Nossa tradução de hoje é sobre Data Science. Um analista de dados de Dublin contou como estava procurando por imóveis em um mercado com alta demanda e baixa oferta.
Sempre invejei aqueles profissionais que conseguem aplicar suas habilidades de trabalho no dia a dia . Pegue um encanador, dentista ou chef, por exemplo: suas habilidades não são úteis apenas no trabalho.
Para o analista de dados e o engenheiro de software, esses benefícios geralmente são menos tangíveis. Claro, eu entendo muito de tecnologia, mas no trabalho eu lido principalmente com o setor empresarial, então é difícil encontrar casos de uso interessantes para minhas habilidades para resolver problemas familiares.
Quando minha esposa e eu decidimos comprar uma nova casa em Dublin, imediatamente vi uma oportunidade de usar esse conhecimento!
O conteúdo do artigo:
- Alta demanda, baixa oferta
- Procurando dados
- Da ideia à ferramenta
- Dados básicos
- Melhorar a qualidade dos dados
- Google Data Studio
- Alguns detalhes de implementação (e depois passando para a parte divertida)
- Endereços de geocodificação
- Cálculo do tempo que o imóvel está no mercado
- Análise
- descobertas
- Conclusão
Os dados abaixo não foram extraídos, mas gerados com este script .
Alta demanda, baixa oferta
Para entender como tudo começou, você pode ler minha experiência pessoal de compra de imóveis em Dublin. Devo admitir que não foi fácil: o mercado tem uma procura muito elevada (graças ao excelente desempenho económico da Irlanda nos últimos anos) e a habitação é extremamente cara. A Irlanda teve os custos de habitação mais elevados em comparação com a UE em 2019, de acordo com um relatório do Eurostat (77% acima da média da UE).

O que este diagrama significa?
1. São muito poucas as casas que cabem no nosso orçamento , e em áreas da cidade com grande demanda há ainda menos casas (com infraestrutura de transporte mais ou menos normal).
2. A condição da habitação secundária às vezes é muito ruim, uma vez que não é lucrativo para os proprietários investir em reparos antes de vender. As casas à venda costumam ter baixas classificações de eficiência energética, encanamento e equipamento elétrico ruins, o que significa que os compradores terão que adicionar os custos de renovação a um preço já alto.
3. As vendas são baseadas em um sistema de leilão e, na maioria dos casos, os lances dos compradores excedem o preço inicial. Pelo que entendi, isso não se aplica a edifícios novos, mas eles estavam muito além do nosso orçamento, então não consideramos esse segmento de forma alguma.
Acho que muita gente ao redor do mundo conhece essa situação, já que, provavelmente, as coisas são iguais nas grandes cidades.
Como todas as outras pessoas na nossa pesquisa de propriedades, queríamos encontrar a casa perfeita na área perfeita a um preço acessível. Vamos ver como a análise de dados nos ajudou a fazer isso!
Procurando dados
Em qualquer projeto de Data Science existe uma etapa de coleta de dados e, para esse caso em particular, estava em busca de uma fonte contendo informações sobre todos os imóveis disponíveis no mercado. Na Irlanda, existem dois tipos de sites:
- sites de agências imobiliárias,
- agregadores.
Ambas as opções são muito úteis e tornam a vida muito mais fácil para vendedores e compradores. Infelizmente, a interface do usuário e os filtros sugeridos nem sempre fornecem a maneira mais eficiente de extrair as informações necessárias e comparar as diferentes propriedades. Aqui estão algumas perguntas que são difíceis de responder com mecanismos de pesquisa como o Google:
1. Quanto tempo leva para chegar ao trabalho?
2. Quantas propriedades existem em uma área ou outra? É possível comparar bairros da cidade em sites clássicos, mas eles geralmente cobrem vários quilômetros quadrados. Esse detalhe não é suficiente para entender, por exemplo, que uma frase muito alta em uma determinada rua indica algum tipo de truque. A maioria dos sites especializados possui mapas, mas eles não são tão informativos quanto gostaríamos.
3. Quais são as instalações perto da casa?
4. Qual é o preço médio pedido por um grupo de propriedades?
5. Há quanto tempo o imóvel está à venda? Mesmo que essa informação esteja disponível, nem sempre é confiável, pois o corretor de imóveis pode deletar o anúncio e colocá-lo novamente.
Redesenhar a interface do usuário para ser mais amigável ao consumidor e melhorar a qualidade dos dados tornou muito mais fácil encontrar uma casa e nos permitiu obter alguns insights muito interessantes.
Da ideia à ferramenta
Dados básicos
A primeira etapa foi escrever um raspador para coletar informações básicas:
- endereço bruto da propriedade,
- preço de venda atual,
- link para a página com a propriedade,
- características básicas, como número de quartos, número de banheiros, classificação de eficiência energética,
- número de visualizações do anúncio (se disponível),
- tipo de imóvel (casa, apartamento, prédio novo).
Esses são, na verdade, todos os dados que pude encontrar na Internet. Para uma análise mais profunda, eu precisava melhorar este conjunto de dados.
Melhorar a qualidade dos dados
Ao escolher uma casa, meu principal argumento a favor da compra é um caminho conveniente para o trabalho, para mim não são mais do que 50 minutos em todo o trajeto de porta a porta. Para esses cálculos, decidi usar o Google Cloud Platform:
1. Usando a API Geocoding, obtive as coordenadas de latitude e longitude usando o endereço da propriedade.
2. Usando a API de rotas, calculei o tempo que leva para ir de casa para o trabalho a pé e de transporte público. Nota: andar de bicicleta é cerca de 3 vezes mais rápido do que andar.
3. Usando assentos de API (API do Google Places)Recebi informações sobre as amenidades de cada propriedade. Em particular, estávamos interessados em farmácias, supermercados e restaurantes. Observação: as APIs do Google Places são muito caras: com um banco de dados de 4.000 propriedades, você precisaria executar 12.000 consultas para encontrar informações sobre três tipos de comodidades. Portanto, excluí esses dados do painel final.
Além da localização geográfica, eu estava interessado em outra pergunta: há quanto tempo o imóvel está no mercado? Se a propriedade não foi vendida por muito tempo, este é um alerta: talvez algo esteja errado com a área ou a própria casa, ou o preço pedido é muito alto.
Por outro lado, se o imóvel acaba de ser colocado à venda, deve-se ter em mente que os proprietários não concordarão com a primeira oferta recebida. Infelizmente, essa informação é bastante fácil de esconder. Usando o aprendizado de máquina básico, estimei esse aspecto usando a contagem de visualizações do anúncio e algumas outras métricas.
Por fim, melhorei o conjunto de dados com alguns campos de serviço para facilitar a filtragem (por exemplo, adicionando uma coluna com uma faixa de preço).
Google Data Studio
Com um conjunto de dados aprimorado que estava bom para mim, eu iria criar um painel poderoso . Escolhi o Google Data Studio como uma ferramenta de visualização de dados para essa tarefa. Este serviço tem algumas desvantagens (seus recursos são muito, muito limitados), mas também tem vantagens: é gratuito, tem uma versão para web e pode ler dados do Planilhas Google. Abaixo está um diagrama que descreve todo o fluxo de trabalho.

Alguns detalhes de implementação
Para ser honesto, a implementação foi bastante direta e não há nada de novo ou especial aqui: apenas um monte de scripts para coletar dados e algumas transformações básicas do Pandas. Só que vale destacar a interação com a API do Google e o cálculo do tempo durante o qual o imóvel esteve no mercado.
Os dados abaixo não foram extraídos, mas gerados com este script .
Vamos dar uma olhada nos dados brutos.
Como eu esperava, o arquivo contém as seguintes colunas:
id
: ID do anúncio._address
: Endereço do imóvel._d_code
: . D<>. <> , (, ), — ._link
: , ._price
: .type
: (, , )._bedrooms
: ()._bathrooms
: ._ber_code
: , : «», ._views
: ( )._latest_update
: ( ).days_listed
: — , ,_last_update
.
O objetivo é trazer tudo isso para o mapa e aproveitar o poder dos dados geolocalização. Para fazer isso, vamos ver como obter latitude e longitude usando a API do Google.
Para fazer isso, você precisa de uma conta no Google Cloud Platform e, em seguida, pode seguir o tutorial no link para obter uma chave de API e habilitar a API correspondente. Como escrevi anteriormente, para este projeto eu usei a API de geocodificação, API de direções e API de lugares (então você precisará habilitar essas APIs específicas ao criar a chave de API). Abaixo está um snippet de código para interagir com o Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)
Cálculo do tempo que o imóvel está no mercado
Vamos dar uma olhada nos dados :
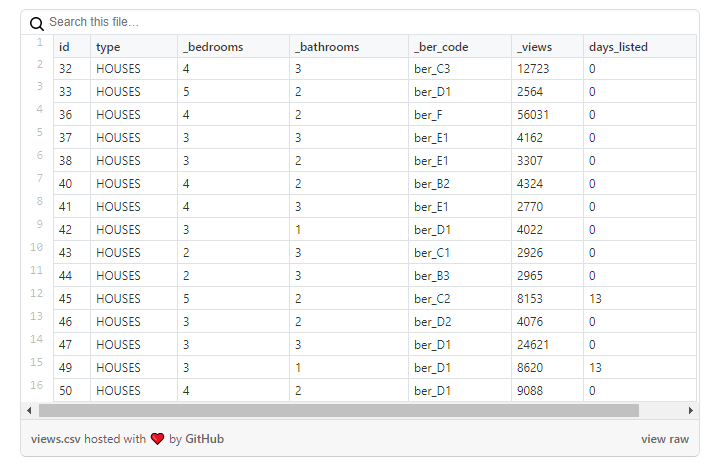
como você pode ver neste exemplo, o número de visualizações de propriedades não se reflete no número de dias durante os quais o anúncio esteve ativo: por exemplo, uma casa com id = 47 tem ~ 25 mil visualizações, mas apareceu naquele dia quando carreguei os dados.
No entanto, esse problema não é comum para todas as propriedades. No exemplo abaixo , o número de visualizações é mais comparável ao número de dias que o anúncio esteve ativo:

Como podemos usar as informações acima? Facilmente! Podemos usar o segundo conjunto de dados como um conjunto de treinamento para o modelo, que podemos então aplicar ao primeiro conjunto de dados.
Testei duas abordagens:
1. Pegue um conjunto de dados "comparável" e calcule o número médio de visualizações por dia e, em seguida, aplique esse valor ao primeiro conjunto de dados. Esta abordagem não deixa de ter bom senso, mas apresenta o seguinte problema: todas as propriedades estão reunidas num só grupo, sendo provável que um anúncio de venda de uma casa no valor de 10 milhões de euros receba menos visualizações por dia, uma vez que tal o orçamento está disponível para um grupo restrito de pessoas.
2. Treine o modelo Random Forest no segundo conjunto de dados e aplique-o ao primeiro.
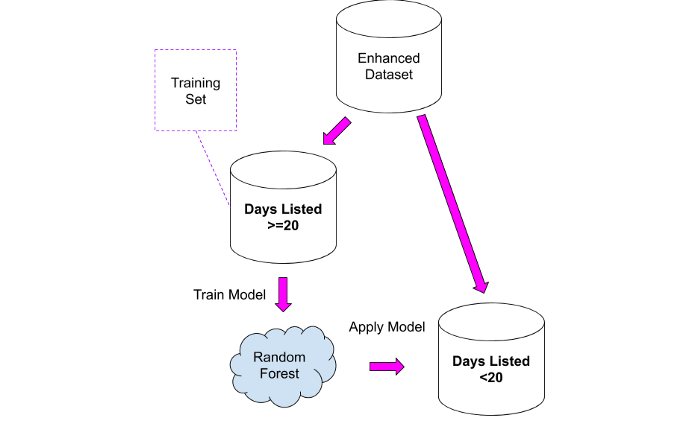
Os resultados devem ser vistos com muito cuidado, lembrando que a nova coluna conterá apenas valores aproximados: Usei-os como ponto de partida para analisar mais detalhadamente as propriedades onde algo parecia estranho.
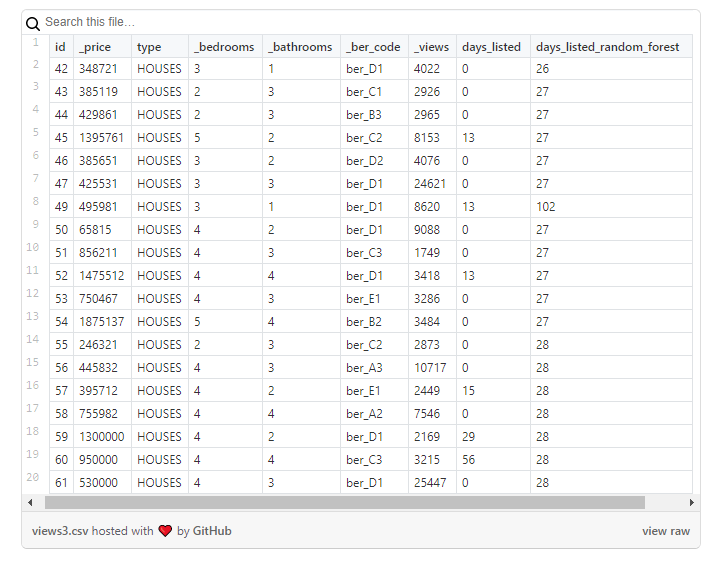
Análise
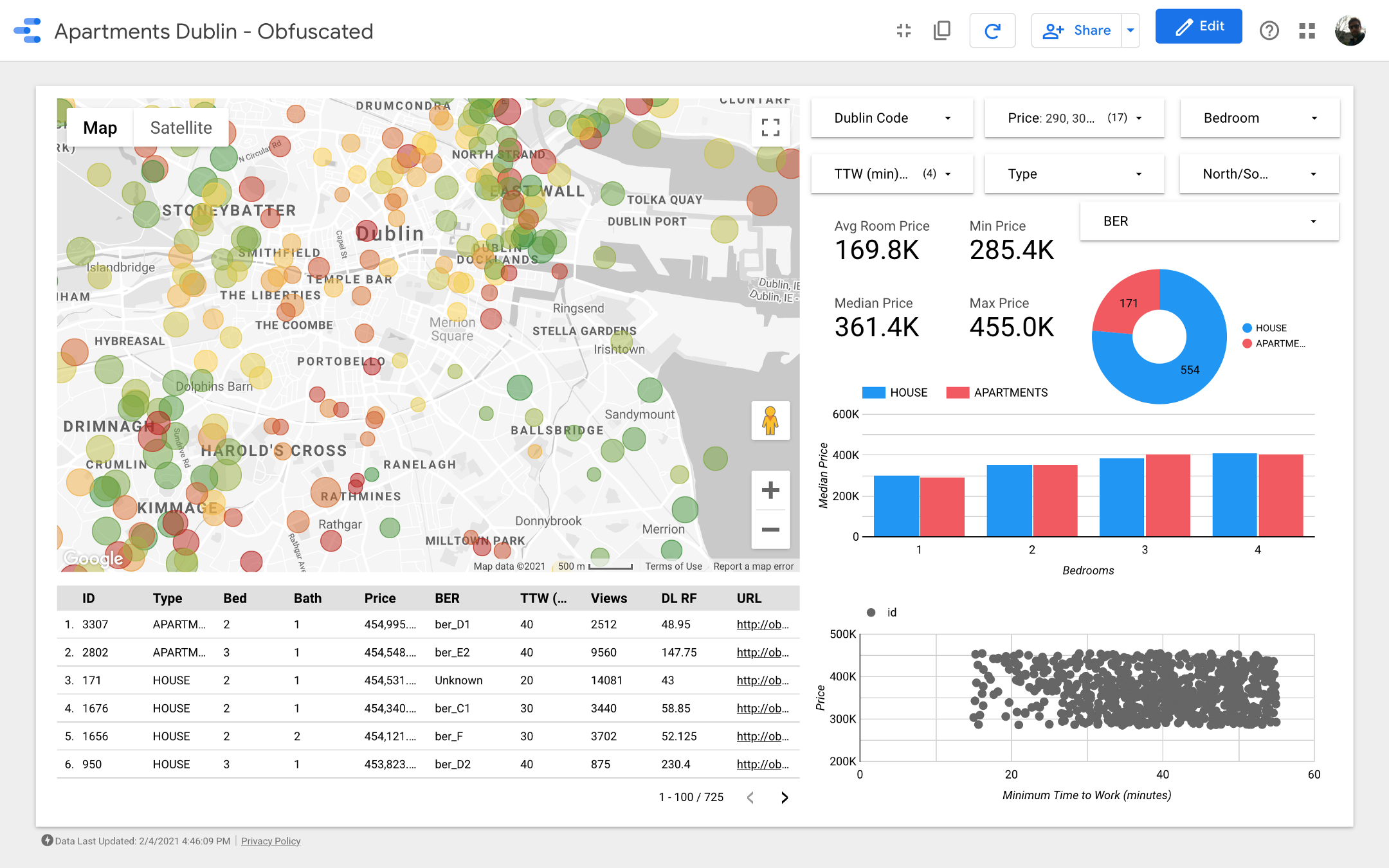
Senhoras e senhores, apresento a vossa atenção o painel final . Se você quiser se aprofundar nele, siga o link .
Nota: Infelizmente, o módulo do Google Maps não funciona quando embutido em um artigo, então tive que usar capturas de tela.
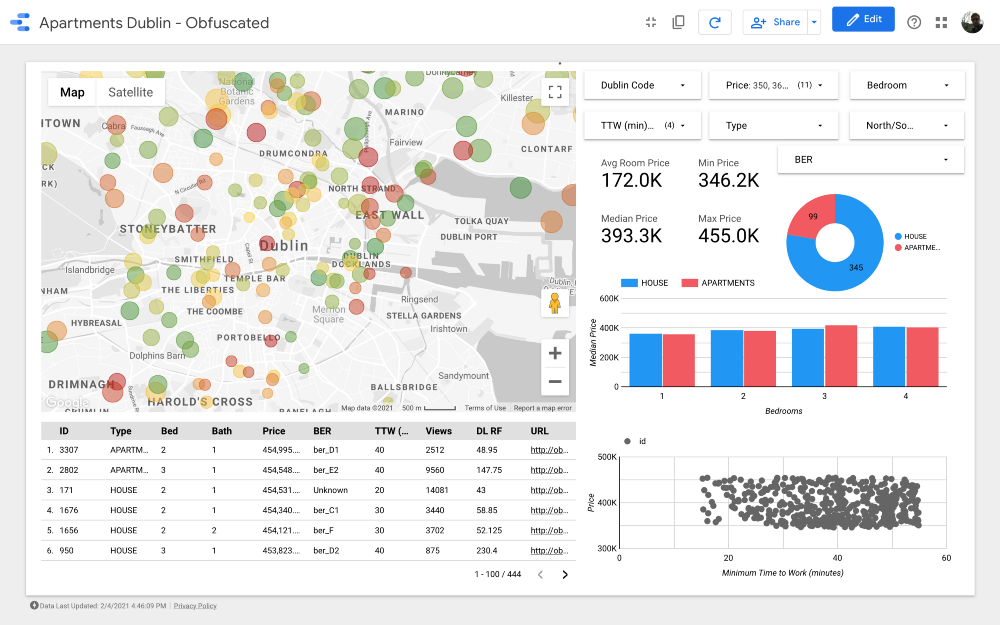
https://datastudio.google.com/s/qKDxt8i2ezE O
mapa é a parte mais importante do painel. A cor das bolhas depende do preço da casa / apartamento, e a coloração leva em consideração apenas as propriedades disponíveis (correspondendo às configurações do filtro no canto superior direito); o tamanho das bolhas indica a distância para o trabalho: quanto menor, mais curta é a estrada.
Os gráficos permitem que você analise como o preço pedido muda dependendo de algumas características (por exemplo, o tipo de edifício ou o número de quartos), e o gráfico de dispersão compara a distância para o trabalho e o preço pedido.
Por fim, a tabela de dados brutos (
DL RF
significa Dias listados de floresta aleatória e mostra o número de dias em que o anúncio esteve ativo, o modelo de floresta aleatória).
descobertas
Vamos mergulhar na análise e ver quais conclusões podemos tirar do painel.
O conjunto de dados inclui cerca de 4.000 casas e apartamentos: é claro, não podemos ver todos eles, então nossa tarefa é identificar um subconjunto de registros contendo uma ou mais propriedades que estamos prontos para considerar a compra.
Primeiro, precisamos esclarecer os critérios de pesquisa. Por exemplo, digamos que estamos procurando um imóvel que atenda às seguintes características:
1. Tipo de imóvel: Casa.
2. Número de cômodos (quartos): 3.
3. Distância até o trabalho: menos de 60 minutos.
4. Classificação de eficiência energética: A, B, C ou D.
5. Preço: de 250 a 540 mil euros.
Vamos aplicar todos os filtros exceto o preço e olhar para o mapa (filtrando apenas aqueles que são mais caros do que 1 milhão e menos do que 200 mil euros).
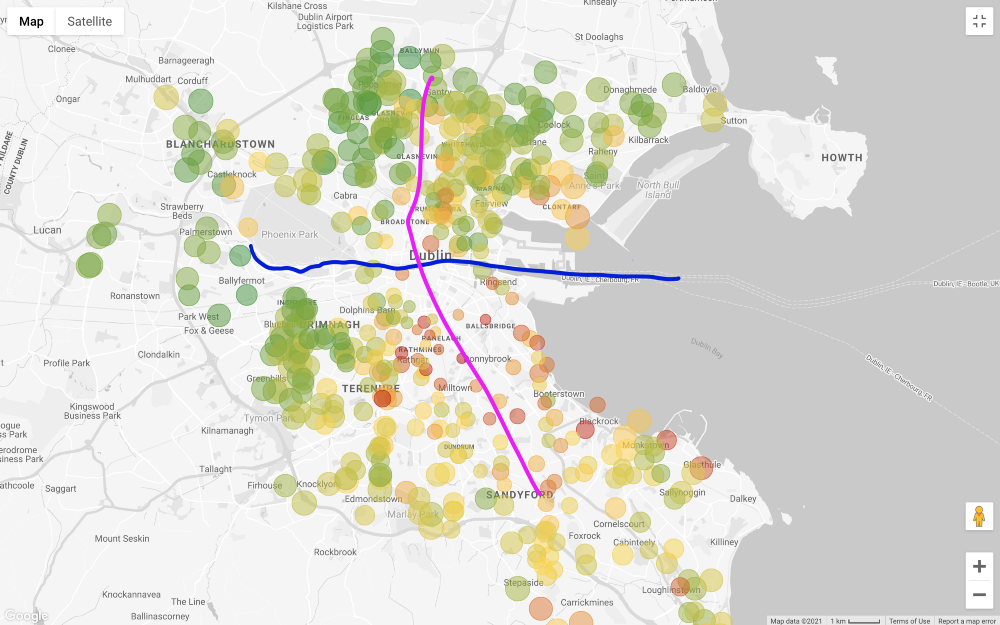
Em geral, o preço pedido por propriedades no sul de Liffey é muito mais alto do que no norte, com algumas exceções no sudoeste da cidade. Mesmo as "áreas externas" no norte, ou seja, no nordeste e no noroeste, parecem menos caras do que o norte do centro da cidade. Uma razão para esse preço é que a Main Tramway Line (LUAS) de Dublin cruza a cidade de norte a sul em linha reta (há outra linha que vai de oeste a leste, mas não passa por todos os distritos comerciais).
Observe que estou fazendo essas considerações com base apenas na inspeção visual. Uma abordagem mais completa requer testar a correlação entre o preço de uma casa e sua distância das rotas de transporte público, mas não estamos interessados em provar essa conexão.
A situação torna-se ainda mais interessante, se definir os preços de filtro de acordo com o nosso orçamento (não se esqueça que no mapa acima mostra a casa com 3 quartos, e chega ao trabalho em menos de 60 minutos, e no mapa abaixo adicionado apenas filtrar por preço):
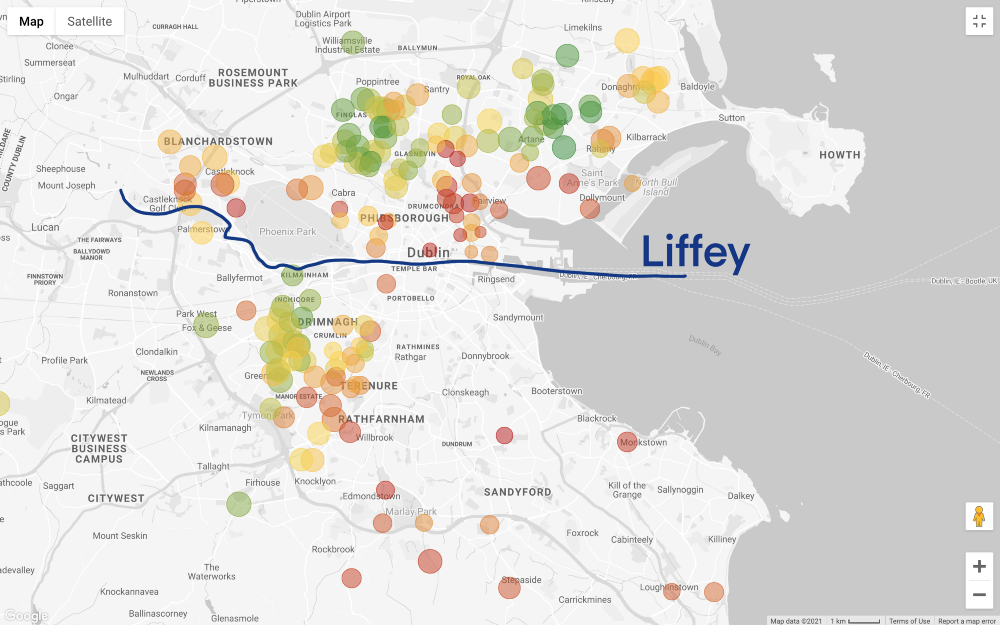
vamos dar um passo para trás. Temos uma ideia geral das áreas que podemos pagar, mas agora o mais difícil está pela frente - a busca de compromissos! Queremos encontrar uma opção mais econômica? Ou consideramos a melhor casa que nossas economias arduamente conquistadas podem comprar? Infelizmente, a análise de dados não pode responder a essas perguntas, esta é uma decisão de negócios (e altamente pessoal).
Suponha que escolhemos a segunda opção: priorizamos a qualidade da casa ou área sobre o preço mais baixo.
Nesse caso, devemos considerar as seguintes opções:
1. Áreas com baixa concentração de propostas - uma casa isolada no mapa pode indicar que não há muitas ofertas na área, o que significa que os proprietários não têm pressa em parte de sua casa em uma área tão boa ...
2. Uma casa localizada em um conjunto de propriedades caras - se todas as outras propriedades próximas a uma determinada casa forem caras, isso pode significar que a área está em alta demanda. Esta é apenas uma nota adicional, mas poderíamos quantificar esse fenômeno usando autocorrelação espacial (por exemplo, calculando o I de Moran ).
Mesmo que a primeira opção pareça atraente, deve-se ter em mente que o preço muito baixo do imóvel em comparação com outras ofertas na mesma área pode implicar em algum tipo de captura na própria casa (por exemplo, quartos pequenos ou custos de renovação muito elevados ) Por isso, continuaremos nossa análise focando na segunda opção, que, a meu ver, é a mais promissora diante de nosso objetivo.
Vejamos mais de perto quais são as propostas na área:

Já reduzimos nossas opções de 4.000 para menos de 200, e agora precisamos quebrar melhor os pontos e comparar os clusters.
A automação da pesquisa de cluster não acrescentará muito a essa análise, mas vamos aplicar o algoritmo DBSCAN de qualquer maneira.... Usamos DBSCAN porque alguns dos grupos podem ser não globulares (por exemplo, k-means não funcionará corretamente neste banco de dados). Em teoria, precisamos calcular a distância geográfica entre os pontos, mas usaremos o sistema euclidiano, pois dá uma boa aproximação:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")

O algoritmo mostrou um resultado muito bom, mas eu revisaria os clusters da seguinte forma (levando em consideração o conhecimento dos distritos de negócios de Dublin):

Recusamos áreas com preços mais baixos, pois priorizamos a máxima qualidade de habitação e uma estrada confortável para trabalhar dentro nosso orçamento para que os Clusters 2, 3, 4, 6 e 9 possam ser excluídos. Observe que os Clusters 2, 3 e 4 estão localizados em algumas das áreas mais econômicas do norte de Dublin (provavelmente devido à infraestrutura de transporte público menos desenvolvida). O cluster 11 apresenta opções caras localizadas longe do trabalho, portanto, também podemos excluí-lo.
Olhando para os clusters mais caros, o número 7 é um dos melhores em termos de distância até o trabalho. isto Drumcondra , uma bela área residencial no norte de Dublin; apesar de não estar muito convenientemente localizado em relação à linha do bonde, as linhas de ônibus passam ao longo dele; no cluster 8, os preços da habitação e a distância ao trabalho são os mesmos que em Drumkondra. Outro cluster que vale a pena analisar é o de número 10: parece estar em uma área com menor oferta, o que significa que as pessoas aqui provavelmente raramente vendem habitação, e a área também está convenientemente localizada para vias públicas. Transporte (desde que todas as áreas tenham o mesmo densidade populacional).
Por fim, os clusters 1 e 5, localizados próximo ao Phoenix Park, o maior parque público cercado .
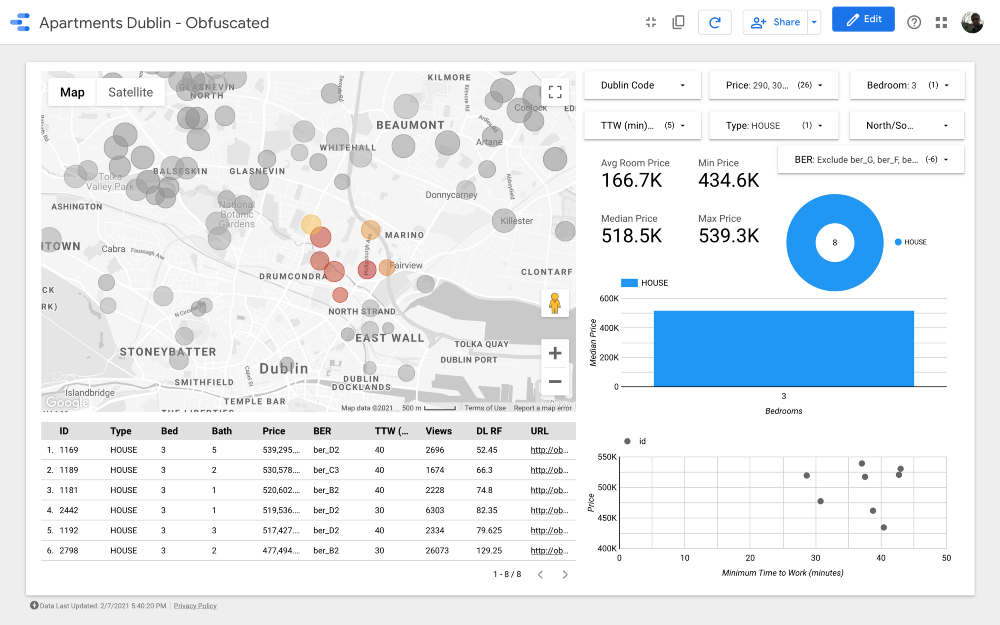
Cluster 7

Cluster 8
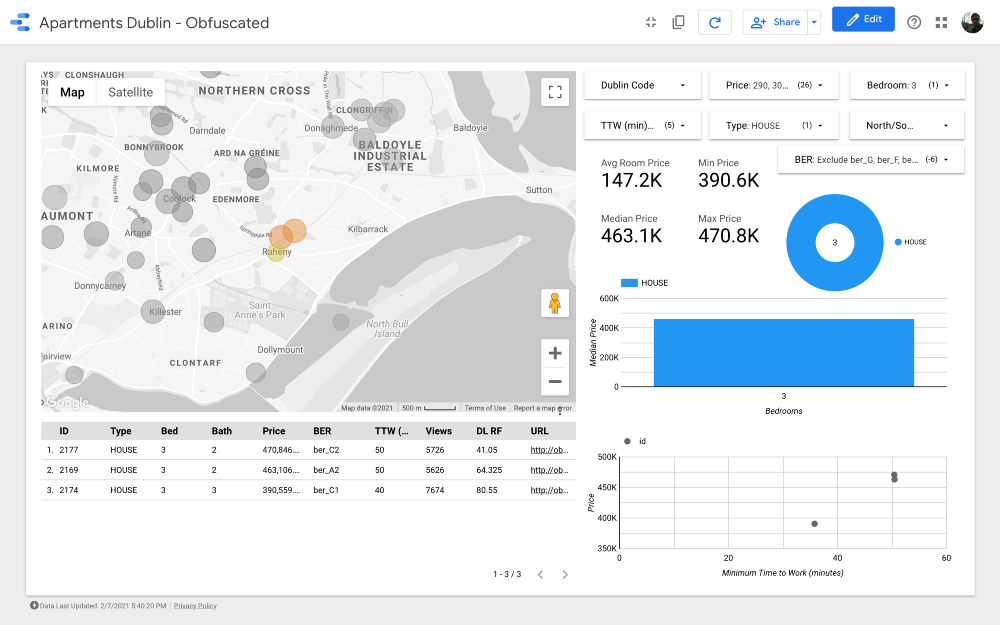
Cluster 10
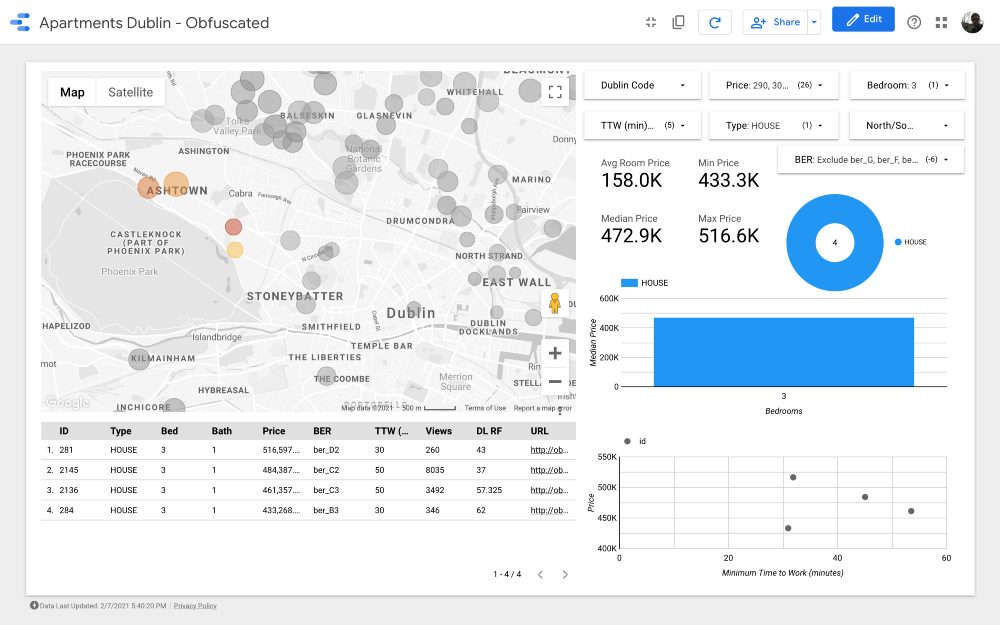
Cluster 1

Cluster 5
Ótimo! Encontramos 26 propriedades que valem a pena ver primeiro. Agora podemos analisar cuidadosamente cada oferta e, em última instância, marcar uma visita com um corretor de imóveis!
Conclusão
Começamos nossa busca, sem saber praticamente nada sobre Dublin, e no final conseguimos um bom entendimento de quais áreas da cidade são mais procuradas na hora de comprar uma casa.
Note, nós nem olhamos as fotos dessas casas e não lemos nada sobre elas! Apenas olhando para um painel bem organizado, chegamos a algumas conclusões úteis às quais não poderíamos ter chegado no início!
Esses dados não são mais úteis e algumas integrações podem ser feitas para melhorar a análise. Algumas reflexões:
1. Não integramos o conjunto de dados de amenidades (aquele que compilamos usando a API do Google Places) no estudo. Com um orçamento maior para serviços em nuvem, poderíamos facilmente adicionar essas informações ao painel.
2. Na Irlanda, muitos dados interessantes são publicados no site do serviço de estatística : por exemplo, você pode encontrar informações sobre o número de chamadas para cada delegacia de polícia por trimestre e por tipo de crime. Assim, poderíamos descobrir em quais áreas há mais furtos. Como é possível obter dados do censo para cada assembleia de voto, também podemos calcular a taxa de criminalidade per capita. Observe que, para tais recursos avançados, precisamos de um sistema de informação geográfica apropriado (por exemplo, QGIS ) ou um banco de dados que possa lidar com dados geográficos (por exemplo, PostGIS ).
3. A Irlanda tem um banco de dados de preços de casas anteriores, denominado Residential Property Register . Seu site contém informações sobre todos os imóveis residenciais adquiridos na Irlanda desde 1º de janeiro de 2010, incluindo a data de venda, preço e endereço. Ao comparar os preços atuais das residências com os anteriores, você pode ver como a demanda mudou ao longo do tempo.
4. Os preços do seguro residencial dependem, em grande medida, da localização da casa. Com algum esforço, poderíamos descartar os sites das seguradoras para integrar seu "modelo de fator de risco" em nosso painel.
Em um mercado como Dublin, encontrar uma nova casa pode ser uma tarefa difícil, especialmente para alguém que acabou de se mudar para a cidade e não conhece muito bem.
Graças a esta ferramenta, minha esposa e eu economizamos tempo (e ao corretor): fomos assistir 4 vezes, oferecemos o preço a 3 vendedores e um deles aceitou nossa oferta.