O artigo é direcionado a iniciantes como eu.
Começar
Primeiro, vamos dar uma olhada no problema. Peguei um site de notícias pouco conhecido sobre Israel, já que eu mesmo moro neste país, e quero ler notícias sem publicidade e sem notícias interessantes. E assim, há um site onde as notícias são postadas: há notícias marcadas em vermelho, e há notícias comuns. Aqueles que são comuns não são nada interessantes, e aqueles marcados em vermelho são o próprio suco. Considere nosso site.
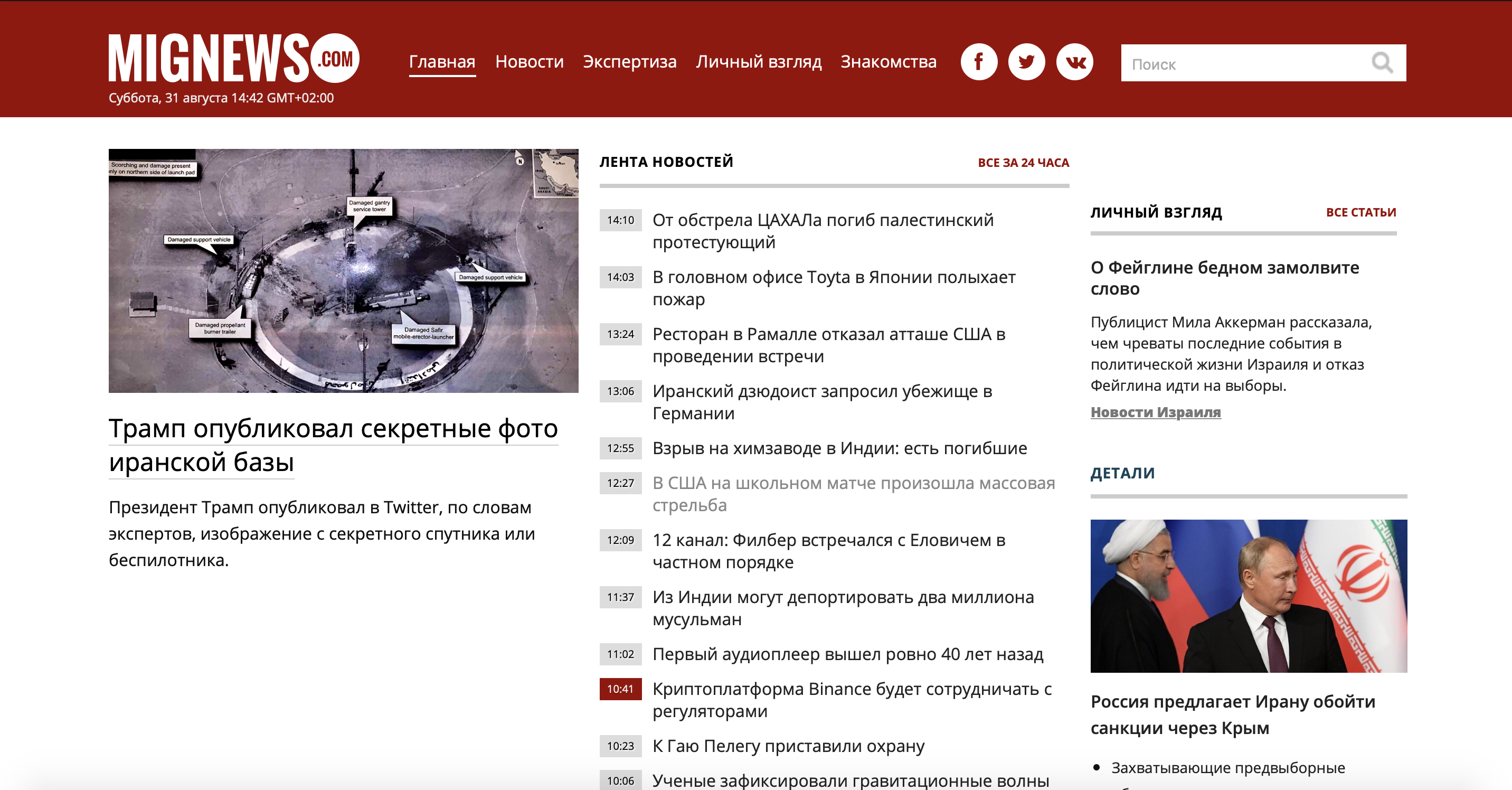
Como você pode ver, o site é grande o suficiente e há muitas informações desnecessárias, mas só precisamos usar o container de notícias. Vamos usar a versão móvel do site
para economizar o mesmo tempo e esforço.

Como você pode ver, o servidor nos deu um lindo contêiner de notícias (que, aliás, é mais do que no site principal, que está a nosso favor) sem anúncios e sem lixo.
Vamos dar uma olhada no código-fonte para entender com o que estamos lidando.

Como você pode ver, cada notícia encontra-se separadamente na tag 'a' e tem a classe 'lenta'. Se abrirmos a tag 'a', notaremos que dentro dela há uma tag 'span', que contém a classe 'time2' ou 'time2 time3', bem como o tempo de publicação, e após fechar a tag, vemos o próprio texto da notícia.
O que separa notícias importantes de notícias sem importância? A mesma classe 'time2' ou 'time2 time3'. Notícias marcadas como 'time2 time3' são nossas notícias vermelhas. Uma vez que a essência da tarefa é clara, vamos prosseguir para a prática.
Prática
Para trabalhar com analisadores, pessoas inteligentes criaram a biblioteca "BeautifulSoup4", que tem muito mais funções interessantes e úteis, mas mais sobre isso da próxima vez. Também precisamos da biblioteca Requests, que nos permite enviar várias solicitações http. Vamos baixá-los.
(certifique-se de ter a versão mais recente do pip)
pip install beautifulsoup4
pip install requests
Vá para o editor de código e importe nossas bibliotecas:
from bs4 import BeautifulSoup
import requests
Primeiro, vamos salvar nosso URL em uma variável:
url = 'http://mignews.com/mobile'
Agora vamos enviar uma solicitação GET () ao site e salvar os dados recebidos na variável 'page':
page = requests.get(url)
Vamos verificar a conexão:
print(page.status_code)
O código nos retornou o código de status '200', o que significa que estamos conectados com sucesso e que tudo está em ordem.
Agora vamos criar duas listas (explicarei para que servem mais tarde):
new_news = [] news = []
É hora de usar o BeautifulSoup4 e alimentá-lo com nossa página, indicando entre aspas como ele nos ajudará 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")
Se você pedir a ele para mostrar o que salvou lá:
print(soup)
Vamos obter todo o código html de nossa página.
Agora vamos usar a função de pesquisa no BeautifulSoup4:
news = soup.findAll('a', class_='lenta')
Vamos dar uma olhada mais de perto no que escrevemos aqui.
Na lista de 'notícias' criada anteriormente (à qual prometi retornar), salve tudo com a tag 'a' e a classe 'notícias'. Se pedirmos para enviar para o console tudo o que encontrou, ele nos mostrará todas as notícias que estavam na página:

Como você pode ver, junto com o texto das notícias, as tags 'a', 'span', as classes ' lenta 'e' time2 ', e também' time2 time3 ', em geral, tudo o que ele achou de acordo com nossos desejos.
Vamos continuar:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
Aqui, em um loop for, iteramos sobre toda a nossa lista de notícias. Se nas notícias sob o índice [i] encontrarmos a tag 'span' e a classe 'time2 time3', então salvamos o texto desta notícia na nova lista 'new_news'.
Observe que estamos usando '.text' para reformatar as linhas em nossa lista do 'bs4.element.ResultSet' que BeautifulSoup usa para suas pesquisas em texto simples.
Uma vez que fiquei preso neste problema por um longo tempo devido a um mal-entendido de como funcionam os formatos de dados e por não saber como usar o debug, tome cuidado. Assim, agora podemos salvar esses dados em uma nova lista e usar todos os métodos das listas, pois agora este é um texto comum e, em geral, fazer com ele o que quisermos.
Vamos exibir nossos dados:
for i in range(len(new_news)):
print(new_news[i])
Aqui está o que obtemos:

temos tempo de postagem e apenas notícias interessantes.
Em seguida, você pode construir um bot no carrinho e carregar essas notícias lá, ou criar um widget em sua área de trabalho com as notícias atuais. Em geral, você pode descobrir uma maneira conveniente de saber mais sobre as notícias.
Esperamos que este artigo ajude os novatos a entender o que pode ser feito com analisadores e os ajude a avançar um pouco em seu aprendizado.
Obrigado por sua atenção, fiquei feliz em compartilhar minha experiência.