De certa forma, este artigo é uma continuação do nosso artigo sobre dimensionamento em Habré . Mas exemplos da vida real apareceram aqui, portanto, se houver necessidade de algum tipo de continuidade, comece com aquele artigo e depois volte aqui. Todos os detalhes estão sob o corte.
Este artigo é baseado em Benchmarking e dimensionamento de seu cluster Elasticsearch para logs e métricas no blog Elastic. Modificamos um pouco e eliminamos os exemplos com o Elastic baseado em nuvem.
Recursos de hardware do cluster Elasticsearch
O desempenho de um cluster Elasticsearch depende principalmente de como você o usa e do que é executado sob ele (no sentido do hardware). O hardware é caracterizado pelo seguinte:
Cofre
O fornecedor recomenda o uso de SSDs sempre que possível. Mas, obviamente, esse pode não ser o caso em todos os lugares, então a arquitetura quente-quente-fria e o Gerenciamento do Ciclo de Vida do Índice (ILM) estão à sua disposição.
Elasticsearch não requer armazenamento redundante (você pode fazer sem RAID 1/5/10), cenários de log ou armazenamento métrico geralmente têm pelo menos uma réplica para tolerância mínima a falhas.
Memória
A memória no servidor é dividida em:
JVM Heap. Armazena metadados sobre cluster, índices, segmentos, segmentos e dados de campo de documento. Idealmente, você deve alocar 50% da RAM disponível para isso.
Cache do sistema operacional. O Elasticsearch usará a memória disponível restante para armazenar dados em cache, o que melhorará drasticamente o desempenho, evitando leituras de disco durante pesquisas de texto completo, agregações de valor de documento e classificação. E não se esqueça de desabilitar a troca (arquivo de troca) para evitar descarregar o conteúdo da RAM no disco e depois ler a partir dele (isso é lento!).
CPU
Os nós Elasticsearch têm os assim chamados. pools de threads e filas de threads que usam os recursos de computação disponíveis. O número e o desempenho dos núcleos da CPU determinam a velocidade média e a taxa de transferência de pico das operações de dados no Elasticsearch. Na maioria das vezes, são 8-16 núcleos.
Rede
Desempenho da rede - a largura de banda e a latência podem afetar significativamente a comunicação entre os nós do Elasticsearch e a comunicação entre os clusters do Elasticsearch. Observe que, por padrão, uma verificação de disponibilidade do nó é realizada a cada segundo e se um nó não executar ping dentro de 30 segundos, ele é marcado como indisponível e é desligado do cluster.
Dimensionando um cluster Elasticsearch por volume de armazenamento
O armazenamento de logs e métricas geralmente requer uma quantidade significativa de espaço em disco, portanto, vale a pena usar a quantidade desses dados para determinar inicialmente o tamanho de nosso cluster Elasticsearch. Abaixo estão algumas perguntas para entender a estrutura de dados que precisa ser gerenciada em um cluster:
- Quantos dados brutos (GB) iremos indexar por dia?
- Por quantos dias manteremos os dados?
- Quantos dias estão na zona quente?
- Quantos dias estão na zona quente?
- Quantas réplicas serão usadas?
É aconselhável colocar 5% ou 10% no topo para que 15% do espaço total em disco permaneça sempre em estoque. Agora vamos tentar contar este caso.
Tamanho total dos dados (GB) = Número de dados brutos por dia (GB) * Número de dias de armazenamento * (Número de réplicas + 1).
Armazenamento total (GB) = Dados totais (GB) * (1 + 0,15 espaço de armazenamento + 0,1 armazenamento adicional).
Número total de nós de dados = OKRVVERH (tamanho total de dados (GB) / tamanho de memória por nó de dados / memória: proporção de dados). No caso de uma grande instalação, é melhor manter mais um nó adicional em estoque.
Elastic recomenda as seguintes proporções de memória: dados para diferentes tipos de nós: quente → 1:30 (30 GB de espaço em disco por gigabyte de memória), quente → 1: 160, frio → 1: 500). OKRVVERKH - surround para o inteiro superior mais próximo.
Exemplo de cálculo de pequeno cluster
Vamos supor que cerca de 1 GB de dados chegue todos os dias, que precisam ser armazenados por 9 meses.
Dados totais (GB) = 1 GB x (9 meses x 30 dias) x 2 = 540 GB
Armazenamento total (GB) = 540 GB x (1 + 0,15 + 0,1) = 675 GB
Número total de nós de dados = 675 GB / 8 GB RAM / 30 = 3 nós.
Exemplo de cálculo de um grande cluster
Você obtém 100 GB por dia e armazenará esses dados por 30 dias na zona quente e 12 meses na zona quente. Você tem 64 GB de memória por nó, dos quais 30 GB são alocados para o Heap da JVM e o restante para o cache do sistema operacional. A proporção recomendada de memória: dados para a zona quente é 1:30, para a zona quente - 1: 160.
Portanto, se você obtém 100 GB por dia e precisa armazenar esses dados por 30 dias, obtemos:
Quantidade total de dados (GB) na zona quente = (100 GB x 30 dias * 2) = 6000 GB de armazenamento
total da zona quente (GB) = 6000 GB x (1 + 0,15 + 0,1) = 7500 GB de nós de dados da
zona quente = OKRVUPH ( 7500 / 64/30) + 1 = 5 nós
Dados totais (GB) na zona quente= (100 GB x 365 dias * 2) = 73.000 GB
Armazenamento total (GB) na zona quente = 73.000 GB x (1 + 0,15 + 0,1) = 91.250 GB
Número total de nós de dados na zona quente = OKRVVERKH (91 250 / 64/160) + 1 = 10 nós
Assim, obtivemos 5 nós para a zona quente e 10 nós para a fruta quente. Para a zona fria, cálculos semelhantes, mas a proporção da memória: os dados já serão 1: 500.
Testes de performance
Uma vez que o tamanho do cluster foi determinado, é necessário confirmar se a matemática funciona na vida real.
Este teste usa a mesma ferramenta que os engenheiros do Elasticsearch usam, o Rally . É fácil de implantar e executar e é totalmente personalizável, portanto, vários cenários (trilhas) podem ser testados.
Para facilitar a análise dos resultados, o teste é dividido em duas seções: indexação e consultas de pesquisa. Os testes usarão dados de trilhas do Metricbeat e logs do servidor da web .
Indexando
O teste responde às seguintes perguntas:
- Qual é a taxa de transferência máxima para clusters de indexação?
- Quantos dados podem ser indexados por dia?
- O cluster é maior ou menor do que o tamanho apropriado?
Este teste usa um cluster de 3 nós com a seguinte configuração para cada nó:
- 8 vCPU;
- HDD;
- Pilha de 32 GB / 16.
Teste de indexação nº 1
O conjunto de dados usado para o teste são dados Metricbeat com as seguintes características:
- 1.079.600 documentos;
- Volume de dados: 1,2 GB;
- Tamanho médio do documento: 1,17 KB.
Em seguida, haverá vários testes para determinar o tamanho ideal do pacote e o número ideal de threads.
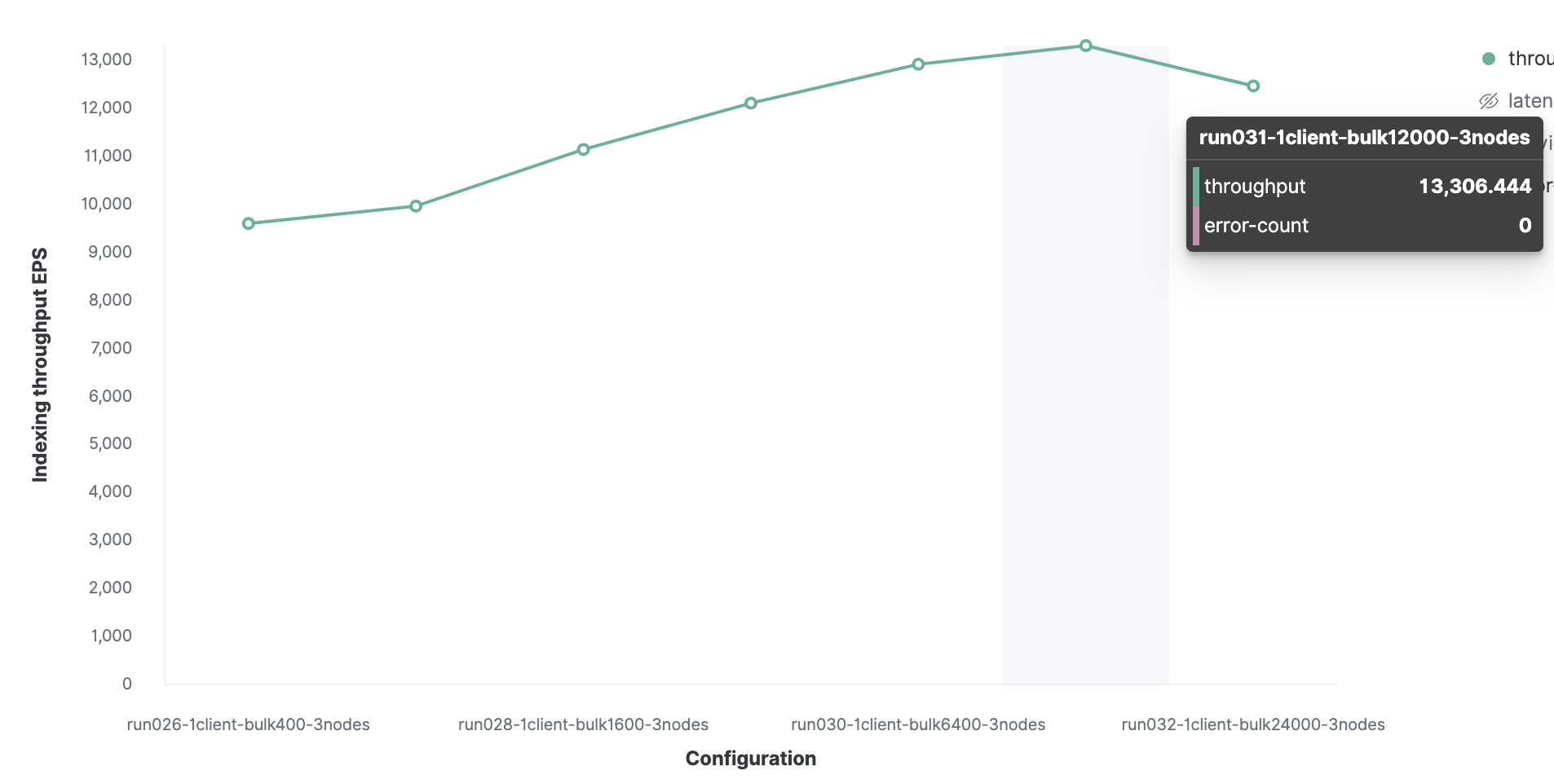
Tudo começa com 1 cliente Rally para encontrar o tamanho ideal do pacote. Inicialmente, 100 documentos são carregados e, em seguida, seu número dobra nas inicializações subsequentes. O resultado será um tamanho de lote ideal de 12.000 documentos (cerca de 13,7 MB). À medida que o tamanho do pacote aumenta, o desempenho começa a cair.
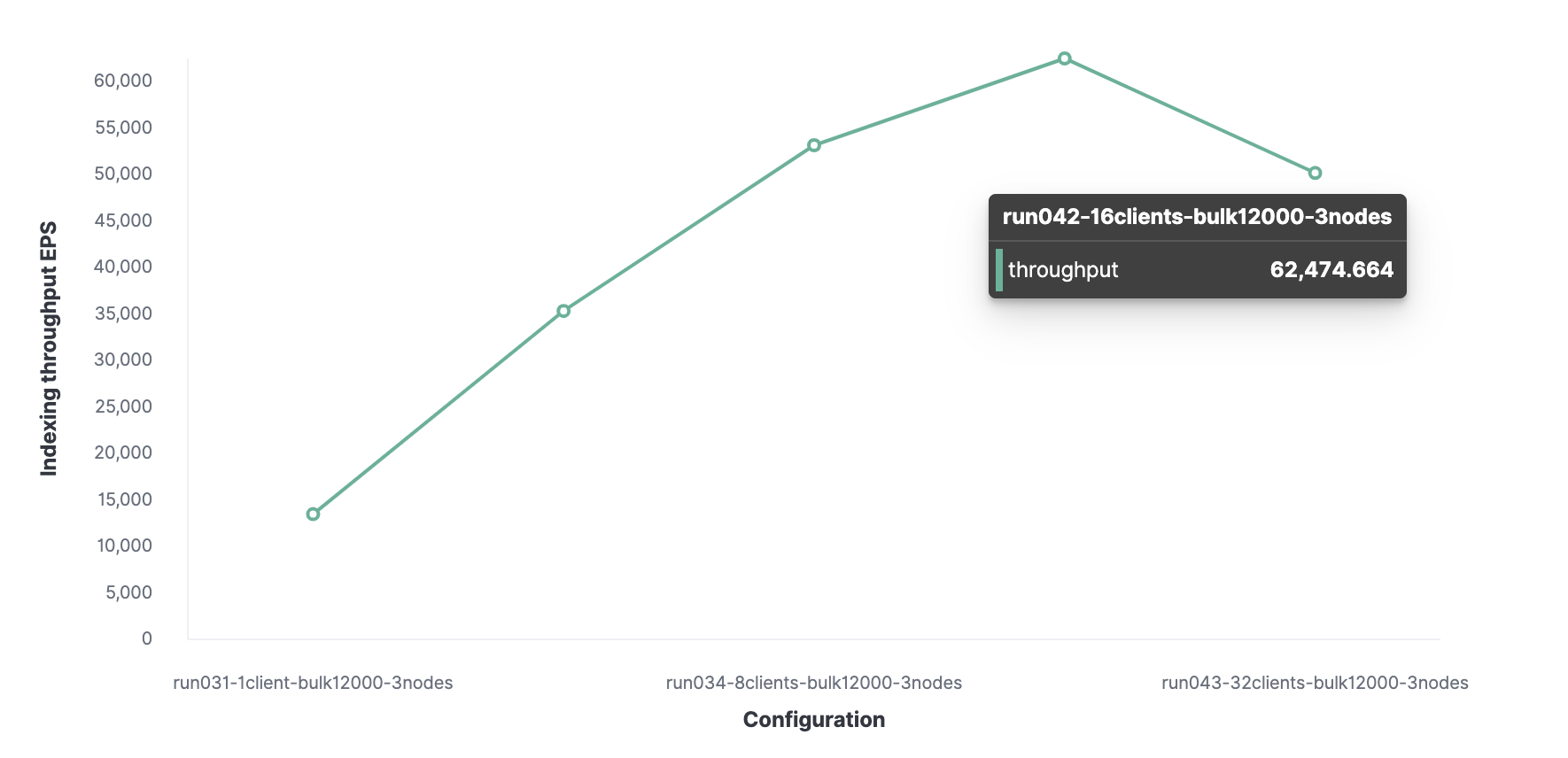
Então, usando um método semelhante, 16 é o número ideal de clientes para atingir 62.000 eventos indexados por segundo.
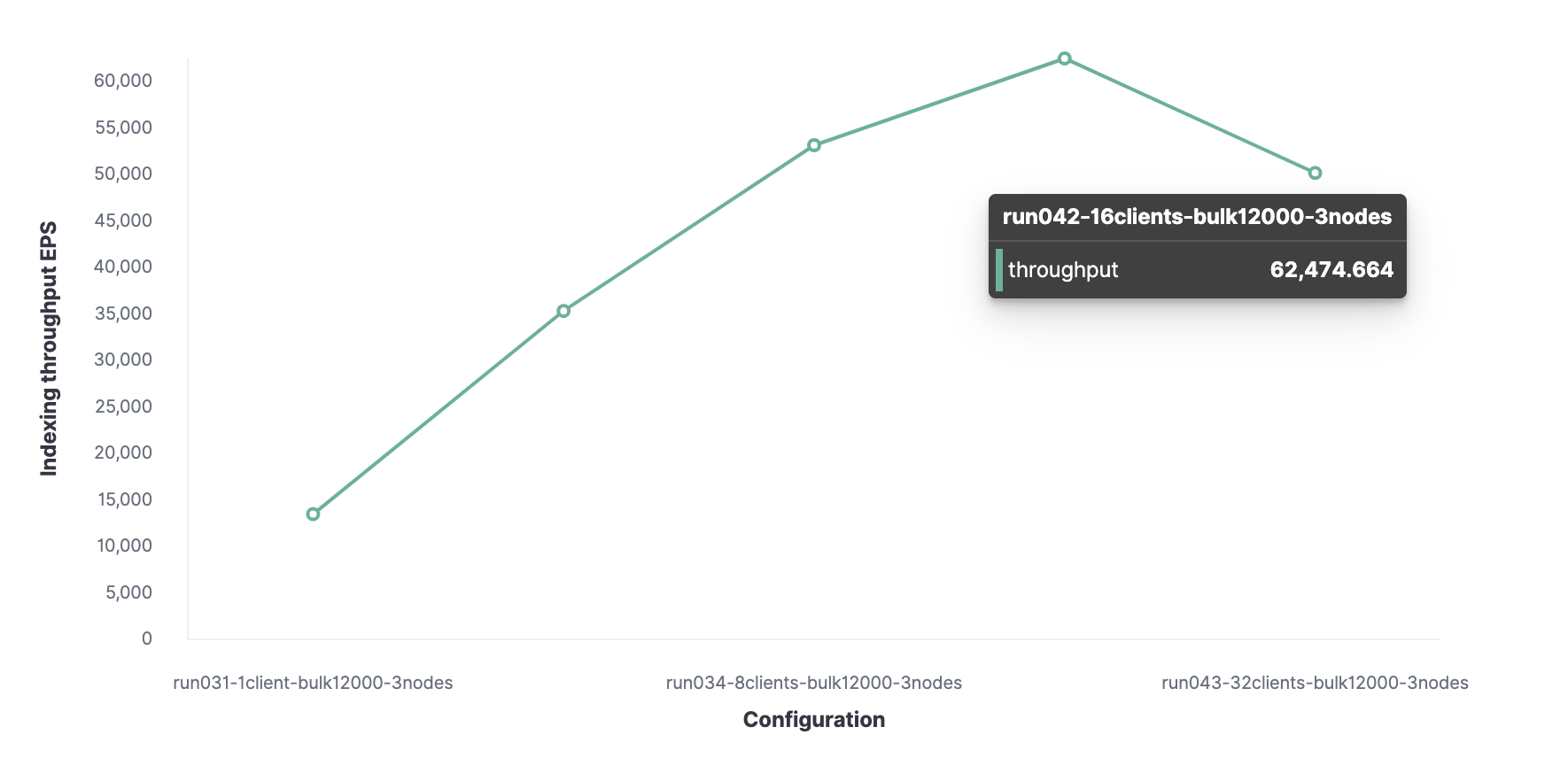
No total, o cluster pode processar no máximo 62.000 eventos por segundo sem sacrificar o desempenho. Para aumentar esse número, você precisará adicionar um novo nó.
Abaixo está o mesmo teste com um pacote de 12.000 eventos, mas para comparação, os dados de largura de banda são fornecidos para 1 nó, 2 e 3 nós.
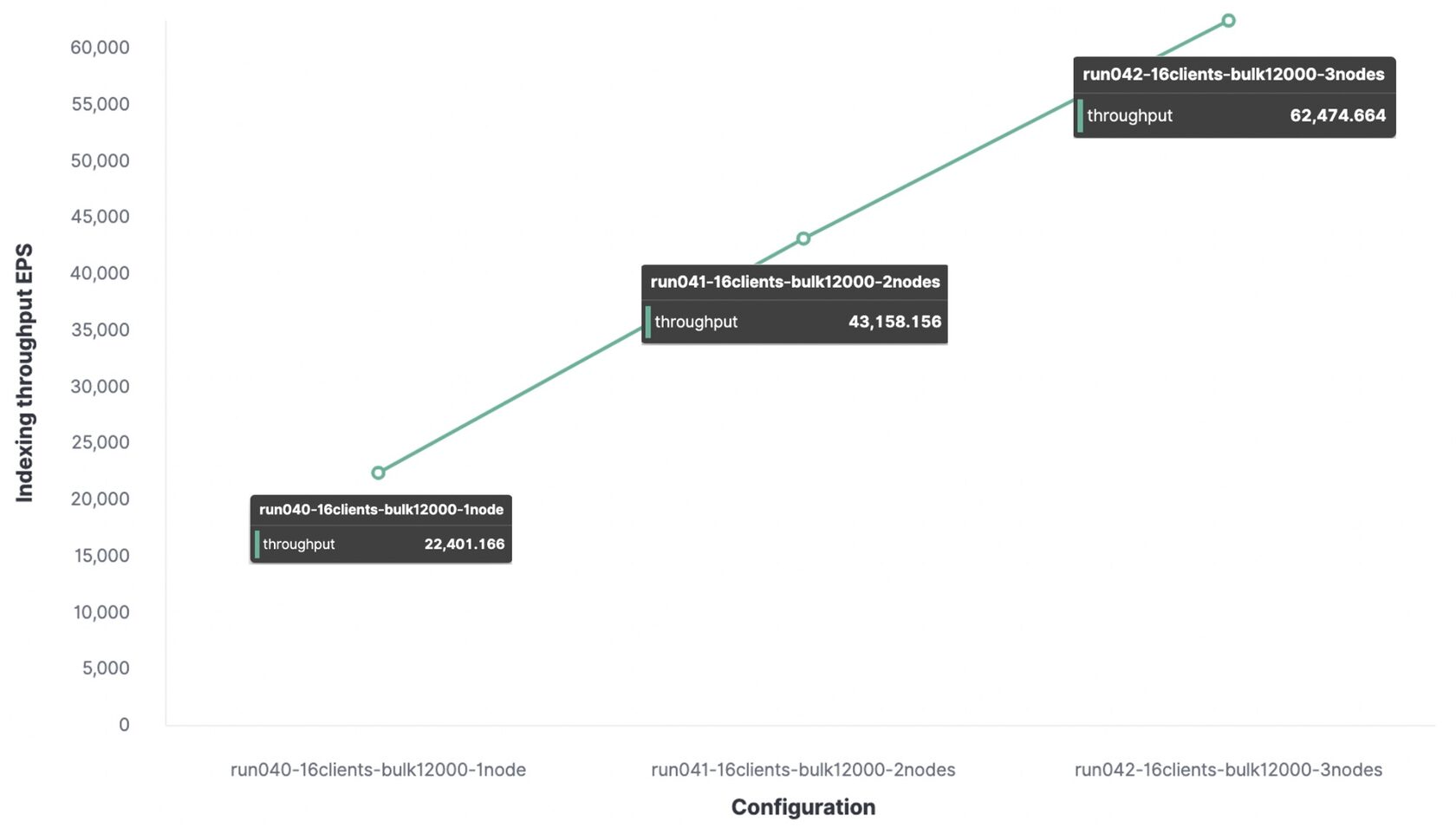
Para um ambiente de teste, a taxa de transferência máxima de indexação será:
- Com 1 nó e 1 fragmento, 22.000 eventos por segundo foram indexados;
- Com 2 nós e 2 fragmentos, 43.000 eventos por segundo foram indexados;
- Com 3 nós e 3 fragmentos, 62.000 eventos por segundo foram indexados.
Qualquer solicitação de índice adicional será enfileirada e, quando estiver cheia, o nó responderá rejeitando a solicitação de índice.
Observe que o conjunto de dados afeta o desempenho do cluster, por isso é importante executar pistas de Rally com seus próprios dados.
Teste de indexação nº 2
Para a próxima etapa, as trilhas de dados de registro do servidor HTTP com a seguinte configuração serão usadas:
- 247 249 096 documentos;
- Volume de dados: 31,1 GB;
- Tamanho médio do documento: 0,8 KB.
O tamanho ideal do pacote é de 16.000 documentos.
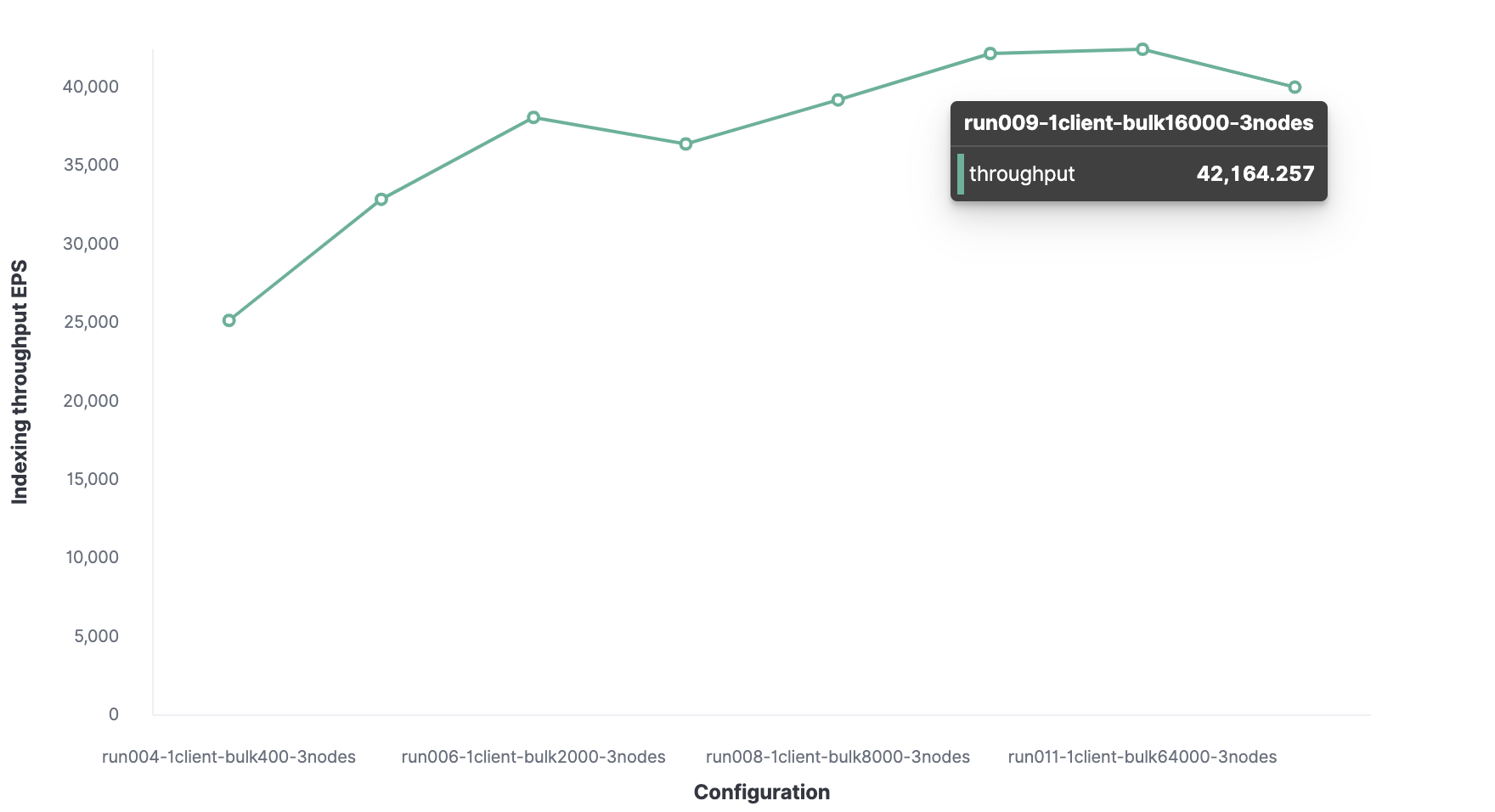
O número ideal de clientes é 32.
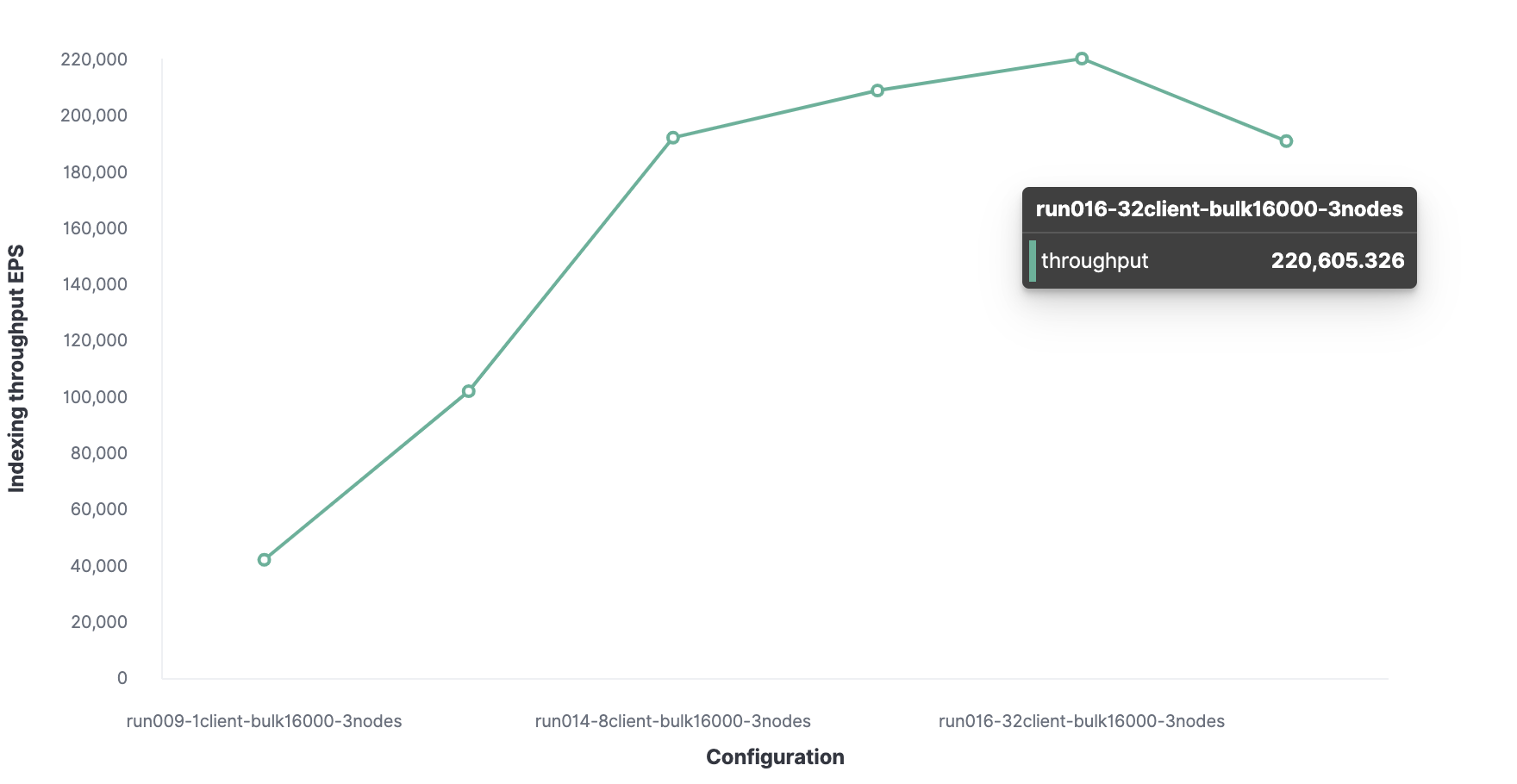
Conseqüentemente, a taxa de transferência máxima de indexação no Elasticsearch é de 220.000 eventos por segundo.
Procurar
A taxa de transferência da pesquisa será estimada com base em 20 clientes e 1000 operações por segundo. Três testes serão realizados para a pesquisa.
Teste de pesquisa nº 1
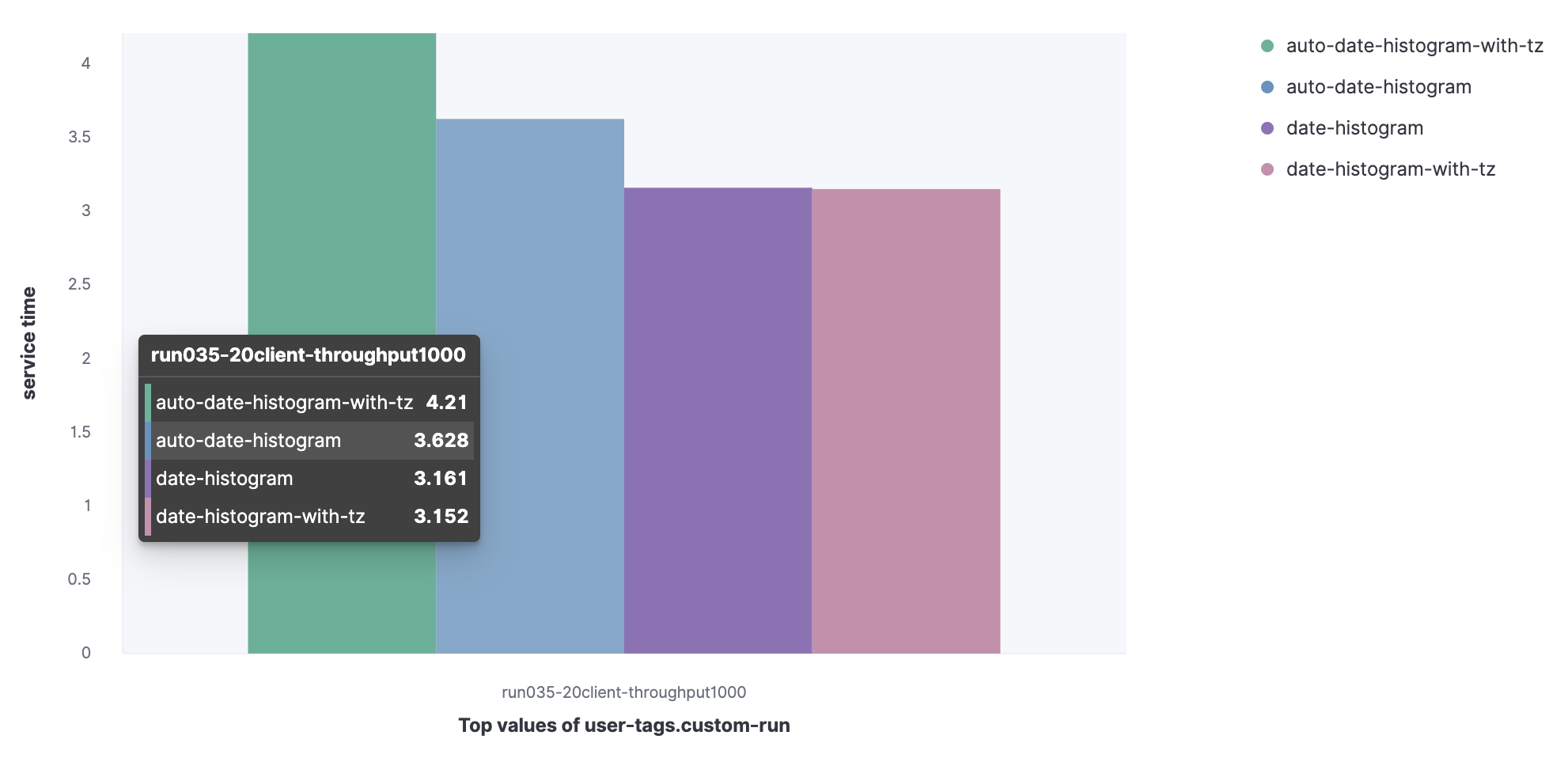
Compara o tempo de serviço (ou melhor, o percentil 90) para um conjunto de consultas.
Conjunto de dados da Metricbeat:
- Histograma de datas agregadas com intervalo automático (auto-data-historgram);
- Histograma de data agregada com fuso horário com intervalo automático (auto-data-histograma-com-tz);
- Histograma de data agregada (histograma de data);
- Histograma de data agregada com fuso horário (data-histograma-com-tz).
Você pode ver que a solicitação auto-date-histogram-with-tz tem o tempo de serviço mais longo no cluster.
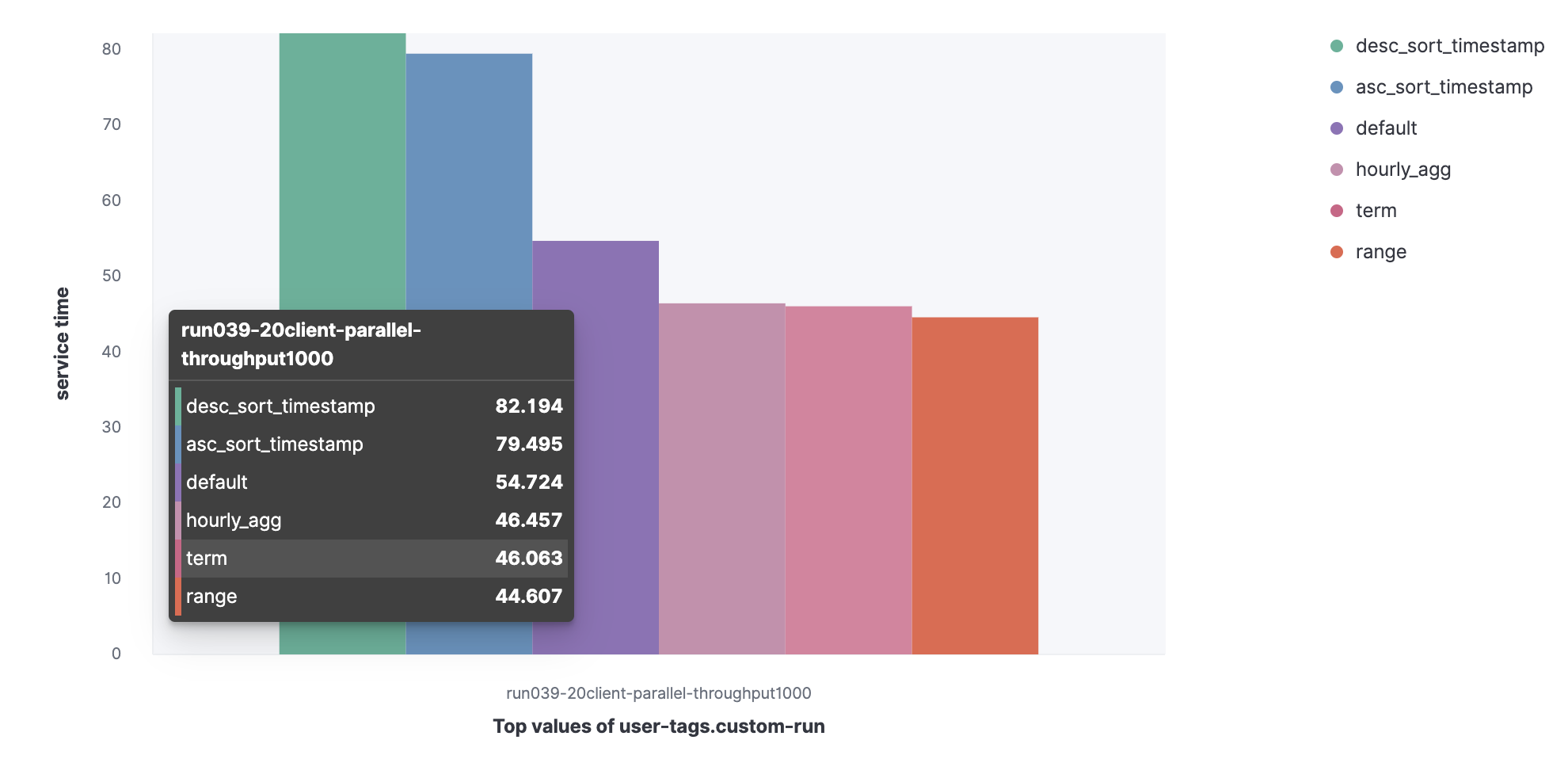
Conjunto de dados do registro do servidor HTTP:
- Predefinição;
- Prazo;
- Faixa;
- Hourly_agg;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Você pode ver que as solicitações desc_sort_timestamp e desc_sort_timestamp têm uma vida útil mais longa.

Teste de pesquisa nº 2
Agora, vamos examinar as consultas paralelas. Vamos ver como o tempo de serviço do 90º percentil aumenta se as consultas são executadas em paralelo.
Teste de pesquisa nº 3
Considere a velocidade de indexação e o tempo de serviço das consultas de pesquisa na presença de indexação paralela.
Vamos executar uma tarefa de indexação e pesquisa paralela para ver a velocidade de indexação e o tempo de serviço de consulta.

Vamos ver como o tempo de serviço de consulta do 90º percentil aumentou ao realizar pesquisas em paralelo com operações de indexação.

No total, são 32 clientes para indexação e 20 usuários para pesquisa:
- A taxa de transferência de indexação é de 173.000 eventos por segundo, o que é inferior a 220.000 obtidos em experimentos anteriores;
- A largura de banda da pesquisa é de 1000 eventos por segundo.
O Rally é uma ferramenta de benchmarking poderosa, mas você deve usá-lo apenas com dados que também serão colocados em produção no futuro.
Alguns anúncios:
Desenvolvemos um curso de formação sobre noções básicas de trabalho com Elastic Stack , que se adapta às necessidades específicas do cliente. Programa de treinamento detalhado a pedido.
Convidamos você a se inscrever no Elastic Day na Rússia e no CIS 2021, que será realizado online em 3 de março, das 10h às 13h.
Leia nossos outros artigos:
- Dimensionamento Elasticsearch
- Como as licenças do Elastic Stack (Elasticsearch) são licenciadas e diferentes
- Compreendendo o aprendizado de máquina no Elastic Stack (também conhecido como Elasticsearch, também conhecido como ELK)
- Elastic under the lock: habilitando opções de segurança para o cluster Elasticsearch para acesso interno e externo
Se estiver interessado em serviços de administração e suporte para a instalação do Elasticsearch, você pode deixar uma solicitação no formulário de feedback em uma página especial.
Inscreva-se em nosso grupo no Facebook e canal no Youtube .