
Muitas vezes, o uso de ferramentas prontas para o desenvolvimento torna-se uma solução abaixo do ideal. Foi o que aconteceu conosco. Para gerenciar pipelines de dados, decidimos desenvolver nosso próprio sistema - Wombat. Contaremos a você o que aconteceu e o que nos deu a recusa em usar a solução pronta.
Por que estamos desenvolvendo nosso próprio sistema
Criar seu próprio sistema de gerenciamento de pipeline de dados não é uma escolha óbvia. Hoje existem muitas soluções prontas que podem resolver o problema: Airflow, MLflow, Kubeflow, Luigi e um monte de outros. Experimentamos muitos desses sistemas e chegamos à conclusão de que nenhum deles é adequado para nós.
Por exemplo, considere a solução mais comum - Airflow. Ele combina seis blocos principais: uma API para descrever pipelines, um coletor de wokflow, um painel de controle e interfaces, um agendador de tarefas e um orquestrador de tarefas e, finalmente, monitorar os componentes do Airflow. Mas, para gerenciar pipelines, essa funcionalidade não foi suficiente em nosso caso.
Para nós, recursos como integração do sistema de gerenciamento de pipeline com o sistema de compilação e CI, integração com Kubernetes, capacidade de gerenciar artefatos e validação de dados eram essenciais.

Descobrimos quanto nos custaria construir a funcionalidade do sistema acabado para o nível necessário e percebemos que seria muito mais fácil e rápido desenvolver nosso próprio sistema. Chamamos de Wombat - porque o animal é muito fofo e, em segundo lugar, porque é considerado o salvador da natureza australiana. E para nós, um sistema que nos permitisse combinar o desenvolvimento e todas as etapas do trabalho com dados também seria uma verdadeira salvação.
Que problemas resolvemos
Historicamente, em nossa equipe de desenvolvimento, os engenheiros de DevOps oferecem suporte aos serviços de produção. E eles estão acostumados a trabalhar com pipelines, que são descritos não por código, mas por configurações em formatos como yaml. Por causa dessa discrepância, você precisa compartilhar o suporte ou treinar engenheiros para trabalhar com um sistema de integração contínua não clássico.
Tudo isso seria um trabalho redundante e desnecessário, porque os pipelines na forma de gráficos acíclicos direcionados são perfeitamente descritos no formato que é usado nas ferramentas padrão de CI e DevOps.

O segundo problema que enfrentamos foi o armazenamento e o controle de versão dos artefatos. Trabalhar com artefatos no sistema de gerenciamento de pipeline de dados permite obter duas oportunidades muito úteis: reutilizar os resultados do trabalho com pipelines e reproduzir experimentos com dados, economizando tempo para organizar novos experimentos.
Se a organização de armazenamento de artefatos não for automatizada, mais cedo ou mais tarde novos artefatos começarão a sobrescrever os antigos ou o espaço livre começará a se esgotar nas máquinas de produção. Além disso, a produção precisará aplicar requisitos específicos para garantir a confiabilidade e tolerância a falhas do armazenamento, que é outro processo caro.
Portanto, queríamos obter uma solução que executasse todas as tarefas relacionadas ao gerenciamento de pipelines em segundo plano, permitindo que especialistas em dados trabalhassem com artefatos de outros projetos e, ao mesmo tempo, não pensassem no custo de armazenamento de dados.
O terceiro problema é a digitação dos fluxos de dados. Sim, Python permite que você desenvolva protótipos e teste várias hipóteses em alta velocidade. Mas, ao trabalhar com dados, você deve prestar atenção aos tipos com os quais está trabalhando, se não quiser surpresas inesperadas. Para reduzir o número de tais problemas na produção, precisamos de suporte para a descrição de esquemas de dados, até a descrição de esquemas de quadro de dados, e a digitação de dados deve ser feita separadamente para desenvolvimento e produção.
O que aconteceu no final
Convencionalmente, a arquitetura Wombat pode ser representada assim:

Este diagrama mostra a função do sistema. É uma camada intermediária entre a descrição dos pipelines e o sistema de CI, com a ajuda do qual você pode trabalhar com eles na produção.
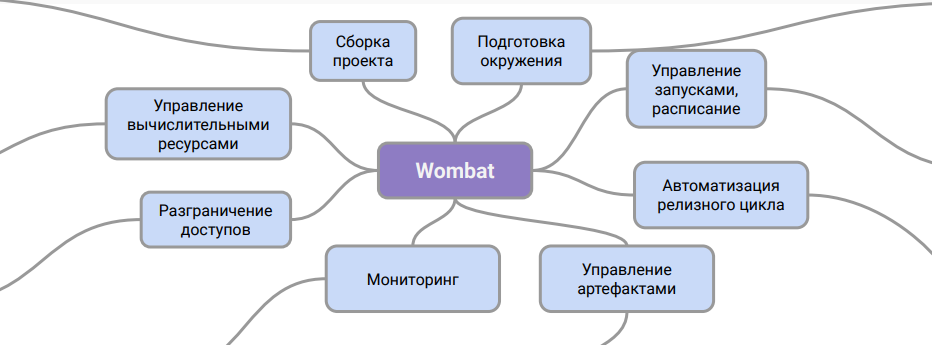
Graças a esse esquema de trabalho, podemos organizar suporte para pipelines no departamento de DevOps sem treinamento adicional para engenheiros e sem envolver especialistas em dados neste processo. Além disso, o problema com o armazenamento de artefatos de dados e seu controle de versão foi resolvido.
Agora estamos desenvolvendo funcionalidades que permitirão introduzir a ferramenta na fase inicial de prototipagem e experimentação em uma forma nativa para cientistas de dados, o que irá acelerar significativamente o lançamento de projetos em piloto e produção.
Estamos nos preparando para lançar essa ferramenta em código aberto em um futuro muito próximo. Ficaremos felizes se você compartilhar sua opinião sobre nosso projeto e sua experiência de trabalho com modernos sistemas de pipeline de dados.
Além disso, percebendo que este artigo é mais informativo do que técnico por natureza, em um futuro próximo planejamos preparar um texto mais detalhado e pesado. Escreva nos comentários o que você gostaria de ver e descobrir em termos técnicos. Vamos levar em consideração, descrever e escrever. Obrigado pela atenção!
PS: Ainda estamos interessados em programadores talentosos. Venha, vai ser interessante !