Geralmente não é costume falar sobre esses erros, porque apenas pessoas celestiais e sem pecado trabalham em todos os integradores. Como você sabe, no nível do DNA, não há possibilidade de estar errado ou errado.
Mas vou arriscar. Espero que minha experiência seja útil para alguém. Temos um grande cliente, varejo online, para o qual oferecemos suporte total à fábrica Cisco ACI. A empresa não possui administrador próprio competente para este sistema. Uma malha de rede é um grupo de switches que possui um único centro de controle. Além disso, há um monte de recursos úteis dos quais o fabricante se orgulha, mas no final, para descartar tudo, você precisa de um administrador, não dezenas. E um centro de controle, não dezenas de consoles.
A história começa assim: o cliente deseja transferir o núcleo de toda a rede para esse grupo de switches. Esta decisão se deve ao fato de que a arquitetura ACI, na qual este grupo de switches é "coletado", é muito tolerante a falhas. Embora isso não seja típico e em geral, uma fábrica em qualquer data center não é usada como rede de trânsito para outras redes e serve apenas para conectar a carga final (rede stub). Mas essa abordagem é perfeitamente possível, então o cliente deseja - nós fazemos isso.
Aí aconteceu uma coisa banal - confundi dois botões: deletar a política e deletar a configuração de um fragmento da rede:
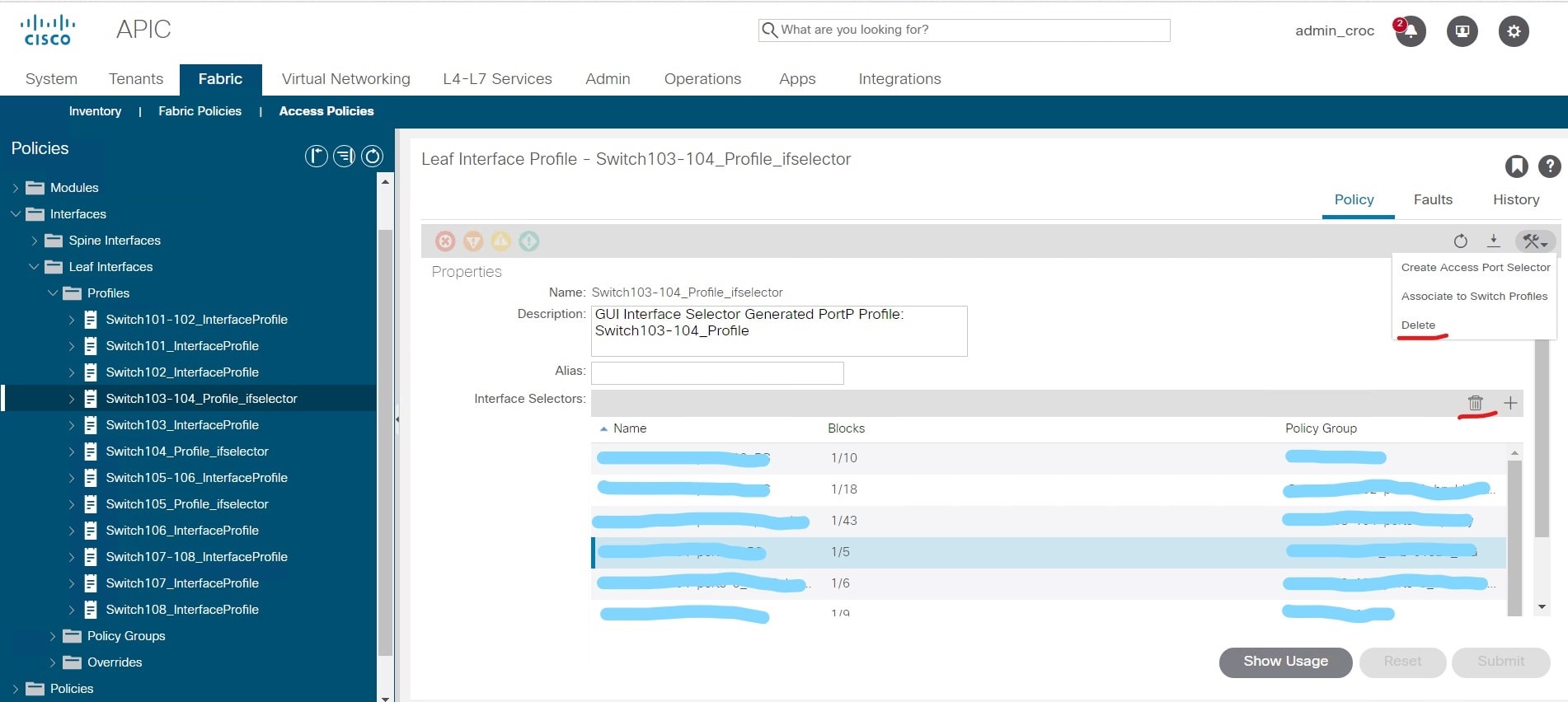
Bom, então, de acordo com os clássicos, era preciso remontar parte da rede colapsada.
Em ordem
O pedido do cliente soava assim: era necessário construir grupos de portas separados para a transferência do equipamento diretamente para esta fábrica.
Colegas, por favor, transfira as configurações das portas Leaf 1-1 101 e leaf 1-2 102, portas 43 e 44, para Leaf 1-3 103 e leaf 1-4 104, portas 43 e 44. Para as portas 43 e 44 na Leaf 1- 1 e 1-2, a pilha 3650 está conectada, ela ainda não foi colocada em operação, você pode transferir as configurações da porta a qualquer momento.
Ou seja, eles queriam transferir o cluster de servidor. Foi necessário configurar um novo grupo de portas virtuais para o ambiente do servidor. Na verdade, esta é uma tarefa de rotina; geralmente não há tempo de inatividade do serviço para tal tarefa. Em essência, um grupo de portas na terminologia APIC é um VPC montado a partir de portas que estão fisicamente localizadas em switches diferentes.
O problema é que, na fábrica, as configurações desses grupos de portas estão vinculadas a uma entidade separada (que surge devido ao fato de a fábrica ser controlada pelo controlador). Este objeto é denominado política de portas. Ou seja, ao grupo de portas que adicionamos, também precisamos aplicar uma política geral de cima como uma entidade que irá gerenciar essas portas.
Ou seja, foi necessário analisar quais EPGs são usados nas portas 43 e 44 nos nós 101 e 102 para montar uma configuração semelhante nos nós 103-104. Depois de analisar as mudanças necessárias, comecei a configurar os nós 103-104. Para configurar um novo VPC na política de interface existente para os nós 103 e 104, foi necessário criar uma política na qual as interfaces 43 e 44 seriam trazidas.
E há uma nuance na GUI. Criei esta política e percebi que durante o processo de configuração cometi um pequeno erro - nomeei-o de forma diferente do costume do cliente. Isso não é crítico - porque a política é nova e não afeta nada. E eu tive que deletar esta política, já que mudanças não podem mais ser feitas nela (o nome não muda) - você só pode deletar e recriar a política.
O problema é que a GUI tem ícones de exclusão que se referem às políticas de interface e há ícones que se referem às políticas de switch. Visualmente, eles são quase idênticos. E, em vez de excluir a política que criei, excluí todas as configurações das interfaces nos switches 103-104: em
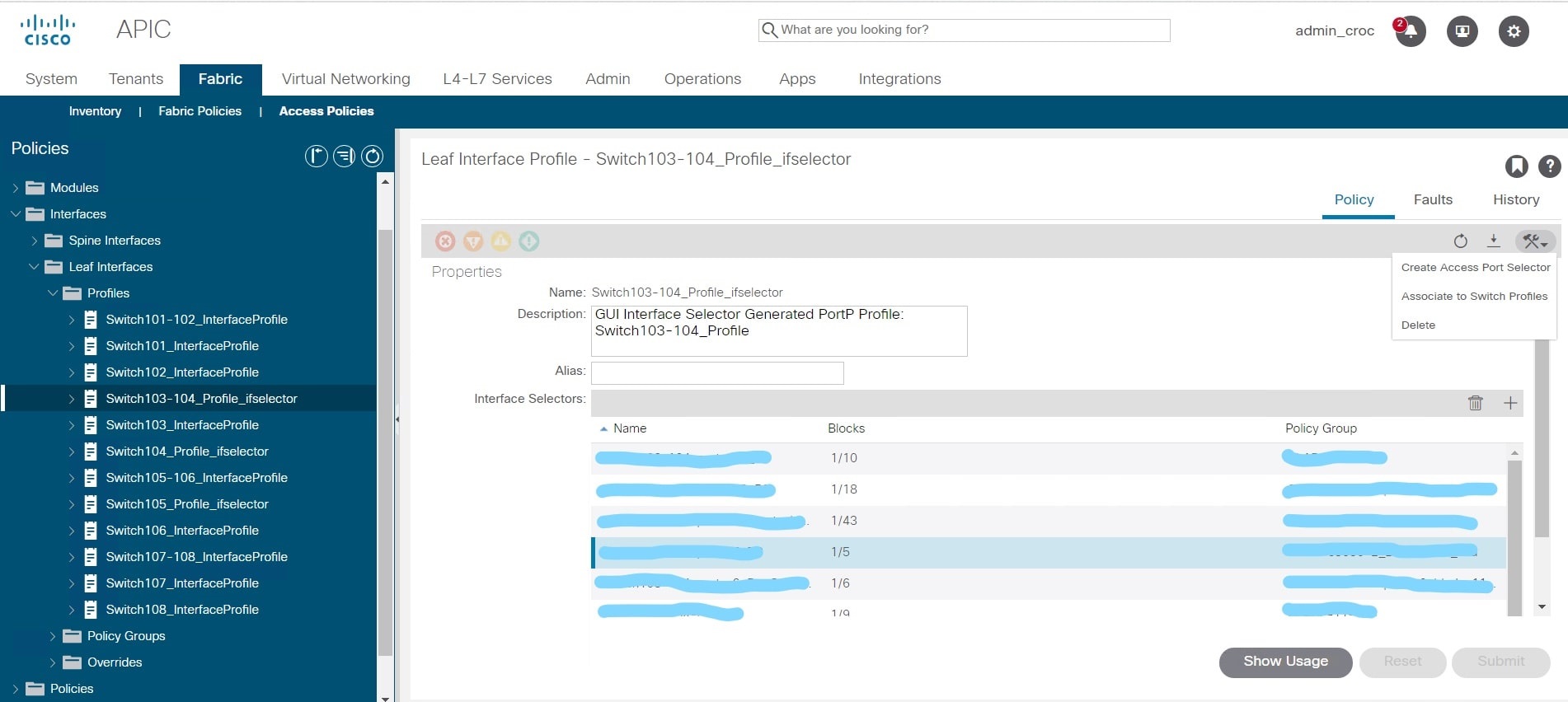
vez de excluir um grupo, na verdade excluí todos os VPCs das configurações de nó, usei delete em vez de trashbin.
Esses links tinham VLANs sensíveis aos negócios. Na verdade, depois de excluir a configuração, desativei parte da grade. Além disso, isso não foi imediatamente perceptível, porque a fábrica não é controlada pelo kernel, mas tem uma interface de gerenciamento separada. Não fui expulso na hora, não houve erro na fábrica porque a ação foi tomada pelo administrador. E a interface pensa - bem, se você disse para excluir, então deveria ser assim. Não houve indicação de erros. O software decidiu que algum tipo de reconfiguração estava em andamento. Se o admin deletar o perfil folha, então para a fábrica ele deixa de existir e não escreve um erro informando que não funciona. Não funciona - porque foi deliberadamente removido. Não deve funcionar para software.
Então o software decidiu que eu era Chuck Norris e sabia exatamente o que estava fazendo. Tudo está sob controle. O administrador não pode estar errado, e mesmo quando ele dá um tiro no próprio pé, isso faz parte de um plano astuto.
Porém, depois de cerca de dez minutos, fui expulso da VPN, que inicialmente não associei à configuração do APIC. Mas isso é pelo menos suspeito, e entrei em contato com o cliente para esclarecer o que estava acontecendo. E nos minutos seguintes, pensei que o problema fosse trabalho técnico, uma escavadeira repentina ou uma queda de energia, mas não a configuração de fábrica.
A rede do cliente é complexa. Vemos apenas parte do ambiente pelo nosso acesso. Ao restaurar eventos, tudo parece que o reequilíbrio do tráfego começou, após o que, após alguns segundos, o roteamento dinâmico dos sistemas restantes simplesmente não funcionou.
A VPN que eu estava usando era a VPN do administrador. Funcionários comuns sentavam-se uns aos outros, tudo continuava a funcionar para eles.
Em geral, demorou mais alguns minutos de negociações para entender que o problema ainda está na minha configuração. A primeira ação em uma batalha em tal situação é reverter para as configurações anteriores e só então ler os logs, porque isso é prod.
Restauração de fábrica
Demorou 30 minutos para restaurar a fábrica - incluindo todas as ligações e coleta de todos os envolvidos.
Encontramos outra VPN pela qual você pode passar (isso exigia um acordo com os guardas de segurança) e reverti a configuração de fábrica - na Cisco ACI, isso é feito em dois cliques. Não há nada complicado. O ponto de restauração é simplesmente selecionado. Demora 10-15 segundos. Ou seja, a recuperação em si demorou 15 segundos. O resto do tempo foi gasto tentando descobrir como obter o controle remoto.
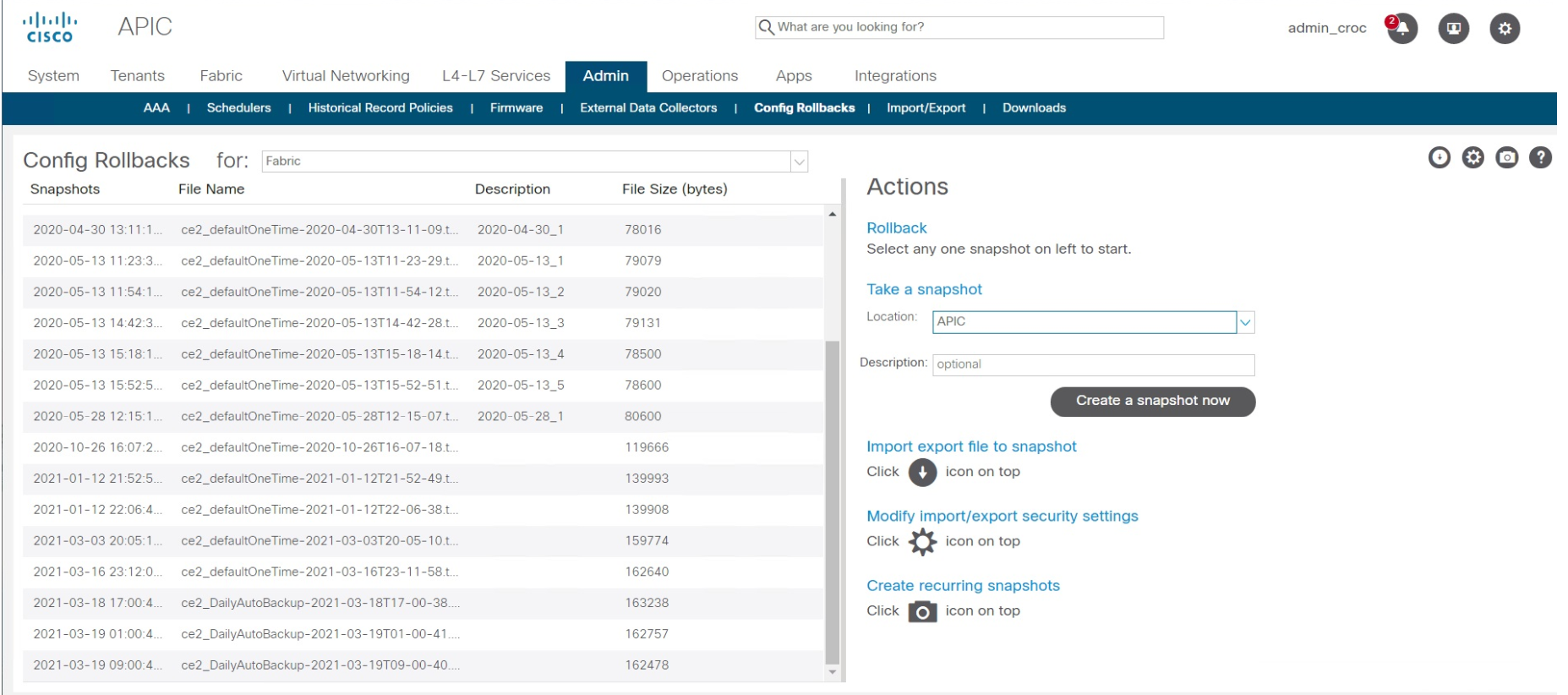
Depois do incidente
Outro dia analisamos os registros e restauramos a cadeia de eventos. Em seguida, eles agendaram uma ligação com o cliente, expuseram com calma a essência e as causas do incidente, propuseram uma série de medidas para minimizar os riscos de tais situações e do fator humano.
Combinamos que só tocamos nas configs da fábrica fora do horário de trabalho: à noite e à noite. Realizamos trabalhos com uma conexão remota duplicada (existem canais VPN em funcionamento, existem canais de backup). O cliente recebe um aviso nosso e neste momento monitora os serviços.
O engenheiro (ou seja, eu) permaneceu o mesmo no projeto. Posso dizer que o sentimento de confiança em mim se tornou ainda maior do que antes do incidente - creio eu, precisamente porque trabalhamos rapidamente na situação e não permitimos que uma onda de pânico envolvesse o cliente. O principal é que eles não tentaram esconder a junta. Pela prática, sei que nesta situação é mais fácil tentar mudar para o fornecedor.
Aplicamos políticas de rede semelhantes a outros clientes terceirizados: é mais difícil para os clientes (canais VPN adicionais, mudanças adicionais de administrador fora do horário comercial), mas muitos entenderam por que isso era necessário.
Também nos aprofundamos no software Cisco Network Assurance Engine (NAE), onde encontramos a oportunidade de fazer duas coisas simples, mas muito importantes na fábrica da ACI:
- primeiro, o NAE nos permite analisar a mudança planejada, mesmo antes de implementá-la na fábrica e filmar tudo para nós mesmos, prevendo como a mudança afetará positiva ou negativamente a configuração existente;
- em segundo lugar, o NAE, após a mudança, permite medir a temperatura geral da fábrica e ver como essa mudança acabou afetando o estado de saúde.
Se você estiver interessado em mais detalhes - amanhã teremos um webinar sobre a cozinha interna de suporte técnico, contaremos como tudo funciona conosco e com os fornecedores. Também analisaremos os erros)