
Nós, da ForePaaS, temos experimentado DevOps há algum tempo - primeiro como uma equipe e agora em toda a empresa. O motivo é simples: a organização está crescendo. Anteriormente, tínhamos apenas uma equipe para todas as ocasiões. Ela estava envolvida na arquitetura, design e segurança de produtos e era rápida em responder a qualquer problema. Agora estamos divididos em várias equipes por especialização: front-end, back-end, desenvolvimento, operação ...
Percebemos que nossos métodos anteriores não seriam tão eficazes e precisamos mudar algo, mantendo a velocidade sem sacrificar a qualidade e vice-versa versa.
Anteriormente, chamávamos a equipe devops, que, na verdade, fazia operações e também era responsável pelo desenvolvimento no back-end. Uma vez por semana, outros desenvolvedores disseram à equipe de DevOps quais novos serviços precisavam ser implantados na produção. Isso às vezes causava problemas. Por um lado, a equipe de DevOps não entendia realmente o que estava acontecendo com os desenvolvedores, por outro lado, os desenvolvedores não se sentiam responsáveis por seus serviços.
Recentemente, o pessoal do DevOps tem tentado despertar essa responsabilidade nos desenvolvedores - pela disponibilidade, confiabilidade e qualidade do código do serviço. Para começar, precisávamos tranquilizar os desenvolvedores, que ficaram alarmados com a carga que havia caído sobre eles. Eles precisavam de mais informações para diagnosticar problemas emergentes, então decidimos implementar o monitoramento do sistema.
Neste artigo, falaremos sobre o que é monitoramento e como ele é consumido, aprenderemos sobre os chamados quatro sinais de ouro e discutiremos como usar métricas e detalhamento para explorar os problemas atuais.
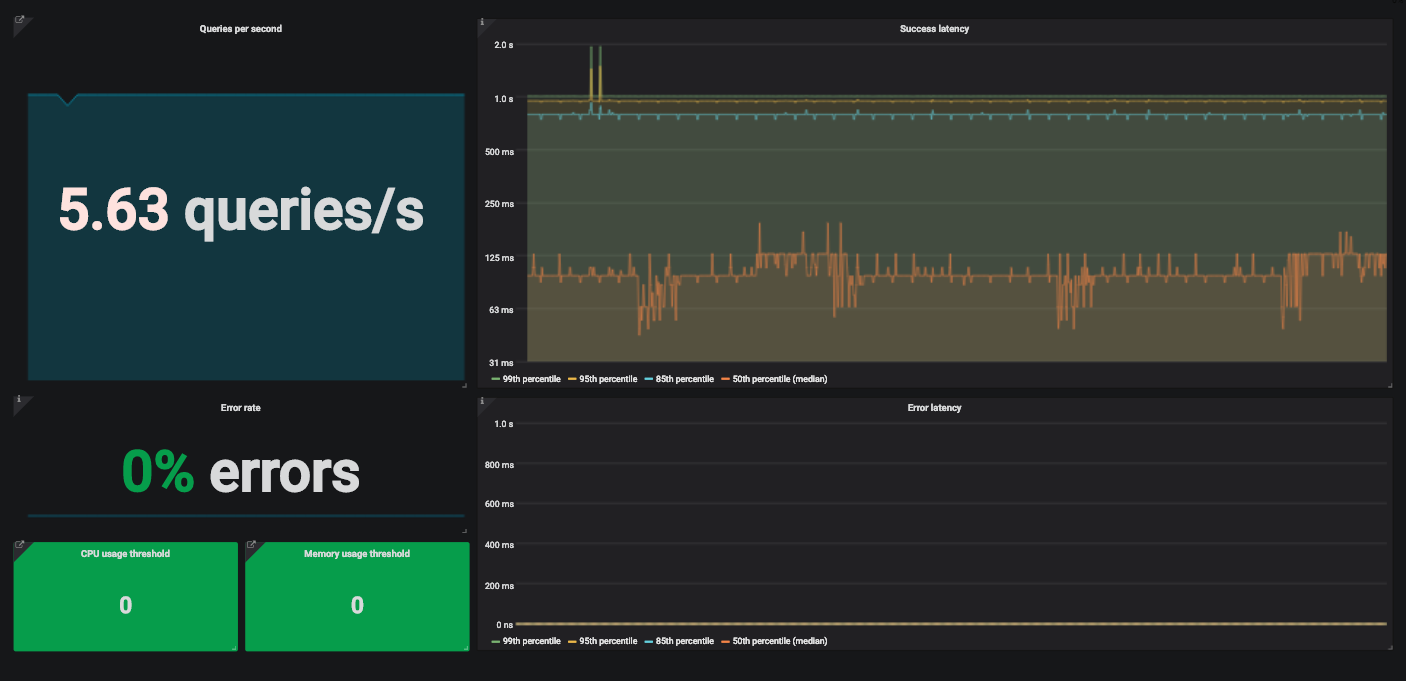
Um exemplo de painel Grafana com quatro sinais dourados para monitorar um serviço.
O que é monitoramento?
Monitoramento é a criação, coleta, agregação e uso de métricas que fornecem informações sobre a integridade de um sistema.
Para monitorar um sistema, precisamos de informações sobre seus componentes de software e hardware. Essas informações podem ser obtidas por meio de métricas coletadas por meio de um programa especial ou instrumentação de código.
A instrumentação está mudando seu código para que você possa medir seu desempenho. Estamos adicionando um código que não afeta a funcionalidade do produto em si, mas simplesmente calcula e fornece métricas. Digamos que queremos medir a latência de uma solicitação. Adicione um código que calculará quanto tempo leva para o serviço processar a solicitação recebida.
A métrica criada dessa forma ainda precisa ser coletada e combinada com outras. Isso geralmente é feito com Metricbeat para coleta e Logstash para indexar métricas no Elasticsearch . Então, essas métricas podem ser usadas para seus próprios fins. Normalmente, essa pilha é complementada por Kibana , que renderiza os dados indexados no Elasticsearch.
Por que monitorar?
Você precisa monitorar o sistema por vários motivos. Por exemplo, monitoramos o status atual do sistema e suas variações para gerar alertas e preencher painéis. Quando recebemos um alerta, procuramos os motivos da falha no painel. Às vezes, o monitoramento é usado para comparar duas versões de um serviço ou analisar tendências de longo prazo.
O que monitorar?
Site Reliability Engineering possui um capítulo útil sobre monitoramento de sistemas distribuídos que descreve a abordagem do Google para rastrear os Quatro Sinais de Ouro.

Beyer, B., Jones C., Murphy, N. & Petoff, J. (2016) Site Reliability Engineering. Como o Google executa sistemas de produção. O'Reilly. Versão online gratuita: https://landing.google.com/sre/sre-book/toc/index.html
- — . . — , .
- — . API . , .
- . (, 500- ) . — , .
- , , . ? . . , , .
?
Veja a pilha de tecnologia, por exemplo. Normalmente escolhemos ferramentas padrão populares em vez de soluções personalizadas. Exceto quando a funcionalidade disponível não for suficiente para nós. Implementamos a maioria dos serviços em ambientes Kubernetes e instrumentamos o código para obter métricas sobre cada serviço personalizado. Para coletar essas métricas e prepará-las para o Prometheus, usamos uma das bibliotecas cliente do Prometheus . Existem bibliotecas cliente para quase todas as linguagens populares. Na documentação, você pode descobrir tudo o que precisa para escrever sua própria biblioteca.
Se for um serviço de código aberto de terceiros, geralmente aceitamos os exportadores sugeridos pela comunidade. Exportadores são o código que coleta as métricas do serviço e as formata para o Prometheus. Eles são normalmente usados com serviços que não geram métricas do Prometheus.
Enviamos as métricas pelo pipeline e as armazenamos no Prometheus como séries temporais. Além disso, usamos kube-state-metrics no Kubernetes para coletar e enviar métricas ao Prometheus. Podemos então criar painéis e alertas no Grafana usando solicitações do Prometheus. Não entraremos em detalhes técnicos aqui, experimente você mesmo essas ferramentas. Eles têm documentação detalhada, você pode descobrir isso facilmente.
Por exemplo, vamos examinar uma API simples que recebe tráfego e processa as solicitações recebidas usando outros serviços.
Atraso
Latência é o tempo que leva para processar uma solicitação. Medimos a latência separadamente para solicitações bem-sucedidas e erros. Não queremos que essas estatísticas se misturem.
A latência geral é geralmente levada em consideração, mas nem sempre é uma boa escolha. Melhor rastrear a distribuição de latência porque está mais de acordo com os requisitos de disponibilidade. A proporção de solicitações processadas mais rápido do que um determinado limite é um indicador de nível de serviço (SLI) comum. Aqui está um exemplo de objetivo de nível de serviço (SLO) para este SLI:
"Em 24 horas, 99% das solicitações devem ser processadas em menos de 1 segundo."
A maneira mais visual de representar as métricas de latência é com um gráfico de série temporal. Colocamos métricas em baldes e os exportadores as coletam a cada minuto. Dessa forma, n-quantis para latências de serviço podem ser calculados.
Se 0 <n <1, e o gráfico contém valores de q, o quantil n deste gráfico é igual a um valor que não excede n * q de valores de q. Ou seja, a mediana, quantil 0,5 de um gráfico com x registros é igual a um valor que não excede a metade de x registros.
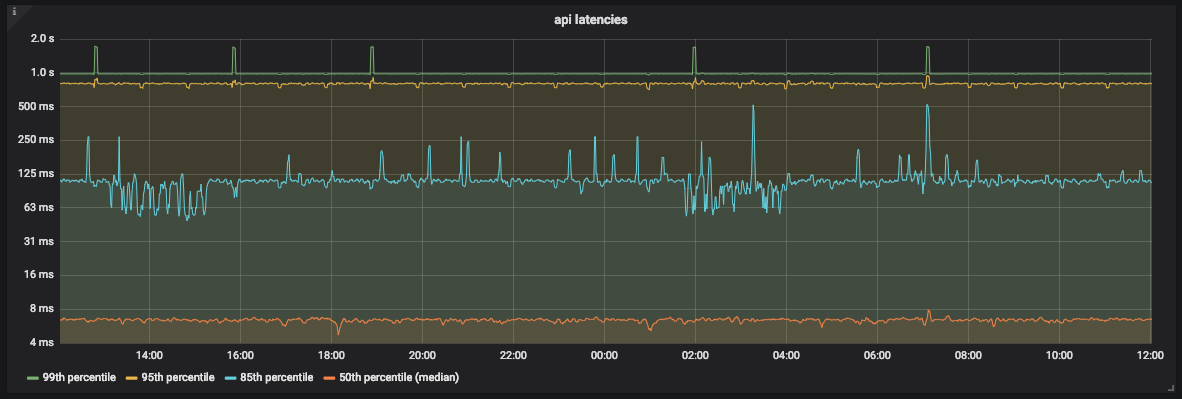
Gráfico de latência da API
Como você pode ver no gráfico, na maioria das vezes a API processa 99% das solicitações em menos de 1 segundo. No entanto, também existem picos em torno de 2 segundos que não correspondem ao nosso SLO.
Como estamos usando o Prometheus, precisamos ter muito cuidado ao escolher o tamanho do balde. O Prometheus permite tamanhos de balde lineares e exponenciais. Não importa o que escolhemos, desde que os erros de estimativa sejam contabilizados .
Prometheus não fornece um valor exato para o quantil. Ele determina em qual intervalo o quantil está e, em seguida, usa a interpolação linear e calcula um valor aproximado.
Tráfego
Para medir o tráfego de uma API, você precisa contar quantas solicitações ela recebe a cada segundo. Como coletamos as métricas uma vez por minuto, não obteremos o valor exato para um segundo específico. Mas podemos calcular o número médio de solicitações por segundo usando as funções de taxa e irado no Prometheus.
Para exibir essas informações, usamos o painel Grafana SingleStat. Ele exibe a média atual de solicitações por segundo e tendências.

Um exemplo de painel Grafana SingleStat com o número de solicitações que nossa API recebe por segundo.
Se o número de solicitações por segundo mudar repentinamente, nós veremos. Se o tráfego for reduzido pela metade em alguns minutos, entenderemos que há um problema.
Erros
É fácil calcular a porcentagem de erros óbvios - divida as respostas HTTP 500 pelo número total de solicitações. Tal como acontece com o tráfego, usamos uma média aqui.
O intervalo deve ser o mesmo do tráfego. Isso tornará mais fácil rastrear o tráfego com erros em um painel.
Digamos que a taxa de erro seja de 10% nos últimos cinco minutos e a API esteja processando 200 solicitações por segundo. É fácil calcular que, em média, ocorreram 20 erros por segundo.
Saturação
Para monitorar a saturação, você precisa definir os limites do serviço. Para a nossa API, começamos medindo os recursos do processador e da memória, porque não sabíamos o que afeta mais. Kubernetes e kube-state-metrics fornecem essas métricas para contêineres.
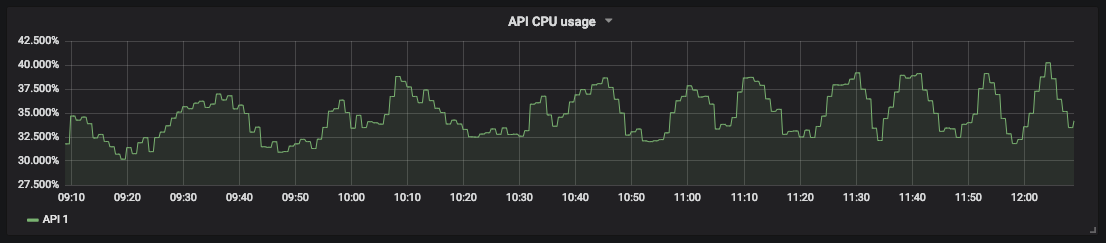
Um gráfico de utilização da CPU para nossa
medição de saturação da API permite prever o tempo de inatividade e agendar recursos. Por exemplo, para armazenamento de banco de dados, você pode medir o espaço livre em disco e a velocidade com que ele está sendo preenchido para saber quando agir.
Painéis detalhados para monitorar serviços distribuídos
Vamos dar uma olhada em outro serviço. Por exemplo, uma API distribuída que atua como proxy para outros serviços. Esta API possui várias instâncias em diferentes regiões e vários terminais. Cada um deles depende de seu próprio conjunto de serviços. Logo se torna bastante difícil ler gráficos com dezenas de linhas. Precisamos ser capazes de monitorar todo o sistema e, se necessário, detectar falhas individuais.
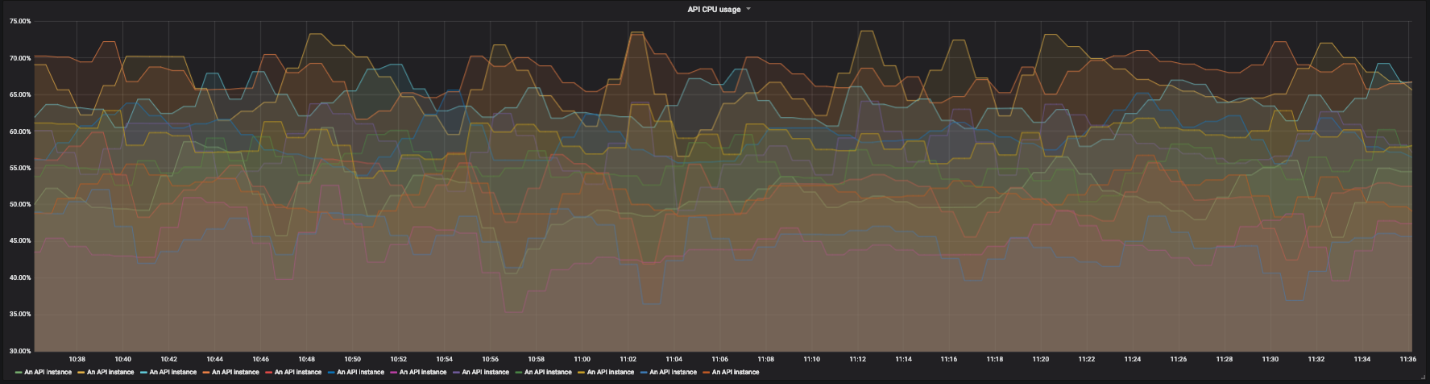
Gráfico de utilização da CPU para 12 instâncias de nossa API
Para isso, usamos painéis detalhados. Em cada tela de um painel, temos uma visão global do sistema e podemos clicar em elementos individuais para examinar os detalhes. Para saturação, não usamos gráficos, mas simplesmente retângulos coloridos mostrando o uso de recursos de processador e memória. Se o uso de recursos exceder o limite especificado, o retângulo ficará laranja.

Indicadores de uso de CPU e memória para
instâncias de API Clique no retângulo, vá para detalhes e veja vários retângulos coloridos representando diferentes instâncias de API.

Indicadores de uso de CPU para instâncias de API
Se apenas uma instância apresentar problema, podemos clicar no retângulo e obter mais detalhes. Aqui vemos a região da instância, solicitações recebidas e assim por diante.

Uma visão granular do estado de uma instância de API. Da esquerda para a direita, de cima para baixo: região do provedor, nome do host da instância, data da última reinicialização, solicitações por segundo, utilização da CPU, utilização da memória, total de solicitações por caminho e porcentagem total de erros por caminho.
Fazemos o mesmo com a porcentagem de erros - clicamos e olhamos a porcentagem de erros para cada terminal da API para entender onde está o problema - na própria API ou nos serviços aos quais ela está associada.
Fizemos o mesmo para atrasos e erros de solicitação bem-sucedidos, embora haja nuances aqui. O objetivo principal é garantir que o serviço seja bom em escala global. O problema é que a API tem muitos terminais diferentes, cada um dos quais depende de vários serviços. Cada endpoint tem seus próprios atrasos e tráfego.
É um incômodo configurar SLOs (e SLAs) separados para cada terminal de serviço. Alguns terminais terão uma latência nominal mais alta do que outros. Nesse caso, a refatoração pode ser necessária. Se SLOs separados forem necessários, você precisará dividir todo o serviço em serviços menores. Talvez possamos ver que a cobertura do nosso serviço era muito ampla.
Decidimos que seria melhor monitorar a latência geral. A granularidade simplesmente permite que o problema seja investigado quando os desvios de latência são tão grandes que atraem a atenção.
Conclusão
Já faz algum tempo que usamos esses métodos para monitorar sistemas e percebemos que o tempo necessário para encontrar problemas e o tempo médio de recuperação (MTTR) diminuíram. O detalhamento nos permite encontrar a causa real de um problema global e, para nós, essa capacidade mudou muito.
Outras equipes de desenvolvimento também começaram a usar esses métodos e veem apenas vantagens neles. Agora eles não são apenas responsáveis pela operação de seus serviços. Eles vão ainda mais longe e podem determinar como as alterações no código afetam o comportamento dos serviços.
Os quatro sinais dourados não resolvem todos os problemas, mas são muito úteis com os mais comuns. Quase sem esforço, conseguimos melhorar significativamente o monitoramento e reduzir o MTTR. Adicione quantas métricas forem necessárias, desde que haja quatro sinais de ouro entre elas.