Nossos leitores não puderam deixar de notar nosso crescente interesse pela linguagem Go. Junto com o livro do post anterior , temos muitas coisas interessantes sobre esse assunto . Hoje queremos oferecer a você uma tradução do material "para profissionais", que demonstra aspectos interessantes do gerenciamento manual de memória em Go, bem como a execução simultânea de operações de memória em Go e C ++.
Na linguagem Dgraph Labs , Go usado desde a sua criação em 2015. Depois de cinco anos ou 200.000 linhas de código em movimento, pronto para anunciar com alegria que não é errado Go. Essa linguagem inspira não apenas como uma ferramenta para a criação de novos sistemas, mas também incentiva a escrita de scripts em Go que são tradicionalmente escritos em Bash ou Python. Acontece que Go permite que você crie uma base de código limpo, legível e sustentável que - o mais importante - é eficiente e fácil de manusear simultaneamente.
No entanto, há um problema com Go, que se manifesta já nos estágios iniciais de trabalho: gerenciamento de memória... Não tivemos nenhuma reclamação sobre o coletor de lixo Go, mas, além disso, o quanto simplifica a vida dos desenvolvedores, tem os mesmos problemas de outros coletores de lixo: simplesmente não consegue competir em eficiência com o gerenciamento manual de memória .
Gerenciar a memória manualmente resulta em menos uso de memória, uso de memória previsível e evita picos loucos no uso de memória quando um novo pedaço grande de memória é alocado nitidamente. Todos os problemas acima com gerenciamento automático de memória foram observados ao usar memória no Go.
Linguagens como Rust são capazes de ganhar uma posição em parte porque fornecem gerenciamento de memória manual seguro. Isso é bem-vindo.
Em minha experiência, alocar memória manualmente e rastrear possíveis vazamentos de memória é mais fácil do que tentar otimizar o uso de memória com ferramentas de coleta de lixo. A coleta de lixo manual compensa o incômodo de criar bancos de dados que oferecem escalabilidade virtualmente ilimitada.
Por amor ao Go e pela necessidade de evitar a coleta de lixo usando o Go GC, tivemos que encontrar maneiras inovadoras de gerenciar manualmente a memória no Go. Obviamente, a maioria dos usuários Go nunca precisará gerenciar a memória manualmente e recomendamos que você evite fazer isso, a menos que seja realmente necessário. E quando você precisar - você precisa saber como fazer .
Construindo memória com Cgo
Esta seção é modelada após o artigo Cgo wiki sobre a conversão de arrays C em segmentos Go. Poderíamos usar malloc para alocar memória em C e usar inseguro para passá-la para Go, sem exigir qualquer intervenção do coletor de lixo Go.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
No entanto, o acima é possível com a ressalva observada em golang.org/cmd/cgo.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Portanto, em vez de malloc, usaremos sua contraparte
calloc
um pouco mais pesada.
calloc
funciona exatamente assim
malloc
, com a ressalva de que redefine a memória para zero antes de retorná-la ao chamador.
Para começar, acabamos de implementar em sua forma mais simples as funções Calloc e Free que alocam e liberam segmentos de bytes para Go via Cgo. Para testar esses recursos, um teste contínuo de uso de memória foi desenvolvido e testado. ... Este teste, na forma de um loop infinito, repetiu um ciclo de alocação / liberação de memória, no qual primeiro fragmentos de memória de tamanho aleatório foram alocados até que o total de memória alocada atingiu 16 GB e, em seguida, esses fragmentos foram gradualmente liberados até que apenas 1 GB de memória foi alocado .
O programa C equivalente funcionou conforme o esperado. Nós
htop
vimos como a quantidade de memória alocada para o processo (RSS) recebe primeiro a 16GB, então cai para 1 GB, em seguida, cresce novamente para 16 GB, e assim por diante. No entanto, um programa Go usando
Calloc
e estava
Free
usando mais e mais memória após cada loop (consulte o diagrama abaixo).
Foi sugerido que isso se deve à fragmentação da memória devido à falta de "reconhecimento de thread" nas chamadas
C.calloc
padrão. Para evitar isso, decidiu-se tentar
jemalloc
.
jemalloc
jemalloc
É uma implementação genéricamalloc
que se concentra em evitar a fragmentação e manter a simultaneidade escalonável.jemalloc
foi usado pela primeira vez no FreeBSD em 2005 como um alocadorlibc
e, desde então, encontrou uso em muitos aplicativos devido ao seu comportamento previsível. - jemalloc.net
Trocamos nossas APIs para usar
jemalloc
com chamadas
calloc
e
free
. Além disso, essa opção funcionou perfeitamente: ela
jemalloc
oferece suporte nativo a fluxos com quase nenhuma fragmentação de memória. O teste de memória, que testou os ciclos de alocação e desalocação de memória, permaneceu dentro do razoável, exceto pela pequena sobrecarga envolvida na execução do teste.
Apenas para reforçar que estamos usando jemalloc e evitando conflitos de nomenclatura, adicionamos um prefixo durante a instalação
je_
para que nossas APIs agora chamem
je_calloc
e
je_free
, não
calloc
e
free
.
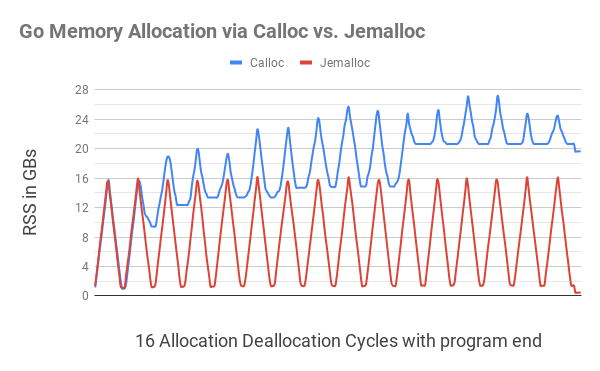
Esta ilustração mostra que alocar memória Go com
C.calloc
leva a uma séria fragmentação da memória, que faz com que o programa consuma até 20 GB de memória no 11º ciclo. O código equivalente
jemalloc
não deu nenhuma fragmentação perceptível, cabendo em cada ciclo próximo a 1GB.
Mais perto do final do programa (uma pequena ondulação na borda direita), depois que toda a memória alocada foi liberada, o programa
C.calloc
ainda consumia um pouco menos de 20 GB de memória, enquanto
jemalloc
custava apenas 400 MB de memória.
Para instalar o jemalloc, baixe-o aqui e execute os seguintes comandos:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
Todo o código
Calloc
é parecido com isto:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
Este código está incluído no pacote Ristretto . Uma tag de montagem foi adicionada para permitir que o código resultante alterne para jemalloc para alocar blocos de bytes
jemalloc
. Para simplificar ainda mais as operações de implantação, a biblioteca foi estaticamente vinculada
jemalloc
a qualquer binário Go resultante, definindo os sinalizadores LDFLAGS apropriados.
Decompondo estruturas Go em segmentos de bytes
Agora temos uma maneira de alocar e liberar um segmento de byte, e então usaremos isso para definir nossas estruturas em Go. Você pode começar com o exemplo mais simples (código completo).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
No exemplo acima, apresentamos a estrutura Go na memória alocada em C usando
newNode
. Criamos uma função apropriada
freeNode
que nos permite liberar memória assim que terminarmos com a estrutura. A estrutura na linguagem Go contém o tipo de dado mais simples
int
e um ponteiro para a próxima estrutura do nó, tudo isso pode ser configurado no programa, e então essas entidades podem ser acessadas. Selecionamos 2M de objetos de nó e criamos uma lista vinculada a partir deles para demonstrar que o jemalloc funciona conforme o esperado.
Com a alocação de memória padrão do Go, você pode ver que 31 MiB do heap está alocado a uma lista vinculada com 2M de objetos, mas nada é alocado
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
Usando a tag de montagem
jemalloc
, vemos que 30 bytes MiB de memória são alocados em
jemalloc
, e depois que a lista vinculada é liberada, esse valor cai para zero. Go aloca apenas 399 KiB da memória, o que provavelmente se deve ao overhead de execução do programa.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortizando Custos de Calloc com Alocador
O código acima faz um ótimo trabalho de alocação de memória no Go. Mas isso é feito às custas da degradação do desempenho . Tendo dirigido ambas as cópias com
time
, vemos que sem o
jemalloc
programa lidou com 1,15 segundos. Já
jemalloc
ela fez 5 vezes mais devagar, com mais de 5,29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
Essa lentidão pode ser atribuída ao fato de que as chamadas Cgo foram feitas para cada alocação de memória e cada chamada Cgo incorre em alguma sobrecarga. Para lidar com isso, a biblioteca Allocator foi escrita , também incluída no pacote ristretto / z . Essa biblioteca aloca segmentos de memória maiores em uma chamada, cada um dos quais pode acomodar muitos objetos pequenos, o que elimina a necessidade de chamadas Cgo caras .
O Allocator começa com um buffer e, assim que é usado, cria um novo buffer com o dobro do tamanho do primeiro. Ele mantém uma lista interna de todos os buffers alocados. Finalmente, quando o usuário terminar com os dados, podemos chamar Release para liberar todos esses buffers de uma só vez. Nota: O Allocator não move a memória. Isso garante que todos os ponteiros que temos para a estrutura continuem a funcionar.
Embora tal gerenciamento de memória possa parecer desajeitado e comparado a como operar
tcmalloc
e
jemalloc
, essa abordagem é muito mais simples. Depois de alocar memória, você não pode liberar apenas uma estrutura. Você só pode liberar toda a memória usada pelo Alocador de uma vez.
O que o Allocator é realmente bom é alocar milhões de estruturas de forma barata e então liberá-las quando o trabalho estiver concluído, sem ter que envolver um monte de Go para fazer o trabalho . A execução do programa acima com a nova tag de construção do alocador será ainda mais rápida do que a versão de memória Go.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
No Go 1.14 e posterior, o sinalizador
-race
permite verificações de alinhamento de estruturas na memória. O Allocator tem um método
AllocateAligned
que retorna memória, e o ponteiro deve estar alinhado corretamente para passar nessas verificações. Se a estrutura for grande, pode haver perda de memória, mas as instruções da CPU passam a funcionar de maneira mais eficiente devido à correta delimitação das palavras.
Ocorreu outro problema com o gerenciamento de memória. Acontece que a memória é alocada em um lugar e liberada em um lugar completamente diferente. Toda a comunicação entre esses dois pontos pode ser realizada por meio de estruturas, e eles só podem ser distinguidos pela transferência de um objeto específico
Allocator
. Para lidar com isso, atribuímos um ID exclusivo a cada objeto.
Allocator
que esses objetos armazenam na referência
uint64
. Cada novo objeto
Allocator
é armazenado no dicionário global com referência a uma referência a si mesmo. Objetos alocadores podem então ser recuperados usando esta referência e liberados quando os dados não forem mais necessários.
Organize os links com competência
NÃO faça referência à memória alocada Go da memória alocada manualmente.
Ao alocar manualmente uma estrutura conforme mostrado acima, é importante garantir que não haja referências à memória alocada pelo Go dentro dessa estrutura. Vamos modificar um pouco a estrutura acima:
type node struct {
val int
next *node
buf []byte
}
Vamos usar a função
root := newNode(val)
definida acima para selecionar manualmente um nó. Se então instalarmos
root.next = &node{val: val}
, alocando assim todos os outros nós na lista vinculada por meio da memória Go, inevitavelmente obteremos o seguinte erro de fragmentação:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
A memória alocada pelo Go está sujeita à coleta de lixo porque nenhuma estrutura Go válida aponta para ela. As referências são apenas da memória alocada em C e o heap de Go não contém nenhuma referência adequada, o que provoca o erro acima. Portanto, se você criar uma estrutura e alocar memória manualmente para ela, é importante garantir que todos os campos acessíveis recursivamente também sejam alocados manualmente.
Por exemplo, se a estrutura acima usou um segmento de byte, então alocamos esse segmento usando um Allocator e também evitamos misturar a memória Go com a memória C.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
Como lidar com gigabytes de memória dedicada
Allocator
bom para selecionar manualmente milhões de estruturas. Mas também há casos em que você precisa criar bilhões de pequenos objetos e classificá-los. Para fazer isso no Go, mesmo com ajuda
Allocator
, você precisa escrever um código como este:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
Todos esses nós 1B são alocados manualmente
Allocator
, o que é caro. Você também tem que gastar dinheiro em cada segmento de memória em Go, o que é bastante caro por si só, já que precisamos de 8 GB de memória (8 bytes por ponteiro de nó).
Para lidar com essas situações práticas, um
z.Buffer
arquivo mapeado em memória foi criado, permitindo que o Linux troque e libere as páginas de memória conforme o sistema requer. Ele implementa
io.Writer
e nos permite não depender
bytes.Buffer
.
Mais importante,
z.Buffer
fornece uma nova maneira de destacar segmentos de dados menores. Quando você liga
SliceAllocate(n)
,
z.Buffer
gravará o comprimento do segmento a ser selecionado
(n)
e, em seguida, selecione esse segmento. Isso torna
z.Buffer
mais fácil entender os limites do segmento e iterar sobre os segmentos corretamente com
SliceIterate
.
Classificando dados de comprimento variável
Para classificação, tentamos inicialmente obter os deslocamentos de segmento de
z.Buffer
, consultar os segmentos para comparação, mas classificar apenas os deslocamentos. Tendo recebido o deslocamento, ele
z.Buffer
pode lê-lo, encontrar o comprimento do segmento e retornar este segmento. Assim, esse sistema permite que você retorne os segmentos em uma forma ordenada sem recorrer a qualquer embaralhamento de memória. Por mais inovador que seja, esse mecanismo coloca uma pressão significativa na memória, já que ainda temos que pagar uma penalidade de 8 GB de memória apenas para empurrar as compensações de interesse para a memória Go.
O fator mais importante que limitava nosso trabalho era que os tamanhos não eram iguais para todos os segmentos. Além disso, poderíamos acessar esses segmentos apenas em ordem sequencial, e não na ordem inversa ou aleatória, não sendo possível calcular e armazenar os offsets com antecedência. A maioria dos algoritmos de classificação no local pressupõe que todos os valores têm o mesmo tamanho, podem ser acessados em qualquer ordem e nada impede que sejam trocados.
sort.Slice
in Go funciona de maneira semelhante e, portanto, não era adequado para
z.Buffer
.
Dadas essas limitações, concluiu-se que o algoritmo de merge sort é o mais adequado para a tarefa em questão. Com a classificação por mesclagem, você pode trabalhar em um buffer, executando operações em ordem sequencial, com a sobrecarga de memória adicional sendo apenas metade do tamanho do buffer. Ele acabou sendo não apenas mais barato do que mover o recuo para a memória, mas também melhora significativamente a previsibilidade em termos de sobrecarga de memória (metade do tamanho do buffer). Melhor ainda, a sobrecarga necessária para realizar a classificação por mesclagem é ela própria mapeada para a memória.
Há mais um efeito muito positivo no uso da classificação por mesclagem. A classificação de deslocamento deve manter os deslocamentos na memória enquanto iteramos sobre eles e processamos o buffer, o que apenas aumenta a pressão na memória. Com a classificação por mesclagem, toda a memória adicional necessária é liberada no momento em que a enumeração é iniciada, o que significa que teremos mais memória para processar o buffer.
O z.Buffer também suporta a alocação de memória
Calloc
, bem como o mapeamento automático de memória após exceder um certo limite especificado pelo usuário. Portanto, a ferramenta funciona bem com dados de qualquer tamanho.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Captura de vazamentos de memória
Toda essa discussão seria incompleta sem tocar no tópico de vazamentos de memória. Afinal, se alocarmos memória manualmente, os vazamentos de memória serão inevitáveis em todos os casos em que nos esquecemos de liberar memória. Como você pode pegá-los?
Há muito tempo usamos uma solução simples - usamos um contador atômico que rastreia o número de bytes alocados durante essas chamadas. Neste caso, você pode descobrir rapidamente quanta memória alocamos manualmente no programa usando
z.NumAllocBytes()
. Se ao final do teste de memória ainda tínhamos alguma memória extra, isso significava um vazamento.
Quando conseguimos encontrar um vazamento, primeiro tentamos usar o criador de perfil de memória jemalloc. Mas logo ficou claro que isso não ajudava - ele não viu toda a pilha de chamadas, pois estava esbarrando na fronteira de Cgo. Tudo o que o criador de perfil vê é a alocação de memória e os atos de liberação das mesmas chamadas
z.Calloc
e
z.Free
.
Graças ao tempo de execução Go, fomos capazes de construir rapidamente um sistema simples para capturar chamadores
z.Calloc
e mapeá-los para chamadas
z.Free
. Este sistema requer bloqueios mutex, então decidimos não habilitá-lo por padrão. Em vez disso, usamos o sinalizador de construção
leak
para habilitar mensagens de depuração para vazamentos em assemblies de desenvolvedor. Assim, os vazamentos são detectados automaticamente e exibidos no console exatamente onde se originaram.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Resultado
Com a ajuda das técnicas descritas, um meio-termo é alcançado. Podemos alocar memória manualmente em caminhos de código críticos que são altamente dependentes da memória disponível. Ao mesmo tempo, podemos aproveitar a coleta de lixo automática de maneiras menos críticas. Mesmo que você não seja muito bom em lidar com Cgo ou jemalloc, pode usar essas técnicas com pedaços relativamente grandes de memória em Go - o efeito será comparável.
Todas as bibliotecas mencionadas acima estão disponíveis sob a licença Apache 2.0 no pacote Ristretto / z . O teste de memória e o código de demonstração estão na pasta contrib .