
Tenho certeza de que a maioria dos leitores está pelo menos um pouco familiarizada com os termos "Unicode" e "UTF-8". Mas todos sabem exatamente o que está por trás deles? Em essência, eles se referem aos padrões de codificação de caracteres, também conhecidos como conjuntos de caracteres. O conceito surgiu na época do telégrafo óptico, e não na era do computador, como se poderia pensar. Já no século 18, havia a necessidade de transmissão rápida de informações por longas distâncias, para as quais eram utilizados os chamados códigos telegráficos. As informações foram codificadas por meios óticos, eletrônicos e outros.
Nas centenas de anos que se passaram desde a invenção do primeiro código telegráfico, não houve nenhuma tentativa real de padronização internacional de tais esquemas de codificação. Mesmo as primeiras décadas da era do teletipo e do computador doméstico mudaram pouco. Embora EBCDIC (codificação de caracteres de 8 bits da IBM, mostrado em um cartão perfurado na ilustração do cabeçalho) e ASCII melhorassem um pouco as coisas, ainda não havia como codificar uma coleção crescente de caracteres sem uso significativo de memória.
O desenvolvimento do Unicode começou no final da década de 1980, quando o crescimento da troca de informações digitais em todo o mundo tornou mais urgente a necessidade de um único sistema de codificação. Atualmente, o Unicode nos permite usar um único esquema de codificação para tudo, desde texto básico em inglês até chinês tradicional, vietnamita e até maia, até os pictogramas que costumávamos chamar de emojis.
Do código aos gráficos
Nos tempos do Império Romano, era bem sabido que a transmissão rápida de informações era importante. Por muito tempo, isso significou a presença de mensageiros a cavalo que carregavam mensagens por longas distâncias, ou seu equivalente. Como melhorar o sistema de entrega de informações foi inventado no século 4 aC - é assim que um telégrafo aquático e um sistema de luzes de sinalização surgiram. Mas foi só no século 18 que a transmissão de dados de longa distância se tornou realmente eficaz.
Já escrevemos sobre o telégrafo óptico, também chamado de "semáforo", em um artigo sobre a história da comunicação óptica. Consistia em várias estações retransmissoras, cada uma equipada com um sistema de sinalização usado para exibir símbolos de código telegráfico. O sistema dos irmãos Chappe, que foi usado pelas tropas francesas entre 1795 e 1850, era baseado em uma barra de madeira com duas extremidades móveis (alavancas), cada uma das quais podendo se mover para uma das sete posições. Junto com as quatro posições da barra transversal, o semáforo em teoria poderia indicar 196 caracteres (4x7x7). Na prática, o número foi reduzido para 92-94 posições.
O sistema de semáforo foi usado não tanto para codificar caracteres diretamente, mas para denotar cadeias de caracteres específicas em um livro de código. O método implicava que era possível decifrar a mensagem inteira usando vários sinais de código. Isso tornou a transmissão mais rápida e tornou a interceptação de mensagens sem sentido.
Melhoria de desempenho
Em seguida, o telégrafo óptico foi substituído por um elétrico. Isso significava que os dias em que os códigos eram capturados pelas pessoas que assistiam à torre de retransmissão mais próxima haviam acabado. Com dois dispositivos telegráficos conectados por um fio metálico, a corrente elétrica se tornou o instrumento de transmissão de informações. Essa mudança levou a novos códigos de telégrafo elétrico, e o código Morse acabou se tornando um padrão internacional (com exceção dos Estados Unidos, que continuaram a usar o código Morse americano fora da radiotelegrafia) desde sua invenção na Alemanha em 1848.
O código Morse internacional tem uma vantagem sobre seu homólogo americano: usa mais traços do que pontos. Essa abordagem diminui a velocidade de transmissão, mas melhora a recepção de mensagens na outra extremidade da linha. Isso era necessário quando mensagens longas eram transmitidas por quilômetros de fios por operadores de diferentes níveis de habilidade.
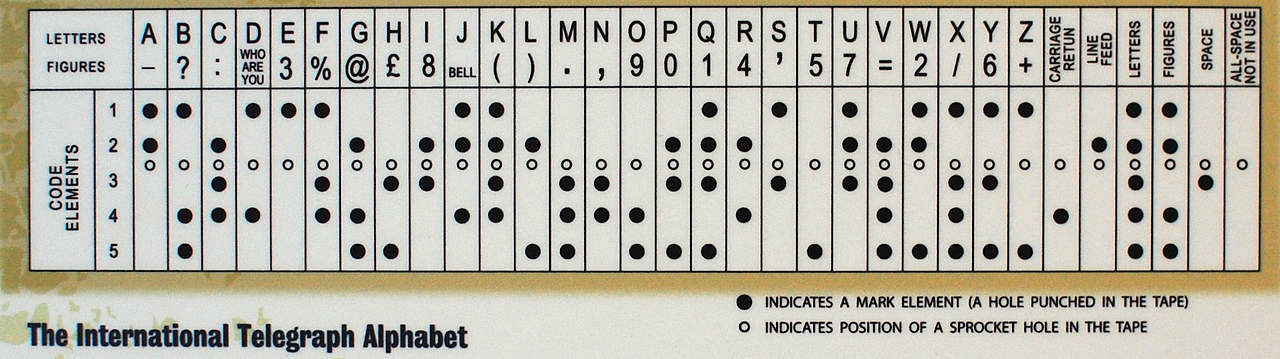
Com o desenvolvimento da tecnologia, o telégrafo manual foi substituído no Ocidente por um automático. Ele usava o código Baudot de 5 bits, bem como o código Murray derivado dele (o último era baseado no uso de fita de papel na qual os furos eram perfurados). O sistema de Murray tornou possível preparar uma fita de mensagens com antecedência e depois carregá-la em um leitor para que a mensagem fosse transmitida automaticamente. O código Baudot formou a base para o Alfabeto Telegráfico Internacional Versão 1 (ITA 1), e o código Baudot-Murray modificado formou a base para o ITA 2, que foi usado até 1960.
Na década de 1960, o limite de 5 bits por caractere não era mais necessário, levando ao desenvolvimento do ASCII de 7 bits nos Estados Unidos e de padrões como JIS X 0201 (para caracteres katakana japoneses) na Ásia. Em combinação com teletipoas, que eram amplamente utilizadas, isso permitia a transmissão de mensagens bastante complexas, incluindo letras maiúsculas e minúsculas.
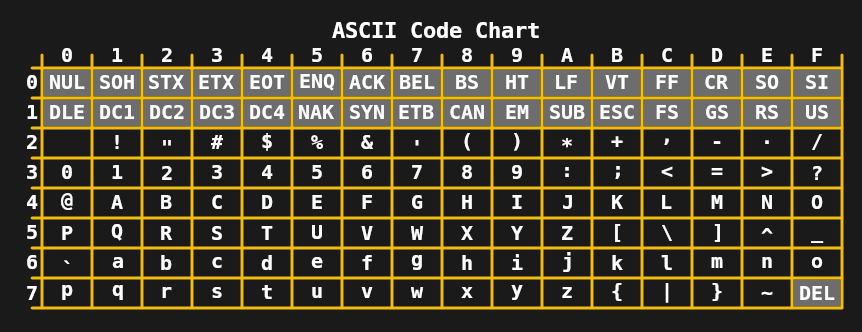
Durante os anos 1970 e início dos anos 1980, as limitações das codificações de 7 e 8 bits, como ASCII estendido (como ISO 8859-1 ou Latin 1), eram suficientes para os computadores domésticos convencionais e as necessidades de escritório. Apesar disso, a necessidade de melhorias era clara, já que tarefas comuns, como a troca de documentos e textos digitais, muitas vezes causavam estragos nas muitas codificações ISO 8859. O primeiro passo foi dado em 1991 com o Unicode 1.0 de 16 bits.
Desenvolvimento de codificações de 16 bits
Surpreendentemente, em apenas 16 bits, o Unicode conseguiu cobrir não apenas todos os sistemas de escrita ocidentais, mas também muitos caracteres chineses e muitos caracteres especiais usados, por exemplo, em matemática. Com 16 bits permitindo até 65.536 pontos de código, o Unicode 1.0 acomodou facilmente 7.129 caracteres. Mas quando o Unicode 3.1 apareceu em 2001, ele continha pelo menos 94.140 caracteres.
Agora, em sua 13ª versão, o Unicode contém um total de 143.859 caracteres, excluindo os caracteres de controle. Inicialmente, o Unicode destinava-se a ser usado apenas para codificar os sistemas de notação atualmente em uso. Mas, com o lançamento do Unicode 2.0 em 1996, ficou claro que esse objetivo precisava ser repensado para codificar até mesmo personagens raros e históricos. Para conseguir isso sem a codificação obrigatória de 32 bits de cada caractere, o Unicode mudou: ele permitiu não apenas codificar caracteres diretamente, mas também usar seus componentes, ou grafemas.
O conceito é um pouco semelhante às imagens vetoriais, em que cada pixel não é especificado, mas sim os elementos que compõem a imagem. Como resultado, a codificação Unicode Transformation Format 8 (UTF-8) suporta 2 31 ponto de código, com a maioria dos caracteres no conjunto de caracteres Unicode atual normalmente exigindo um ou dois bytes.
Unicode para todos os gostos e cores
Neste ponto, algumas pessoas provavelmente estão confusas com os vários termos que são usados quando se trata de Unicode. Portanto, é importante notar aqui que Unicode se refere ao padrão e os vários Unicode Transformation Format são implementações dele. UCS-2 e USC-4 são implementações de 2 e 4 bytes mais antigas de Unicode, com UCS-4 sendo idêntico ao UTF-32 e UCS-2 substituindo UTF-16.
UCS-2, como a forma mais antiga de Unicode, entrou em muitos sistemas operacionais na década de 1990, tornando a transição para UTF-16 a opção menos perigosa. É por isso que Windows e MacOS, gerenciadores de janela como o KDE e os tempos de execução Java e .NET usam UTF-16 internamente.
UTF-32, como o nome sugere, codifica cada caractere em quatro bytes. É um desperdício, mas totalmente previsível. O mesmo caractere UTF-8 pode codificar um caractere no intervalo de um a quatro bytes. No caso do UTF-32, determinar o número de caracteres em uma string é aritmética simples: pegue o número inteiro de bytes e divida por quatro. Isso levou a compiladores e algumas linguagens, como Python, que permitem que UTF-32 represente strings Unicode.
No entanto, de todos os formatos Unicode, UTF-8 é de longe o mais popular. Isso foi amplamente facilitado pela World Wide Web, onde a maioria dos sites veicula seus documentos HTML na codificação UTF-8. Por causa do layout dos diferentes planos de pontos de código em UTF-8, Western e muitos outros sistemas de escrita comuns cabem em dois bytes. Em comparação com as antigas codificações ISO 8859 e Shift JIS, na verdade o mesmo texto em UTF-8 não ocupa mais espaço do que antes.
De torres ópticas à Internet
Os dias dos mensageiros a cavalo, torres de retransmissão e pequenas estações telegráficas acabaram. A tecnologia de comunicação evoluiu muito. Mesmo os dias em que os teletipos eram comuns nos escritórios são difíceis de lembrar. No entanto, em todas as fases do desenvolvimento da história, a humanidade teve necessidade de codificar, armazenar e transmitir informações. E isso nos levou ao ponto em que agora podemos transmitir instantaneamente uma mensagem ao redor do mundo em um sistema de símbolos que podem ser decodificados, não importa onde você esteja.
Para aqueles que alternaram entre as codificações ISO 8859 em clientes de e-mail e navegadores da web para obter algo que se parecia com a mensagem de texto original, o suporte a Unicode foi uma bênção. Eu posso entender essas pessoas. Quando o ASCII de 7 bits (ou EBCDIC) era a tecnologia incontestável, às vezes era necessário passar horas resolvendo a confusão simbólica de um documento digital recebido de um escritório europeu ou americano.
Mesmo que o Unicode tenha seus problemas, é difícil não se sentir grato comparando-o com o que costumava ser. Aqui estão eles, 30 anos de Unicode.
