No entanto, escrever programas inteiramente em linguagem assembly não é apenas longo, enfadonho e difícil, mas também um tanto bobo - porque abstrações de alto nível foram inventadas para esse propósito, para reduzir o tempo de desenvolvimento e simplificar o processo de programação. Portanto, na maioria das vezes, funções bem otimizadas tomadas separadamente são escritas em linguagem assembly, que são então chamadas de linguagens de nível superior, como C ++ e C #.
Com base nisso, o ambiente de programação mais conveniente será o Visual Studio, que já inclui MASM. Você pode conectá-lo a um projeto C / C ++ através do menu de contexto do projeto Build Dependencies - Build Customizations ..., marcando a caixa ao lado de masm, e os próprios programas assembler serão localizados em arquivos com o .asm extensão (nas propriedades das quais o Tipo de item deve ser definido como Microsoft Macro Assembler). Isso permitirá não apenas compilar e chamar programas em linguagem assembly sem gestos desnecessários - mas também realizar depuração de ponta a ponta, "caindo" na fonte do assembler diretamente de c ++ ou c # (incluindo o ponto de interrupção dentro da lista de montagem) , bem como rastrear o estado dos registradores junto com as variáveis usuais na janela Watch.
Realce de sintaxe
O Visual Studio não possui realce de sintaxe integrado para assembler e outras realizações da estrutura IDE moderna; mas pode ser fornecido com extensões de terceiros.
AsmHighlighter é historicamente o primeiro com funcionalidade mínima e conjunto de comandos incompleto - não apenas o AVX está faltando, mas também alguns dos padrões, em particular o fsqrt. Este fato me levou a escrever minha própria extensão -
ASM Advanced Editor . Além de destacar e recolher seções de código (usando comentários "; [", "; [+" e ";]"), ele vincula dicas a registros que aparecem ao passar o mouse sobre o código (também por meio de comentários). Se parece com isso:
;rdx=
ou assim:
mov rcx, 8;=
Dicas para comandos também estão presentes, mas em uma forma experimental - descobriu-se que levará mais tempo para preenchê-los completamente do que para escrever a própria extensão.
Também de repente descobriu-se que os botões usuais para anotar / comentar a seção destacada do código pararam de funcionar. Portanto, tive que escrever outra extensão em que esta funcionalidade estivesse pendurada no mesmo botão, e a necessidade desta ou daquela ação fosse automaticamente selecionada.
Asm cara- apareceu um pouco depois. Nele, o autor foi por outro caminho e concentrou seus esforços na referência de comando embutida e no preenchimento automático, incluindo tags de rastreamento. O dobramento de código também está presente lá (de acordo com "#region / #end region"), mas parece não haver vinculação de comentários a registradores ainda.
32 vs. 64
Desde que a plataforma de 64 bits apareceu, tornou-se a norma escrever 2 versões de aplicativos. É hora de parar com isso! Quanto legado você pode extrair. O mesmo se aplica às extensões - você só pode encontrar um processador sem SSE2 em um museu - além disso, sem SSE2 os aplicativos de 64 bits não funcionarão. Não haverá prazer de programação se você escrever 4 variantes de funções otimizadas para cada plataforma.
A vantagem da plataforma de 64 bits não está nos registros "largos" - mas no fato de que o número desses registros dobrou - 16 peças cada, tanto de uso geral quanto XMM / YMM. Isso não apenas simplifica a programação, mas também reduz significativamente os acessos à memória.
FPU
Se antes não havia nenhum lugar sem FPU, tk. funções com números reais deixaram o resultado no topo da pilha, então em uma plataforma de 64 bits a troca ocorre sem sua participação usando os registradores xmm da extensão SSE2. A Intel também recomenda ativamente descartar FPUs em favor de SSE2 em suas diretrizes. No entanto, há uma ressalva: FPU permite que você execute cálculos com precisão de 80 bits - o que em alguns casos pode ser crítico. Portanto, o suporte de FPU não foi a lugar nenhum e definitivamente não vale a pena considerá-lo como uma tecnologia desatualizada. Por exemplo, o cálculo da hipotenusa pode ser feito "de frente" sem medo de transbordar,
nomeadamente
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
A principal dificuldade na programação da FPU é a organização da pilha. Para simplificar, um pequeno utilitário foi escrito que gera comentários automaticamente com o estado atual da pilha (foi planejado adicionar funcionalidade semelhante diretamente à extensão principal para realce de sintaxe - mas nunca chegamos a isso)
Exemplo de otimização: transformada de Hartley
Os compiladores C ++ modernos são inteligentes o suficiente para vetorizar código automaticamente para tarefas simples, como somar números em uma matriz ou vetores rotativos, reconhecendo os padrões correspondentes no código. Portanto, obter um ganho significativo de desempenho em tarefas primitivas não é algo que não funcionará - pelo contrário, pode acontecer que seu programa superotimizado execute mais devagar do que o que o compilador gerou. Mas você também não deve tirar conclusões de longo alcance disso - assim que os algoritmos se tornam um pouco mais complicados e não óbvios para a otimização, toda a magia de otimizar compiladores desaparece. Ainda é possível obter um aumento de dez vezes no desempenho por meio da otimização manual em 2021.
Então, como uma tarefa, pegamos o algoritmo (lento) Transformações de Hartley :
o código
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
Também é bastante trivial para vetorização automática (veremos mais tarde), mas dá um pouco mais de espaço para otimização. Bem, nossa versão otimizada será semelhante a esta:
código (comentários removidos)
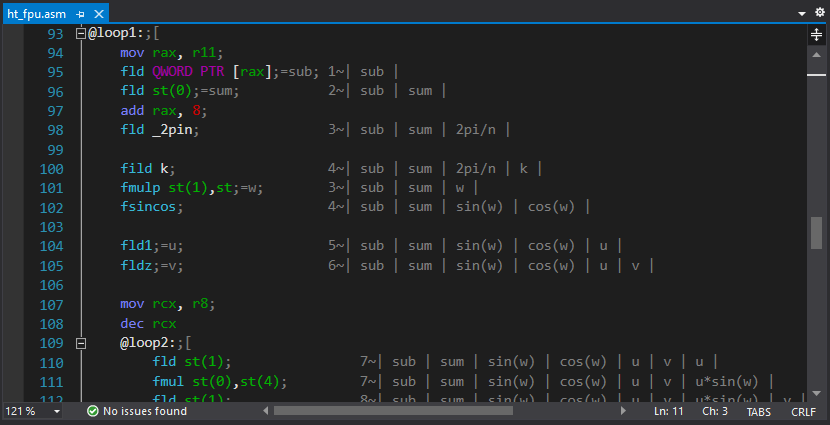
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Observação: não há desenrolamento de loop, sem SSE / AVX, sem tabelas de cosseno, sem redução de complexidade devido ao algoritmo de transformação "rápida". A única otimização explícita é o cálculo iterativo de seno / cosseno no loop interno do algoritmo diretamente nos registradores FPU.
Por se tratar de uma transformação integral, além da velocidade, também nos interessa a precisão do cálculo e o nível de erros acumulados. Neste caso, é muito simples calculá-lo - fazendo duas transformações consecutivas, devemos obter (em teoria) os dados iniciais. Na prática, serão um pouco diferentes, e será possível calcular o erro através do desvio padrão do resultado obtido do analítico.
Os resultados da otimização automática de um programa c ++ também podem depender muito das configurações dos parâmetros do compilador e da escolha de um conjunto de instruções estendidas válido (SSE / AVX / etc). No entanto, existem duas nuances:
- Os compiladores modernos tendem a calcular tudo o que é possível na fase de compilação - portanto, é bem possível no código compilado, ao invés do algoritmo, ver um valor pré-calculado, que, ao medir o desempenho, dará ao compilador uma vantagem de 100.500 vezes. Para evitar isso, minhas medições usam a função externa zero (), que adiciona ambigüidade aos parâmetros de entrada.
- « AVX» — , AVX. . – , AVX .
O parâmetro de otimização mais interessante é o modelo de ponto flutuante, que usa valores precisos | estritos | rápidos. No caso do Fast, o compilador pode fazer quaisquer transformações matemáticas a seu critério (incluindo cálculos iterativos) - de fato, apenas neste modo ocorre a vetorização automática.
Portanto, compilador do Visual Studio 2019, framework de destino AVX2, modelo de ponto flutuante = preciso. Para torná-lo ainda mais interessante, ele medirá a partir de um projeto c # em uma matriz de 10.000 elementos:
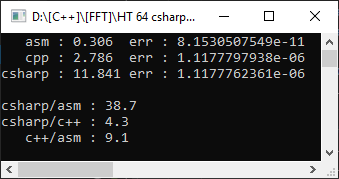
C #, como esperado, acabou sendo mais lento do que C ++, e a função montadora acabou sendo 9 vezes mais rápida! No entanto, é muito cedo para se alegrar - vamos definir o modelo de ponto flutuante = rápido:

Como você pode ver, isso ajudou a acelerar significativamente o código e o atraso da otimização manual foi de apenas 1,8 vezes. Mas o que não mudou é o erro. Que a outra opção deu um erro de 4 dígitos significativos - e isso é importante em cálculos matemáticos.
Nesse caso, nossa versão acabou sendo mais rápida e precisa. Mas nem sempre é o caso - e escolhendo FPU para armazenar os resultados, inevitavelmente perderemos a possibilidade de otimização por vetorização. Além disso, ninguém proíbe combinar FPU e SSE2 nos casos em que faz sentido (em particular, usei essa abordagem na implementação da aritmética duplo-duplo , tendo recebido um aumento de 10 vezes durante a multiplicação).
A otimização posterior da transformada de Hartley encontra-se em um plano diferente e (para um tamanho arbitrário) requer o algoritmo Bluestein, que também é crítico para a precisão dos cálculos intermediários. Bem, este projeto pode ser baixado no GitHub e, como bônus, também há algumas funções para somar / escalar arrays para FPU / SSE2 / AVX (para fins educacionais).
O que ler
Literatura sobre montador em massa. Mas existem várias fontes principais:
1. Documentação oficial da Intel . Nada supérfluo, a probabilidade de erros de digitação é mínima (que são onipresentes na literatura impressa).
2. Diretório online obtido da documentação oficial.
3. Site de Agner Fogh , um especialista em otimização reconhecido. Também contém exemplos de código C ++ otimizado usando intrínsecos.
4. SIMPLESMENTE FPU .
5.40 Práticas Básicas em Programação em Linguagem Assembly .
6. Tudo o que você precisa saber para começar a programar para versões de 64 bits do Windows .
Apêndice: Por que não usar apenas o Intrinsics?
Texto oculto
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.