Olá pessoal. Estamos entrando na reta final: hoje é o artigo final sobre o que a ciência de dados pode fornecer para prever o COVID-19.
O primeiro artigo está aqui . O segundo está aqui .
Hoje estamos conversando com Alexander Zhelubenkov sobre suas decisões para prever a disseminação do COVID-19.
Nossas condições são as seguintes:
Dadas : Capacidades colossais de ciência de dados, três especialistas talentosos.
Encontre : Maneiras de prever a propagação do COVID-19 com uma semana de antecedência.
E aqui está a decisão de Alexander Zhelubenkov
- Alexander, olá. Primeiro, conte-nos um pouco sobre você e seu trabalho.
- Trabalho na Lamoda como chefe do grupo de análise de dados e aprendizado de máquina. Estamos empenhados em um motor de busca e algoritmos para classificar os produtos no catálogo. A ciência de dados me interessou quando eu estava estudando na Universidade Estadual de Moscou na Faculdade de Matemática Computacional e Cibernética.
- Conhecimento e habilidades foram úteis. Você fez um modelo de qualidade: simples o suficiente para não ser superdimensionado. Como você conseguiu isso?
- O problema da previsão de séries temporais é bem estudado e as abordagens que podem ser aplicadas a ele são compreensíveis. Em nossa tarefa, as amostras são muito pequenas para os padrões de aprendizado de máquina - vários milhares de observações nos dados de treinamento e apenas 560 previsões precisam ser feitas para cada semana (previsão para 80 regiões para cada dia da semana seguinte). Nesses casos, modelos mais grosseiros são usados e funcionam bem na prática. Na verdade, acabei com uma linha de base limpa.
Como modelo, usei o aumento de gradiente nas árvores. Você pode notar que os modelos prontos para uso não sabem como prever tendências, mas se mudarmos para metas incrementais, será possível prever a tendência. Acontece que você precisa ensinar o modelo a prever quanto o número de casos aumentará em relação ao dia atual nos próximos X dias, onde X de 1 a 7 é o horizonte de previsão.
Outra característica foi que a qualidade das previsões do modelo foi avaliada em escala logarítmica, ou seja, a penalidade não foi pelo quanto você errou, mas por quantas vezes as previsões do modelo se mostraram imprecisas. E isso teve o seguinte efeito: a qualidade final das previsões para todas as regiões foi muito influenciada pela precisão das previsões em pequenas regiões.
Os cronogramas para cada região eram conhecidos: o número de casos em cada um dos dias no passado e, literalmente, algumas características qualitativas, como população e proporção de residentes urbanos. Basicamente, isso é tudo. É difícil treinar novamente esses dados se for normal fazer a validação e determinar onde vale a pena parar no treinamento de reforço.
- Que biblioteca de aumento de gradiente você usou?
- Estou à moda antiga - XGBoost. Eu sei sobre LightGBM e CatBoost, mas para tal tarefa, me parece que a escolha não é tão importante.
- OK. Mas ainda assim o alvo. O que você tomou como alvo? É o logaritmo da relação de dois dias ou o logaritmo do valor absoluto?
- Como meta, peguei a diferença nos logaritmos do número de casos. Por exemplo, se hoje houver 100 casos e amanhã houver 200, então, ao fazer a previsão com um dia de antecedência, você precisa aprender a prever o logaritmo do crescimento duplo.
Em geral, sabe-se que nas primeiras semanas ocorre um aumento exponencial da propagação do vírus. Isso significa que se usarmos incrementos em uma escala logarítmica como metas, então, de fato, será possível prever uma constante multiplicada pelo horizonte de previsão todos os dias. O aumento de gradiente é um modelo versátil e lida bem com essas tarefas.
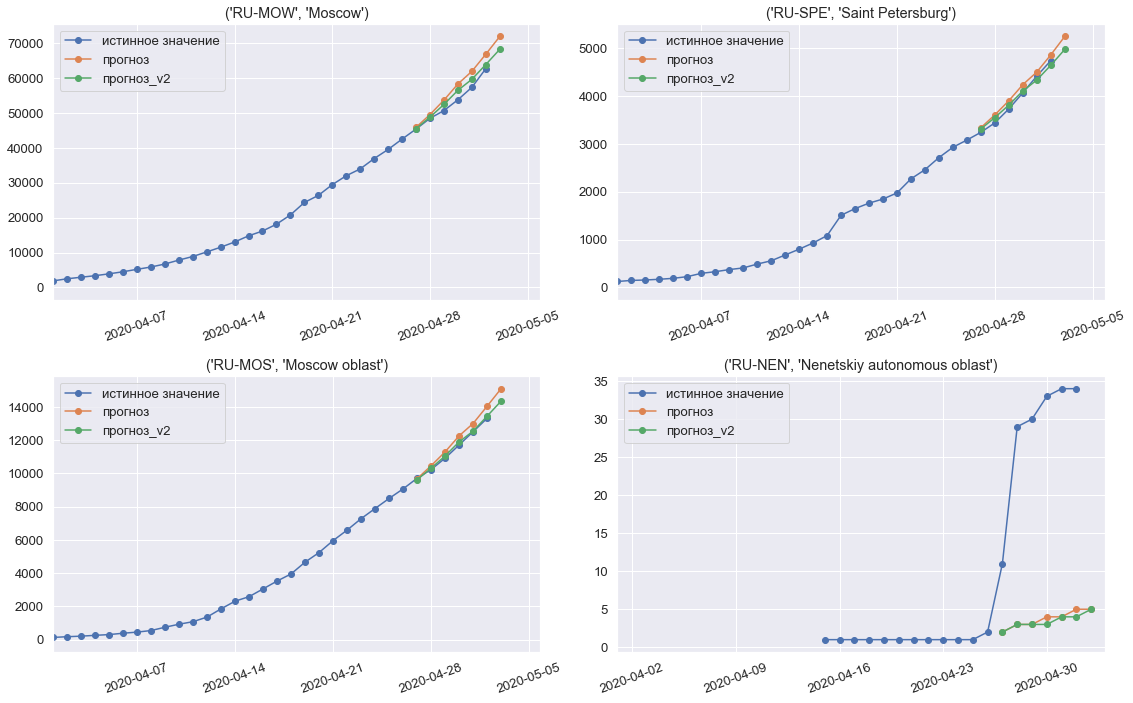
Predições modelo para a terceira semana final da competição
- Que amostra de treinamento você tirou?
- Para prever regiões, peguei informações sobre distribuição por país. Parece que isso ajudou, pois em algum lugar já o crescimento acentuado foi desacelerando, e os países começaram a entrar no planalto. Nas regiões da Rússia, cortei o período inicial, quando havia alguns casos isolados. Para o treinamento, usei dados de fevereiro.
- Como você é validado?
- Validado no tempo, como para séries temporais e como é normal fazer. Usei as últimas duas semanas para o teste. Se prevermos a última semana, então, para o treinamento, usaremos todos os dados anteriores. Se prevermos o penúltimo, usaremos todos os dados, sem as últimas duas semanas.
- Você usou outra coisa? Alguns dias, 10 ou 20 dias, o que significa a partir daí?
- Os principais fatores que foram importantes foram estatísticas diferentes: médias, mediana, aumentos nos últimos N dias. Para cada região, pode ser calculado separadamente. Você também pode adicionar os mesmos fatores separadamente, calculados apenas para todas as regiões de uma vez.
- Pergunta sobre validação. Você está procurando mais estabilidade ou precisão? Qual foi o critério?
- Observei a qualidade média do modelo, que foi obtida nas últimas duas semanas selecionadas para validação. Ao adicionar alguns fatores, obtivemos uma imagem que com uma configuração de boost fixo e variando apenas o parâmetro de semente aleatório, a qualidade das previsões poderia saltar muito - ou seja, uma grande variação foi obtida. Para não treinar novamente e obter um modelo mais estável, no final não usei esses fatores duvidosos no modelo final.
- O que você lembra? Surpreso? Um recurso que funcionou ou algum tipo de truque de reforço?
- Aprendi duas lições. Primeiro, quando decidi combinar dois modelos: linear e boosting, e ao mesmo tempo, para cada região, os coeficientes com os quais esses dois modelos foram tomados (eles acabaram sendo diferentes) foram simplesmente configurados na última semana - ou seja, por sete dias. Na verdade, configurei 1-2 coeficientes para cada região por 7 dias. Mas a descoberta foi esta: a previsão acabou sendo muito pior do que se eu não tivesse feito essas configurações. Em algumas regiões, o modelo foi fortemente retreinado e, como resultado, as previsões neles revelaram-se ruins. Na terceira fase da competição, decidi não fazer isso.
E o segundo ponto: parece que o número de dias a partir do início deve ser útil como característica: desde o primeiro doente, desde o décimo doente. Tentei adicioná-los, mas na validação isso piorou a situação. Expliquei desta forma: a distribuição dos valores nas amostras muda com o tempo. Se você estudar no 20º dia a partir do início da propagação do vírus, então ao prever a distribuição dos valores deste recurso irá avançar sete dias, e, talvez, isso não permita que tais fatores sejam usados com beneficiar.
- Você disse que a proporção da população urbana teve algum papel. E o que mais?
- Sim, a parcela da população urbana de ambos os países e regiões da Rússia sempre foi usada. Esse fator deu um pequeno impulso consistente à qualidade das previsões. Como resultado, além da própria série temporal, não incluí mais nada no modelo final. Tentei adicionar diversos, mas não funcionou.
- Qual a sua opinião: SARIMA é o século passado?
- Modelos de autorregressivos - média móvel - são mais difíceis de configurar, e é mais caro adicionar fatores adicionais a eles, embora eu tenha certeza que com modelos (S) ARIMA (X) seria possível fazer boas previsões, mas não tão bom quando comparado ao aumento.
- E por mais de uma semana você pode fazer previsões, o que você acha?
- Seria interessante. Inicialmente, os organizadores tiveram a ideia de coletar previsões de longo prazo. O mês parece um ponto de virada em que você ainda pode tentar as abordagens que eu fiz.
- O que você acha que vai acontecer depois?
- Precisamos reconstruir o modelo, olha. A propósito, minha solução pode ser encontrada aqui:
github.com/Topspin26/sberbank-covid19-challenge Para as
últimas notícias de ciência de dados COVID da comunidade internacional, visite https://www.kaggle.com/tags/covid19 . E, claro, nós o convidamos para o canal #coronavirus em opendatascience.slack.com (convidado por ods.ai ).