
Como ter certeza de que qualquer desenvolvedor pode rapidamente apresentar uma solução para seu problema e garantidamente entregá-la à produção? A implantação do aplicativo é fácil. Torná-lo um produto completo para que uma dúzia de equipes o use em centenas de instâncias é mais difícil. E se estamos falando de um sistema mestre para vários terabytes, então o nível de ansiedade aumenta, as mãos suam e a base está explodindo (talvez).
Quero compartilhar uma maneira de implantar sem tempo de inatividade e sem negação de serviço. Pipeline de Jenkins, zero intermediários, 500 instâncias em um ambiente de produção em 60 minutos. Tudo isso está em código aberto. Para mais detalhes, convido você em cat.
Meu nome é Roman Proskin, eu crio e dou suporte a sistemas de alta carga baseados em Tarantool no Mail.ru Group. Vou contar como nossa equipe construiu uma implantação de aplicativo Tarantool, que atualiza o código em um ambiente de produção sem tempo de inatividade ou negação de serviço. Descreverei os problemas que encontramos no processo e as soluções que escolhemos no final. Espero que nossa experiência seja útil na construção de sua implantação.
A implantação de um aplicativo é fácil. Tarantool tem um utilitário cartucho-cli ( github) Com ele, o aplicativo em cluster será implantado em algum lugar do Docker em alguns minutos. É muito mais difícil transformar uma solução do joelho em um produto completo. Ele deve lidar facilmente com centenas de instâncias. Ao mesmo tempo, você precisa ser procurado em dezenas de equipes de diferentes níveis de treinamento.
A ideia por trás de nossa implantação é muito simples:
- Você pega dois servidores de ferro.
- Em cada um, você inicia uma instância.
- Combine-os em um conjunto de réplicas.
- Você atualiza um por um.
Mas quando se trata de um sistema mestre com vários terabytes de dados, o nível de ansiedade aumenta, as mãos suam e a base está explodindo (talvez).
Definir as condições iniciais
O sistema possui um SLA rígido: é necessário garantir 99% de disponibilidade, levando em consideração a obra planejada. Isso significa que há um total de 87 horas por ano em que podemos não responder a consultas. Parece que 87 horas é muito, mas ...
O projeto é projetado para um volume de dados de cerca de 1,8 TB. Só o reinício levará 40 minutos! A própria atualização, se as alterações forem feitas manualmente, adicionará mais informações acima. Fazemos três atualizações por semana: um total de 40 * 3 * 52/60 = 104 horas - o SLA é violado . E estes são apenas trabalhos planejados sem levar em conta os acidentes que certamente ocorrerão.
O aplicativo foi desenvolvido para uma alta carga de usuário, o que significa que ele teve que atender aos requisitos de estabilidade. Para não perder dados no caso de falha de um nó, decidimos dividir geograficamente nosso cluster em dois data centers. Portanto, decidimos por um mecanismo de implantação que não violasse o SLA. Deixe as instâncias serem atualizadas não imediatamente, mas em lotes nos datacenters.
A carga pode ser transferida para o segundo data center, então o cluster estará disponível para gravação durante toda a atualização. Esta é uma implantação clássica de ombro e uma das práticas padrão de recuperação de desastres .
A capacidade de atualização em data centers é um dos principais elementos de uma implantação com tempo de inatividade zero. Contarei mais sobre o processo no final do artigo, mas por agora vou me alongar nas características de nosso desdobramento desumano e nas dificuldades que encontramos.
Problemas
Nós transferimos o tráfego na estrada
Existem vários centros de dados e os pedidos podem ir para qualquer um deles. Uma viagem a um data center próximo para obter dados aumentará o tempo de resposta em 1 a 100 ms. Para evitar o tráfego cruzado, demos aos nossos data centers tags ativos e de espera . O balanceador (nginx) é configurado para que o tráfego sempre flua para o datacenter ativo. Se o Tarantool travar ou ficar indisponível no data center ativo, ele muda automaticamente para a reserva.
Cada solicitação do usuário é importante, portanto, você precisa de uma maneira de garantir que as conexões sejam mantidas. Para isso, escrevemos um playbook ansible separado que alterna o tráfego entre os data centers. A comutação é implementada usando uma diretiva
backup
na descrição
upstream
para o servidor. Os fluxos ascendentes são selecionados pelo limite, que se tornará ativo. O resto é prescrito
backup
: o nginx permitirá o tráfego neles somente se todos os ativos estiverem indisponíveis. Ao alterar a configuração, as conexões abertas não são fechadas e novas solicitações irão para roteadores que não estão sujeitos a reinicialização.
O que pode ser feito se a infraestrutura não tiver um balanceador de carga externo? Escreva seu próprio minibalanceador em Java que monitorará a disponibilidade de instâncias do Tarantool. Mas esse subsistema separado também exigirá sua própria implantação. Outra opção é construir um mecanismo de comutação dentro dos roteadores. Uma coisa permanece inalterada: o tráfego HTTP precisa ser controlado.
Resolvemos isso com o nginx, mas os problemas não pararam por aí. A comutação também deve ser feita para mestres em conjuntos de réplicas. Como mencionei, os dados devem ser mantidos próximos aos roteadores para evitar viagens de rede desnecessárias. Além disso, quando o mestre atual (ou seja, uma instância de armazenamento com acesso de gravação) falha, o mecanismo de failover não funciona imediatamente. Enquanto o cluster toma uma decisão geral sobre a indisponibilidade da instância, todas as solicitações para os dados afetados serão erradas. Para resolver esse problema, também precisamos compilar um manual, onde usamos consultas GraphQL para a API do cluster.
Os mecanismos para alterar os assistentes e o tráfego do usuário são os últimos elementos-chave de uma implantação sem tempo de inatividade. Um balanceador de carga controlado evita a perda de conexões e erros no processamento de solicitações do usuário e alteração de mestre - erros com acesso a dados. Junto com a atualização sobre os ombros desses três pilares, uma implantação tolerante a falhas é obtida, que automatizamos ainda mais.
Legado de luta
O cliente já tinha um mecanismo de distribuição pronto: funções que implementam e configuram instâncias passo a passo. Então nós viemos com o cartucho mágico ansible ( github) que resolverá todos os problemas. Não levamos em consideração apenas que o cartucho de ansible em si é um monólito - uma grande função, cujos diferentes estágios são separados por rótulos e tarefas separadas. Para utilizá-lo totalmente, foi necessário alterar o processo de entrega do artefato, revisar a estrutura do diretório nas máquinas de destino, alterar o orquestrador e muito mais. Passei um mês refinando a implantação usando cartucho ansible. O papel monolítico simplesmente não se encaixava nos manuais acabados. Não funcionou desta forma, e fui interrompido por uma só pergunta de um colega: "Precisamos disso?"
Não desistimos - separamos a configuração do cluster de uma única peça, a saber:
- combinar instâncias de armazenamento em conjuntos de réplicas;
- bootstrap vshard (mecanismo de fragmentação de dados de cluster);
- configurar failover (troca automática de masters em caso de queda).
Esses são os estágios finais da implantação, quando todas as instâncias estão ativas e em execução. Infelizmente, todas as outras etapas tiveram que ser deixadas como estão.
Escolha de um orquestrador
O código nos servidores é inútil se não puder ser executado. Precisamos de um utilitário para iniciar e parar as instâncias do Tarantool. O ansible-cartridge inclui tarefas para criar arquivos de serviço systemctl e trabalhar com pacotes rpm. Mas a especificidade da nossa tarefa era a presença de um circuito fechado no cliente e a ausência de privilégios de sudo. Isso significa que não podemos usar o systemctl.
Logo encontramos um orquestrador que não requer privilégios permanentes de root - supervisord... Tive que primeiro instalá-lo em todos os servidores e também resolver problemas locais com acesso ao arquivo de soquete. Uma nova função ansible apareceu para trabalhar com supervisord: inclui tarefas para criar arquivos de configuração, atualizar a configuração, iniciar e interromper instâncias. Isso foi o suficiente para colocá-lo em produção.
Para fins de experiência, adicionamos a capacidade de executar o aplicativo usando supervisord em ansible-cartridge. Este método acabou sendo menos flexível e ainda está aguardando conclusão em uma ramificação separada.
Reduzindo o tempo de carregamento
Seja qual for o orquestrador que usarmos, não podemos esperar uma hora para que a instância seja iniciada. O limite é de 20 minutos. Se a instância ficar indisponível por mais tempo do que esse limite, uma falha automática será acionada e registrada no sistema de contabilidade. Acidentes frequentes afetam o desempenho-chave das equipes e podem prejudicar os planos de desenvolvimento do sistema. Não quero perder o prêmio de forma alguma por causa da implantação banalmente necessária. Certamente, você precisa manter dentro de 20 minutos.
Fato: O tempo de download depende diretamente da quantidade de dados. Quanto mais você precisa aumentar dos registros para a RAM, mais tempo a instância inicia após a atualização. Você também precisa levar em consideração que as instâncias de armazenamento na mesma máquina competirão por recursos: Tarantool usa todos os núcleos do processador para construir índices.
Com base em nossas observações, o tamanho
memtx_memory
por instância não deve exceder 40 GB. Esse valor é ideal para que a recuperação da instância leve menos de 20 minutos. O número de instâncias em um servidor é calculado separadamente e está intimamente relacionado à infraestrutura do projeto.
Nós conectamos o monitoramento
Qualquer sistema precisa ser monitorado e Tarantool não é exceção. Nosso monitoramento não apareceu imediatamente. Todo um quarteirão foi gasto na obtenção do acesso necessário, na homologação e na configuração do ambiente.
No processo de desenvolvimento do aplicativo e de criação de manuais, modificamos ligeiramente o módulo de métricas ( github ). Agora você pode dividir as métricas pelo nome da instância da qual elas voaram - rótulos globais feitos. Como resultado da integração com sistemas de monitoramento, toda uma função surgiu para aplicativos de cluster. O novo tipo de métrica de quantil também emergiu da generalização dos requisitos para nosso sistema.
Agora vemos o número atual de solicitações ao sistema, o tamanho da memória usada, o atraso de replicação e muitas outras métricas importantes. Além disso, eles são configurados com notificações em chats. Os problemas mais críticos se enquadram no sistema geral de acidentes de carro e têm um SLA claro para eliminação.
Um pouco sobre as ferramentas. Uma descrição detalhada de onde, o que e como obter é coletada no etcd , de onde o agente do telegraf recebe suas instruções. As métricas formatadas em JSON são armazenadas no InfluxDB . Usamos o Grafana como visualizador , para o qual até escrevemos um painel de modelo . E, finalmente, os alertas são configurados por meio de kapacitor .
Claro, esta está longe de ser a única opção para implementar o monitoramento. Você pode usar o Prometheus , e métricas só sabe como fornecer valores no formato exigido. Para alertas, o zabbix também pode ser útil , por exemplo.
Meu colega me contou mais sobre como configurar o monitoramento do Tarantool no artigo " Monitorando o Tarantool: Logs, métricas e seu processamento ".
Configurando o registro
Você não pode se limitar a monitorar. Para ter uma visão completa do que está acontecendo com o sistema, todos os diagnósticos devem ser coletados, e isso também inclui logs. Além disso, quanto mais alto o nível de registro, mais informações de depuração e maiores serão os arquivos de registro.
O espaço em disco não é infinito. Nosso aplicativo pode gerar até 1 TB de logs por dia no pico de carga. Em tal situação, você pode adicionar discos, mas mais cedo ou mais tarde o espaço livre ou o orçamento do projeto acabará. Mas você também não quer perder informações de depuração sem deixar rastros! O que fazer?
Em um dos estágios de implantação, adicionamos a configuração logrotate: mantenha alguns arquivos de 100 MB brutos e comprima mais alguns. Em operação normal, isso é suficiente para localizar um problema local em 24 horas. Os registros são armazenados em um diretório estritamente definido no formato JSON. Todos os servidores executam o daemon filebeat , que coleta logs de aplicativos e os envia para armazenamento de longo prazo para ElasticSearch . Essa abordagem evita erros de estouro de disco e permite que você analise o desempenho do sistema em caso de problemas de longo prazo. E essa abordagem se encaixa bem na implantação.
Escalamos a solução
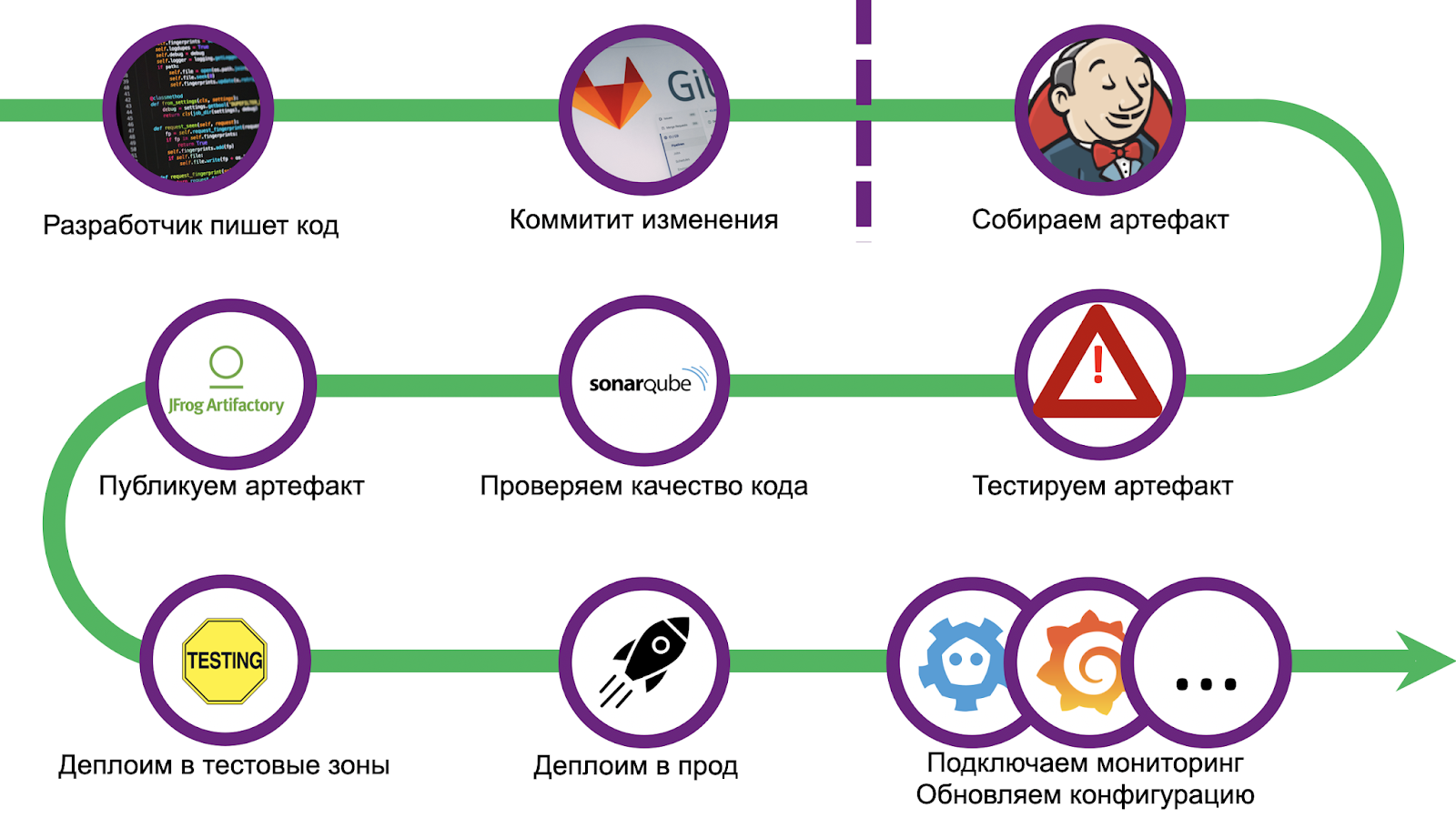
O caminho era longo e espinhoso, conseguimos uma quantidade razoável de cones. Para não repetir erros, padronizamos a implantação e usamos o pacote CI / CD - Gitlab + Jenkins. O escalonamento também causou uma série de problemas, depurar a solução levou mais de um mês. Mas nós superamos e agora estamos prontos para compartilhar nossa experiência com você. Vamos percorrer as etapas.
Como ter certeza de que qualquer desenvolvedor pode rapidamente apresentar uma solução para seu problema e garantidamente entregá-la à produção? Tire o Jenkinsfile dele! É necessário traçar limites arrojados, indo além do que significa a impossibilidade de implantação, e direcionar o desenvolvedor por esse caminho.
Fizemos um aplicativo de amostra completo, que foi implementado da mesma maneira e que é um ponto de partida exaustivo. Mas fomos ainda mais longe com o cliente: escrevemos um utilitário para criar automaticamente um modelo que configura um repositório git e tarefas Jenkins. O desenvolvedor precisará de menos de uma hora para tudo sobre tudo, e o projeto estará em produção.
O pipeline começa com uma verificação de código padrão e configuração de ambiente. Além disso, colocamos inventário para implantação subsequente em várias zonas de teste funcional e produção. Em seguida, vem a fase de teste de unidade.
A estrutura de teste padrão do Tarantool luatest ( github) Você pode escrever testes de unidade e integração nele, existem módulos auxiliares para executar e configurar o cartucho Tarantool . Também nas versões recentes, você pode ativar a cobertura . Começamos com um comando simples:
.rocks/bin/luatest --coverage
No final dos testes, as estatísticas recolhidas são enviadas para o SonarQube - software de avaliação da qualidade e segurança do código. No interior, já configuramos o Quality Gate. Qualquer código da aplicação, independentemente da linguagem (Lua, Python, SQL, etc.), é validado. No entanto, não há um manipulador embutido para Lua, portanto, para representar a cobertura em formato genérico, temos plug-ins que são instalados antes do início dos testes.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
Uma versão de console simples pode ser vista assim:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
O relatório para SonarQube é gerado pelo comando:
.rocks/bin/luacov -r sonar
Depois da cobertura, vem o estágio do linter. Estamos usando luacheck ( github ), que também é um dos plug-ins do Tarantool.
tarantoolctl rocks install luacheck 0.26.0-1
Os resultados do Linter também são enviados ao SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Estatísticas de cobertura de código e linters são contados juntos. Para passar pelo Quality Gate, todas as condições devem ser atendidas:
- a cobertura do código por testes deve ser de pelo menos 80%;
- as mudanças não devem introduzir novos odores;
- o número total de problemas críticos é 0;
- o número total de estoques não críticos é inferior a 5.
Depois de passar pelo Quality Gate, você precisa assar o artefato. Como decidimos que todos os aplicativos usarão o Tarantool Cartridge, usamos o cartucho-cli ( github ) para a construção . Este é um pequeno utilitário para executar (na verdade, desenvolver) aplicativos do Tarantool em cluster localmente. Ela também sabe criar imagens e arquivos do Docker com o código do aplicativo, tanto localmente quanto no Docker (por exemplo, se você precisar construir um artefato para uma arquitetura diferente). A montagem
tar.gz
é realizada pelo comando:
cartridge pack tgz --name <nme> --version <vrsion>
O arquivo resultante é então carregado para qualquer repositório, por exemplo, para Artifactory ou Mail.ru Cloud Storage .
Implante sem tempo de inatividade
E a etapa final do pipeline é a implantação em si. Dependendo do estado das edições, a rolagem é realizada em diferentes zonas de teste. Uma zona é alocada para qualquer espirro: cada envio para o repositório inicia o pipeline inteiro. Existem também várias áreas funcionais onde você pode testar a interação com sistemas externos, para isso você precisa criar uma solicitação de mesclagem na ramificação mestre do repositório. Mas, na produção, a rolagem é iniciada somente depois que as alterações são aceitas e o botão de mesclagem é pressionado.
Deixe-me lembrá-lo dos principais elementos de nossa implantação sem tempo de inatividade:
- atualização para data centers;
- alternar mestres em conjuntos de réplicas;
- configurar o balanceador para um datacenter ativo.
Ao atualizar, você precisa monitorar a compatibilidade das versões e do esquema de dados. A atualização será interrompida se ocorrer um erro em qualquer uma das etapas.
A atualização pode ser representada esquematicamente da seguinte forma:
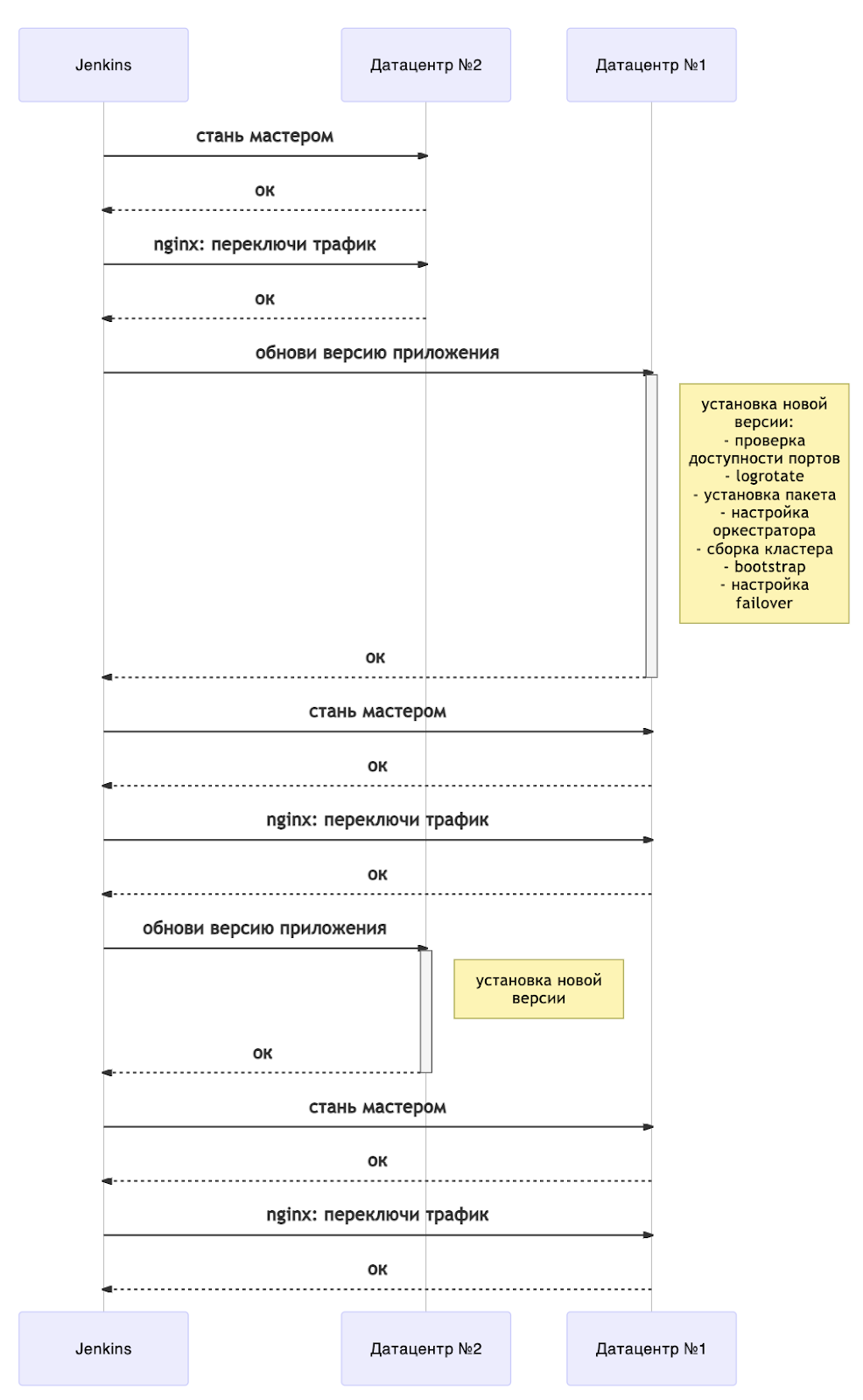
Agora, qualquer atualização é acompanhada por uma reinicialização do servidor. Para entender quando você pode continuar implantando, temos um manual separado de espera pelo estado das instâncias. O Tarantool Cartridge tem uma máquina de estados, e estamos aguardando o estado RolesConfigured , o que significa que a instância está totalmente configurada (e para nós, está pronta para aceitar solicitações). Se o aplicativo for implantado pela primeira vez, você precisará aguardar o estado Desconfigurado .
No geral, o diagrama mostra uma visão geral de uma implantação sem tempo de inatividade. É facilmente escalonável para mais data centers. Dependendo de suas necessidades, você pode atualizar todos os "braços" de backup imediatamente após alterar os mestres (ou seja, junto com o data center nº 1) ou um por um.
Claro, não poderíamos deixar de trazer nossos desenvolvimentos para o código aberto. Até agora, eles estão disponíveis em meu fork do cartucho ansible ( opomuc / ansible-cartridge ), mas há planos de movê-lo para o branch master do repositório principal.
Um exemplo pode ser encontrado aqui ( exemplo ). Para que funcione corretamente, o servidor deve estar configurado
supervisord
para o usuário
tarantool
. Os comandos de configuração podem ser encontrados aqui . O arquivo com o aplicativo também deve conter um binar
tarantool
.
A sequência de comandos para iniciar a implantação do ombro:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
O parâmetro
base_dir
indica o caminho para o diretório "inicial" do projeto. Após a implementação, os subdiretórios serão criados:
<base_dir>/run
- para soquetes de controle e arquivos pid;<base_dir>/data
- para arquivos .snap e .xlog, bem como configuração do Tarantool Cartridge;<base_dir>/conf
- para configurações de aplicativos e instâncias específicas;<base_dir>/releases
- para controle de versão e código-fonte;<base_dir>/instances
- para links para a versão atual de cada instância do aplicativo.
O parâmetro
cartridge_package_path
fala por si, mas há uma peculiaridade:
- se o caminho começar com
http://
ouhttps://
, o artefato será pré-carregado da rede (por exemplo, do artefato gerado próximo a ele). - em outros casos, o arquivo é pesquisado localmente
O parâmetro
app_version
será usado para controle de versão na pasta
<base_dir>/releases
. O padrão é
latest
.
A tag
supervisor
significa que ela será usada como orquestrador
supervisord
.
Existem muitas opções para iniciar uma implantação, mas a mais confiável é a boa e velha
Makefile
. O comando condicional
make deploy
pode ser incluído em qualquer CI \ CD e tudo funcionará exatamente da mesma forma.
Resultado
Isso é tudo! Agora temos um pipeline pronto no Jenkins, nos livramos dos intermediários e a velocidade de entrega das alterações tornou-se insana. O número de usuários está crescendo, no ambiente de produção já são 500 instâncias implantadas exclusivamente com a nossa solução. Temos espaço para crescer.
E embora o processo de implantação em si esteja longe de ser ideal, ele fornece uma base sólida para o desenvolvimento de processos DevOps. Você pode levar nossa implementação com segurança para entregar rapidamente o sistema à produção e não ter medo de fazer edições frequentes.
E também será uma lição para nós de que é impossível trazer um monólito e esperar por seu uso generalizado: precisamos de uma decomposição de cartilhas, a atribuição de papéis para cada etapa da instalação, uma forma flexível de apresentar inventário. Algum dia nossos desenvolvimentos serão incluídos no master e tudo ficará ainda melhor!
Links
- Um guia passo a passo para cartucho ansible:
- Você pode ler sobre Tarantool Cartridge aqui .
- Sobre a implantação no Kubernetes:
- Monitoramento Tarantool: logs, métricas e seu processamento .
- Para obter ajuda, entre em contato com o chat do Telegram .