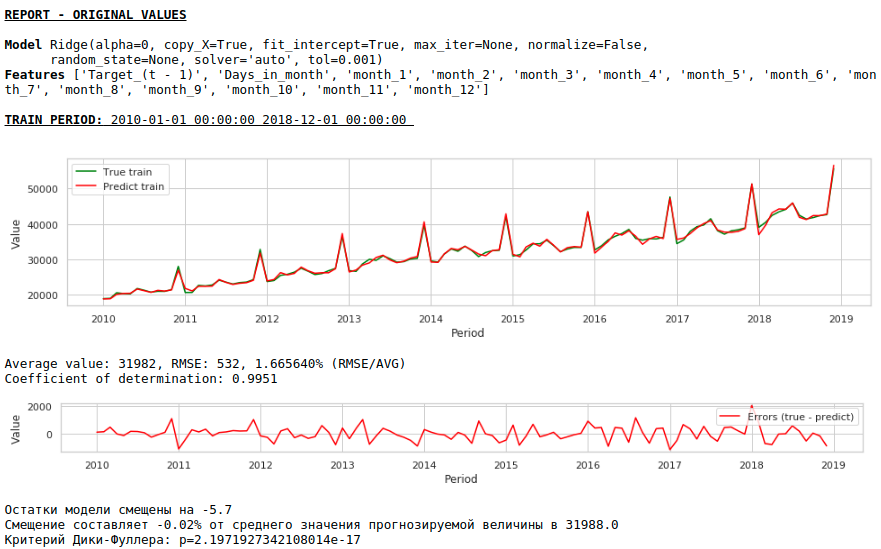
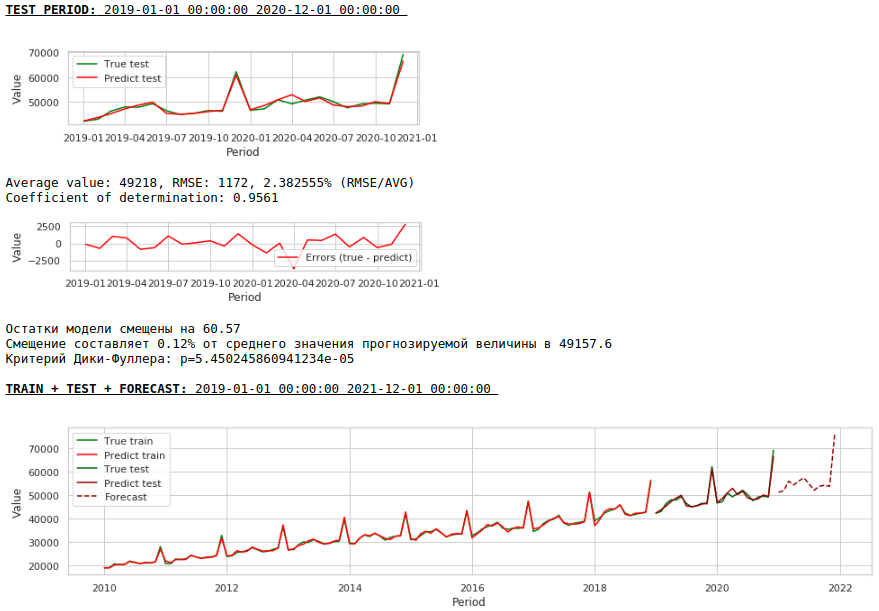
A qualidade melhorou significativamente e a previsão é visualmente verossímil.
Agora vamos fazer uma previsão sem usar variáveis exógenas.
Assistindo gráficos
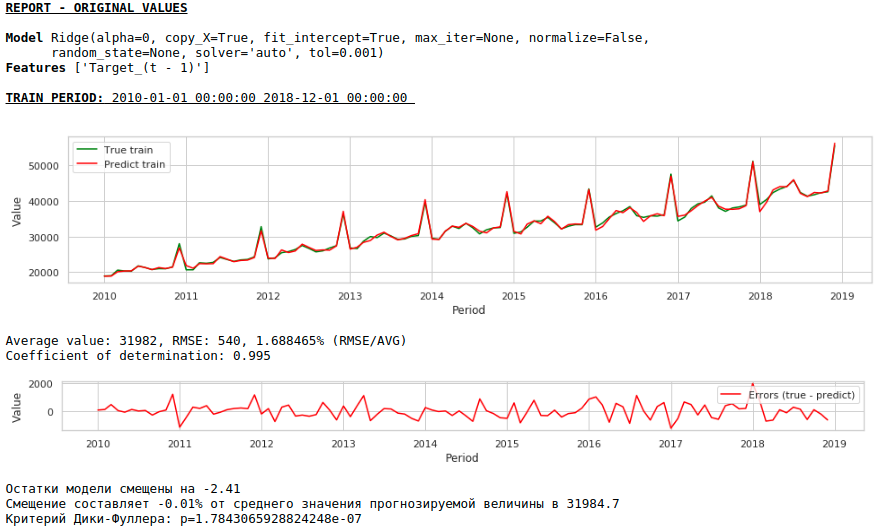
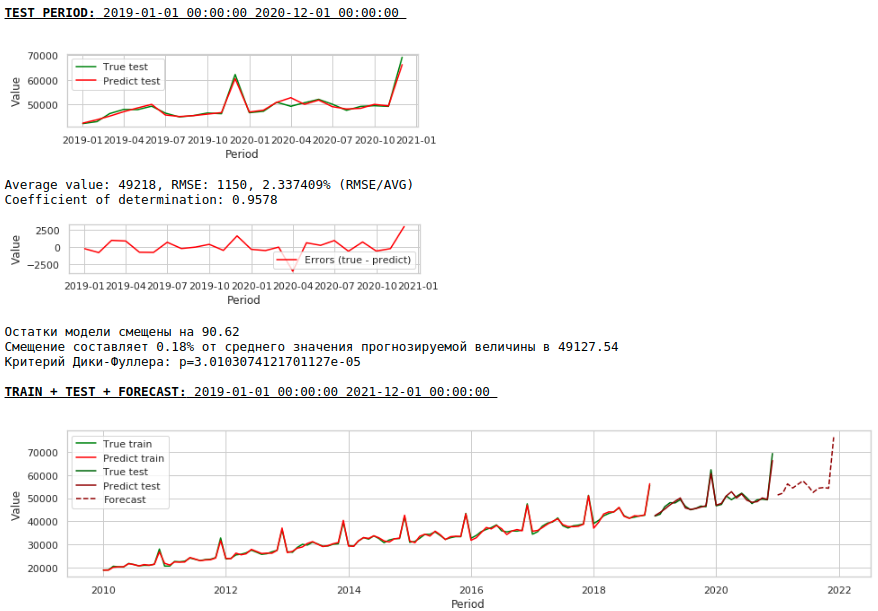
A qualidade melhorou ainda mais e a plausibilidade da previsão é preservada :)
Previsão com uma rede neural de camada única
Alimentaremos os conjuntos de dados existentes para a entrada da rede neural. Como nossa rede é de camada única, na verdade esta é a mesma regressão linear com modificações simples e você não deve esperar uma diferença muito grande na qualidade das previsões.
Primeiro, vamos dar uma olhada na própria rede.
Veja o código
class Model_1(nn.Module):
def __init__(self, input_size, output_size):
super(Model_1, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear = nn.Linear(self.input_size, self.output_size)
def forward(self, x):
output = self.linear(x)
return output
Agora, algumas palavras sobre como vamos treiná-la.
- Fixamos uma semente aleatória para fins de reprodutibilidade do resultado
- Inicializando o modelo
- Configurando a função de perda - MSELoss
- Selecionando o otimizador Adam como o otimizador
- Indicamos a etapa inicial do treinamento e determinamos a condição sob a qual o degrau é abaixado. Observe que a escolha correta de uma etapa e sua posterior alteração (geralmente uma diminuição) trazem bons resultados.
- Especifique o número de épocas de aprendizagem
- Começamos a treinar
- Fornecemos todo o conjunto de dados para a entrada da rede, uma vez que é muito pequeno e não faz sentido dividi-lo em lotes
- Durante o treinamento, a cada mil épocas, formamos gráficos do valor da função de perda nas amostras de treinamento e teste. Isso nos permite controlar o sobreajuste ou a não reciclagem do modelo.
Abaixo está o código para treinar a rede no primeiro conjunto de dados. Para cada conjunto de dados, os parâmetros mudaram ligeiramente: o número de épocas de treinamento e a etapa de treinamento.
Veja o código
# fix the random seed
SEED = 42
random_init(SEED)
# initialization model, loss function, optimizator
model = Model_1(len(features),1)
loss_func = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=5e-2)
# set the epoch numbers, initialization list for every loss after learning on epoch
epochs = 15000
losses_train = []
losses_test = []
# initialization counter for calculation epoch numbers
counter = 0
# start the learning model
for epoch in range(epochs):
model.train()
# make prediction targets on train data
y_pred_train = model(torch.tensor(X_train.to_numpy(), dtype=torch.float))
# calculate loss
loss = loss_func(y_pred_train,
torch.reshape(torch.tensor(y_train.to_numpy(), dtype=torch.float),(-1,1)))
# bacward loss to model and calculate new parameters (coefficients) with fixed learning rate
loss.backward()
opt.step()
opt.zero_grad()
# add loss to list losses
losses_train.append(loss)
model.eval()
y_pred_test = model(torch.tensor(X_test.to_numpy(), dtype=torch.float))
loss_test = loss_func(y_pred_test,
torch.reshape(torch.tensor(y_test.to_numpy(), dtype=torch.float),(-1,1)))
losses_test.append(loss_test)
# make the mini report for every 1000 epoch
if epoch % 1000 == 0 and epoch > 0:
print ('Epoch:', epoch // 1000)
print ('Learning rate:', opt.param_groups[0]['lr'])
print ('Last loss on TRAIN data:', losses_train[-1].cpu().detach().numpy(),
' Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
# print ('Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
fig, (ax1, ax2) = plt.subplots(1, 2)
# fig.suptitle('MSE on TRAIN & TEST DATA')
fig.set_figheight(3)
fig.set_figwidth(12)
ax1.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_train][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TRAIN data")
ax2.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_test][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TEST data")
plt.show()
counter += 1000
# reduce learning rate
if epoch == 1000:
opt = torch.optim.Adam(model.parameters(), lr=7e-3)
Não vamos considerar a qualidade das previsões para cada conjunto de dados separadamente (quem quiser pode ver os detalhes no gita). Vamos comparar os resultados finais.
Qualidade em uma amostra de teste usando Qualidade de regressão de cume
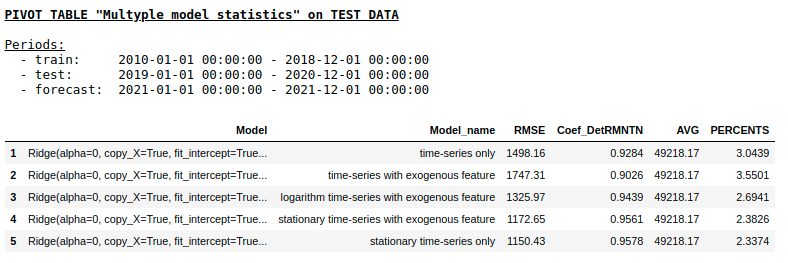
em uma amostra de teste usando NN de camada única
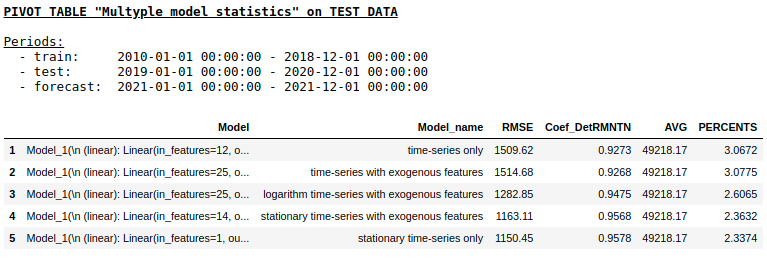
Como esperávamos, não havia diferença fundamental entre a regressão regular e uma rede neural de camada única simples. É claro que os neurônios fornecem mais manobra para o aprendizado: você pode alterar os otimizadores, ajustar as etapas de aprendizado, usar camadas ocultas e funções de ativação, pode ir ainda mais longe e usar redes neurais recorrentes - RNNs. A propósito, pessoalmente, não consegui obter a melhor qualidade neste problema usando RNN, no entanto, na Internet, você pode encontrar muitos exemplos interessantes de previsão de série temporal usando LSTM.
Nesse ponto, o artigo chegou ao fim. Espero que o material seja útil como uma espécie de visão geral das abordagens de linha de base usadas na previsão de séries temporais e sirva como um bom complemento prático para o curso "Problemas Aplicados de Análise de Dados" do MIPT e Yandex.
Links Úteis
- Fontes no github
- Curso "Problemas Aplicados de Análise de Dados" do MIPT e Yandex
- Estatísticas estaduais "EMISS" (dados sobre salários)
- LSTM para previsão de série temporal
- Aula 9. Previsão baseada em um modelo de regressão. Centro de Ciência da Computação
- A imagem abaixo do título foi tirada daqui :)