 É conveniente fotografar uma página de um passaporte, um cartão de visita de um colega, um acordo com um banco ou um cheque de um restaurante em um smartphone. Documentos importantes estão sempre à mão e podem ser impressos ou enviados. Mas encontrar rapidamente os arquivos de que precisa na galeria do celular está se tornando cada vez mais difícil. Via de regra, os usuários acumulam toda uma coleção de memes e fotos com gatos mesclados com fotos de contas de luz, SNILS, etc. Funcionários de empresas, por exemplo, gerentes de campo de um banco ou escritório de advocacia, também têm situações semelhantes. Só que em vez de fotos de maricas - centenas de fotos de contratos de clientes e outros documentos. Como encontrar o exemplar necessário para enviar aos colegas do escritório, ou como imprimir a foto da carteira de habilitação na escala correta, e não no A4 inteiro? Teremos que mexer.
É conveniente fotografar uma página de um passaporte, um cartão de visita de um colega, um acordo com um banco ou um cheque de um restaurante em um smartphone. Documentos importantes estão sempre à mão e podem ser impressos ou enviados. Mas encontrar rapidamente os arquivos de que precisa na galeria do celular está se tornando cada vez mais difícil. Via de regra, os usuários acumulam toda uma coleção de memes e fotos com gatos mesclados com fotos de contas de luz, SNILS, etc. Funcionários de empresas, por exemplo, gerentes de campo de um banco ou escritório de advocacia, também têm situações semelhantes. Só que em vez de fotos de maricas - centenas de fotos de contratos de clientes e outros documentos. Como encontrar o exemplar necessário para enviar aos colegas do escritório, ou como imprimir a foto da carteira de habilitação na escala correta, e não no A4 inteiro? Teremos que mexer.
É muito mais fácil realizar todas essas tarefas com um único aplicativo. É por isso que atualizamos o ABBYY FineScanner AI . Agora ele é capaz de classificar automaticamente as fotos da galeria do smartphone em 7 grupos de documentos e pesquisar rapidamente as fotos necessárias por meio de consultas de texto.
Hoje, contaremos a você em detalhes como criamos cada um desses recursos, quais tecnologias usamos e como a estrutura ABBYY NeoML ajudou nisso. Também mostraremos como funciona no aplicativo. E no final - compartilharemos nossos planos para o desenvolvimento do FineScanner e faremos algumas perguntas.
Coloque tudo nas prateleiras dos papais
De acordo com um estudo da Appsflyer , o uso de dispositivos móveis e downloads de aplicativos, incluindo os de não jogos , disparou em 2020. Para trabalhar juntos remotamente, os funcionários precisam não apenas de mensageiros corporativos, mas também de ferramentas móveis convenientes para processamento de informações, impressão, fluxo de trabalho remoto e armazenamento de dados eficientes.
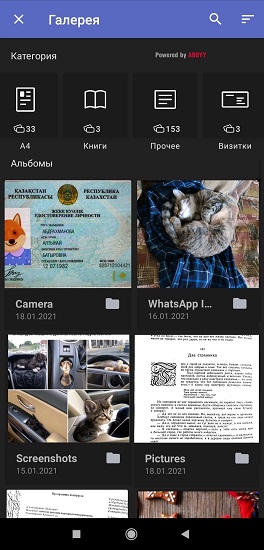
De acordo com pesquisas de usuários do FineScanner e entrevistas com eles, na maioria das vezes páginas A4 de uma ou várias páginas (contratos, faturas, ofícios, etc.), passaportes e carteiras de motorista, livros, cheques e cartões de visita são digitalizados usando o aplicativo. 40% dos entrevistados tiram fotos de documentos cerca de uma vez por mês e 20% - uma vez por semana. Com base nas estatísticas, compilamos uma lista dos tipos de documentos que os usuários costumam filmar com uma câmera e armazenam na galeria do smartphone para si próprios ou para o trabalho. E então ensinamos o FineScanner a dividir as fotos em grupos. O processo consiste em duas etapas, ocorre inteiramente em segundo plano e não requer conexão com a Internet.
1). O FineScanner primeiro classifica as fotos da galeria do usuário
Após o primeiro lançamento do aplicativo e recebendo todas as permissões do usuário, as redes neurais integradas analisam automaticamente as fotos no smartphone e as distribuem em 7 categorias: formato A4, livros, cartões de visita, carteiras de identidade, recibos, texto manuscrito e “Outros” (nesta pasta estão guardados posters, postais, revistas a cores, etc.)

Nossa rede neural no mecanismo ABBYY NeoML , da qual falamos em detalhes no Habré, está trabalhando na classificação inteligente de imagens . O mecanismo consiste em duas redes neurais: a primeira detecta a presença de texto na imagem, a segunda determina os tipos de documentos. A arquitetura de rede é baseada em blocos MobilenetV3.
Era importante para nós separar os documentos manuscritos dos impressos, então a primeira grade divide os arquivos em 3 classes:
- imagem com texto manuscrito,
- imagem com texto impresso,
- imagem sem texto (gatos, selfies e meio ambiente).
Na primeira grade, usamos adicionalmente informações sobre o corte central (um pedaço da imagem do centro, cortado em alta resolução) para determinar a presença de texto na imagem. Fizemos justamente esse recorte, pois na amostra (falaremos disso um pouco a seguir) em todas as fotos, o texto estava principalmente na parte central. Essa imagem é alimentada junto com a miniatura para um ramo separado da rede e ajuda a decidir se há texto na imagem ou não.
A segunda grade define os tipos de documentos:
- Documento A4 (com alguns desenhos),
- 4 ( , — , ),
- ( - ),
- ( , , ),
- ,
- ID (, .) – , ,
- ( . ).
O conjunto de dados para treinamento de redes neurais foi coletado e marcado por nossos funcionários. A amostra foi composta por cerca de 40 mil fotografias (cartões de visita, flyers, cartões bancários, certificados, seguros etc.) tiradas com smartphone.
Devido à rede neural, o peso do aplicativo aumentou de forma insignificante - em apenas 3 MB. Tentamos especificamente tornar a rede neural compacta. Eu não queria inchar muito o aplicativo por causa de um recurso um tanto "experimental".
2). Após a classificação, o texto é reconhecido nas fotografias de documentos encontradas.
Para fazer isso, usamos nossa tecnologia ABBYY Mobile Capture SDK , que funciona tanto no TextGrabber para OCR ou sequências de vídeo, quanto no Business Card Reader para processar cartões de visita. FineScanner já usou este SDK antes para reconhecimento rápido de documentos offline. Desta vez, aproveitamos ao máximo: ele pode reconhecer texto em milhares de fotos. Claro, tentamos fazer isso com cuidado e cuidado para que o processo não carregue o aparelho e não devore a bateria. Além disso, decidimos não baixar as fotos do usuário enviadas para as nuvens por enquanto, mas processar apenas aquelas que estão disponíveis localmente no dispositivo.
O tempo total para todo o processamento da galeria depende da quantidade de fotos e documentos entre eles, bem como da geração do telefone e é em média de 10 a 30 minutos pela primeira vez. No futuro, apenas novas fotos serão digitalizadas, e já haverá muito menos delas, não milhares de peças.
Encontre um documento pelo seu texto
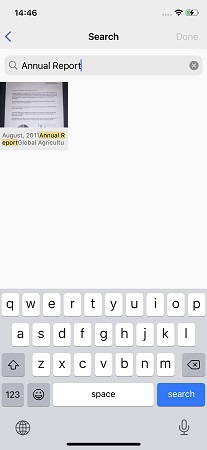 Classificar imagens por tipo é uma coisa boa, mas e se houver centenas de imagens na pasta Livros, mas você precisar encontrar uma, por exemplo, uma receita de shakshuka picante fotografada de uma rara enciclopédia culinária? Ou encontra na pasta A4 um contrato de locação assinado há dois anos?
Classificar imagens por tipo é uma coisa boa, mas e se houver centenas de imagens na pasta Livros, mas você precisar encontrar uma, por exemplo, uma receita de shakshuka picante fotografada de uma rara enciclopédia culinária? Ou encontra na pasta A4 um contrato de locação assinado há dois anos?
Para esses casos, ensinamos o FineScanner como pesquisar o texto do documento. Além disso, a opção com a busca por uma consulta exata, palavra por palavra, foi descartada imediatamente. Como regra, não é difícil pesquisar texto em documentos bem fotografados, mas na galeria de um smartphone pode haver qualquer coisa - fotos fortemente giradas ou borradas. Não é difícil organizar a chamada "busca clara" segundo eles, mas os resultados serão tristes. É claro que a capitalização (usando letras maiúsculas) pode e deve ser ignorada, mas existem, por exemplo, erros de grafia dos usuários ao redigir uma solicitação.
Para que o aplicativo engolisse esse espectro de erros, fizemos uma "busca fuzzy". Eles não iriam escrever seu próprio mecanismo de busca completo, então olharam para as abordagens e bibliotecas existentes. Como resultado, para resolver nosso problema veio um bom algoritmo diff de Eugene Myers (algoritmo diff de Myer).
O algoritmo diff não é usado para pesquisar, mas para comparar dois textos ou duas versões do mesmo documento.
Eles pegaram a implementação final a partir daqui . Verdade, eu tive que adicionar em cima disso o cálculo da distância Levenshtein entre a consulta de pesquisa e a substring encontrada e selecionar os limites para que não houvesse opções completamente selvagens. Como resultado, nossa pesquisa de texto funciona de forma clara, rápida e em tempo real.
Régua AR na versão iOS, ou como determinar o tamanho de um documento sem dançar com um pandeiro
 Quando desenvolvemos novos recursos no FineScanner, levamos em consideração os desejos dos usuários. Por exemplo, muitas vezes precisam imprimir documentos não apenas nos tamanhos usuais (A4, A5, A6, cartão de visita), mas também fora do padrão: folhetos, flyers, SNILS, etc. E com a impressão de tais arquivos, dificuldades surgem: por exemplo, a foto é esticada para o A4 inteiro, embora as proporções originais sejam diferentes.
Quando desenvolvemos novos recursos no FineScanner, levamos em consideração os desejos dos usuários. Por exemplo, muitas vezes precisam imprimir documentos não apenas nos tamanhos usuais (A4, A5, A6, cartão de visita), mas também fora do padrão: folhetos, flyers, SNILS, etc. E com a impressão de tais arquivos, dificuldades surgem: por exemplo, a foto é esticada para o A4 inteiro, embora as proporções originais sejam diferentes.
Os tamanhos de documento mais comuns podem ser selecionados em uma lista pronta no apêndice, existem 8 tipos deles. Quaisquer outros - postais, vistos, etc. - agora pode ser medido automaticamente. Para isso, integramos o ARKit (linha em realidade aumentada) na nova versão do FineScanner para iOS. Para seu desenvolvimento, usamos a API da Apple em conjunto com nosso módulo de colheita ABBYY Mobile Capture SDK, que permite definir os limites do documento mesmo em um fundo branco e completá-los se forem fechados manualmente. A régua determina o tamanho físico do documento para especificá-lo nas propriedades e exibi-lo corretamente no papel quando impresso em uma impressora.
É assim que funciona:
Como nossos clientes empresariais usam o FineScanner
Nossos clientes B2C serão os primeiros a experimentar a nova funcionalidade e as empresas começarão a usar o aplicativo um pouco mais tarde. Isso se deve principalmente às rígidas políticas de segurança corporativa.
Nossos clientes de grandes empresas usam suas versões do ABBYY FineScanner sob o controle de várias plataformas de MDM (Mobile Device Management, ou seja, soluções que permitem configurar os níveis de proteção de informações corporativas contra acesso e distribuição não autorizados, bem como determinar se as informações armazenadas em um dispositivo móvel estarão disponíveis para aplicativos de terceiros). Por exemplo, a equipe de auditoria ou consultoria de negócios da PwC usa um scanner móvelpara digitalização rápida de quaisquer documentos. Durante as auditorias, eles tiram fotos de, por exemplo, contratos ou pedidos em apenas alguns segundos, convertem-nos em PDF pesquisável e enviam-nos a repositórios corporativos para verificação adicional e análise de dados.
Para a conveniência de nossos clientes, estamos agora nos preparando para lançar uma versão do FineScanner com suporte para os sistemas MDM mais populares - Microsoft InTune, Mobile Iron, Workspace One e outros.
Para o futuro
Esperamos que o FineScanner atualizado ajude a simplificar as tarefas de digitalização e reconhecimento de documentos e livros direto no seu smartphone, bem como encontrar rapidamente os arquivos de que você precisa na galeria e imprimi-los.
Coletamos regularmente solicitações de usuários para o FineScanner, a fim de entender como desenvolver ainda mais o produto. De acordo com nossa última pesquisa, metade dos usuários enviam documentos fotografados para seu próprio correio ou para outro e-mail e continuam a trabalhar com eles no computador, por exemplo, impressão ou armazenamento. Além disso, mais de 70% esperam que o FineScanner se integre ao ABBYY FineReader PDF . Ficou interessante para nós descobrir o que os khabrovitas pensam sobre isso.