O que é uma condição de corrida
Como os desenvolvedores geralmente esquecem que o código pode ser executado por vários threads ao mesmo tempo, eles não testam o produto para uma condição de corrida, embora esse erro seja bastante comum.
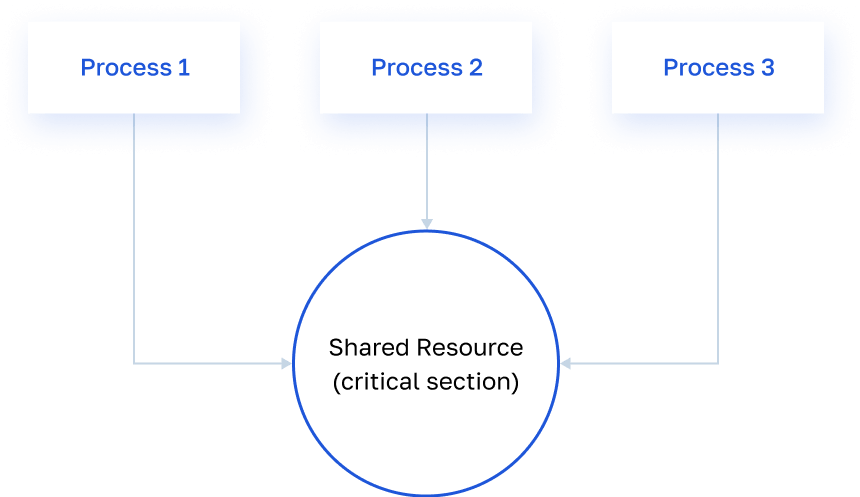
Do ponto de vista do backend, fica assim: vários threads acessam simultaneamente o mesmo recurso compartilhado: variáveis ou arquivos para os quais não há bloqueio ou sincronização. Isso leva a uma saída de dados inconsistente.
Aqui está um exemplo concreto de tal vulnerabilidade. Digamos que temos um aplicativo que permite a transferência de bônus entre carteiras de pagamento. O atacante tem duas carteiras - A e B, e cada uma delas possui 1000 bônus. O diagrama mostra como, ao manipular o tempo de envio de uma solicitação de transação, um invasor pode aumentar a quantidade de transferência para sua conta e ganhar 10 bônus em 20.

Existem ferramentas automáticas para pesquisar essas vulnerabilidades. Por exemplo, RacePWN, que em um tempo mínimo envia muitas solicitações HTTP para o servidor e aceita a configuração json como entrada, facilitando o processo de ataque aos cibercriminosos. Isso é feito manualmente, enviando solicitações POST.
Condição de raça mortal
Nos Estados Unidos, de junho de 1985 a janeiro de 1987, um erro de condição de corrida em uma máquina de terapia de radiação Therac-25 criada pela organização estatal canadense Atomic Energy of Canada Limited (AECL) causou seis overdoses de radiação . As vítimas receberam doses de dezenas de milhares de alegres. O nível de 1000 é considerado letal. Após as queimaduras resultantes, as vítimas morreram em poucas semanas. Apenas um paciente conseguiu sobreviver.
Os modelos anteriores do Therac tinham mecanismos de proteção de hardware: circuitos de bloqueio independentes que controlam o feixe de elétrons; bloqueadores mecânicos; disjuntores de hardware; desconectar fusíveis. A proteção de hardware foi removida no Therac-25. O software era responsável pela segurança. O dispositivo tinha vários modos de operação e, devido a um erro de condição de corrida, o médico às vezes não entendia em que modo o dispositivo realmente funciona. Durante o processo judicial, descobriu-se que o software Therac-25 foi desenvolvido por um programador, mas a AECL não tinha informações sobre quem exatamente.
Como resultado do processo, o governo dos Estados Unidos tornou muito mais rígidos os requisitos para o projeto e operação de sistemas cuja segurança é crítica para as pessoas.
Como se proteger
A maneira mais fácil e barata de resolver o problema da condição de corrida é projetar a arquitetura do aplicativo corretamente. Aqui está o que deve ser previsto para isso.
- Bloqueio de registros críticos no banco de dados. Existem diferentes maneiras de garantir que você trabalhe com a gravação de um fluxo em um determinado momento. O principal é não bloquear nada desnecessário.
- Isolamento de transações no banco de dados , o que garante que as transações sejam confirmadas sequencialmente. O mais importante aqui é encontrar um equilíbrio entre segurança e velocidade.
- . . , , , . , , , .
Nosso cliente é uma loja online de entrega de alimentos que oferece descontos através de cupons. Durante o teste, descobrimos uma vulnerabilidade - ao enviar uma solicitação POST com um valor de cupom. Ao enviar um pedido com atrasos diferentes, foi possível obter um desconto duas vezes. Aparentemente, os desenvolvedores cometeram um erro grave relacionado ao acesso compartilhado ao objeto que foi identificado com a compra.
Provavelmente havia tal pseudocódigo sem mecanismos de sincronização:
…
1 Se promo_flag não estiver definido:
2 Preço = get_price ()
3 Preço - = preço * promo_percent;
4 set_price (price)
5 set_promo_flag ()
...
Aqui, aplicar um código promocional e definir o sinalizador apropriado não é uma operação atômica. Provavelmente, quando a segunda aplicação do código promocional começou, a primeira parou na 5ª linha (ou seja, ainda não foi executada). Nesse momento, a função get_price () da segunda linha retornou um novo valor de preço, já com desconto.
Decisão
O problema é resolvido de forma simples:
…
1 acqure_mutex ()
2 Se promo_flag não estiver definido:
3 Preço = get_price ()
4 Preço - = preço * promo_percent;
5 set_price (price)
6 set_promo_flag ()
7 release_mutex ()
...
Agora, a aplicação do código promocional será realizada completa e completamente uma vez. Mesmo quando surge uma situação em que o segundo encadeamento tenta aplicar o código promocional enquanto o primeiro processo já está ocupado com o processamento, ele não será capaz de fazer isso. O mutex bloqueará o acesso à "seção crítica", e o segundo processo terá que esperar até que o primeiro seja concluído.
A condição de corrida não deve ser subestimada. Melhor gastar tempo e recursos procurando vulnerabilidades para evitar consequências imprevistas, inclusive para o orçamento da empresa.
Blog ITGLOBAL.COM - TI gerenciada, nuvens privadas, IaaS, serviços de segurança da informação para empresas:
- Como encontramos a vulnerabilidade no servidor de e-mail do banco e como ela ameaçou
- Segurança da informação em 2021. Ameaças, tendências do setor
- Sites populares ainda são vulneráveis a ataques DDoS massivos
- Por que hackers éticos devem trabalhar juntos para invadir corporações. Entrevista com o caçador de insetos Alex Chapman
- Medo da automação do trabalho e outras tendências na segurança cibernética global e russa