
O manuseio duplicado é um dos tópicos mais dolorosos no trabalho de um analista. Em nossa plataforma, tentamos automatizar este processo tanto quanto possível, a fim de reduzir a carga sobre os especialistas da NSI e aumentar a produtividade dos colegas com processamento de dados. Hoje veremos como a plataforma ajuda a formar um único registro dourado usando o exemplo de um dos livros de referência mais comuns e básicos - o diretório de “contrapartes”.
Vamos considerar um dos cenários típicos. Suponha que um grande distribuidor B2B receba mercadorias de diferentes fornecedores e as venda a clientes - pessoa jurídica. pessoas. Se na prática tudo está mais ou menos bem com a manutenção por parte do fornecedor, então o processamento da base de clientes às vezes requer toda uma equipe dedicada de especialistas. Isso se deve ao fato de que normalmente as empresas usam várias fontes de sistemas de dados de clientes: ERP, CRM, fontes abertas, etc. O trabalho é especialmente difícil quando há vários departamentos na empresa, cada um dos quais mantém sua própria base de clientes dentro o mesmo território ... Nesse caso, parte dos dados do cliente é duplicada na redistribuição de uma base e também se cruza implicitamente entre diferentes bases de clientes. Em um sistema ERP, o processamento sério de registros duplicados é necessário para obter o chamado registro mestre,com o qual você pode trabalhar no futuro. A plataforma Unidata possui um mecanismo especial para localização e processamento de registros duplicados, que realiza com sucesso tais tarefas.
Vamos começar
A plataforma é baseada no metamodelo do domínio utilizado. Domínio é um conjunto estruturado de registros, diretórios. seus atributos e as relações entre eles, que juntos descrevem a estrutura de dados do domínio. Falaremos sobre o próprio metamodelo mais tarde, mas agora veremos como a plataforma permite que você trabalhe com registros duplicados em um modelo de dados existente. Em nosso exemplo, existe um registro de "contrapartes", onde os principais atributos são: o nome da contraparte (geralmente abreviado e completo), TIN, KPP, endereços legais e reais, endereço de registro da pessoa jurídica, etc.
A plataforma usa um mecanismo de consolidação para lidar com duplicatas. A essência da consolidação é que definimos certas regras para encontrar duplicatas, definimos fontes de dados e para cada fonte de dados definimos pesos especiais que são responsáveis pelo nível de confiança das informações recebidas do sistema de origem e, em seguida, as duplicatas encontradas por o sistema é mesclado em um único registro de referência. Nesse caso, os registros duplicados desaparecem dos resultados da pesquisa, mas permanecem no histórico do registro de referência. Todas as configurações são feitas na interface do administrador da plataforma e não requerem programação. Se a mesclagem de registros for feita por engano, sempre haverá a possibilidade de desfazer a mesclagem. Dessa forma, a maior parte do trabalho com duplicatas é assumido pelo próprio sistema, o usuário só pode controlar esse processo.Consideremos a aplicação do mecanismo de consolidação nos casos do exemplo indicado.
Digamos que a plataforma Unidata foi introduzida no barramento de integração da empresa, que recebe dados de contrapartes do sistema CRM, sistema ERP e sistema de vendas móvel. A plataforma remove duplicatas, enriquece e harmoniza os dados e, em seguida, transfere os registros de referência para os sistemas receptores.
Caso 1. Correspondência de TIN e KPP
A maneira mais fácil de encontrar contrapartes duplicadas é compará-las por TIN e KPP; na maioria dos casos, até mesmo um TIN é suficiente. Para implementar essa regra de busca de registros duplicados, é suficiente configurar uma regra de correspondência exata para os atributos INN e KPP.
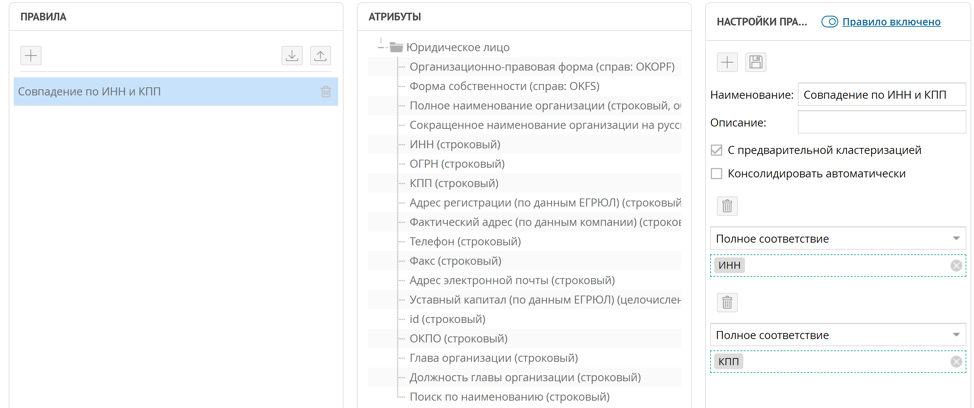
De acordo com esta regra, quando um novo registro chega à plataforma, a regra de pesquisa duplicada configurada é automaticamente lançada se a regra for definida como "pré-clustering". Todas as tuplas de registros encontradas por coincidência de INN e KPP são coletadas em clusters duplicados. Na janela de cluster duplicado, Unidata permite que você crie um registro mestre a partir de registros duplicados.
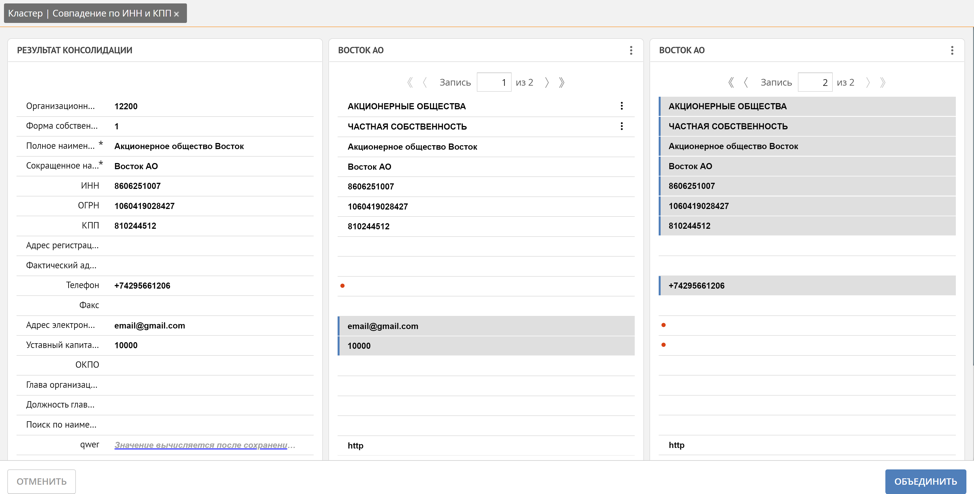
Aqui o usuário pode rastrear manualmente qual registro se torna automaticamente uma referência e, se necessário, corrigi-lo marcando manualmente os valores dos atributos dos registros duplicados que devem ser incluídos no registro de referência, ou marcando o registro inteiro. Além disso, o Unidata oferece suporte a um mecanismo para enriquecer valores ausentes com base em registros semelhantes. Por exemplo, telefone, correio e capital social foram obtidos automaticamente de 2 registros duplicados diferentes.
Como já observamos, a plataforma, ao formar um cluster de duplicatas, determina automaticamente como o registro de referência será formado. Isso ocorre devido aos pesos de confiança mencionados anteriormente dos sistemas de origem. Quanto maior o peso do sistema de onde veio o registro, mais significativos serão os valores de seus atributos para o registro de referência. Mas muitas vezes existem situações em que os valores de certos atributos para um determinado sistema de origem devem prevalecer sobre todos os outros, por exemplo, nós confiamos no endereço de entrega real do cliente acima de tudo para o agente que negocia diretamente no território do cliente e sabe o endereço exatamente, o que significa em nosso sistema de vendas móvel de exemplo. Para resolver esses problemas, a plataforma tem a capacidade de definir pesos não apenas para as fontes de dados, mas também para os atributos de registro no contexto de cada fonte de dados.Essa combinação de pesos permite configurar com flexibilidade as regras para gerar um registro de referência.

Caso 2. Correspondência difusa pelo nome da pessoa jurídica
Embora o TIN seja um atributo obrigatório, vamos supor que a informação do cliente não é atualizada há muito tempo, ele mudou sua forma organizacional e jurídica. Nesse caso, uma entrada com um TIN diferente já virá para a plataforma e a correspondência TIN não funcionará. Neste caso, a plataforma permite formar uma regra de fuzzy match pelo valor dos atributos, neste caso pelo nome da entidade legal.

A pesquisa difusa não possui clustering preliminar, já que esta operação consome muitos recursos, o que significa que esta regra não funcionará imediatamente quando um novo registro for adicionado. Para iniciar as regras de pesquisa difusa, uma operação especial de localização de duplicatas é usada, que é iniciada manualmente pelo administrador ou pelo sistema em uma programação. Depois que as duplicatas são localizadas, os clusters formados podem ser visualizados em uma seção especial da interface de operação de dados.

A pesquisa fuzzy duplicada funciona de forma que determinamos valores de string semelhantes que diferem em 1-2 caracteres ou requerem não mais do que duas permutações (distância de Levenshtein), há também a possibilidade de pesquisar por n-gramas. Esta abordagem permite que você encontre registros semelhantes com alta precisão, enquanto não carrega recursos para calcular todas as manipulações de string possíveis se as strings forem muito diferentes umas das outras.
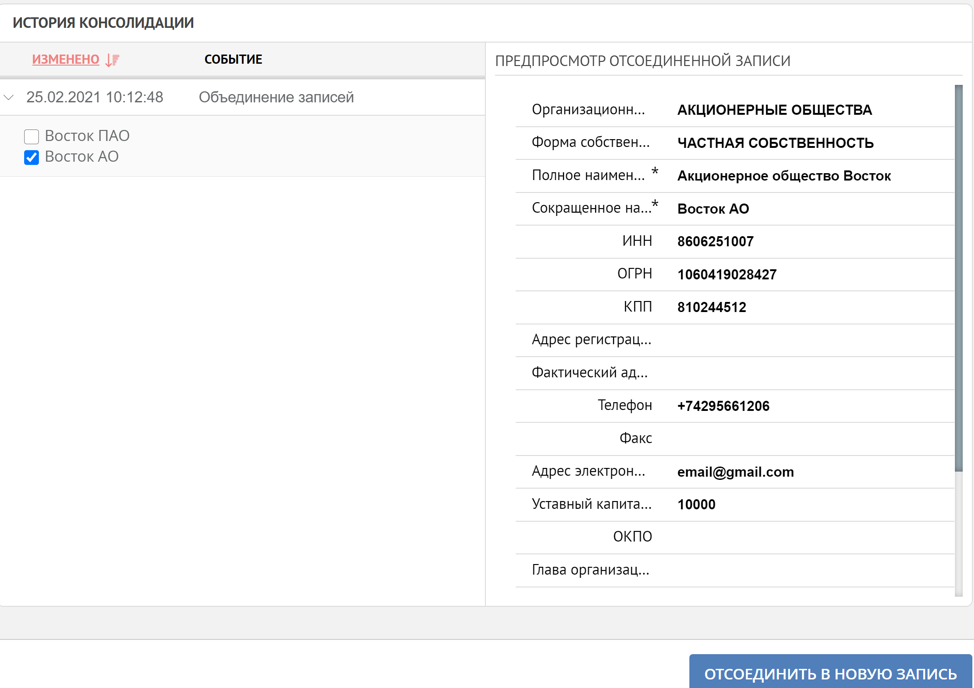
Assim, demonstramos em casos típicos simples os princípios da plataforma ao trabalhar com registros duplicados. O processamento duplicado pode ser executado completamente sob o controle do usuário ou automaticamente. Se a consolidação dos dados ocorreu por engano, então, conforme mencionado no início, o sistema sempre tem a oportunidade de visualizar o histórico de formação do registro de referência e, se necessário, iniciar o processo reverso.
Não paramos por aí, pesquisamos novos algoritmos e abordagens ao trabalhar com duplicatas, nos esforçamos para garantir a máxima qualidade de dados em uma variedade de sistemas corporativos.