
Na Playrix, uma quantidade significativa de recursos é alocada para preparação e análise de dados, tentamos usar tecnologias avançadas e levamos a sério o treinamento dos funcionários. A empresa é uma das 3 principais desenvolvedoras de jogos para celular do mundo, por isso tentamos manter o nível adequado em análise de dados e, especificamente, em Business Intelligence. Mais de 27 milhões de usuários jogam nossos jogos todos os dias, e este número pode dar uma ideia aproximada da quantidade de dados gerados por dispositivos móveis todos os dias. Além disso, os dados são obtidos de dezenas de serviços em vários formatos, após o que são agregados e carregados em nossos armazenamentos. Trabalhamos com AWS S3 como Data Lake, enquanto o Data Warehouse no AWS Redshift e PostgreSQL tem uso limitado. Usamos esses bancos de dados para análises. Redshift é mais rápido, mas mais caroé por isso que armazenamos os dados mais solicitados lá. PostgreSQL é mais barato e lento, ele armazena pequenas quantidades de dados ou dados cuja velocidade de leitura não é crítica. Para dados pré-agregados, usamos cluster Hadoop e Impala.
A principal ferramenta de BI do Playrix é o Tableau. Este produto é bastante conhecido no mundo inteiro, possui amplas oportunidades de análise e visualização de dados, trabalho com diversas fontes. Além disso, você não precisa escrever código para tarefas de análise simples, portanto, pode treinar usuários de diferentes departamentos para analisar seus dados de negócios por conta própria. O fornecedor da ferramenta Tableau Software também posiciona seu produto como uma ferramenta de autoanálise de dados, ou seja, de Autoatendimento.
Existem duas abordagens principais para a análise de dados em BI:
- Reporting Factory . Essa abordagem tem um departamento e / ou pessoas desenvolvendo relatórios para usuários de negócios.
- Self-Service. - .
A primeira abordagem é tradicional, e a maioria das empresas tem uma fábrica de relatórios para toda a empresa como esta. A segunda abordagem é relativamente nova, especialmente para a Rússia. É bom porque os dados são pesquisados pelos próprios usuários de negócios - eles conhecem seus processos locais muito melhor. Isso ajuda a descarregar os desenvolvedores, livrando-os da necessidade de mergulhar nas especificidades dos processos da equipe e criar os relatórios mais básicos todas as vezes. Isso ajuda a resolver o que provavelmente é o maior problema - fazer a ponte entre os usuários de negócios e os desenvolvedores. Afinal, o principal problema da abordagem do Reporting Factory é precisamente que a maioria dos relatórios pode permanecer sem reclamação apenas devido ao fato de que os programadores-desenvolvedores não entendem os problemas dos usuários de negócios e, portanto, criam relatórios desnecessários.que são retrabalhados posteriormente ou simplesmente não usados.
Na Playrix, programadores e analistas estiveram inicialmente envolvidos no desenvolvimento de relatórios na empresa, ou seja, especialistas que trabalham com dados no dia a dia. Mas a empresa está se desenvolvendo muito rapidamente e, à medida que as necessidades dos usuários por relatórios aumentam, os desenvolvedores de relatórios deixaram de estar a tempo de resolver todas as tarefas de sua criação e suporte. Então surgiu a questão de expandir o grupo de desenvolvimento de BI ou transferir competências para outros departamentos. A direção do Autoatendimento parecia promissora para nós, então decidimos ensinar os usuários de negócios a criar seus próprios projetos e analisar dados por conta própria.
Na Playrix, a divisão de Business Intelligence (Equipe de BI) atua nas seguintes tarefas:
- Recolha, preparação e armazenamento de dados.
- Desenvolvimento de serviços analíticos internos.
- Integração com serviços externos.
- Desenvolvimento de interfaces web.
- Desenvolvimento de relatórios em Tableau.
Estamos engajados na automação de processos internos e análises. De forma simplificada, nossa estrutura pode ser representada usando o diagrama:

Equipe de BI de mini-equipes Os
retângulos aqui representam as mini-equipes. Nas laterais esquerdas, nas laterais direitas. Cada um deles tem competências suficientes para trabalhar com as tarefas das equipes relacionadas e assumi-las quando as outras equipes estão sobrecarregadas.
A equipe de BI tem um ciclo completo de desenvolvimento: desde a coleta de requisitos até a implantação em um ambiente de produto e suporte subsequente. Cada miniequipe tem seu próprio analista de sistemas, desenvolvedores e engenheiros de teste. Eles servem como Reporting Factory , preparando dados e relatórios para uso interno.
É importante observar aqui que, na maioria dos projetos do Tableau, desenvolvemos não relatórios simples, que geralmente são mostrados em demonstrações, mas ferramentas com funcionalidade rica, um grande conjunto de controles, recursos abrangentes e conexão de módulos externos. Essas ferramentas são constantemente revisadas, novos recursos são adicionados.
No entanto, também surgem problemas locais simples, que podem ser resolvidos pelo próprio cliente.
Transferência de competências e lançamento de projeto piloto
De acordo com nossa experiência de trabalho e comunicação com outras empresas, os principais problemas ao transferir competências de dados para usuários de negócios são:
- A relutância dos próprios usuários em aprender novas ferramentas e trabalhar com dados.
- Falta de suporte da gestão (investimento em treinamentos, licenças, etc.).
Temos um apoio colossal da administração, além disso, a administração se ofereceu para introduzir o Autoatendimento. Os usuários também desejam aprender a trabalhar com dados e Tableau - isso é interessante para os caras, além de que a análise de dados agora é uma habilidade muito significativa que certamente será útil no futuro.
Implementar uma nova ideologia em toda a empresa geralmente requer muitos recursos e nervos, então começamos com um piloto. O projeto piloto de Autoatendimento foi lançado no departamento de Aquisição de Usuários há um ano e meio e, durante o processo piloto, foram acumulados erros e experiências para repassá-los a outros departamentos no futuro.
A direção de Aquisição de Usuários trabalha nas tarefas de aumentar a audiência de nossos produtos, analisa as formas de aquisição de tráfego e escolhe em quais direções de captação de usuários vale a pena investir os recursos da empresa. Anteriormente, para essa direção, os relatórios eram elaborados pela equipe de BI, ou a própria galera processava os uploads do banco de dados em Excel ou Planilhas Google. Mas, em um ambiente de desenvolvimento dinâmico, essa análise acarreta atrasos e o número de dados analisados é limitado pelos recursos dessas ferramentas.
No início do piloto, conduzimos o treinamento básico para os funcionários trabalharem com o Tableau, criamos a primeira fonte de dados comum - uma tabela no banco de dados Redshift, na qual havia mais de 500 milhões de linhas e as métricas necessárias. Deve-se observar que o Redshift é um banco de dados colunar (ou colunar), e esse banco de dados fornece dados muito mais rápido do que os bancos de dados relacionais. A tabela piloto no Redshift era realmente grande para pessoas que nunca trabalharam com mais de 1 milhão de linhas ao mesmo tempo. Mas foi um desafio para a galera aprender a trabalhar com dados desses volumes.
Sabíamos que os problemas de desempenho começariam à medida que esses relatórios se tornassem mais complexos. Não demos aos usuários acesso ao próprio banco de dados, mas uma fonte foi implementada no servidor Tableau, conectada no modo ao vivo a uma tabela no Redshift. Os usuários tinham licenças de criador e podiam se conectar a essa fonte a partir do servidor Tableau, desenvolvendo relatórios lá, ou do Tableau Desktop. Devo dizer que, ao desenvolver relatórios na web (o Tableau tem um modo de edição da web), existem algumas limitações no servidor. O Tableau Desktop não tem essas restrições, por isso desenvolvemos principalmente no Desktop. Além disso, se apenas um usuário empresarial precisar de análise, não é necessário publicar esses projetos no servidor - você pode trabalhar localmente.
Treinamento
Em nossa empresa, é costume a realização de webinars e compartilhamento de conhecimentos, nos quais cada funcionário pode falar sobre novos produtos, funcionalidades ou capacidades das ferramentas com as quais trabalha ou está pesquisando. Todas essas atividades são registradas e armazenadas em nossa base de conhecimento. Esse processo também funciona em nossa equipe, por isso também compartilhamos conhecimento periodicamente ou preparamos webinars de treinamento fundamental.
Para todos os usuários com licenças do Tableau, hospedamos e gravamos um webinar de meia hora sobre como trabalhar com o servidor e os painéis. Eles falaram sobre projetos no servidor, trabalhando com controles nativos de todos os painéis - este é o painel superior (atualizar, pausar, ...). É imperativo informar a todos os usuários do Tableau sobre isso para que possam trabalhar totalmente com recursos nativos e não façam solicitações para o desenvolvimento de recursos que repetem o trabalho dos controles nativos.
O principal obstáculo para dominar uma ferramenta (e na verdade algo novo) geralmente é o medo de não ser possível entender e trabalhar com essa funcionalidade. Portanto, o treinamento é talvez a etapa mais importante na implementação da abordagem de BI de autoatendimento. O resultado da implantação desse modelo vai depender muito dele - se vai se enraizar na empresa e, em caso afirmativo, com que rapidez. No lançamento dos webinars, as barreiras ao uso do Tableau devem ser removidas.
Existem dois grupos de webinars que realizamos para pessoas que não estão familiarizadas com o trabalho de bancos de dados:
- Kit de conhecimento para iniciantes para iniciantes:
- Conexão de dados, tipos de conexão, tipos de dados, transformações de dados básicos, normalização de dados (1 hora).
- Visualizações básicas, agregação de dados, cálculos básicos (1 hora).
- /, (2 ).
Neste primeiro webinar de lançamento, cobrimos tudo relacionado à conectividade e transformação de dados no Tableau. Como as pessoas geralmente têm um nível básico de proficiência em MS Excel, é importante aqui explicar como trabalhar no Excel é fundamentalmente diferente de trabalhar no Tableau. Este é um ponto muito importante, porque você precisa mudar uma pessoa da lógica das tabelas com células coloridas para a lógica dos dados normalizados do banco de dados. No mesmo webinar, explicamos o trabalho de JOIN, UNION, PIVOT e também tocamos em Blending. No primeiro webinar, mal tocamos na visualização de dados, seu objetivo é explicar como trabalhar e transformar seus dados para o Tableau. É importante que as pessoas entendam que os dados são primários e a maioria dos problemas surge no nível dos dados, não no nível da visualização.
O segundo webinar sobre Autoatendimento tem como objetivo falar sobre a lógica de criação de visualizações no Tableau. O Tableau é muito diferente de outras ferramentas de BI precisamente porque tem seu próprio mecanismo e sua própria lógica. Em outros sistemas, por exemplo, no PowerBI, existe um conjunto de visuais prontos (você pode baixar módulos adicionais na loja), mas esses módulos não são personalizáveis. No Tableau, você realmente tem uma tela em branco sobre a qual pode criar o que quiser. Obviamente, o Tableau tem ShowMe - um menu de visualizações básicas, mas todos esses gráficos e diagramas podem e devem ser construídos de acordo com a lógica do Tableau. Em nossa opinião, se você deseja ensinar alguém a trabalhar com o Tableau, não precisa usar o ShowMe para construir gráficos - a maioria deles não será útil para as pessoas no início, mas você precisa ensinar exatamente a lógica da construção visualizações. Para painéis de negócios, é suficiente sabercomo construir:
- Séries Temporais. Gráficos de linha / área (gráficos de linha),
- Gráficos de barra
- Gráficos de dispersão,
- Mesas
Este conjunto de visualizações é suficiente para a autoanálise dos dados.
Séries Temporais: são muito utilizadas em negócios porque é interessante comparar métricas em diferentes períodos de tempo. Provavelmente, todos os colaboradores da empresa estão a olhar para a dinâmica dos resultados empresariais no nosso país. Usamos gráficos de barras para comparar as métricas por categoria. Gráficos de dispersão raramente são usados, geralmente para encontrar correlações entre métricas. Tabelas: algo que os painéis de negócios não conseguem eliminar completamente, mas sempre que possível tentamos minimizar seu número. Nas tabelas, coletamos os valores numéricos das métricas por categoria.
Ou seja, enviamos as pessoas em free float após 1 hora de treinamento em trabalho com dados e 1 hora de treinamento em cálculos básicos e visualizações. Aí os próprios caras trabalham com seus dados por algum tempo, enfrentam problemas, ganham experiência, é só botar as mãos neles. Esta fase leva de 2 a 4 semanas em média. Naturalmente, neste período existe a oportunidade de consultar a Equipe de BI se algo não der certo.
Após o primeiro estágio, os colegas precisam aprimorar suas habilidades e explorar novas oportunidades. Para isso, preparamos webinars de treinamento aprofundado. Neles, mostramos como trabalhar com funções LOD, funções de tabela, scripts Python para TabPy. Trabalhamos com dados da empresa ao vivo, que são sempre mais interessantes do que dados falsos ou do conjunto de dados básico do Tableau - Superstore. Nos mesmos webinars, falamos sobre os principais recursos e truques do Tableau que são usados em painéis proprietários, por exemplo:
- Troca de folhas (substituição de folhas),
- Agregação de gráficos usando parâmetros,
- Formatos de data e métrica
- Descartando períodos incompletos para agregações semanais / mensais.
Todos esses truques e recursos eram usados há alguns anos, então todos na empresa se acostumaram com eles e os adotamos nos padrões de desenvolvimento de painel. Usamos scripts Python para calcular algumas métricas internas, todos os scripts já estão prontos e, para o Autoatendimento, precisamos entender como inseri-los em nossos cálculos.
Portanto, realizamos apenas 4 horas de webinars para iniciar o Autoatendimento e isso geralmente é o suficiente para uma pessoa motivada começar a trabalhar com o Tableau e analisar os dados por conta própria. Além disso, para analistas de dados, temos nossos próprios webinars, que estão disponíveis publicamente e você pode conhecê-los.
Desenvolvimento de fontes de dados para autoatendimento
Após a realização do projeto piloto, consideramos o mesmo um sucesso e ampliamos o número de usuários do Autoatendimento. Um dos grandes desafios foi preparar fontes de dados para diferentes equipes. Os caras da Self-Service podem trabalhar com mais de 200 milhões de linhas, então a equipe de Engenharia de Dados teve que descobrir como implementar essas fontes de dados. Para a maioria das tarefas analíticas, usamos Redshift devido à velocidade de leitura de dados e facilidade de uso. Mas dar acesso ao banco de dados para cada pessoa do Autoatendimento era arriscado do ponto de vista da segurança da informação.
A primeira ideia era criar fontes com uma conexão ativa ao banco de dados, ou seja, várias fontes foram publicadas no Tableau Server que olhavam em tabelas ou em exibições preparadas do Redshift. Nesse caso, não armazenamos dados no servidor Tableau, e os próprios usuários por meio dessas fontes foram do Tableau Desktop (clientes) para o banco de dados. Isso funciona quando as tabelas são pequenas (milhões) ou as consultas do Tableau não são excessivamente complexas. À medida que se desenvolviam, os caras começaram a complicar seus painéis no Tableau, usar LODs, classificações personalizadas e scripts Python. Naturalmente, isso levou a uma lentidão no trabalho de alguns painéis de autoatendimento. Portanto, alguns meses após o início do Autoatendimento, revisamos a abordagem de trabalho com as fontes.
A nova abordagem que temos usado até agora implementou extratos publicados no Tableau Server. Devo dizer que o Autoatendimento constantemente tem novas tarefas, e eles recebem solicitações para adicionar novos campos à fonte, claro, as fontes de dados estão constantemente sendo modificadas. Desenvolvemos a seguinte estratégia para trabalhar com fontes:
- De acordo com o TOR para a origem do lado do Autoatendimento, os dados são coletados nas tabelas do banco de dados.
- Uma visualização imaterializada é criada no esquema de teste do banco de dados Redshift.
- O envio é testado quanto à exatidão dos dados pela equipe de QA.
- No caso de um resultado positivo da verificação, a visão é aumentada no esquema de redshift prod.
- A equipe de engenharia de dados dá uma visão para suporte - scripts para analisar a validade dos dados são conectados, alarmes ETL são conectados e direitos de leitura são fornecidos para a equipe de autoatendimento.
- Tableau Server (), .
- ETL .
- .
- , Self-Service.
Um pouco sobre o ponto 7. Nativamente, o Tableau permite que você crie extrações em uma programação com uma diferença mínima de 5 minutos. Se você tem certeza de que suas tabelas no banco de dados são sempre atualizadas às 4 da manhã, então você pode simplesmente definir a extração para as 5 da manhã para que seus dados sejam coletados. Isso cobre uma série de tarefas. No nosso caso, as tabelas são coletadas de acordo com dados de vários provedores, inclusive. Assim, se um provedor ou nosso serviço interno não conseguir atualizar sua parte dos dados, toda a tabela é considerada inválida. Ou seja, você não pode simplesmente definir uma programação para um horário fixo. Portanto, usamos a API do Tableau para executar extrações quando as tabelas estão prontas. Os sinais de lançamento de extrações são gerados por nosso serviço ETL depois que ele garante que todos os novos dados chegaram e são válidos.
Essa abordagem permite que você tenha novos dados válidos na extração com latência mínima.
Publicação de painéis de autoatendimento no Tableau Server
Deliberadamente, não limitamos as pessoas em experimentos com seus dados e nos permitimos publicar e compartilhar nossas pastas de trabalho. Dentro de cada equipe, se uma pessoa acha que seu painel é útil para outras pessoas, ou se o funcionário precisa de um painel no servidor, ele pode publicá-lo. A equipe de BI não interfere nos experimentos internos das equipes, respectivamente, eles elaboram toda a lógica dos dashboards e cálculos próprios. Há casos em que um projeto interessante surge do Autoatendimento, que então é totalmente transferido para o suporte da equipe de BI e vai para a produção. Este é exatamente o efeito do Autoatendimento, quando as pessoas, tendo um bom conhecimento de suas tarefas de negócios, passam a trabalhar com seus dados e a formar uma nova estratégia para seu trabalho. Com base nisso, fizemos o seguinte esquema de projetos no servidor:
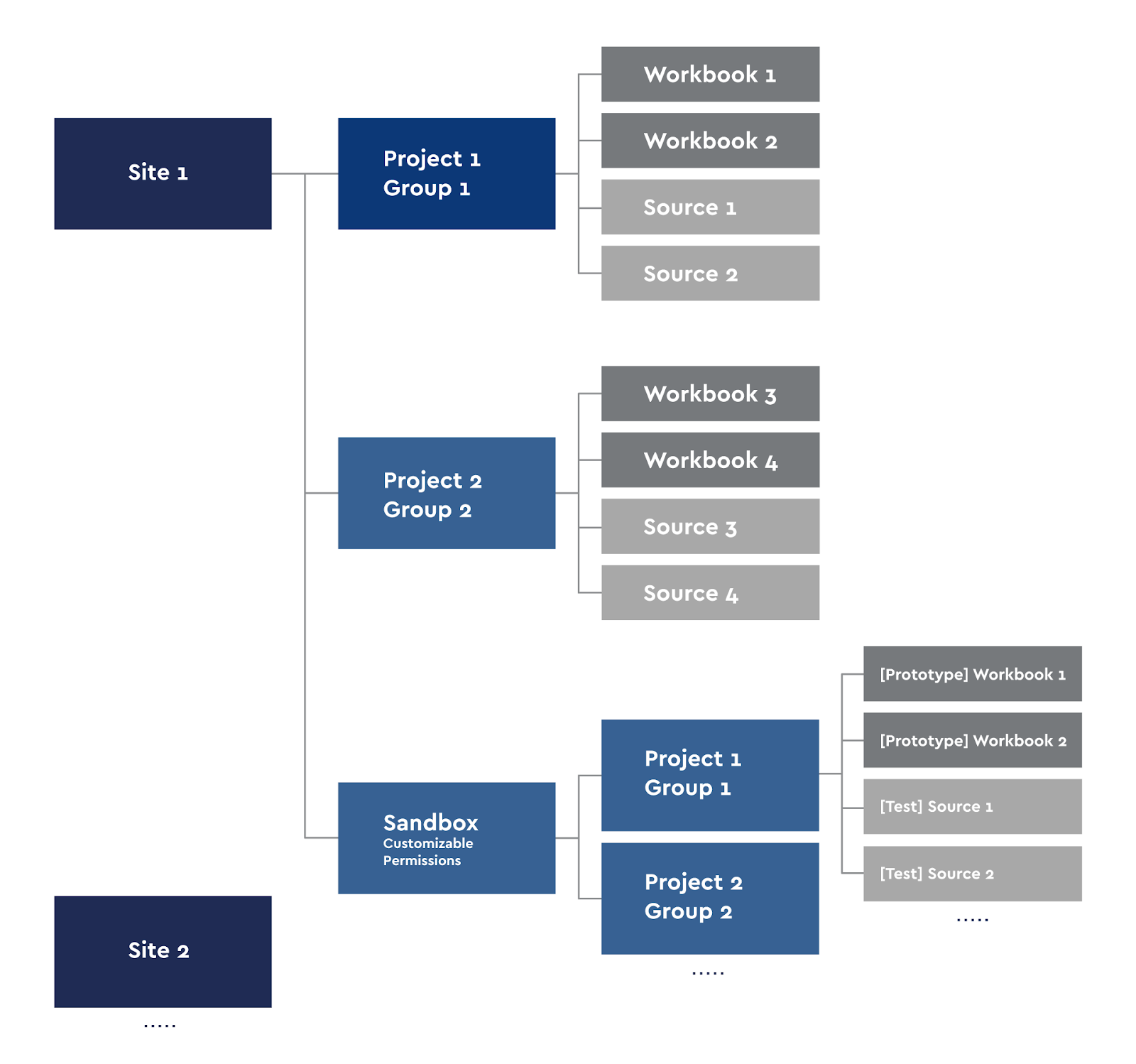
Diagrama de projeto do Tableau Server
Cada usuário Criador pode publicar suas pastas de trabalho no servidor ou fazer a análise localmente. Para o autoatendimento, criamos nosso próprio Sandbox com nossos grupos de projetos.
Os sites no Tableau são ideologicamente divididos para que os usuários de um site não vejam o conteúdo de outro, portanto, dividimos o servidor em sites em áreas que não se sobrepõem: por exemplo, análise de jogos e finanças. Estamos usando o acesso de grupo. Cada site tem projetos nos quais os direitos de suas pastas de trabalho e fontes são herdados. Ou seja, o grupo de usuários Grupo 1 vê apenas suas pastas de trabalho e fontes de dados. A exceção a essa regra é o site Sandbox, que também possui subprojetos. Utilizamos Sandbox para prototipagem, desenvolvimento de novos dashboards, testando-os e para as necessidades de Autoatendimento. Qualquer pessoa com acesso de publicação a seu projeto Sandbox pode publicar seus protótipos.
Monitorar fontes e painéis no Tableau Server
Como transferimos a carga de solicitações de painéis de autoatendimento do banco de dados para o Tableau Server, trabalhamos com grandes fontes de dados e não limitamos as pessoas em solicitações de fontes publicadas, outro problema surgiu - monitorar o desempenho de tais painéis e monitorar o origens.
O monitoramento do desempenho dos painéis e do desempenho dos servidores Tableau é uma tarefa enfrentada por empresas de médio e grande porte, portanto, muitos artigos foram escritos sobre o desempenho dos painéis e seu ajuste. Não nos tornamos pioneiros nessa área, nosso monitoramento é feito em vários painéis baseados no banco de dados interno PostgreSQL Tableau Server. Esse monitoramento funciona com todo o conteúdo, mas você pode selecionar painéis de autoatendimento e ver seu desempenho.
A equipe de BI resolve problemas de otimização do painel de tempos em tempos. Os usuários às vezes perguntam “Por que o painel está lento?”, E precisamos entender o que é “lento” do ponto de vista do usuário e quais critérios numéricos podem caracterizar isso. Para não entrevistar o usuário e não tirar seu tempo de trabalho para uma releitura detalhada dos problemas, monitoramos e analisamos as solicitações de http, encontramos as mais lentas e descobrimos os motivos. Depois disso, vamos otimizar os painéis, se isso levar a um aumento de desempenho. É claro que com uma conexão ao vivo com as fontes, haverá atrasos associados à formação de uma visão no banco de dados, atrasos no recebimento de dados. Também há atrasos na rede que estamos investigando com nossa equipe de suporte para toda a infraestrutura de TI, mas não vamos nos alongar sobre eles neste artigo.
Um pouco sobre solicitações http
Cada interação do usuário com o painel no navegador inicia sua própria solicitação http, transmitida ao Tableau Server. Todo o histórico de tais consultas é armazenado no banco de dados interno PostgreSQL Tableau Server, o período de armazenamento padrão é de 7 dias. Esse período pode ser aumentado alterando as configurações do Tableau Server, mas não queríamos aumentar a tabela de solicitações http, portanto, simplesmente coletamos uma extração incremental que contém apenas dados novos todos os dias, enquanto os antigos não são substituídos. Essa é uma boa maneira com um mínimo de recursos para manter na extração os dados históricos do servidor que não estão mais no banco de dados.
Cada solicitação http tem seu próprio tipo (action_type). Por exemplo, _bootstrap é o carregamento inicial da visão, filtro de data relativa é o filtro de data (controle deslizante). A maioria dos tipos pode ser identificada pelo nome, então fica claro o que cada usuário faz com o painel: alguém olha mais as dicas de ferramentas, alguém altera os parâmetros, alguém cria suas próprias visualizações personalizadas e alguém descarrega os dados.
Abaixo está nosso painel de serviço que nos permite definir painéis lentos, tipos de solicitações lentas e usuários que precisam esperar.
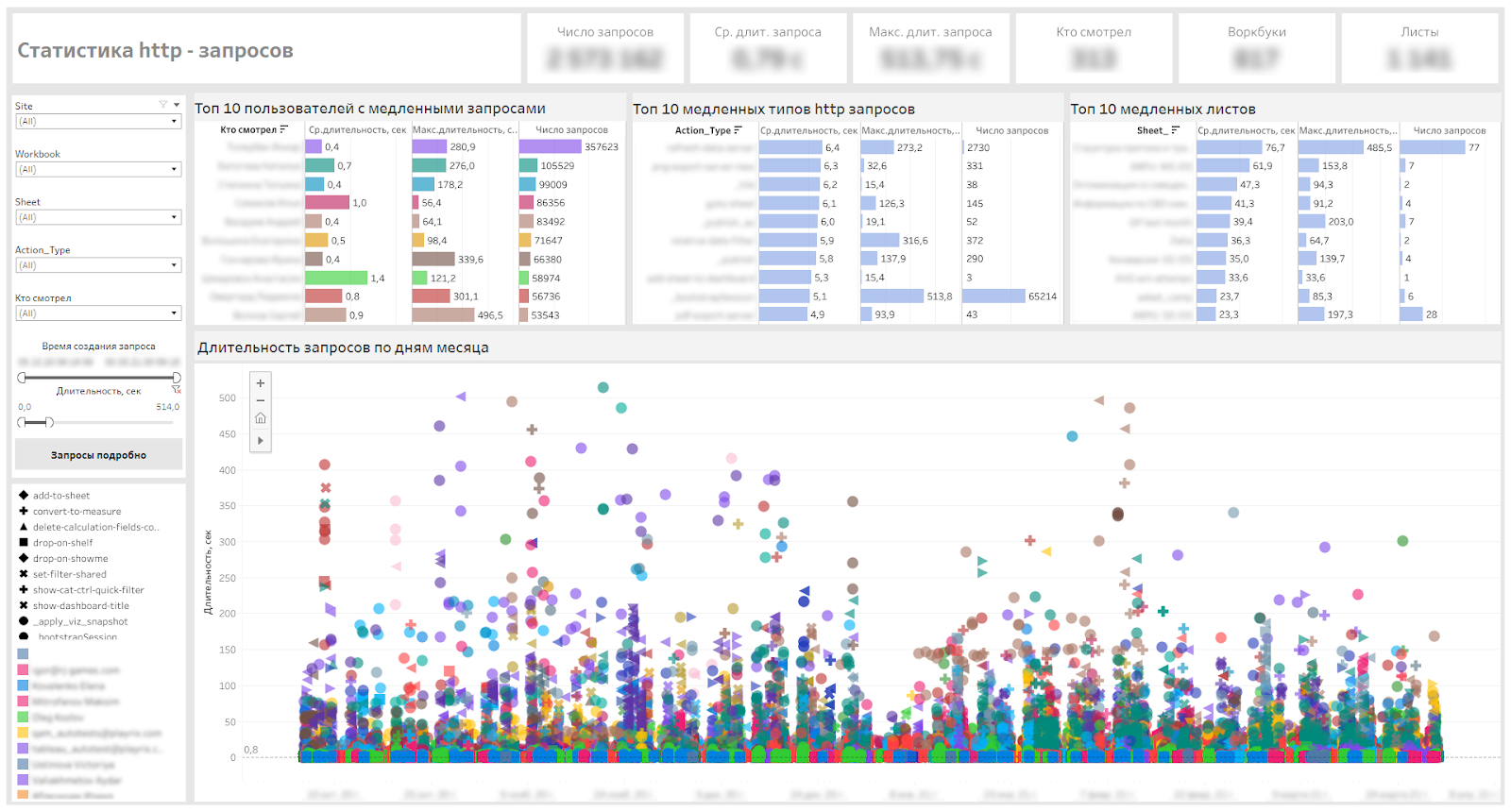
Painel para monitorar solicitações de http
Monitoramento de sessões VizQL
Quando um painel é aberto no navegador, uma sessão VizQL é iniciada no servidor Tableau, dentro do qual as visualizações são renderizadas, os recursos também são alocados para manter a sessão. Essas sessões são interrompidas após 30 minutos de inatividade por padrão.
Conforme o número de usuários no servidor aumentou e o Autoatendimento foi introduzido, recebemos várias solicitações para aumentar os limites de sessão VizQL. O problema para os usuários era que eles abriam painéis, definiam filtros, examinavam algo e passavam para suas outras tarefas fora do Tableau Server, depois de um tempo eles voltavam para os painéis abertos, mas eram redefinidos para a exibição padrão e precisavam ser reaproveitado. Nossa tarefa era tornar a experiência do usuário mais confortável e garantir que a carga no servidor não aumente de forma crítica.
Os próximos dois parâmetros no servidor podem ser alterados, mas você deve entender que a carga no servidor pode aumentar.
vizqlserver.session.expiry.minimum 5
Número de minutos de tempo ocioso após o qual uma sessão VizQL pode ser descartada se o processo VizQL começar a ficar sem memória.
vizqlserver.session.expiry.timeout 30 Número de minutos de tempo ocioso após o qual uma sessão VizQL é descartada.
Portanto, decidimos monitorar as sessões VizQL e rastrear:
- Número de sessões,
- Número de sessões por usuário,
- Duração média das sessões,
- A duração máxima das sessões.
Além disso, precisávamos entender em quais dias e em quais horários se abre o maior número de sessões.
O resultado é um painel como este:

Dashboard para monitoramento de sessões VizQL
Desde o início de janeiro deste ano, começamos a aumentar gradativamente os limites e monitorar a duração das sessões e carga. A duração média da sessão aumentou de 13 para 35 minutos - isso pode ser visto nos gráficos da duração média da sessão. As configurações finais são as seguintes:
vizqlserver.session.expiry.minimum 120 vizqlserver.session.expiry.timeout 240
Depois disso, recebemos feedback positivo dos usuários, o que se tornou muito mais agradável de trabalhar - as sessões pararam de diminuir.
Os mapas de calor deste painel também nos permitem agendar o trabalho de serviço durante as horas de demanda mínima do servidor.
Monitoramos a mudança na carga do cluster - CPU e RAM - no Zabbix e no console AWS. Não registramos mudanças significativas na carga durante o aumento nos tempos limite.
Se falarmos sobre o que pode dobrar muito seu Tableau Server, então pode ser, por exemplo, um painel não otimizado. Por exemplo, crie uma tabela no Tableau com dezenas de milhares de linhas por categorias e id de alguns eventos e, em Medida, use cálculos de LOD no nível de id. Com grande probabilidade, a exibição da tabela no servidor não funcionará, e você obterá um travamento com um Erro Inesperado, pois todos os LODs em granulação mínima consumirão muita memória, e logo o processo rodará em 100% de consumo de memória.
Este exemplo é dado aqui para deixar claro que um painel não ideal pode consumir todos os recursos do servidor, e mesmo 100 sessões VizQL dos painéis ideais não consumirão tantos recursos.
Fontes de dados do servidor de monitoramento
Acima, notamos que para o Autoatendimento, preparamos e publicamos várias fontes de dados no servidor. Todas as fontes são extrações de dados. As fontes publicadas são salvas no servidor e disponibilizadas para os funcionários que trabalham com o Tableau Desktop.
O Tableau tem a capacidade de marcar fontes como certificadas. Isso é o que a equipe de BI faz ao preparar fontes de dados para Autoatendimento. Isso garante que a própria fonte foi testada.
As fontes publicadas podem ter até 200 milhões de linhas e 100 campos. Para o autoatendimento, esse é um volume muito grande, uma vez que poucas empresas têm fontes de tais volumes para análises independentes.
Naturalmente, ao coletar requisitos para gerar uma fonte, observamos como podemos reduzir a quantidade de dados na fonte agrupando categorias, dividindo as fontes por projeto ou limitando os períodos de tempo. Mesmo assim, como regra, as fontes são obtidas a partir de 10 milhões de linhas.
Como as fontes são grandes, ocupam espaço no servidor, utilizam recursos do servidor para atualizar as extrações, então todas elas precisam ser monitoradas, para ver com que frequência são utilizadas e com que rapidez aumentam de volume. Para isso, fizemos um monitoramento de fontes de dados publicadas. Mostra os usuários que se conectam a fontes, pastas de trabalho que usam essas fontes. Isso permite que você encontre fontes irrelevantes ou problemáticas que a extração não pode coletar.
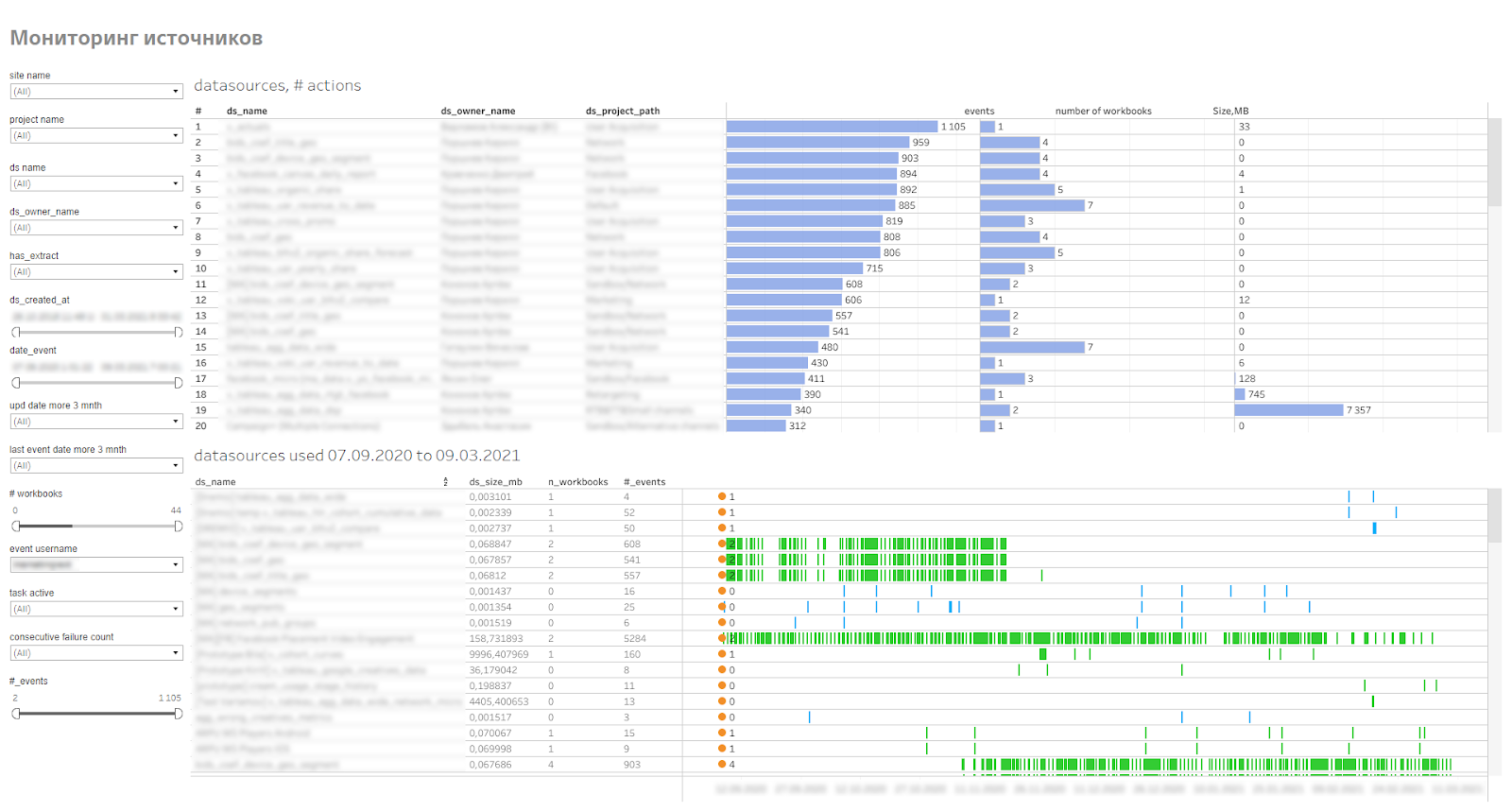
Painel de monitoramento de origem
Resultado
Temos usado a abordagem de autoatendimento há 1,5 anos. Durante esse tempo, 50 usuários começaram a trabalhar de forma independente com os dados. Isso reduziu a carga da Equipe de BI e permitiu que os caras não esperassem até que a Equipe de BI chegasse à sua tarefa específica de desenvolver um painel. Cerca de 5 meses atrás, começamos a conectar outras áreas à autoanálise.
Estamos planejando realizar um treinamento sobre as melhores práticas de alfabetização de dados e visualização.
É importante entender que o processo de Autoatendimento não pode ser implementado rapidamente em toda a empresa; isso levará algum tempo. Se o processo de transição for orgânico, sem chocar os funcionários, depois de alguns anos de implementação, você poderá obter processos fundamentalmente diferentes para trabalhar com dados em diferentes departamentos e áreas da empresa.