Olá pessoal. Continuamos esta série de artigos sobre o que a ciência de dados pode fornecer para prever o COVID-19. O primeiro artigo está aqui . Hoje falaremos sobre a segunda classe de modelos para prever a dinâmica de disseminação do COVID-19. Eles baseiam-se em suposições sobre um aumento da incidência e descrevem a situação a médio e longo prazo. Estamos conversando com Nikolay Kobalo, engenheiro sênior de dados da CFT.
Vamos relembrar quais são as nossas condições:
Dadas: Colossais capacidades de ciência de dados, três especialistas talentosos.
Encontre: Maneiras de prever a propagação de COVID-19 uma semana antes.
Vamos passar para a segunda solução.
- Kolya, olá. Diga-nos qual modelo você usou para resolver este problema.
- Peguei um dos modelos que, na minha opinião, mais se adequa à ocasião. O modelo é apresentado na forma de uma equação diferencial e consiste em quatro funções:
1. O número de pessoas suscetíveis à infecção por esta infecção;
2. O número de portadores, ou seja, pessoas que já foram infectadas, mas ainda não sabem;
3. O número de pessoas doentes que infectam outras pessoas;
4. O número de recuperados.
Como você pode ver, este modelo não leva em consideração a mortalidade por covid. Você pode ver os detalhes do modelo no meu github: https://github.com/rerf2010rerf/COVID-19-forecast/blob/master/public.ipynb
O modelo é denominado SEIR e pertence a uma família de modelos compartimentados que descrevem a propagação de uma epidemia. Os modelos desta família permitem descrever diferentes tipos de infecções. Por exemplo, aqueles para os quais a imunidade foi desenvolvida (ou, pelo contrário, não foi desenvolvida). Ou aqueles que têm (ou não têm) período de incubação. No caso do COVID-19, usei um modelo com período de incubação e a imunidade que era produzida em pessoas que já estavam doentes.
Todos os modelos polígamos são sistemas de equações diferenciais de primeira ordem. Para SEIR, eles são assim:

Aqui:
S (t) - (Susceptível) - o número de pessoas suscetíveis à infecção.
E (t) - (Exposto) - o número de operadoras, ou seja, pessoas infectadas nas quais a doença ainda não se manifestou devido ao período de incubação.
I (t) - (Infeccioso) - infectado.
R (t) - (Recuperado) - recuperado.
N = S + E + I + R - tamanho da população. Ele permanece constante, ou seja, presume-se que ninguém morre da doença.
µ é a taxa de mortalidade natural.
α é o recíproco do período de incubação da doença.
γ é o inverso do tempo médio de recuperação.
β é o coeficiente de intensidade dos contatos que levam à infecção.
O ciclo de vida de um indivíduo no modelo SEIR é assim:

Uma pessoa saudável, mas ainda não doente (Susceptível) pode ser infectada por uma pessoa infectada (Infecciosa). A probabilidade de uma pessoa saudável se infectar é descrita pelo parâmetro β.
Uma pessoa infectada entra em um estado de portador de infecção (Exposta). Portadores são pessoas em que a doença ainda não se manifestou, ou seja, possuem um período de incubação. As operadoras não podem infectar ninguém. A transição de pessoas suscetíveis a doenças para o estado de portadores é descrita pelas duas primeiras equações do modelo (usando o termo β (I / N)).
Após 1 / α dias (período de incubação) após a infecção, o portador entra no estado infectado (Infeccioso).
Após 1 / γ dias (tempo de recuperação), a pessoa infectada entra no estado Recuperado. A pessoa recuperada desenvolve imunidade e não pode mais contrair a infecção.
O modelo também prevê a mortalidade natural da população na população. A mortalidade no modelo SEIR é equilibrada pela fecundidade, de modo que a população total não muda. Ao mesmo tempo, o número de pessoas recuperadas diminuirá na população, pois os recém-nascidos não terão imunidade. Conseqüentemente, o número de pessoas que se recuperaram na população diminui com o tempo. A taxa de mortalidade é descrita pelo parâmetro μ.
- Você tem coeficientes no modelo. Então, você fez alguma suposição?
- Uma das minhas suposições era que a mortalidade natural da população pode ser negligenciada, ou seja, μ = 0. Esta suposição parece válida, uma vez que queremos prever a propagação da infecção em um curto período de tempo, apenas alguns meses.
Além disso, o modelo escolhido pressupõe que aqueles que se recuperaram tornam-se imunes à infecção, ou seja, não podem ser infectados novamente.
- E é assim, por falar nisso?
- Parece que sim. Várias reinfecções já foram registradas, mas na maioria das vezes isso não acontece. Portanto, podemos dizer que é assim.
- E qual é o seu “fator de intensidade de contato”?
“Aqui me refiro à intensidade com que as pessoas entram em contato umas com as outras e se infectam. Grosso modo, essa é a probabilidade de que, quando duas pessoas se encontram, onde uma está infectada e a outra não, a segunda eventualmente adoece.
- Quanto custa isso? Perto de um?
- Não, selecionei este parâmetro de acordo com os dados. Depende do nível de auto-isolamento. Por exemplo, se uma grande parte da população não entra em contato com outras pessoas, então o coeficiente torna-se mais baixo, e se a população se comunica ativamente entre si, então ele cresce.
- OK. Você também tem um tempo de recuperação? Alfa e gama?
- Tomei o alfa igual a 1 / 5.1, este era um parâmetro conhecido para COVID-19 (o parâmetro inverso do período de incubação em dias). E eu selecionei a gama de acordo com os dados. Este é o "tempo de convalescença". Aliás, a “intensidade dos contatos” também é baseada nos dados.
- Ah bem. Então, novamente, você pode nos dizer quais suposições são feitas pelos modelos? O que cada equação significa?
- A primeira equação descreve a mudança no número de suscetíveis à infecção. Em particular, o terceiro termo diz que quanto mais intensos são os contatos entre infectados e suscetíveis, mais rápido diminui o número de suscetíveis. Além disso, se alguém foi infectado e depois ficou infectado, ele não está mais incluído neste número. No início da epidemia, é igual ao número de pessoas na população.
Então, o número de portadores é retirado daqueles suscetíveis à infecção, ou seja, uma pessoa se comunica com uma pessoa infectada, torna-se infectada e se torna portadora da infecção. Isso é descrito na segunda equação. Diz que a taxa de crescimento dos portadores é tanto maior quanto mais intensos são os contatos entre os suscetíveis e os infectados, e, ao contrário, quanto menos, menos portadores sobram no momento.
A terceira equação diz que a taxa de crescimento dos infectados é tanto maior quanto mais portadores existem agora (que se transformam em infectados), e quanto menos, mais infectados já existem.
A quarta equação descreve a taxa de crescimento daqueles que se recuperaram, que é quanto maior, quanto mais infectados (quem consegue se recuperar), e quanto menos, mais recuperados já estão.
- Parece uma descrição da evolução da situação.
- Na verdade, existem modelos diferentes. Este é o modelo SEIR, e existe o SIR, no qual não há suscetibilidade à infecção. Existem modelos com mais parâmetros. Existe um modelo que prevê mortalidade por infecção, mas não usei.
- Onde você encontrou este modelo?
- Pesquisei. Existe um artigo na Wikipedia. Artigos adicionais encontrados.
- Você também apresentou os gráficos.
- Este gráfico é um exemplo. Não é baseado em dados reais. Isso apenas mostra como o modelo se comporta. Ela prevê que todos eventualmente ficarão doentes e ficarão curados.

- Ok, então você pegou tudo, e depois?
- Peguei os dados que estão disponíveis por país. Ele presumiu que a taxa de mortalidade é zero. Reescreva as diferenças na forma de diferenças finitas:

Como um operador de diferença finita nesta solução, uma diferença de dois lados é usada.
O número de pessoas recuperadas R por dia está nos dados iniciais, e o número de infectados I é igual ao número de casos confirmados menos o número de recuperados. Portanto, a partir da última equação, podemos encontrar γ otimizando a função objetivo MACHO (ΔR-γI).
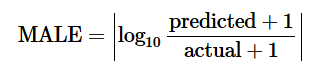
Para rastrear como as medidas de quarentena afetam o desenvolvimento da epidemia, compliquei um pouco minha tarefa e substituí o coeficiente β pela função β (t) - afinal, com a introdução da quarentena no país, a taxa de infecção deve diminuir, o que significa que em nosso caso β não será constante. Como já temos todas as condições iniciais para resolver o difur, podemos usar a otimização para encontrar a função β (t).
- Este é um dia de diferença?
- Dia menos o dia anterior. Eu conectei os dados e calculei os coeficientes desconhecidos.
- Beta e gama?
- Tomei Alpha 5.1 dias. Assim, foi necessário encontrar beta e gama - a intensidade dos contatos e o tempo de recuperação.
- E o que aconteceu com você?
- Existem gráficos. Cada região e cada país revelaram-se diferentes. Decidi para cada país separadamente. À esquerda está um gráfico de dados (preto - era real, vermelho - infectado e recuperado, previsto pelo modelo). Infectado + recuperado - verifica-se E + R. À direita está o gráfico do coeficiente beta. Beta, aliás, é suposto ser dependente do tempo. Aqui, o maior salto em β coincide com o momento da quarentena em 30 de março.
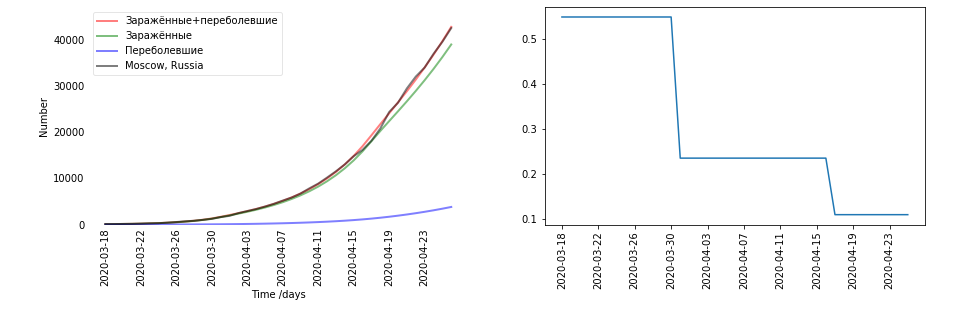
- E você contou de acordo com os dados ou presumiu que sim?
- Isso já está calculado de acordo com os dados. Este é exatamente o resultado do treinamento em Moscou.
- Você mesmo definiu os limites de tempo?
- Eu pensei que a função tem uma forma de duas fases. E otimizado. Eu apenas ajusto os dados e encontro as funções ideais que se adaptam melhor. Também tentei usar funções com um número diferente de degraus, mas os de dois estágios mostraram melhores resultados.
- Vamos dar uma olhada nos países, por exemplo, Itália. Bem, aqui você tem uma imagem diferente ...

- Na Itália, a quarentena, aparentemente, funcionou melhor. E há mais pessoas que estiveram doentes. O modelo confirmou que a quarentena foi introduzida em 9 de março.
- O que você escolheu para a previsão final?
- Para a previsão final, escolhi uma intensidade constante de contatos e construí um modelo utilizando os dois últimos pontos. Ou seja, conhecemos toda a história anterior, mas pegamos apenas os últimos pontos.
- Isso é para a previsão da semana?
- Sim. E o que aconteceu antes foi ver como o modelo se comporta. E então eu já olhei qual função é melhor tomar e quantos pontos estudar.
- Provavelmente, se você quisesse fazer uma previsão até agora, teria recebido uma decisão diferente. Você tem algo que mostre como a situação pode se desenvolver ainda mais?
- Sim. Mas não é muito interessante aí. Ela previu que todos em Moscou estariam doentes em setembro.
- Em um dos encontros você disse que, pela sua previsão, o pico deveria ter sido em julho. Na verdade, tudo aconteceu um pouco antes. O que você acha que o modelo não levou em consideração?
- Provavelmente beta. Talvez a quarentena tenha se intensificado. É possível que a intensidade dos contatos tenha diminuído pelo fato de as pessoas terem estado doentes, não infectar e não infectar. Beta deve de alguma forma depender disso. E aqui não é levado em consideração.
- Bem, isto é, você diz que podemos regular tudo com um beta?
- De acordo com dados conhecidos - sim, podemos, com ajuste de beta e gama.
- Seu modelo prevê a próxima onda?
- Não, está tudo estável: cresce, cresce, cresce e todo mundo vai adoecer. Embora também haja um fator de sazonalidade. Períodos de outono, por exemplo (quando a gripe, etc., o sistema imunológico está enfraquecido). Mas o modelo não leva tudo isso em consideração.
- Quais são os prós e os contras do seu modelo?
- No momento da compilação do modelo, havia poucos dados conhecidos. Agora, tanto o período de recuperação quanto o período de incubação já são conhecidos (então 5,1 era, agora é medido com mais precisão). Dos profissionais: mostra o próprio processo, como ele funciona. E se investigarmos mais profundamente no exemplo de outros países, por exemplo, Itália, Alemanha, como esses betas influenciaram, então seria possível para nós refinar este modelo e construir uma previsão de longo prazo mais precisa.
, data science – .
, , . - – , , , , .
, , . .Ele fez o modelo mais legal;)