
Com 12 questões atrás de nós, é hora de mudar um pouco o nome e design, mas por dentro você ainda está esperando por pesquisas, demonstrações, modelos abertos e conjuntos de dados. Conheça a nova edição do Machine Learning Toolkit.
DALL E
Acessibilidade: página do projeto / acesso à API fechada via lista de espera A
OpenAI apresentou seu novo modelo de linguagem de transformador DALL-E com 12 bilhões de parâmetros, treinados em pares imagem-texto. O modelo é baseado no GPT-3 e é usado para sintetizar imagens a partir de descrições textuais.
Em junho passado, a empresa mostrou como um modelo treinado em sequências de pixels com uma descrição precisa pode preencher lacunas nas imagens que são alimentadas na entrada. Os resultados já eram impressionantes, mas aqui o Open AI superou todas as expectativas. Assim como o GPT-3 sintetiza frases completas coerentes, o DALL · E cria imagens complexas.

Os modelos são surpreendentemente bons em objetos antropomórficos (rabanetes passeando com o cachorro) e uma combinação de objetos incompatíveis (um caracol em forma de harpa), razão pela qual eles escolheram a fusão de dois nomes para o nome - o surrealista espanhol Salvador Dali e o robô da Pixar WALL-I.
Então, quais são os resultados que o modelo apresenta?
O modelo é capaz de visualizar a profundidade do espaço, portanto, é possível manipular uma cena tridimensional. Basta, ao descrever a imagem desejada, indicar de que ângulo o objeto deve ser visto e sob qual iluminação. No futuro, isso permitirá a criação de verdadeiras representações 3D.
Além disso, o modelo é capaz de aplicar efeitos óticos à cena, por exemplo, como ao fotografar com uma lente olho de peixe. Mas até agora ele não lida bem com os reflexos - o cubo no espelho não foi sintetizado de forma convincente. Assim, com vários graus de confiabilidade, o DALL · E por meio de linguagem natural lida com as tarefas para as quais os motores de modelagem 3D são usados na indústria. Isso permite que ele seja usado para renderizar o design do ambiente.
A modelo conhece bem a geografia e os marcos icônicos, bem como as características distintivas de cada época. Ela pode sintetizar uma fotografia de um telefone antigo ou da Ponte Golden Gate em São Francisco.
Com tudo isso, o modelo não precisa de uma descrição ultraprecisa - ele próprio preencherá algumas lacunas. Conforme observado pelo Open AI, quanto mais precisa a descrição, pior o resultado.
Lembre-se de que o GPT-3 é um modelo zero-shot e não precisa ser configurado e treinado adicionalmente para executar tarefas específicas. Além da descrição, você pode dar uma dica para que o modelo gere a resposta desejada. O DALL · E faz o mesmo com a renderização e pode realizar várias tarefas de conversão de imagem em imagem com base em prompts. Por exemplo, você pode fornecer uma imagem como entrada e pedir para criá-la na forma de um esboço.
Surpreendentemente, os criadores não se propuseram tal objetivo e não o previram de forma alguma ao treinar o modelo. A habilidade foi revelada apenas durante o teste.
Guiados por essa descoberta, os autores estudaram a capacidade do DALL · E de resolver problemas lógicos do teste de QI visual e definir a tarefa não de escolher a resposta correta das opções apresentadas, mas de prever totalmente o elemento ausente.
Em geral, o modelo conseguiu continuar corretamente a sequência na parte das tarefas em que era necessária a compreensão geométrica.
O modelo ainda não foi publicado, e não há nem mesmo uma descrição aproximada de sua arquitetura. Neste estágio, você pode solicitar acesso à API ou verificar a implementação não oficial no PyTorch ( uma versão não oficial no TensorFlow também está sendo trabalhada ).
CLIP (linguagem contrastiva - pré-treinamento de imagem)
Acessibilidade: Página do projeto / Código-fonte
Deep Learning revolucionou a visão computacional, mas as abordagens atuais ainda apresentam dois problemas significativos que colocam em dúvida o uso de DNN nesta área.
Em primeiro lugar, a criação de conjuntos de dados permanece muito cara, mas, ao mesmo tempo, como resultado, permite o reconhecimento de um conjunto muito limitado de imagens visuais e é adequada para tarefas restritas. Por exemplo, ao preparar o conjunto de dados ImageNet, foram necessárias 25.000 pessoas para compor descrições de 14 milhões de imagens para 22.000 categorias de objetos. Ao mesmo tempo, o modelo ImageNet é bom para prever apenas as categorias que estão representadas no conjunto de dados e, se qualquer outra tarefa for necessária, os especialistas terão que criar novos conjuntos de dados e concluir o treinamento do modelo.
Em segundo lugar, os modelos com bom desempenho em benchmarks ficam aquém em seu ambiente natural. Os modelos implantados no mundo real não funcionam tão bem quanto em um ambiente de laboratório. Em outras palavras, o modelo é otimizado para passar em um teste específico como um aluno que estuda as questões anteriores do exame.
A rede neural aberta CLIP da OpenAI visa resolver esses problemas. O modelo é treinado em um grande número de imagens e descrições de texto disponíveis na Internet e os traduz em representações vetoriais, embeddings. Essas representações são comparadas de forma que os números da inscrição e da imagem adequada para ela sejam próximos.
O CLIP pode ser testado imediatamente em diferentes benchmarks sem treinamento em seus dados. O modelo executa testes de classificação sem otimização direta. Por exemplo, o teste ObjectNet testa a capacidade do modelo de reconhecer objetos em diferentes locais e com fundos variáveis, enquanto o ImageNet Rendition e o ImageNet Sketch testam a capacidade do modelo de reconhecer imagens mais abstratas de objetos (não apenas uma banana, mas uma banana fatiada ou esboço de banana). CLIP funciona igualmente bem em todos eles.
O CLIP pode ser adaptado para realizar uma ampla gama de tarefas de classificação visual sem exemplos adicionais de treinamento. Para aplicar CLIP a um novo problema, basta dar ao codificador os nomes das representações visuais, e ele produzirá um classificador linear dessas representações, que não é inferior em precisão aos modelos treinados com o professor.
O Github já possui uma implementação para fotos com Unsplash, que mostra o quão bem o modelo agrupa as imagens. Os designers já podem usá-lo para criar moodboards.
DeBERTa by Microsoft
Disponibilidade: Fonte / Página do Projeto
Como de costume, as notícias da OpenAI eclipsaram outros anúncios, embora houvesse outro evento que foi discutido ativamente na comunidade. O modelo DeBERTa da Microsoft superou a linha de base humana no teste SuperGLUE Natural Language Comprehension (NLU).
Um benchmark baseado em 10 parâmetros determina se o algoritmo “entende” o que leu e faz uma classificação. A pontuação média para não especialistas é de 89,8 pontos, e os problemas que os modelos precisam resolver são comparáveis a um exame de inglês. DeBERTa mostrou 90,3, seguido por T5 + Meena do Google.
Dessa forma, o modelo conseguiu ultrapassar um humano pela segunda vez, mas vale ressaltar que o DeBERTa possui 1,5 bilhão de parâmetros de treinamento, 8 vezes menos que o T5.
O modelo representa um novo, diferente do transformador original, mecanismo de atenção dividida, onde cada token é codificado por vetores de conteúdo e posições que não se somam em um vetor, matrizes separadas trabalham com eles.
NeuralMagicEye
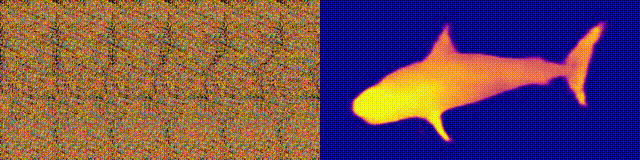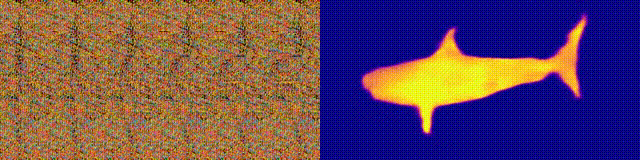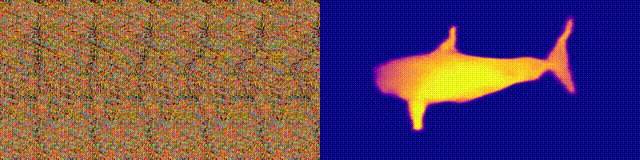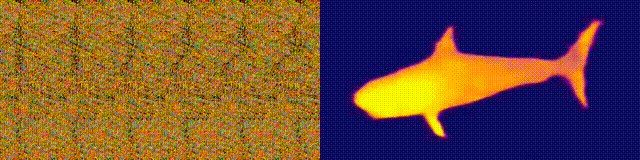
Acessibilidade: página / código / colab do projeto
Lembra-se dos álbuns do Magic Eye com estereogramas? Aqui está algo semelhante, apenas para autostereogramas, em que ambas as partes do estereopar estão na mesma imagem e codificadas em uma estrutura raster, de modo que pode criar ilusões visuais de tridimensionalidade.
O autor do estudo treinou o modelo da CNN para reconstruir a profundidade do autoestereograma e entender seu conteúdo. Para alcançar o efeito estéreo, o modelo teve que ser treinado para detectar e avaliar a incompatibilidade de texturas quase periódicas. O modelo foi treinado em um conjunto de dados de modelos 3D, sem um professor.
O método permite restaurar com precisão a profundidade do autoestereograma. Os pesquisadores esperam que isso ajude as pessoas com deficiência visual, e os estereogramas podem ser usados como marcas d'água em imagens.
StyleFlow

Acessibilidade: Código-fonte
Como vimos mais de uma vez, GANs incondicionais (como StyleGANs) podem criar imagens fotorrealistas de alta qualidade. No entanto, raramente é possível gerenciar o processo de geração usando atributos semânticos, mantendo a qualidade da saída. Devido à latência GAN complexa e confusa, editar um atributo geralmente resulta em alterações indesejadas em outros. Este modelo ajuda a resolver esse problema. Por exemplo, você pode alterar o ângulo de visão, variação de iluminação, expressão, pelos faciais, sexo e idade.
Transformadores Domadores
Acessibilidade: página do projeto / código-fonte Os
transformadores são capazes de fornecer resultados excelentes em uma variedade de aplicações. Mas em termos de potência de computação, eles são muito exigentes, por isso não são adequados para trabalhar com imagens de alta resolução. Os autores do estudo combinaram um transformador com uma rede convolucional deslocada indutivamente e conseguiram obter imagens em alta resolução.
POse EMbedding

Acessibilidade: código-fonte
As atividades do dia a dia, seja correr ou ler um livro, podem ser pensadas como uma sequência de posturas, consistindo na posição e orientação do corpo de uma pessoa no espaço. O reconhecimento de pose abre uma série de possibilidades em AR, controle de gestos, etc. No entanto, os dados obtidos da imagem 2D diferem dependendo do ponto de vista da câmera. Este algoritmo do Google AI reconhece a semelhança de poses de diferentes ângulos, combinando os pontos principais da exibição 2D da pose com a incorporação invariante de visualização.
Aprendendo a aprender
Acessibilidade: Código-fonte
Para aprender como pegar ou colocar uma garrafa na mesa, só precisamos ver outra pessoa fazendo isso. Para aprender como operar tais objetos, uma máquina requer recompensas programadas manualmente para completar com sucesso os blocos de construção de uma tarefa. Antes que um robô possa aprender a colocar uma garrafa na mesa, ele precisa ser recompensado por aprender a mover a garrafa verticalmente. Somente depois de uma série de iterações, ele aprenderá a colocar a garrafa. O Facebook introduziu um método que treina uma máquina em algumas sessões de observação humana.
Este é o quão brilhante foi o primeiro mês deste ano. Obrigado pela leitura e fique ligado nos próximos lançamentos!