A infraestrutura tecnológica do Grupo M.Video-Eldorado hoje é muito mais do que uma gigantesca rede de caixas registradoras em mais de 1000 lojas em todo o país. Nos bastidores, temos uma plataforma online que fornece interação com o cliente, aprendizado de máquina, algoritmos de pesquisa inteligente, bots de bate-papo, um sistema de recomendação, automação dos principais processos de negócios e fluxo de documentos eletrônicos. Abaixo do corte, há uma história detalhada sobre o que nos levou a quebrar o monólito em microsserviços.
Lendas da antiguidade profunda
Para que tudo isso funcione como um relógio, precisamos acompanhar o desenvolvimento das tecnologias e atender prontamente às solicitações do negócio. Infelizmente, a funcionalidade básica dos sistemas ERP globais está longe de ser capaz de responder rapidamente às necessidades emergentes dos clientes internos. Em 2016, esse se tornou um dos argumentos a favor da nossa transição para uma arquitetura de microsserviço.
A empresa se deparou com uma tarefa bastante difícil de implementar uma lógica de negócios unificada de trabalhar com vários mecânicos promocionais no processo de colocação de pedidos de clientes em todos os canais de vendas e pontos de contato (na época: site, aplicativo móvel, caixas eletrônicos e terminais em lojas e operadoras em call center).
Ao mesmo tempo, dentro do cenário de TI, tínhamos grandes sistemas monolíticos como a plataforma de comércio eletrônico Oracle ATG, SAP CRM e outros. A repetição da lógica em cada um deles ou a implementação em um e o reaproveitamento em outro da funcionalidade necessária, segundo nossos cálculos, resultou em anos de tempo e dezenas de milhões de investimentos.
Portanto, reunimos uma pequena equipe de desenvolvedores e pessoas tecnicamente competentes que estavam à nossa disposição na época, e pensamos em como poderíamos fazer um serviço separado para as nossas necessidades. No processo de elaboração, percebemos que na verdade não precisamos de uma, mas de três ou quatro ferramentas de trabalho. É assim que chegamos ao conceito de arquitetura de microsserviço pela primeira vez.
Decidimos codificar em Java, pois tínhamos a experiência necessária nisso. Escolhemos a versão 3.2 do Spring. Como resultado, obtivemos uma espécie de micromonólito distribuído em três ou quatro serviços, intimamente interligados entre si. Apesar de terem sido desenvolvidos de forma independente, apenas todos puderam trabalhar juntos.
No entanto, foi um grande salto em termos de desenvolvimento de tecnologia própria. Mudamos do Java 6 para o Java 8, começamos a dominar o Spring 3, movendo-nos suavemente para o Spring 4. Claro, foi um teste específico.
Reduzimos com sucesso o prazo de implementação do projeto de obscuros "meses para desenvolvimento", tendo implementado a lógica de negócios cross-channel necessária em quase dois meses.
Evolução tecnológica
Em 2017-18, iniciamos uma refatoração global do micromonólito. O conceito de desenvolvimento de microsserviços foi apreciado tanto por especialistas em TI quanto por empresas. O fluxo de tarefas de trabalho começou a crescer. Além disso, continuamos a isolar blocos funcionais necessários a diferentes consumidores do cenário de TI corporativo e a traduzi-los nos trilhos dos microsserviços.
Tentamos acompanhar os tempos e pular para o Java 9, mas não fomos coroados de sucesso. Infelizmente, não obtivemos nenhum benefício tangível com este exercício, então ficamos no Java 8. Havia
cada vez mais serviços, eles tinham que ser gerenciados centralmente e trabalhar com eles padronizados. Foi aqui que tentamos a conteinerização pela primeira vez. Os contêineres Docker eram grandes e pesados, com várias centenas de megabytes cada.
Posteriormente, tivemos que resolver problemas com o balanceamento de tráfego e carga nos serviços. Escolhemos Consul para clientes externos e Eureka para internos como solução. Experimentamos diferentes ferramentas de comunicação interserviços gRPC, RMI. Vivemos assim por quase um ano e parecia-nos que aprendemos como criar microsserviços e construir uma arquitetura de microsserviço com sucesso.
Apertem os cintos, estamos nos afogando!
Em 2019, o número de nossos microsserviços aumentou significativamente, ultrapassando a marca de 100+. Aplicamos novas soluções para comunicação interserviços, sempre que possível, tentamos implementar abordagens baseadas em eventos.
Enquanto isso, as questões de orquestração e gerenciamento de dependências estavam se tornando cada vez mais agudas. Mas a maior mudança que nos tocou já no início de 2019 está relacionada à mudança na política da empresa quanto ao uso de Java.
Tínhamos uma escolha do que fazer a seguir: ficar com a Oracle e pagar a eles muito dinheiro, investir em nossa própria construção de jdk aberto ou tentar encontrar algumas alternativas reais.
Escolhemos a terceira opção e juntamente com a BellSoft, que é um dos cinco líderes mundiais envolvidos no desenvolvimento do projeto OpenJDK, após uma série de reuniões e discussões, formamos um plano para a transição e o piloto da nova versão do Java e combinamos isso com a transição direta para Java 11. O processo foi difícil, mas em todos os testes, não sentimos problemas sérios e insolúveis.
A próxima etapa para nós foi a implementação do gerenciamento de contêineres para Kubernetes. Graças a isso, por algum tempo, parecia-nos que estava tudo bem e que alcançamos um grande sucesso. Mas então surgiram os próximos problemas com a infraestrutura. Ela simplesmente não conseguia lidar com o aumento constante da carga.
Simplesmente não tínhamos tempo para escalar. A necessidade das próximas transformações técnicas fundamentais tornou-se óbvia. Então, começamos a olhar para as tecnologias de nuvem e nos esforçar para experimentá-las em nós mesmos.
Eleve-se acima das nuvens
O início de 2020 nos prometeu um grande passo no desenvolvimento de nossas tecnologias internas, compreensão e aprimoramento de nossa arquitetura de microsserviços. Adiante estava um grande passo nas nuvens. Infelizmente, os planos tiveram que ser corrigidos, como dizem, no decorrer da peça.
Devido à pandemia COVID-19, em vez de migrar gradativamente e explorar as possibilidades dos serviços em nuvem, tínhamos toda a empresa em busca de novas ferramentas para atender às necessidades de mudança de nossos clientes devido à pandemia. Na verdade, escrevemos os próximos microsserviços, simultaneamente introduzindo novas tecnologias e ainda mudando para a infraestrutura de nuvem.
Para nós, o tamanho dos contêineres tornou-se crítico por dois motivos simples: é dinheiro pelo poder de computação em nuvem consumido e o tempo que o desenvolvedor e, portanto, toda a empresa gasta levantando contêineres, sincronizando e configurando-os, executando autotestes, e assim por diante. E aqui sentimos plenamente a vantagem e a utilidade de nossos contêineres compactos com o tempo de execução Liberica JDK.
Apesar do auge da pandemia, em poucos meses implementamos e lançamos com sucesso em operação produtiva duas dezenas de microsserviços, inteiramente baseados na infraestrutura em nuvem.
No final de 2020, nos concentramos nas coisas de processo: investimos muito tempo e esforço na construção de uma abordagem de produto, no desenvolvimento de microsserviços, na seleção e formação de equipes separadas com suas próprias métricas e KPIs em torno de várias áreas de unidades de negócios .
Serrar o monólito em microsserviços usando o exemplo do serviço de cálculo de pedido
Para não testar sua paciência, gostaria de demonstrar exemplos específicos e a lógica de trabalhar com uma infraestrutura de microsserviço. Vamos fazer um cálculo de pedido típico em um ambiente de TI padrão.
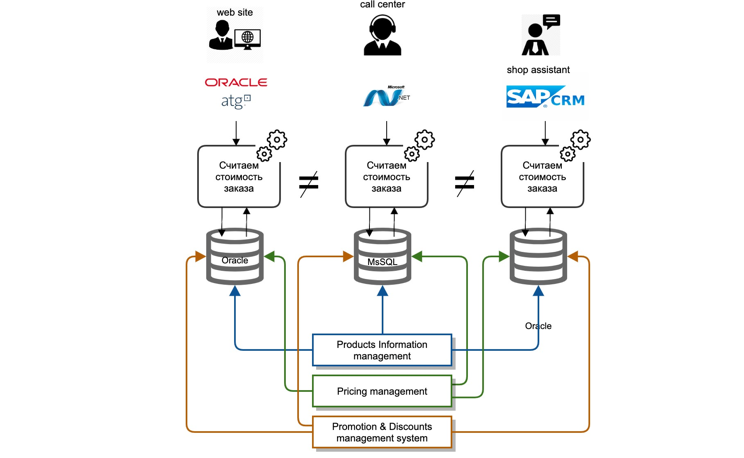
Enfrentamos uma série de desafios. Nossos dados mestres estavam profundamente armazenados nos sistemas do back office. Cada sistema de TI é um monólito clássico: banco de dados, servidor de aplicativos. A integração dos sistemas mestres com os demais participantes do panorama de TI foi realizada como um “ponto a ponto”, ou seja, cada sistema de TI se integrou, à sua maneira e a cada momento.
As integrações eram principalmente de dois tipos: replicação no nível do banco de dados, transferência de arquivos. A lógica de cálculo foi repetida em cada sistema informático separadamente, nomeadamente em diferentes linguagens de desenvolvimento, não havendo como reutilizar sequer o código de uma equipa vizinha.
Era extremamente caro e quase impossível sincronizar a lógica de cálculo simultaneamente em todos os sistemas, devido aos diferentes roteiros e custos de recursos de vários sistemas de TI.
Além disso, ao lidar com reclamações de clientes, era extremamente difícil para nós determinar por que o preço correto ou um ou outro desconto não foi fornecido.
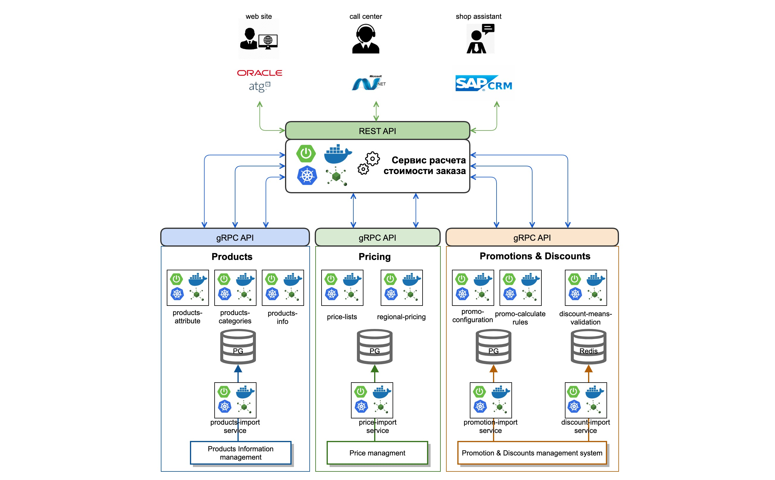
O que nos fizemos? Analisamos e determinamos o contexto necessário para o cálculo correto do valor do pedido. Em seguida, selecionamos domínios de negócios e os dividimos internamente em microsserviços separados. Assim, por exemplo, destacamos dados sobre mercadorias que deveriam ser levados em consideração no processo de cálculo do custo de um pedido.
Implementamos um serviço de importação de dados de sistemas mestres online por meio de filas (Kafka). Além dos dados, implementamos microsserviços atômicos que operam com categorias de produtos e seus atributos (produtos-atributo-serviço, produtos-categorias-serviço). Fizemos o mesmo com os domínios no contexto de Preço e Promoção.
Separadamente, mudamos a lógica e o procedimento de cálculo dos preços dos pedidos para um mecanismo de cálculo de pedidos separado, implementando uma única lógica unificada para calcular preços e custos, usando fundos de desconto e cartões promocionais.
Também implementamos uma API REST padronizada para todos os clientes que implementam a lógica de liquidação de pedidos. Para comunicação interserviços, escolhemos o protocolo gRPC com uma descrição em protobuf3.
Como resultado, um microsserviço padrão hoje se parece com isto: é um aplicativo de inicialização rápida, que é coletado em um contêiner do docker usando GitLab CI e implantado no cluster Kubernetes.
Qual é o resultado final?
No caminho da nossa evolução técnica, em primeiro lugar, revimos a abordagem do processo de desenvolvimento dos próprios serviços e formação de equipas. Focados na abordagem do produto, recrutamos equipes com base nos princípios máximos de autonomia.
Paralelamente, para que as equipas correspondam a domínios e áreas de negócio específicos e, nesse sentido, possam, juntamente com os responsáveis das funções de negócio, participar no desenvolvimento de uma determinada área de negócio.
Em termos de desenvolvimento técnico, escolhemos a conectividade assíncrona usando Kafka, incluindo streams Kafka, como uma das ferramentas de comunicação interserviços. Isso permitiu que as equipes se tornassem praticamente independentes das outras. Também usamos e praticamos ativamente práticas de desenvolvimento reativo, por exemplo, o projeto do reator. Ainda queremos experimentar o projeto Loom.
Para acelerar o desenvolvimento, focamos no desenvolvimento de diversos fatores técnicos e organizacionais que nos permitiram influenciar significativamente o timing.
O aspecto tecnológico é a transição para tecnologias em nuvem, que garantiu a velocidade ideal de automação dos processos de CI \ CD. A velocidade e a duração da regressão completa e implantação de um microsserviço específico são críticas aqui.
Por exemplo, hoje uma execução completa (com todos os tipos de teste de unidade, contratual, integração) CI \ CD Pipeline para um aplicativo de negócios produtivo em funcionamento ─ e isso é cerca de 12-15 microsserviços interconectados) é de cerca de 31 minutos, o que é 7-8 minutos a menos do que os indicadores do início de 2020.
Assim, gastamos cerca de 17-18% menos tempo esperando pelo resultado. Essa economia nos permite realizar outras tarefas de mercearia. Isso se deve em grande parte ao fato de usarmos contêineres compactos baseados no Alpine Linux, que estão ficando mais rápidos e mais leves a cada hora.
Nós nos tornamos mais eficientes em termos de desenvolvimento de microsserviços em geral. E isso tem um efeito positivo na experiência do usuário de nossos clientes. A velocidade é uma das principais métricas de nossos produtos online (site e aplicativos móveis) agora, e o Liberica JDK também nos permite atingir esse ganho, que em termos de desempenho convertemos em uma experiência positiva para nossos clientes.
Além disso, a abordagem certa para o desenvolvimento de microsserviços nos permitiu acelerar significativamente o tempo de lançamento de nosso produto no mercado. Aprendemos como colocar serviços individuais em produção, usando várias estratégias para implantação A \ B, fábrica de conservas e outros, conforme necessário. Isso permite receber rapidamente feedback sobre o trabalho dos microsserviços.
Em dois meses, desenvolvemos e implementamos alguns novos serviços na experiência de compra. Estamos a falar da chamada entrega rápida de mercadorias em 2 horas (utilizamos vários táxis e agregadores de entrega) e da emissão das nossas encomendas nos locais mais inesperados (em lojas Pyaterochka ou Correios russos, mesmo em parques de estacionamento de grandes centros de negócios).
Graças aos nossos microsserviços, alguns dos clientes do Grupo M.Video-Eldorado têm a oportunidade de apanhar um táxi com as suas mercadorias directamente da loja para casa.
Planos criativos
Nossos planos para 2021 incluem o desenvolvimento ativo da infraestrutura em nuvem e a transição inteiramente para o conceito de infraestrutura como código ("infraestrutura como código").
Planejamos prestar muita atenção na construção de soluções transparentes para o controle e interação de microsserviços na forma de uma solução Service Mesh baseada no Istio e Admiral. Temos muito trabalho pela frente para ajustar e melhorar toda a pilha de Observabilidade, monitorar o rastreamento de solicitações e o registro de mensagens.
Também planejamos tentar usar tecnologias sem servidor, incluindo o desejo de experimentá-lo em java. Além disso, existe uma ideia tão distante, mas não aparentemente irreal, de construir uma infraestrutura e um ecossistema com várias nuvens.
Se você está interessado em tocar nossa pilha de tecnologia com as mãos, não hesite, há trabalho suficiente para todos. A inscrição de voluntários é realizada 24 horas por dia, 7 dias por semana: aqui . Você é bem-vindo .
Benefícios, hacks de vida, experiência pessoal

Dmitry Chuiko , arquiteto sênior de desempenho da BellSoft, sobre os segredos de pequenos contêineres Docker para microsserviços Java:
─ . , . Docker-. , : , .
Linux , . JDK. , , .
1.
CentOS CentOS slim. ? Debian. Alpine musl. BellSoft Alpine Linux, — Linux. Liberica JDK 11.0.10 + 11.0.10 Linux.
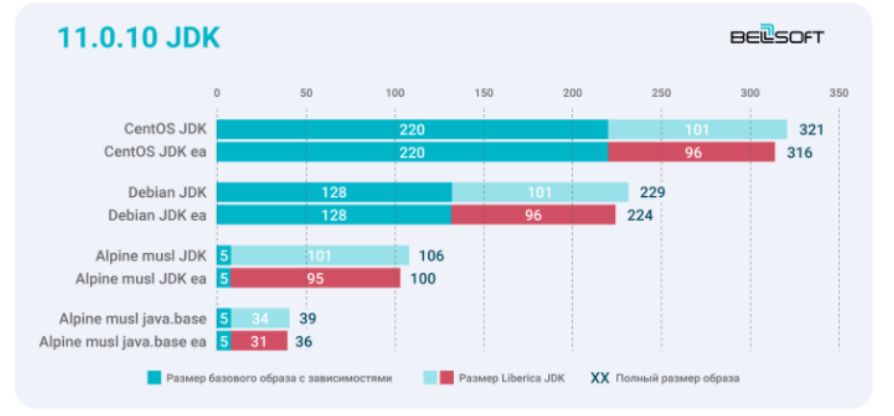
Liberica EA 3–6 14,7 % Alpine musl java.base. 7,6 %. Docker-, JRE java.base. Liberica JRE EA — 16 %.
Liberica Lite . , , — . - Java SE JVM, Standart, JIT- (C1, C2, Graal JIT Compiler), (Serial, Parallel, CMS, G1, Shenandoah, ZGC) serviceability, .
2. JDK
— jdeps JLINK. . Java (JDeps). - Java, . . JAR, , . JDeps JDK, Java-. , , .

jdeps , java.base. jlink. , BellSoft Docker- java.base. DockerHub, .
docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
CLI-like java.base. Liberica JDK Lite Alpine Linux musl 40,4 .
.
Enjoy!