
GTA Online é conhecido por sua baixa velocidade de carregamento. Tendo lançado recentemente o jogo para completar novas missões de ataque, fiquei chocado ao descobrir que carregava tão lentamente quanto quando foi lançado há sete anos.
A hora chegou. Por enquanto, descubra as razões para isso.
Serviço de inteligência
Para começar, queria verificar se alguém já havia resolvido esse problema. A maioria dos resultados encontrados consistia em dados anedóticos sobre como o jogo era difícil , que teve que carregar por tanto tempo, histórias sobre a fraqueza da arquitetura de rede p2p (e isso é verdade), formas complexas de carregar no modo de história e em seguida, em uma única sessão e pares de mods que permitiram pular o vídeo de abertura com o logotipo R *. Algumas fontes relataram que quando todos esses métodos são usados juntos, você pode economizar até 10-30 segundos!
Enquanto isso, no meu PC ...
Benchmark
: 1 10
-: 6
, R* ( social club ).
, : AMD FX-8350
SSD: KINGSTON SA400S37120G
: 2 Kingston 8192 (DDR3-1337) 99U5471
GPU: NVIDIA GeForce GTX 1070
Eu sei que meu carro está desatualizado, mas por que diabos o modo online carrega seis vezes mais devagar? Não consegui encontrar nenhuma diferença na técnica de upload “primeiro a história, depois online”, como outros fizeram antes de mim . Mas mesmo que funcionasse, os resultados estariam dentro da margem de erro.
Eu não estou sozinho
De acordo com esta enquete , o problema é tão generalizado que enfurece um pouco mais de 80% da base de jogadores. Caras da R *, na verdade já se passaram sete anos!

18,8% dos jogadores têm os computadores ou consoles mais potentes, 81,2% estão muito tristes, 35,1% estão muito tristes.
Depois de procurar por 20% desses sortudos cujo carregamento leva menos de três minutos, encontrei uma série de benchmarks com PCs de jogos poderosos e um tempo de carregamento on-line de cerca de dois minutos. Para obter um tempo de carregamento de dois minutos, eu
Como é que as pessoas que fazem esses benchmarks ainda levam cerca de um minuto para carregar o modo de história? (A propósito, o benchmark com M.2 não leva em consideração o tempo de exibição dos logotipos no início.) Além disso, o carregamento do modo de história para o modo online leva apenas um minuto, enquanto o meu leva mais de cinco. Eu sei que a técnica deles é muito melhor do que a minha, mas definitivamente não cinco vezes.
Medições muito precisas
Armado com ferramentas poderosas como o Gerenciador de Tarefas , comecei a investigar para descobrir quais recursos podem ser o gargalo.
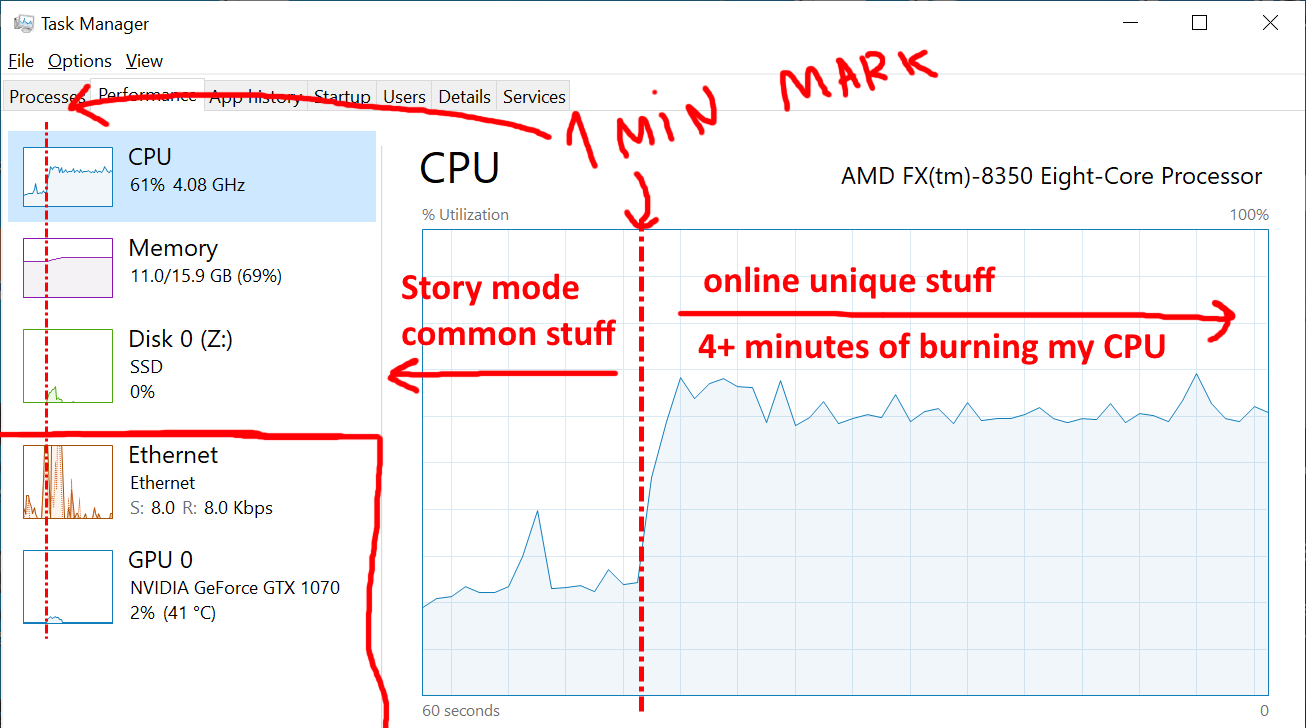
Em um minuto, os recursos padrão do modo de história são carregados, após o que o jogo carrega o processador por mais de quatro minutos.
Após um minuto carregando os recursos compartilhados usados nos modos história e online (um indicador quase igual aos benchmarks de PCs poderosos), GTA decide carregar um núcleo da minha máquina tanto quanto possível por quatro minutos e não fazer mais nada.
Acesso ao disco? Ele não está lá! Uso da rede? Não são muitos, mas depois de alguns segundos o tráfego cai para quase zero (exceto para o carregamento de banners rotativos com informações). Uso da GPU? Por zeros. Uso de memória? Gráfico perfeitamente plano ...
O que está acontecendo, o jogo está minando uma criptografia ou algo assim? Começa a cheirar a código. Código muito ruim .
Limitando um fluxo
Embora meu antigo CPU AMD tenha oito núcleos e ainda possa funcionar bem, ele foi construído nos velhos tempos. Naquela época, o desempenho de thread único dos processadores AMD estava muito aquém do desempenho dos processadores Intel. Isso pode não explicar toda a diferença nos tempos de carregamento, mas deve explicar o mais importante.
O estranho é que o jogo usa apenas a CPU. Eu esperava uma grande quantidade de recursos carregados do disco ou um monte de solicitações de rede para criar uma sessão na rede p2p. Mas isso? Provavelmente é um bug.
Profiling
Profilers são uma ótima maneira de encontrar gargalos de CPU. Há apenas um problema - a maioria deles usa código-fonte para obter uma imagem perfeita do que está acontecendo no processo. E eu não tenho. Mas também não preciso de leituras com precisão de microssegundos - o gargalo dura quatro minutos.
A amostragem de pilha entra em cena: esta é a única maneira de explorar aplicativos de código fechado. Realizamos um despejo de pilha do processo em execução e a localização do ponteiro do comando atual para construir uma árvore de chamada em intervalos especificados. Então, nós os somamos para obter estatísticas sobre o que está acontecendo. Só conheço um criador de perfil (posso estar errado aqui) que pode fazer isso no Windows. E não é atualizado há mais de dez anos. Este é Luke Stackwalker! Deixe alguém dar seu amor a este projeto.

Os culpados # 1 e # 2.
Luke geralmente agrupa as mesmas funções, mas como não tenho símbolos de depuração, preciso examinar os endereços mais próximos com meus olhos para entender que eles são o mesmo lugar. E o que vemos? Não um, mas dois gargalos!
No buraco do coelho
Tendo pegado emprestada uma cópia perfeitamente legítima do popular desmontador de um amigo (não, não posso pagar ... terei que aprender ghidra de alguma forma ), comecei a desmontar o GTA.
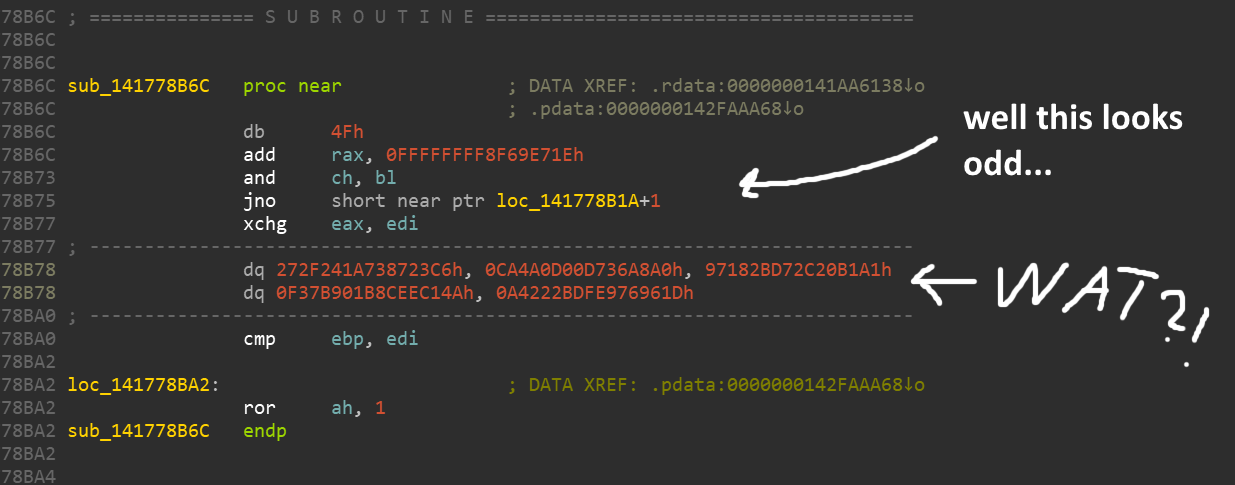
Tudo parece completamente errado. Muitos jogos de alto orçamento têm proteção de engenharia reversa integrada para proteger contra piratas, trapaceiros e modders (para não dizer que isso os impede).
Parece que algum tipo de ofuscação / criptografia é usado aqui, devido ao qual a maioria dos comandos são substituídos por rabiscos. Mas não se preocupe, só precisamos nos livrar da memória do jogo quando executamos a parte que queremos aprender. Antes de sua execução, os comandos devem ser desofuscados de uma forma ou de outra. Eu tinha o Process Dump por perto , mas existem muitas outras ferramentas por aí que podem fazer coisas semelhantes.
Problema nº 1: isso é ... strlen?!
Desmontar o despejo agora menos ofuscado revela que um dos endereços tem uma etiqueta tirada do nada! É isso
strlen
? O próximo na pilha de chamadas é marcado como
vscan_fn
, após o qual os rótulos acabam, no entanto, tenho quase certeza que sim
sscanf
.
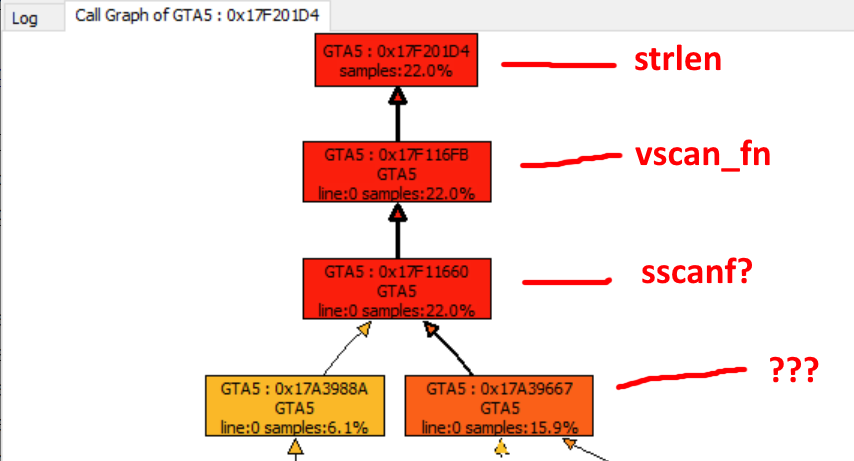
Eles raspam alguma coisa. Mas o que? Analisar o código desmontado levaria infinito, então decidi descartar alguns exemplos do processo em execução usando x64dbg . Depois de um pouco de depuração, descobri que isso é ... JSON! Eles analisam JSON. Espantosos 10 megabytes de dados JSON com quase 63 mil itens .
...,
{
"key": "WP_WCT_TINT_21_t2_v9_n2",
"price": 45000,
"statName": "CHAR_KIT_FM_PURCHASE20",
"storageType": "BITFIELD",
"bitShift": 7,
"bitSize": 1,
"category": ["CATEGORY_WEAPON_MOD"]
},
...
O que é isso? De acordo com algumas fontes, isso se parece com dados de um "diretório de loja online". Assumirei que eles contêm uma lista de todos os itens e atualizações possíveis que podem ser adquiridos no GTA Online.
Esclarecimento: acredito que esses itens sejam comprados com dinheiro do jogo e não diretamente relacionados a microtransações .
Mas 10 megabytes é uma bagatela! E o uso
sscanf
pode não ser ideal, mas não pode ser tão ruim? Nós vamos ...

10 megabytes de strings C na memória. 1. Mova o ponteiro alguns bytes para o próximo valor. 2. Nós ligamos
sscanf(p, "%d", ...)
. 3. Lemos cada caractere em 10 megabytes enquanto lemos cada pequeno valor (!?). 4. Retorne o valor escaneado.
Sim, vai demorar muito ... Para ser honesto, eu não tinha ideia do que
sscanf
chamavam a maioria das implementações
strlen
, então não posso culpar o desenvolvedor que escreveu isso. Eu sugeriria que esses dados são simplesmente escaneados byte por byte e o processamento pode parar em
NULL
.
Problema nº 2: vamos usar um hash ... array?
Descobriu-se que o segundo culpado está sendo chamado diretamente ao lado do primeiro. Ambos são até chamados na mesma declaração
if
, como pode ser entendido nesta descompilação feia:

Ambos os problemas estão dentro de um grande loop de análise de todos os itens. O problema nº 1 é analisar, o problema nº 2 é salvar.
Todos os rótulos são especificados por mim, não tenho ideia de como as funções e parâmetros são realmente chamados.
Qual é o segundo problema? Imediatamente após o item ser analisado, ele é salvo em uma matriz (ou em uma lista incorporada de C ++? Não totalmente claro) Cada item se parece com isto:
struct {
uint64_t *hash;
item_t *item;
} entry;
Mas o que acontece antes de salvar? O código verifica todo o array, elemento por elemento, comparando o hash do item para ver se ele está na lista. Se meus cálculos estiverem corretos, então com cerca de 63 mil elementos isso dá
(n^2+n)/2 = (63000^2+63000)/2 = 1984531500
checagem. A maioria deles é inútil. Temos hashes exclusivos , então por que não usar um mapa de hash ?

O criador de perfil mostra que as duas primeiras linhas estão carregando o processador. A instrução
if
é executada apenas no final. A penúltima linha insere o assunto.
Na engenharia reversa, dei um nome a essa estrutura
hashmap
, mas é óbvio que é
not_a_hashmap
. E então tudo fica melhor. Este hash / array / lista está vazio antes de carregar JSON. E todos os itens em JSON são únicos! O código nem precisa verificar se o item está na lista! Existe até uma função para inserir itens diretamente, basta usá-la! Sério, que porra é essa !?
Prova de conceito
Isso tudo é ótimo, é claro, mas ninguém vai me levar a sério até que eu teste para que eu possa escrever um título clickbait para uma postagem.
Qual é o plano? Escreva
.dll
, injete o GTA dela, intercepte várias funções, ???, PROFIT!
O problema JSON é confuso e substituir o analisador seria extremamente demorado. É muito mais realista tentar substituí-lo
sscanf
por uma função da qual não dependa
strlen
. Mas existe uma maneira ainda mais fácil.
- interceptar strlen
- espere por uma longa fila
- "Cache" seu início e comprimento
- se for chamado novamente dentro da string, retorna o valor em cache
Algo assim:
size_t strlen_cacher(char* str)
{
static char* start;
static char* end;
size_t len;
const size_t cap = 20000;
// if we have a "cached" string and current pointer is within it
if (start && str >= start && str <= end) {
// calculate the new strlen
len = end - str;
// if we're near the end, unload self
// we don't want to mess something else up
if (len < cap / 2)
MH_DisableHook((LPVOID)strlen_addr);
// super-fast return!
return len;
}
// count the actual length
// we need at least one measurement of the large JSON
// or normal strlen for other strings
len = builtin_strlen(str);
// if it was the really long string
// save it's start and end addresses
if (len > cap) {
start = str;
end = str + len;
}
// slow, boring return
return len;
}
Quanto ao problema da matriz hash, é mais fácil de lidar - você pode simplesmente ignorar completamente as verificações de duplicação e inserir itens diretamente, porque sabemos que os valores são únicos.
char __fastcall netcat_insert_dedupe_hooked(uint64_t catalog, uint64_t* key, uint64_t* item)
{
// didn't bother reversing the structure
uint64_t not_a_hashmap = catalog + 88;
// no idea what this does, but repeat what the original did
if (!(*(uint8_t(__fastcall**)(uint64_t*))(*item + 48))(item))
return 0;
// insert directly
netcat_insert_direct(not_a_hashmap, key, &item);
// remove hooks when the last item's hash is hit
// and unload the .dll, we are done here :)
if (*key == 0x7FFFD6BE) {
MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);
unload();
}
return 1;
}
Fontes completas de prova de conceito podem ser encontradas aqui .
resultados
Então, como funcionou?
Tempo de carregamento inicial para o modo online: cerca de 6 minutos
Tempo com apenas verificações duplicadas corrigidas: 4 minutos e 30 segundos
Tempo apenas com patch do analisador JSON: 2 minutos 50 segundos
Tempo com correções de ambos os problemas: 1 minuto 50 segundos
(6 * 60 - (1 * 60 + 50)) / (6 * 60) = tempo de carregamento reduzido em 69,4% (ótimo!)
Oh sim, como funcionou!
Provavelmente, isso não diminuirá o tempo de carregamento para todos os jogadores - pode haver outros gargalos em outros sistemas, mas esse é um problema tão óbvio que não entendo como R * não percebeu isso todos esses anos.
tl; dr
- Há um afunilamento de CPU ao iniciar o GTA Online devido à execução de thread único
- Acontece que o GTA está lutando para analisar um arquivo JSON de 10 MB neste momento.
- O próprio analisador JSON é mal escrito / implementado de forma ingênua e
- Após a análise, um procedimento lento é executado para verificar se não há itens duplicados
R * por favor resolva o problema
Por favor, se este artigo de alguma forma chegar à Rockstar, não demorará mais de um dia para um desenvolvedor corrigir esses problemas. Por favor, faça algo a respeito.
Você pode alternar para o hashmap para eliminar duplicatas ou pular essa verificação, o que será mais rápido. No analisador JSON, substitua a biblioteca por uma mais eficiente. Não acho que haja uma solução mais fácil aqui.
Obrigado.