O que há de errado com o TargetEncoder da biblioteca category_encoders?
Este artigo é uma continuação do artigo anterior , que explicou como a codificação probabilística objetiva realmente funciona. Neste artigo, veremos em quais casos a solução padrão da biblioteca category_encoders dá um resultado incorreto e, além disso, estudaremos a teoria e o exemplo de código para a codificação objetiva-probabilística multiclasse correta. Vai!
1. Quando o TargetEncoder está errado?
Dê uma olhada nestes dados. A cor é uma característica e um objetivo é ... um objetivo. Nosso objetivo é codificar a cor com base no alvo.

Vamos fazer a codificação objetivo-probabilística usual para isso.
import category_encoders as ce
ce.TargetEncoder(smoothing=0).fit_transform(df.Color,df.Target)
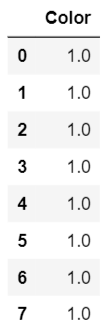
Hmm ... não parece bom, não é? Todas as cores foram alteradas para 1. Por quê? Isso ocorre porque o TargetEncoder obtém a média de todos os valores de destino para cada cor, não a probabilidade.
Embora o TargetEncoder funcione corretamente quando você tem um destino binário com 0 e 1, ele falhará em dois casos:
Quando o destino é binário, mas não 0/1 (pelo menos, por exemplo, 1 e 2).
Quando o alvo é uma multiclasse como no exemplo acima.
Então o que fazer ?!
Teoria
, n . , . n , . n-1 , , . - , , .
.
.
1: - .
enc=ce.OneHotEncoder().fit(df.Target.astype(str)) y_onehot=enc.transform(df.Target.astype(str)) y_onehot
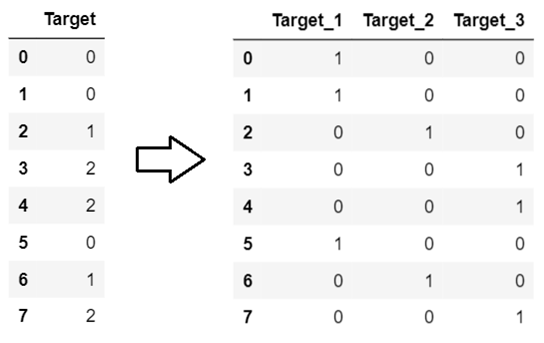
, Target_1 0 Target. 1 Target 0, 0 . Target_2 1 Target.
2: , .
class_names = y_onehot.columns
for class_ in class_names:
enc = ce.TargetEncoder(smoothing = 0)
print(enc.fit_transform(X,y_onehot[class_]))
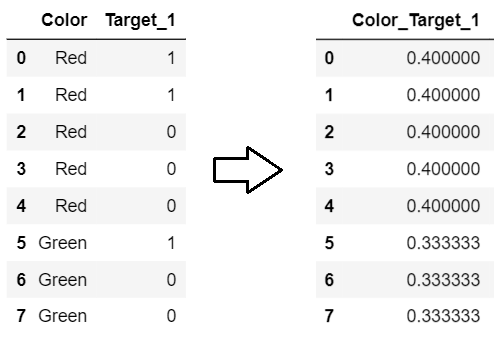
0
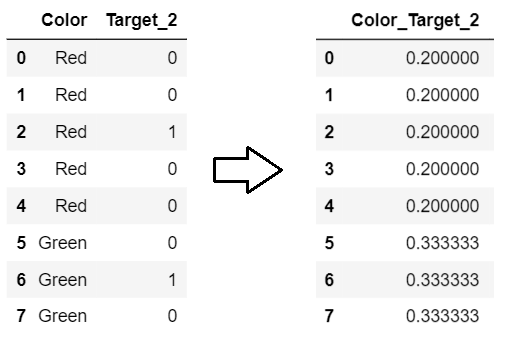
1

2
3: , , 1 2 .
!
, :

, Color_Target. , , . , , , Color_Target_3 ( - ) .
, ?!
Abaixo está uma função que recebe como entrada uma tabela de dados e um objeto de rótulo de destino do tipo Series. A função df pode ter variáveis numéricas e categóricas.
def target_encode_multiclass(X,y): #X,y are pandas df and series
y=y.astype(str) #convert to string to onehot encode
enc=ce.OneHotEncoder().fit(y)
y_onehot=enc.transform(y)
class_names=y_onehot.columns #names of onehot encoded columns
X_obj=X.select_dtypes('object') #separate categorical columns
X=X.select_dtypes(exclude='object')
for class_ in class_names:
enc=ce.TargetEncoder()
enc.fit(X_obj,y_onehot[class_]) #convert all categorical
temp=enc.transform(X_obj) #columns for class_
temp.columns=[str(x)+'_'+str(class_) for x in temp.columns]
X=pd.concat([X,temp],axis=1) #add to original dataset
return X
Resumo
Neste artigo, mostrei o que há de errado com o TargetEncoder da biblioteca category_encoder, expliquei o que o artigo original diz sobre a segmentação de variáveis multiclasse, demonstrei tudo com um exemplo e forneci um código modular funcional que você pode conectar ao seu inscrição.