
Quando falamos sobre CI&CD, muitas vezes nos aprofundamos nas ferramentas básicas para automatizar a construção, teste e entrega de aplicativos - focando nas ferramentas, mas esquecendo de cobrir os processos que ocorrem durante o corte e estabilização de lançamentos. No entanto, nem todas as ferramentas prontas são igualmente úteis e alguns processos personalizados não se encaixam em sua cobertura. Você tem que pesquisar os processos e encontrar maneiras de automatizá-los para otimizá-los.
Em nossa empresa, os engenheiros de QA usam o Zephyr para rastrear o progresso da regressão, uma vez que não podemos substituir os testes manuais e exploratórios por autotestes. Mas, apesar disso, os autotestes são frequentemente perseguidos aqui e em grandes quantidades, então quero ser capaz de omitir algumas verificações banais que foram automatizadas e permitir que os testadores façam um trabalho mais produtivo e útil.
Temos corridas noturnas onde suítes de teste completas estão sendo perseguidas. Mas no início de dominar o Zephyr, durante a regressão, nossos testadores tiveram que baixar xcresult, ou até mesmo plist anterior, ou junit xml, e então colocar as correspondências dos testes verdes e vermelhos em marshmallows com as mãos. Esta é uma operação bastante rotineira e leva muito tempo para passar de 500 a 600 testes manualmente. Você quer deixar essas coisas à mercê de uma máquina sem alma. Foi assim que nasceu o ZERG.
Zerg nasce
Zephyr Enterprise Report Generator é um pequeno utilitário que inicialmente sabia apenas como procurar correspondências no relatório de teste e enviar seus status atuais para o Zephyr. Posteriormente, o utilitário recebeu novas funções, mas hoje nos concentraremos em localizar e enviar relatórios.
No Zephyr, somos solicitados a operar com versões, loops e execuções de casos de teste. Cada versão contém um número arbitrário de ciclos e cada ciclo contém passagens de caso. Esses passes contêm informações sobre a tarefa (zephyr integra-se perfeitamente com jira e o caso de teste é, na verdade, uma tarefa em jira), o autor, o status do caso, bem como quem está envolvido neste caso e outros detalhes necessários .
Para automatizar o problema que descrevemos acima, é importante entendermos como definir o status do caso.
Trabalhando com código
Mas como você correlaciona o teste de código e o teste de marshmallow? Aqui, adotamos uma abordagem bastante simples e direta: para cada teste, adicionamos links para tarefas em jira na seção de comentários.
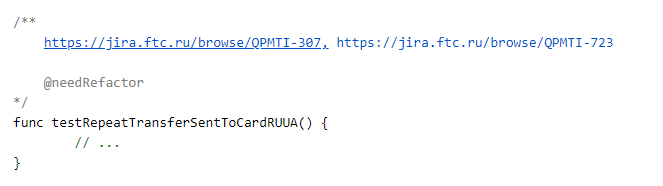
Parâmetros adicionais também podem ser colocados nos comentários, mas mais sobre isso mais tarde.
Portanto, um teste no código pode abranger várias tarefas. Mas a lógica reversa também funciona. Vários testes podem ser escritos em código para uma tarefa. Seus status serão levados em consideração na elaboração do relatório.
Precisamos examinar o código-fonte, extrair todas as classes e testes de teste, vincular tarefas a métodos e correlacionar isso com o relatório de aprovação no teste (xcresult ou junit).
Você pode trabalhar com o próprio código de diferentes maneiras:
- apenas leia os arquivos e recupere informações por meio de expressões regulares
- use o SourceKit
Seja como for, mesmo ao usar o SourceKit, não podemos prescindir de expressões regulares para extrair IDs de tarefas de links nos comentários.
Neste estágio, não estamos interessados em detalhes, então nos isolaremos deles com um protocolo:

Precisamos fazer testes. Para fazer isso, descrevemos as estruturas:
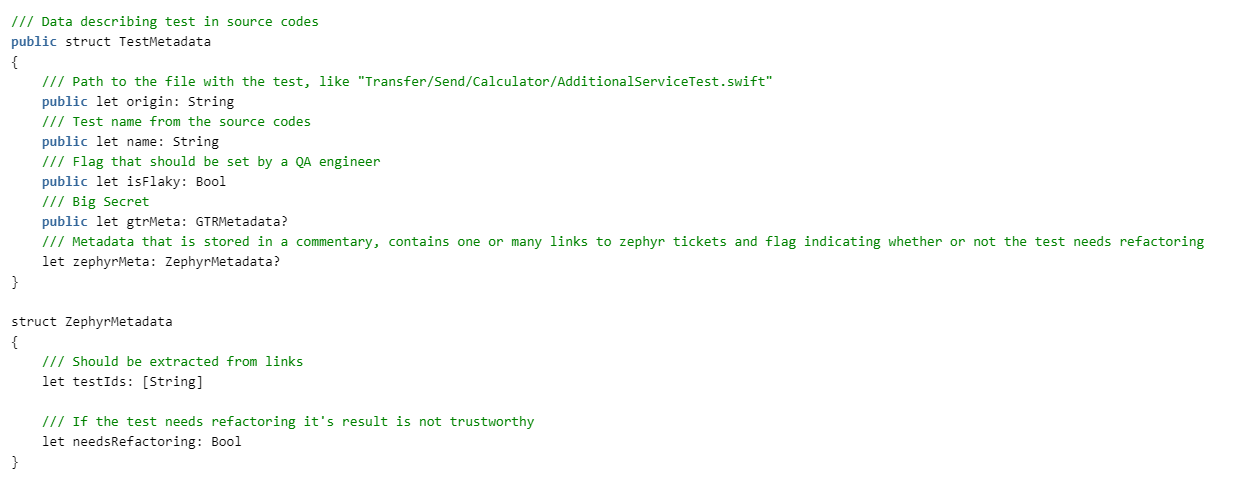
Em seguida, precisamos ler o relatório sobre a aprovação nos testes. ZERG nasceu antes de se mudar para xcresult e, portanto, pode analisar plist e junit. Ainda não estamos interessados nos detalhes deste artigo, eles serão anexados ao código. Portanto, vamos isolar os protocolos

Tudo o que resta é vincular os testes no código aos resultados dos testes dos relatórios.
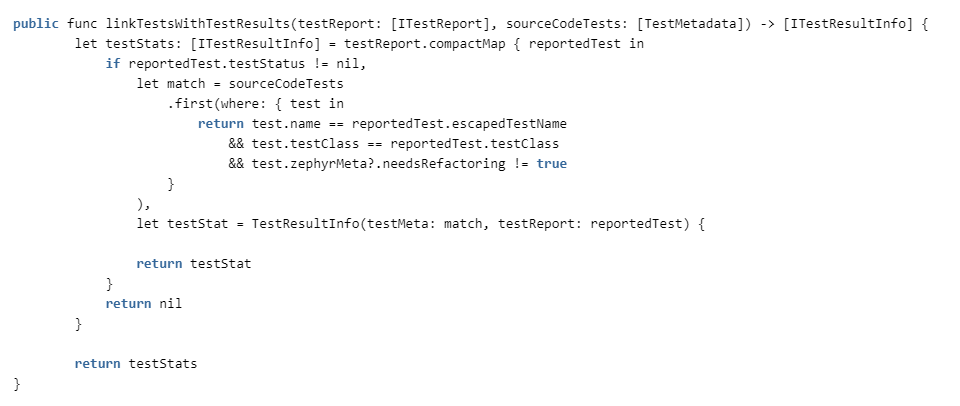
Verificamos a correspondência por nome de classe e nome de teste (classes diferentes podem ter métodos com o mesmo nome) e se a refatoração é necessária para o teste. Se você precisar, consideramos que não é confiável e o jogamos fora das estatísticas.
Trabalhamos com marshmallows
Agora que lemos os relatórios de teste, precisamos traduzi-los para o contexto zephyr. Para fazer isso, você precisa obter uma lista de versões do projeto, correlacionar com a versão do aplicativo (para que funcione assim, é necessário que a versão no marshmallow coincida com a versão no Info.plist do seu aplicativo , por exemplo, 2.56), fazer download de loops e passes. E então correlacionar os passes com nossos relatórios existentes.
Para fazer isso, precisamos implementar os seguintes métodos no ZephyrAPI: A
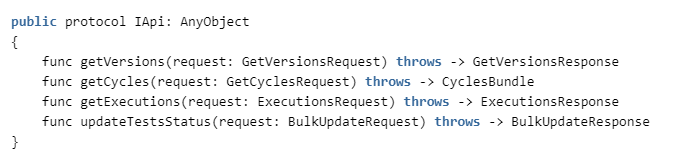
especificação pode ser vista aqui: getzephyr.docs.apiary.io , e a implementação do cliente está em nosso repositório.
O algoritmo geral é muito simples:
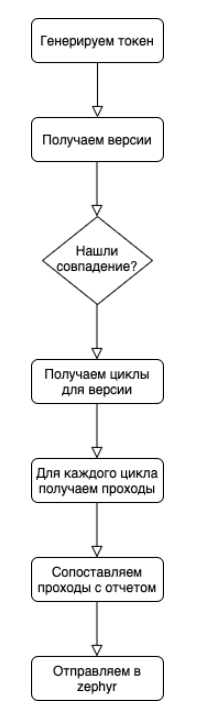
Na fase de correspondência de passes com relatórios, há um ponto sutil que deve ser levado em consideração: na API zephyr, é mais conveniente enviar a atualização de execução em lotes, onde o status geral e uma lista de IDs de passe são transmitidos . Precisamos expandir nossos relatórios de tíquetes e levar em consideração a proporção de nm. Para um caso em marshmallow, pode haver vários testes no código. Um teste no código pode abranger vários casos. Se, para um caso, houver n testes no código e um deles for vermelho, então, para tal caso, o status geral é vermelho, mas se um desses testes cobrir m casos e for verde, o restante dos casos deve não fica vermelho.
Portanto, operamos com conjuntos e procuramos a intersecção do vermelho e do verde. Qualquer coisa que caia na interseção subtraímos dos resultados verdes e enviamos as informações editadas para o zephyr.

Também deve ser observado aqui que dentro da equipe nós concordamos que zerg não mudará o status do passe se:
1. O status atual for bloqueado ou falhou (costumávamos mudar o status para falhou, mas agora desistimos prática, porque queremos que os testadores prestem atenção nos autotestes em vermelho durante a regressão).
2. Se o status atual for aprovado e tiver sido definido por uma pessoa, não por zerg.
3. Se o teste estiver marcado como piscando.
Interesses da API Zephyr
Ao solicitar loops, recebemos json, que à primeira vista não pode ser sistematizado para desserialização. O fato é que uma solicitação para obter loops para uma versão, embora deva retornar um array de loops, na verdade, retorna um objeto, onde cada campo é único e é chamado de identificador de loop, que está no valor. Para lidar com isso, usamos hacks simples: os

status de aprovação de teste vêm em uma das solicitações ao lado do objeto de solicitação. Mas eles podem ser movidos antecipadamente para enum:

ao solicitar loops, você precisa passar a versão e o identificador inteiro do projeto para os parâmetros de solicitação. Mas na solicitação de passes para o loop, o mesmo identificador de projeto deve ser passado em formato de string.

Em vez de uma conclusão
Se houver muito trabalho de rotina, provavelmente algo poderá ser automatizado. Sincronizar a passagem de autotestes com o sistema de gerenciamento de teste é um desses casos.
Assim, todas as noites realizamos um teste completo e, durante a regressão, o relatório é enviado aos engenheiros de QA. Isso reduz o tempo de regressão e dá tempo para testes exploratórios.
Se você implementar corretamente o analisador de origem do Android, ele poderá ser aplicado com o mesmo sucesso para a segunda plataforma.
Nosso Zerg, além de comparar testes, também consegue analisar o impacto inicial, mas mais sobre isso, talvez na próxima vez.