No início, os roteadores eram computadores comuns com placas de interface de rede (NICs) conectadas ao barramento.

Figura 1 - Placas de interface de rede conectadas ao barramento.
Até certo ponto, esse sistema funcionou. Nesta arquitetura, os pacotes entraram na NIC e foram transferidos da NIC para a memória pela CPU. A CPU tomou a decisão de encaminhar e enviar o pacote para o NIC externo. CPU e memória são recursos centralizados com suporte limitado a dispositivos. O barramento também era uma limitação adicional: a largura de banda do barramento tinha que suportar a largura de banda de todas as placas de rede ao mesmo tempo.
Se for necessário expandir a rede, os problemas começam a surgir muito rapidamente. Você pode comprar um processador mais rápido, mas como aumentar a potência do barramento? Se você dobrar a velocidade do barramento, será necessário dobrar a velocidade da interface do barramento em cada NIC e CPU. Isso aumenta o custo de todas as placas, mesmo que a capacidade de uma única placa de rede não aumente.
Lição um: o custo de um roteador deve crescer linearmente com seus recursos
Apesar da lição aprendida, uma solução conveniente para upscaling foi adicionar outro barramento e processador:

Figura 2 - A solução para o problema de escalonamento do sistema foi adicionar um novo barramento e processador.
A Arithmetic Logic Unit (ALU) foi um chip de processamento digital de sinal (DSP) escolhido por sua relação preço-desempenho superior. O barramento adicional aumentou a largura de banda, mas a arquitetura não cresceu em escala de qualquer maneira. Em outras palavras, mais ALUs e ônibus não poderiam ter sido adicionados para aumentar a produtividade.
Visto que as ALUs ainda eram uma limitação significativa, a próxima etapa foi adicionar um Field Programmable Gate Array (FPGA) à arquitetura para reduzir a carga de pesquisa Longest Prefix Match (LPM).

Figura 3 - A próxima etapa foi adicionar o Field Programmable Gate Array.
Embora tenha ajudado, não resolveu completamente o problema. ALU ainda estava sobrecarregado. Os LPMs compunham a maior parte da carga, mas a arquitetura centralizada ainda não escalou bem, mesmo se nos livrássemos de parte do problema.
Lição dois: LPM pode ser implementado em silício e não é uma barreira para o desempenho
Apesar dessa lição, o próximo passo foi dado em uma direção diferente: substituir o ALU e o FPGA por um processador padrão. Os designers tentaram aumentar a escala adicionando mais CPUs e mais barramentos. Exigia muito esforço, mesmo para um pequeno aumento de potência, e o sistema ainda sofria com as limitações de largura de banda do barramento centralizado.
Nesse estágio da evolução da Internet, forças mais sérias entraram em ação. À medida que a web se tornou popular entre o público em geral, o potencial da Internet começou a se tornar mais evidente. Telcos adquiriu redes NSFnet regionais e começou a construir complexos comerciais. Os Circuitos Integrados Específicos de Aplicativo (ASICs) tornaram-se tecnologias comprovadas, permitindo que mais funcionalidades sejam implementadas diretamente no silício. A demanda por roteadores disparou e a necessidade de melhorias significativas de escalabilidade finalmente derrotou o conservadorismo da engenharia. Para atender a essa demanda, muitas startups surgiram com uma ampla gama de soluções possíveis.
A barra transversal programada tornou-se uma das alternativas:

Figura 4 - Barra transversal programada.
Nessa arquitetura, cada NIC tinha uma entrada e uma saída. O processador NIC tomou a decisão de encaminhamento, selecionou a NIC de saída e enviou uma solicitação de agendamento para o switch (barra transversal). O agendador recebeu todas as solicitações das NICs, elaborou a solução ideal, programou a solução no switch e direcionou as entradas para transmissão.
O problema com esse esquema era que cada saída podia "ouvir" uma entrada por vez e o tráfego da Internet pulsava. Se dois pacotes precisassem atingir a mesma saída, um deles teria que esperar. A espera por um pacote fazia com que outros pacotes esperassem na mesma entrada, após o que o sistema começou a sofrer de bloqueio de cabeçote de linha (HOLB), resultando em desempenho muito ruim do roteador.
Lição três: a estrutura interna do roteador não deve bloquear sinais mesmo sob condições de carga
A migração para chips especializados também motivou os designers a migrar para estruturas baseadas em células internas, uma vez que trocar células pequenas e de tamanho fixo é muito mais fácil do que lidar com pacotes de comprimento variável, que às vezes são grandes. No entanto, o uso das células de comutação também significava que o escalonador teria que funcionar em uma frequência mais alta, tornando o escalonamento muito mais difícil.
Outra abordagem inovadora foi construir a NIC em um toro:

Figura 5 - NIC em forma de toro.
Nesse esquema, cada NIC tinha conexões com quatro vizinhos, e a NIC de entrada precisava calcular um caminho pela estrutura para chegar à placa de linha de saída. Este sistema teve problemas - a largura de banda não era a mesma. A largura de transmissão na direção norte-sul foi maior do que na direção leste-oeste. Se o padrão de tráfego de entrada se movesse de leste a oeste, ocorreria congestionamento.
Lição quatro: a estrutura interna do roteador deve ter uma distribuição uniforme da largura de banda, porque não podemos prever a distribuição do tráfego.
Uma abordagem completamente diferente foi criar uma rede de comunicações NIC-NIC completa e distribuir células em todas as NICs:
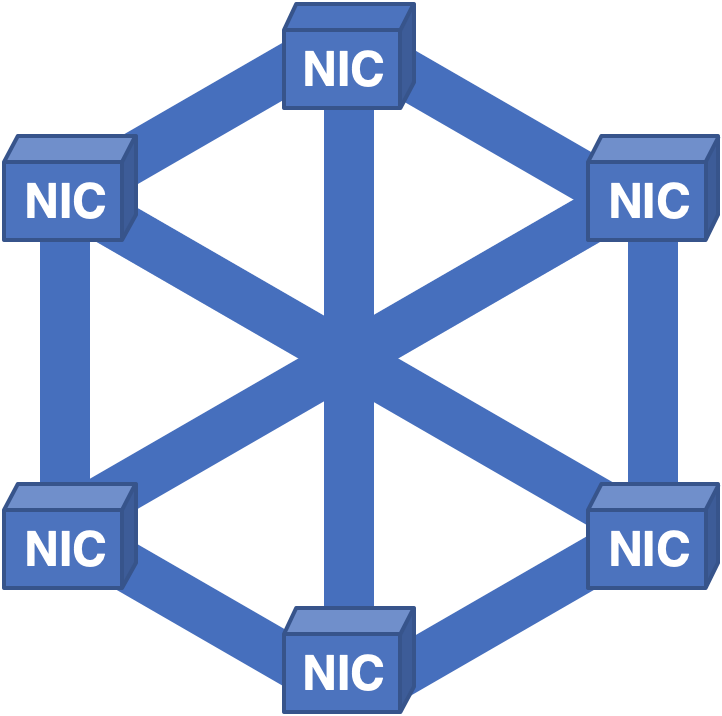
Figura 6 - Estrutura totalmente conectada com distribuição de células para todas as NICs.
Apesar de aprender as lições anteriores, novos problemas foram identificados. Nessa arquitetura, tudo funcionou bem até que foi necessário retirar a placa para conserto. Como cada NIC continha células para todos os pacotes do sistema, quando a placa foi removida, nenhum dos pacotes pôde ser recriado, resultando em um tempo de inatividade curto, mas doloroso.
Lição cinco: os roteadores não devem ter um único ponto de falha
Nós até pegamos essa arquitetura e a viramos de cabeça para baixo:
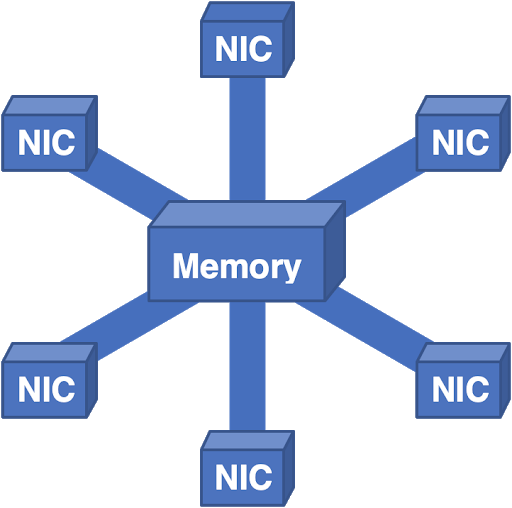
Figura 7 - Aqui todos os pacotes vão para a memória central e depois para a NIC de saída.
Este sistema funcionou muito bem, mas o dimensionamento da memória tornou-se um problema. Você pode apenas adicionar alguns controladores e bancos de memória, mas em algum ponto a largura de banda geral se torna muito complexa para o projeto físico. Confrontados com restrições físicas práticas, fomos forçados a pensar em outras direções.
A rede telefônica se tornou uma fonte de inspiração para nós. Há muito tempo, Charles Close percebeu que switches escalonáveis podiam ser feitos construindo redes de switches menores. No final das contas, todas as propriedades maravilhosas de que precisamos estão presentes na rede Clos:

Figura 8 - Rede fechada.
Fechar propriedades de rede:
- O poder cresce com a escala.
- Não tem um único ponto de falha.
- Mantém redundância suficiente para tolerância a falhas.
- Lida com sobrecargas distribuindo a carga por toda a estrutura.
Sempre implementamos entradas e saídas juntas, então geralmente dobramos essa imagem ao longo da linha pontilhada. Isso resulta em uma rede Clos dobrada, e é isso que usamos hoje em roteadores com vários casos: alguns casos têm uma placa de rede e uma camada de switches, em outros - camadas adicionais de switches.

Figura 9 - Rede fechada recolhida.
Infelizmente, até mesmo essa arquitetura tem seus próprios problemas. O formato das células usadas entre os switches é proprietário e propriedade do fabricante do chip, o que leva à dependência dos chipsets. A dependência de um fornecedor de chip não é muito melhor do que a dependência de um único fornecedor de roteador; os problemas são os mesmos: vincular o preço e a disponibilidade dos dispositivos a uma única fonte. As atualizações de hardware são desafiadoras porque o novo switch de célula deve suportar simultaneamente conexões legadas e formatos de célula para manter a interoperabilidade, bem como todas as taxas de link e formatos de célula de novos equipamentos.
Cada célula deve ser endereçada para indicar a NIC de saída para a qual deve transmitir informações. Esse endereçamento é finito, o que cria um limite de escalabilidade. O controle e o gerenciamento em roteadores de vários casos ainda são totalmente proprietários, causando outro problema de fornecedor único na pilha de software.
Felizmente, podemos resolver esses problemas mudando nossa filosofia de arquitetura. Nos últimos cinquenta anos, temos nos empenhado em dimensionar roteadores. Aprendemos com a experiência da construção de grandes nuvens que a filosofia de scale-out costuma ser mais bem-sucedida.
A arquitetura escalável usa uma estratégia de dividir e conquistar em vez de criar um único servidor enorme e extremamente rápido. Um rack de pequenos servidores pode fazer o mesmo trabalho, sendo mais confiável, flexível e econômico.
Essa abordagem também se aplica a roteadores. É possível pegar vários roteadores pequenos e alinhá-los em uma topologia Clos para obter benefícios arquitetônicos semelhantes e, ao mesmo tempo, evitar problemas relacionados à malha? Como se viu, isso não é particularmente difícil:

Figura 10 - Substituindo switches de célula por switches de pacote, preservando a topologia Clos para facilitar o dimensionamento.
Substituindo os switches de célula por switches de pacote e mantendo a topologia Clos, oferecemos facilidade de escalabilidade.
O escalonamento é possível em duas dimensões: adicionando novos roteadores de ingresso e switches de pacote em paralelo com as camadas existentes ou adicionando camadas de switch adicionais. Como os roteadores individuais são bastante padronizados hoje, evitamos a dependência de um único fornecedor. Todos os links usam Ethernet padrão, portanto, não há problemas de compatibilidade.
As atualizações são diretas e diretas: se o switch precisar de mais canais, você pode simplesmente substituí-lo por um switch maior. Se você precisar atualizar um canal separado e ambas as extremidades do canal tiverem esse recurso, você só precisará atualizar a óptica. Taxas de transmissão diferentes de links diferentes em uma malha não são um problema porque cada roteador atua como um mapeador de taxas.
Essa arquitetura já é popular no mundo dos data centers e, dependendo do número de camadas de switch, é chamada de arquitetura leaf-spine ou super-spine. Ele provou ser altamente confiável, estável e flexível.
Do ponto de vista do plano de transmissão, é claro que esta é uma alternativa viável à arquitetura. Os problemas permanecem com o plano de controle e o plano de controle. O dimensionamento do plano de controle requer uma melhoria de ordem de magnitude na escala de nossos protocolos de controle. Estamos tentando implementá-lo melhorando os mecanismos de abstração, criando uma representação proxy da arquitetura que descreve toda a topologia como um único nó.
Da mesma forma, estamos trabalhando para desenvolver abstrações de plano de controle que nos permitirão controlar toda a estrutura Clos como um único roteador. Este trabalho é feito como um padrão aberto, portanto, nenhuma das tecnologias envolvidas é proprietária.
Ao longo de cinquenta anos, as arquiteturas de roteador evoluíram muito e muitos erros foram cometidos no processo de encontrar soluções de compromisso entre tecnologias diferentes. Obviamente, nossa evolução ainda não está completa. Em cada iteração, abordamos os problemas da geração anterior e descobrimos novos desafios.
Esperançosamente, estudando cuidadosamente nossa experiência passada e atual, podemos avançar em direção a uma arquitetura mais flexível e confiável e criar melhorias futuras sem substituir completamente o hardware.