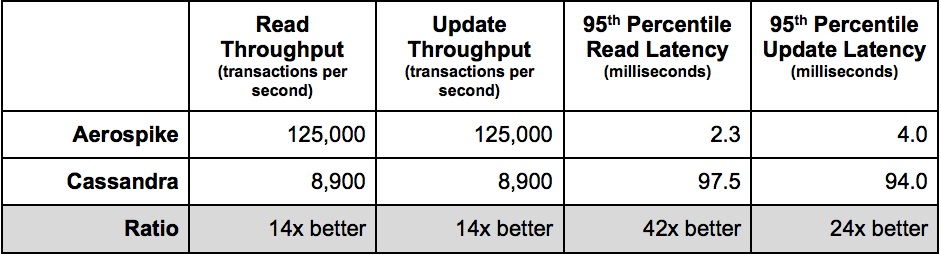
Por uma incrível coincidência, Scylla (doravante SC) também vence CS facilmente, que orgulhosamente anuncia direto em sua página inicial:

Assim, surge naturalmente a questão: quem cercará quem, a baleia ou o elefante?
No meu teste, a versão otimizada do HBase (doravante referido como HB) trabalha com CS em pé de igualdade, então aqui não será um candidato à vitória, mas apenas na medida em que todo o nosso processamento é baseado em HB e eu quero compreender suas capacidades em comparação com os líderes.
É claro que HB e CS são gratuitos, mas por outro lado, se você precisa de X vezes mais hardware para obter o mesmo desempenho, é mais lucrativo pagar pelo software do que alocar um andar no data center por um custo caro almofadas de aquecimento. Especialmente considerando que se estamos falando de desempenho, então, uma vez que os HDDs, em princípio, não são capazes de dar pelo menos alguma velocidade aceitável de leituras de acesso aleatório (consulte " Por que HDD e leituras de acesso aleatório rápidas são incompatíveis "), o que por sua vez significa comprar SSD, que nos volumes necessários para um BigData real, é um prazer bastante caro.
Então, o seguinte foi feito. Aluguei 4 servidores na nuvem AWS na configuração i3en.6xlarge onde cada um a bordo:
CPU - 24 vcpu
MEM - 192 GB
SSD - 2 x 7500 GB
Se alguém quiser repeti-lo, notamos imediatamente que é muito importante para a reprodutibilidade tomar configurações onde o volume total dos discos (7500 GB). Caso contrário, os discos terão que ser compartilhados com vizinhos imprevisíveis, o que certamente irá arruinar seus testes, pois eles provavelmente parecem ser uma carga muito valiosa.
Em seguida, implementei o SC usando o construtor , que foi gentilmente fornecido pelo fabricante em seu próprio site. Em seguida, carreguei o utilitário YCSB (que é quase um padrão para teste comparativo de banco de dados) para cada nó do cluster.
Existe apenas uma nuance importante, em quase todos os casos usamos o seguinte padrão: ler o registro antes de alterar + escrever o novo valor.
Então, eu modifiquei a atualização da seguinte maneira:
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Então eu iniciei o carregamento simultaneamente de todos os 4 hosts (os mesmos onde os servidores de banco de dados estão localizados). Isso é feito deliberadamente, porque às vezes os clientes de alguns bancos de dados consomem mais CPU do que outros. Considerando que o tamanho do cluster é limitado, gostaria de entender a eficiência geral da implementação das partes do servidor e do cliente.
Os resultados do teste serão apresentados a seguir, mas antes de avançarmos para eles, vale a pena considerar mais algumas nuances importantes.
Quanto ao AS, trata-se de uma base de dados bastante atrativa, líder na categoria de satisfação do cliente segundo o recurso g2.
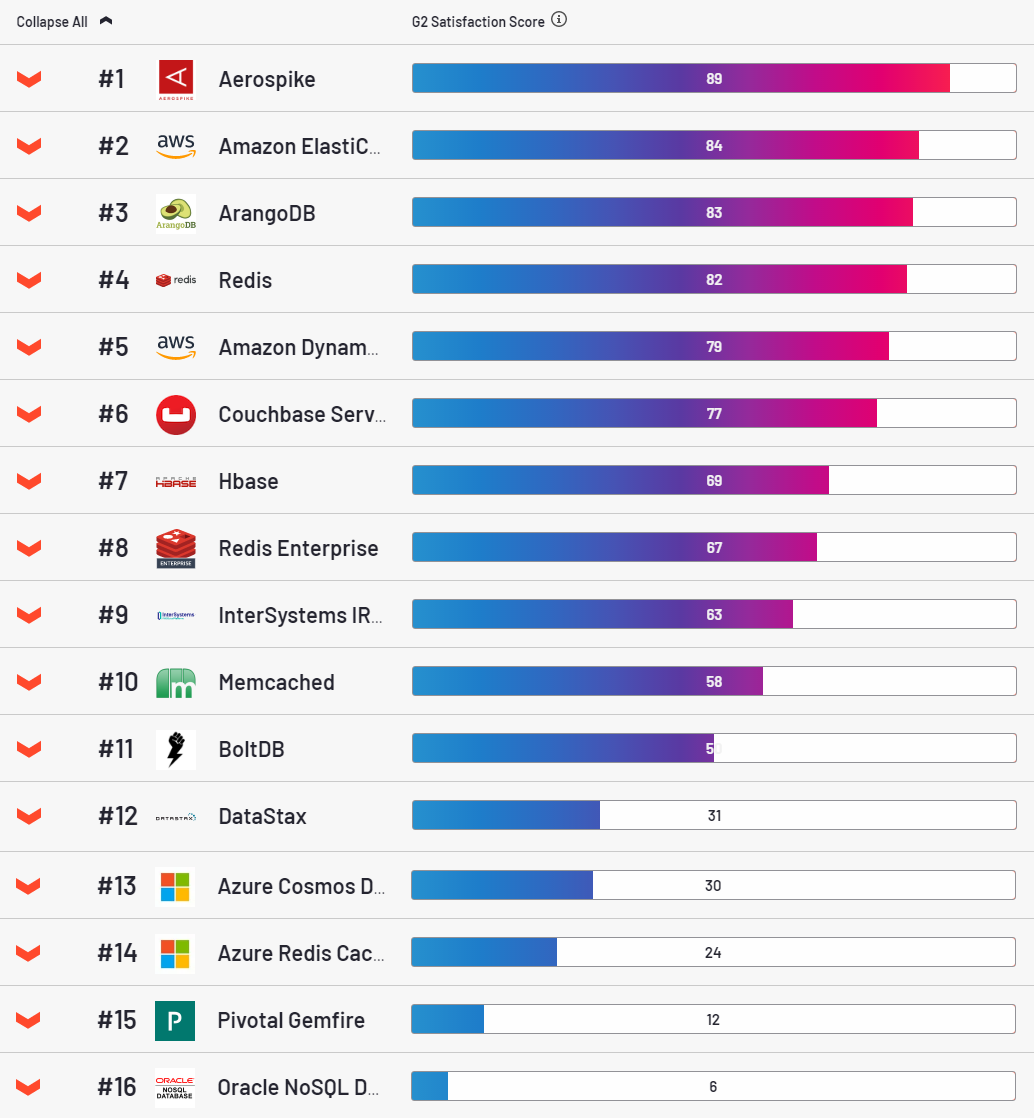
Francamente, de alguma forma também gostei. É colocado de forma simples, com este scriptrola para a nuvem com bastante facilidade. Estável, é um prazer configurar. No entanto, tem uma grande desvantagem. Para cada chave, ele aloca 64 bytes de RAM. Parece um pouco, mas em volumes industriais torna-se um problema. Uma entrada típica em nossas tabelas é 500 bytes. É esta quantidade de valor que usei em quase * todos os testes (* porque quase será dito a seguir).
Como armazenamos 3 cópias de cada registro, para armazenar 1 PB de dados limpos (3 PB de dados sujos), teremos que alocar apenas 400 TB de RAM. Continuando ... não o quê ?! Espere um segundo, há algo que você possa fazer a respeito? - perguntamos ao vendedor.
Claro que você pode fazer muitas coisas, dobrar os dedos:
Ok, agora vamos tratar do HB e já podemos considerar os resultados do teste. Para instalar o Hadoop, a Amazon fornece a plataforma EMR, o que facilita a implementação do cluster de que você precisa. Eu só tive que aumentar os limites do número de processos e arquivos abertos, caso contrário, ele travou sob carga e substituiu o hbase-server pelo meu assembly otimizado (veja os detalhes aqui ). O segundo ponto, o HB desavergonhadamente diminui ao trabalhar com solicitações únicas, isso é um fato. Portanto, só trabalhamos em lotes. Neste teste, lote = 100. Existem 100 regiões na tabela.
Bem, e no último momento, todos os bancos de dados foram testados no modo de "consistência forte". Para o HB, está pronto para uso. AS está disponível apenas na versão empresarial (ou seja, foi habilitado neste teste). SC foi executado em consistência de gravação = modo all. O fator de replicação está em todo lugar 3.
Então, vamos lá. Inserir em AS:
10 seg: 360554 operações; 36055,4 operações atuais / s;
20 seg: 698872 operações; 33831,8 operações atuais / s;
...
230 seg .: 7412626 operações; 22938,8 operações atuais / s;
240 seg: 7542091 operações; 12946,5 operações atuais / s;
250 seg: 7589682 operações; 4759,1 operações atuais / s;
260 seg: 7599525 operações; 984,3 operações atuais / s;
270 s: 7602150 operações; 262,5 operações atuais / s;
280 seg: 7602752 operações; 60,2 operações atuais / s;
290 seg: 7602918 operações; 16,6 operações atuais / s;
300 seg: 7603269 operações; 35,1 operações atuais / s;
310 s: 7603674 operações; 40,5 operações atuais / s;
Erro ao gravar a chave user4809083164780879263: com.aerospike.client.AerospikeException $ Tempo limite: Tempo limite do cliente: tempo limite = 10000 iterações = 1 failedNodes = 0 failedConns = 0 lastNode = 5600000A 127.0.0.1:3000
Erro ao inserir, não tentar mais. número de tentativas: 1 Limite de repetição de inserção: 0
Ops, você é definitivamente um
Ok, vamos continuar. Começamos a carregar 200 milhões de registros (INSERT), depois UPDATE e depois GET. Aqui está o que aconteceu (ops - operações por segundo):

IMPORTANTE! Esta é a velocidade de um nó! Existem 4 deles no total, ou seja, para obter a velocidade total, você precisa multiplicar por 4.
A primeira coluna contém 10 campos, este não é um teste totalmente justo. Aqueles. é quando o índice está na memória, o que é inatingível em uma situação real de BigData.
A segunda coluna está compactando 10 registros em 1. já existe uma economia real de memória, exatamente 10 vezes. Como você pode ver claramente no teste, esse truque não é em vão, o desempenho cai significativamente. A razão é óbvia, cada vez que processar um registro, você terá que lidar com 9 registros adjacentes. A sobrecarga é mais curta.
E, finalmente, totalmente alinhado, aqui está a mesma imagem. As inserções de descarga são piores, mas a operação de atualização de chave é mais rápida, portanto, além disso, iremos apenas comparar com a descarga total.
Na verdade, não vamos puxar o gato, de imediato:

Tudo geralmente está claro, mas o que deve ser adicionado aqui.
- AS , .
- SC - , :

Talvez em algum lugar haja um batente com as configurações ou aquele bug com o kernel que surgiu, não sei. Mas eu configurei tudo do e para o script do fornecedor, então o ciclomotor não é meu, todas as perguntas são para ele.
Você também precisa entender que esta é uma quantidade muito modesta de dados e em grandes volumes a situação pode mudar. Durante os experimentos, queimei várias centenas de dólares, então o entusiasmo foi suficiente apenas para um teste de líder de longo prazo e em um modo limitado a um servidor.
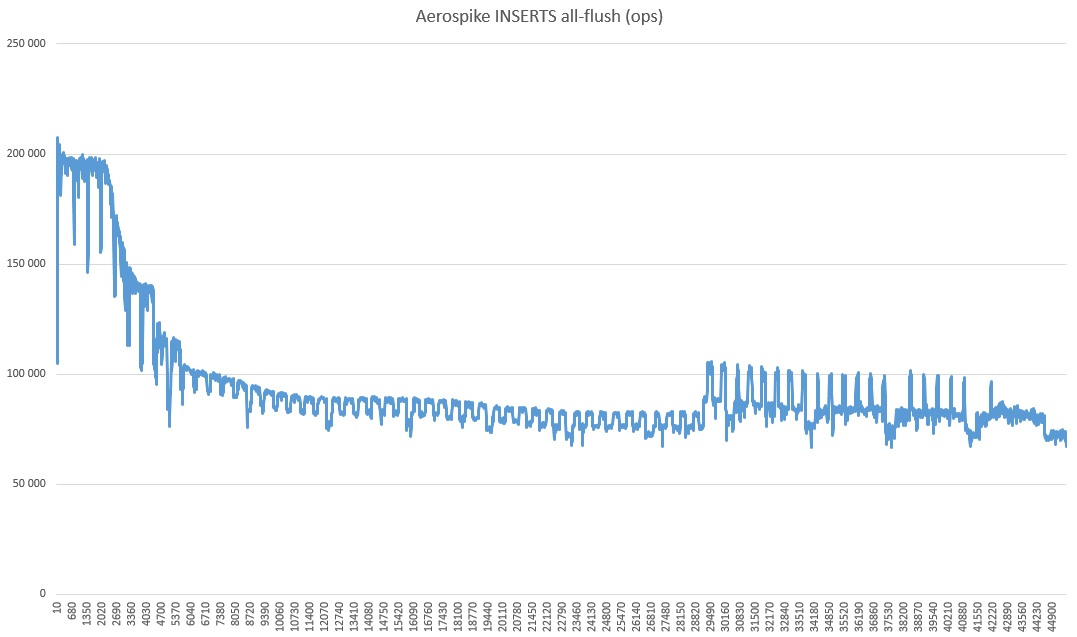
Por que diminuiu tanto e que tipo de avivamento no último terço é um mistério da natureza. Você também pode perceber que a velocidade é radicalmente maior do que nos testes, um pouco maior. Suponho que seja porque o modo de consistência forte está desativado (já que há apenas um servidor).
E, finalmente, GET + WRITE (além de mais de três bilhões de registros inundados com o teste):
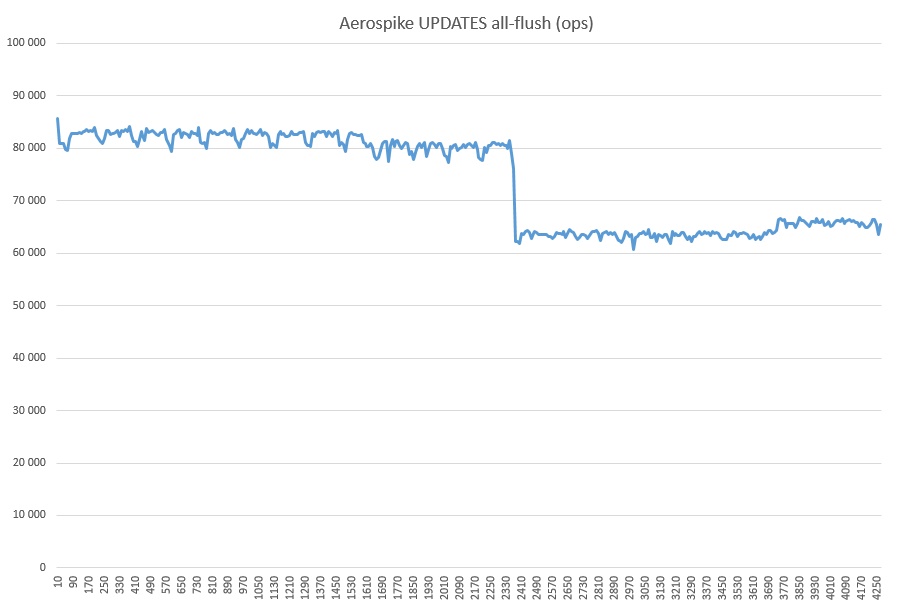
Que tipo de rebaixamento é esse, eu não acho no meu coração. Nenhum processo estranho foi iniciado. Talvez tenha algo a ver com o cache SSD, porque a utilização durante todo o teste de AS em modo all-flush foi de 100%.

Isso é tudo. As conclusões são geralmente claras, são necessários mais testes. É desejável para todos os bancos de dados mais populares nas mesmas condições. Na internet esse gênero não é muito. E seria bom, então os fornecedores básicos estarão motivados para otimizar e nós escolheremos deliberadamente os melhores.