
Daniel Lemire - professor da Correspondence University of Quebec (TÉLUQ), que inventou uma maneira de analisar double muito rapidamente - junto com o engenheiro John Kaiser da Microsoft publicou outro achado: o validador UTF-8, superando a biblioteca UTF-8 CPP (2006) em 48..77 vezes, DFA de Björn Hörmann (2009) - 20..45 vezes e Google Fuchsia (2020) - 13..35 vezes. As novidades desta publicação já foram postadas no Habré , mas sem detalhes técnicos; então nós compensamos essa lacuna.
Requisitos UTF-8
Para começar, lembre-se de que o Unicode permite pontos de código de U + 0000 a U + 10FFFF, que são codificados em UTF-8 como sequências de 1 a 4 bytes:
| O número de bytes na codificação | O número de bits no ponto de código | Valor mínimo | Valor máximo |
|---|---|---|---|
| 1 | 1..7 | U + 0000 = 0 0000000 | U + 007F = 0 1111111 |
| 2 | 8-11 | U + 0080 = 110 00010 10 000 000 | U + 07FF = 110 11111 10 111111 |
| 3 | 12 a 16 | U + 0800 = 1110 0000 10 100000 10 000000 | U + FFFF = 1110 1111 10 111111 10 111111 |
| quatro | 17 a 21 | U + 010000 = 11110 000 10 010000 10 000000 10 000000 | U + 10FFFF = 11110 100 10 001111 10 111111 10 111111 |
De acordo com as regras de codificação, os bits mais significativos do primeiro byte da sequência determinam o número total de bytes na sequência; O bit mais significativo zero só pode estar em caracteres de byte único (ASCII), os dois bits mais significativos denotam um caractere multibyte, 1 e zero denotam um byte de continuação> caractere multibyte.
Que tipo de erro pode haver em uma string codificada dessa maneira?
- Seqüência incompleta : um byte inicial ou caractere ASCII foi encontrado no local onde um byte de continuação era esperado;
- Seqüência desabotoada : um byte inicial ou um caractere ASCII era esperado no local onde um byte de continuação foi encontrado;
- Sequência muito longa : o byte inicial
11111xxx
corresponde a uma sequência de cinco bytes ou mais que não é permitida em UTF-8; - Indo além dos limites do Unicode : após decodificar a sequência de quatro bytes, o ponto de código é superior a U + 10FFFF.
Se a linha não contiver nenhum desses quatro erros, ela poderá ser decodificada em uma sequência de pontos de código corretos. UTF-8, no entanto, requer mais - que cada sequência de pontos de código corretos seja codificada de forma exclusiva. Isso adiciona mais dois tipos de erros possíveis:
- : code point ;
- : code points U+D800 U+DFFF UTF-16, code point U+FFFF. UTF-8 , code points , .
Na codificação CESU-8 raramente usada, o último requisito é cancelado (e no MUTF-8 é também o penúltimo), devido ao qual o comprimento da sequência é limitado a três bytes, mas a descriptografia e validação de strings são complicadas. Por exemplo, o emoticon U + 1F600 GRINNING FACE é representado em UTF-16 como um par de substitutos
0xD83D 0xDE00
e CESU-8 / MUTF-8 o traduz em um par de sequências de três bytes
0xED 0xA0 0xBD 0xED 0xB8 0x80
; mas em UTF-8 este smiley é codificado em uma seqüência de quatro bytes
0xF0 0x9F 0x98 0x80
.
Para cada tipo de erro, a seguir estão as sequências de bits que levam a ele:
| Seqüência inacabada | 2º byte ausente | 11xxxxxx 0xxxxxxx
|
11xxxxxx 11xxxxxx
|
||
| 3º byte ausente | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta 4º byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Sequência não testada | 2º byte extra | 0xxxxxxx 10xxxxxx
|
| 3º byte extra | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4º byte extra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5º byte extra | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Seqüência muito longa | 11111xxx
|
|
| Indo além dos limites do Unicode | U + 110000..U + 13FFFF | 11110100 1001xxxx
|
11110100 101xxxxx
|
||
| ≥ U + 140.000 | 11110101
|
|
1111011x
|
||
| Consistência não mínima | 2 bytes | 1100000x
|
| 3 bytes | 11100000 100xxxxx
|
|
| 4 bytes | 11110000 1000xxxx
|
|
| Substitutos | 11101101 101xxxxx
|
|
Validando UTF-8
Com a abordagem ingênua usada na biblioteca UTF-8 CPP de Serbian Nemanja Trifunovic, a validação é realizada em uma cascata de ramos aninhados:
const octet_difference_type length = utf8::internal::sequence_length(it);
// Get trail octets and calculate the code point
utf_error err = UTF8_OK;
switch (length) {
case 0:
return INVALID_LEAD;
case 1:
err = utf8::internal::get_sequence_1(it, end, cp);
break;
case 2:
err = utf8::internal::get_sequence_2(it, end, cp);
break;
case 3:
err = utf8::internal::get_sequence_3(it, end, cp);
break;
case 4:
err = utf8::internal::get_sequence_4(it, end, cp);
break;
}
if (err == UTF8_OK) {
// Decoding succeeded. Now, security checks...
if (utf8::internal::is_code_point_valid(cp)) {
if (!utf8::internal::is_overlong_sequence(cp, length)){
// Passed! Return here.
Dentro
sequence_length()
e
is_overlong_sequence()
também ramificando dependendo do comprimento da sequência. Se as sequências de comprimentos diferentes forem intercaladas de forma imprevisível na string de entrada, o preditor de ramificação não poderá evitar a descarga do pipeline várias vezes em cada caractere processado.
Uma abordagem mais eficiente para a validação UTF-8 é usar uma máquina de estado de 9 estados: (o estado de erro não é mostrado no diagrama)
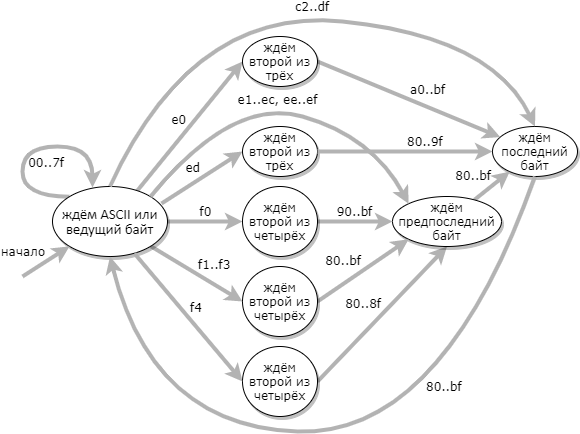
Quando a tabela de transição do autômato é construída, o código do validador é muito simples:
uint32_t type = utf8d[byte];
*codep = (*state != UTF8_ACCEPT) ?
(byte & 0x3fu) | (*codep << 6) :
(0xff >> type) & (byte);
*state = utf8d[256 + *state + type];
Aqui, para cada caractere processado, as mesmas ações são repetidas, sem transições condicionais - portanto, nenhuma redefinição de pipe é necessária; por outro lado, a cada iteração, o acesso adicional à memória (para a tabela de salto
utf8d
) é realizado além da leitura do caractere de entrada.
Lemir e Kaiser usaram o mesmo DFA como base para seu validador e alcançaram uma aceleração dez vezes maior devido à aplicação de três melhorias:
- A tabela de salto foi reduzida de 364 bytes para 48, de forma que cabe inteiramente em três registradores vetoriais (128 bits cada), e os acessos à memória são necessários apenas para a leitura dos caracteres de entrada;
- Blocos de 16 bytes adjacentes são processados em paralelo;
- Se um bloco de 16 bytes consiste inteiramente em caracteres ASCII, então ele está correto e não há necessidade de uma verificação mais completa. Essa "fatia do caminho" acelera o processamento de textos "realistas" contendo frases inteiras do alfabeto latino duas a três vezes; mas em textos aleatórios, onde o alfabeto latino, hieróglifos e emoticons são misturados uniformemente, isso não acelera.
Existem sutilezas sutis na implementação de cada uma dessas melhorias, portanto, vale a pena considerá-las em detalhes.
Reduzindo a tabela de saltos
A primeira melhoria é baseada na observação de que para detectar a maioria dos erros (12 sequências de bits inválidas das 19 listadas na tabela acima), é suficiente verificar os primeiros 12 bits da sequência:
| Seqüência inacabada | 2º byte ausente | 11xxxxxx 0xxxxxxx
|
0x02
|
11xxxxxx 11xxxxxx
|
|||
| Sequência não testada | 2º byte extra | 0xxxxxxx 10xxxxxx
|
0x01
|
| Seqüência muito longa | 11111xxx 1000xxxx
|
0x20
|
|
11111xxx 1001xxxx
|
0x40
|
||
11111xxx 101xxxxx
|
|||
| Indo além dos limites do Unicode | U + 1 [1235679ABDEF] xxxx | 111101xx 1001xxxx
|
|
111101xx 101xxxxx
|
|||
| U + 1 [48C] xxxx | 11110101 1000xxxx
|
0x20
|
|
1111011x 1000xxxx
|
|||
| Consistência não mínima | 2 bytes | 1100000x
|
0x04
|
| 3 bytes | 11100000 100xxxxx
|
0x10
|
|
| 4 bytes | 11110000 1000xxxx
|
0x20
|
|
| Substitutos | 11101101 101xxxxx
|
0x08
|
|
Para cada um desses erros potenciais, os pesquisadores atribuíram um dos sete bits, conforme mostrado na coluna mais à direita. (Os bits atribuídos são diferentes entre seu artigo publicado e seu código GitHub ; aqui estão os valores do artigo.) Para sobreviver com sete bits, os dois subcasos unicode fora dos limites tiveram que ser reparticionados para que o segundo é concatenado com uma sequência não mínima de 4 bytes; e o caso de sequência excessivamente longo é dividido em três subcasos e combinado com os subcasos fora dos limites do Unicode.
Assim, as seguintes alterações foram feitas com o Hörmann DKA:
- A entrada não vem por byte, mas por tétrade (nibble);
- O autômato é usado como não determinístico - o processamento de cada tétrade transfere o autômato entre subconjuntos de todos os estados possíveis;
- Oito estados corretos são combinados em um, mas um incorreto é dividido em sete;
- Três tétrades adjacentes são processadas não sequencialmente, mas independentemente umas das outras, e o resultado é obtido como a interseção de três conjuntos de estados finais.
Graças a essas mudanças, três tabelas de 16 bytes são suficientes para descrever todas as transições possíveis: cada elemento da tabela é usado como um campo de bits que lista todos os estados finais possíveis. Três desses elementos são unidos por AND e, se houver bits diferentes de zero no resultado, um erro foi detectado.
| Tétrade | Valor | Possíveis erros | O código |
|---|---|---|---|
| Alto no primeiro byte | 0-7 | 2- | 0x01
|
| 8–11 | () | 0x00
|
|
| 12 | 2- ; 2- | 0x06
|
|
| 13 | 2- | 0x02
|
|
| 14 | 2- ; 2- ; | 0x0E
|
|
| 15 | 2- ; ; Unicode; 4- | 0x62
|
|
| 0 | 2- ; 2- ; | 0x37
|
|
| 1 | 2- ; 2- ; 2- | 0x07
|
|
| 2–3 | 2- ; 2- | 0x03
|
|
| 4 | 2- ; 2- ; Unicode | 0x43
|
|
| 5–7 | 0x63
|
||
| 8–10, 12–15 | 2- ; 2- ; | ||
| 11 | 2- ; 2- ; ; | 0x6B
|
|
| 0–7, 12–15 | O segundo byte está faltando; sequência muito longa; Sequência não mínima de 2 bytes | 0x06
|
|
| 8 | 2º byte extra; sequência muito longa; indo além dos limites do Unicode; consistência não mínima | 0x35
|
|
| nove | 0x55
|
||
| 10-11 | 2º byte extra; sequência muito longa; indo além dos limites do Unicode; Sequência não mínima de 2 bytes; substitutos | 0x4D
|
Existem mais 7 sequências de bits inválidas não processadas:
| Seqüência inacabada | 3º byte ausente | 111xxxxx 10xxxxxx 0xxxxxxx
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta 4º byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Sequência não testada | 3º byte extra | 110xxxxx 10xxxxxx 10xxxxxx
|
| 4º byte extra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5º byte extra | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
E aqui o bit mais significativo é útil, prudentemente deixado sem uso nas tabelas de transição: ele corresponderá a uma sequência de bits
10xxxxxx 10xxxxxx
, ou seja, dois bytes consecutivos. Agora, verificar três blocos de notas pode detectar um erro ou fornecer um resultado
0x00
ou
0x80
. E este resultado da primeira verificação - junto com o primeiro caderno - é suficiente para nós:
| 3º byte ausente | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| Falta 4º byte | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| 3º byte extra | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4º byte extra | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5º byte extra | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Combinações permitidas |
|
|
|
||
Isso significa que para completar a verificação, basta verificar se cada resultado
0x80
corresponde a uma das duas combinações válidas.
Vetorização
Como processar blocos de 16 bytes adjacentes em paralelo? A ideia central é usar a instrução
pshufb
como 16 substituições simultâneas de acordo com uma tabela de 16 bytes. Para a segunda verificação, você precisa encontrar no bloco todos os bytes do formulário
111xxxxx
e
1111xxxx
; como não há comparação de vetor sem sinal na Intel, ele é substituído pela subtração de saturação (
psubusb
).
As fontes simdjson são difíceis de ler devido ao fato de que todo o código é dividido em funções de uma linha. Todo o pseudocódigo do validador se parece com isto:
prev = vector(0)
while !input_exhausted:
input = vector(...)
prev1 = prev<<120 | input>>8
prev2 = prev<<112 | input>>16
prev3 = prev<<104 | input>>24
#
nibble1 = prev1.shr(4).lookup(table1)
nibble2 = prev1.and(15).lookup(table2)
nibble3 = input.shr(4).lookup(table3)
result1 = nibble1 & nibble2 & nibble3
#
test1 = prev2.saturating_sub(0xDF) # 111xxxxx => >0
test2 = prev3.saturating_sub(0xEF) # 1111xxxx => >0
result2 = (test1 | test2).gt(0) & vector(0x80)
# result1 0x80 , result2,
#
if result1 != result2:
return false
prev = input
return true
Se uma sequência incorreta estiver localizada na borda direita do último bloco, ela não será detectada por este código. Para não se incomodar, você pode complementar a string de entrada com zero bytes, de modo que no final você obtenha um bloco totalmente zero. Em vez disso, simdjson escolheu implementar uma verificação especial para os últimos bytes: para uma string ser correta, o último byte deve ser estritamente menor
0xC0
, o penúltimo byte estritamente menor
0xE0
e o terceiro do final estritamente menor
0xF0
.
A última das melhorias que Lemierre e Kaiser fizeram é o corte ASCII. Determinar que existem apenas caracteres ASCII no bloco atual é muito simples:
input & vector(0x80) == vector(0)
... Neste caso, é suficiente certificar-se de que não há sequências incorretas no limite
prev
e
input
, - e você pode ir para o próximo bloco. Esta verificação é realizada da mesma forma que no final da string de entrada; a comparação do vetor sem sinal com
[..., 0x0, 0xE0, 0xC0]
, que não está disponível na Intel, é substituída pelo cálculo do máximo do vetor (
pmaxub
) e sua comparação com o mesmo vetor.
A verificação de ASCII acaba sendo a única ramificação dentro da iteração do validador e, para prever essa ramificação com sucesso, é suficiente que a string de entrada não intercale blocos inteiramente ASCII com blocos contendo caracteres não ASCII. Os pesquisadores descobriram que resultados ainda melhores em textos reais podem ser alcançados verificando a concatenação OR de quatro blocos adjacentes para ASCII e pulando todos os quatro blocos no caso de ASCII. De fato, pode-se esperar que se o autor do texto, a princípio, usar caracteres não ASCII, eles ocorrerão pelo menos uma vez a cada 64 caracteres, o que é suficiente para prever a transição.
